Scrapy中的UA池,代理池,以及selenium的应用
UA池
- 下载中间件:
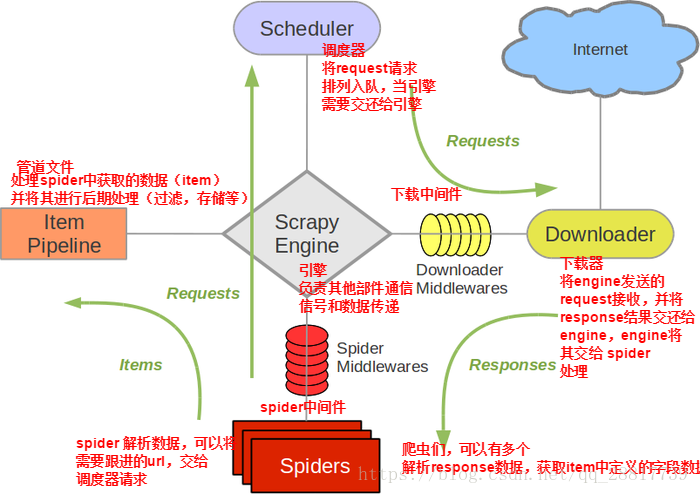
- 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件。
- 作用:
- 引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系列处理。比如设置请求的 User-Agent,设置代理等
- 在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理。比如进行gzip解压等
我们主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent ,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
- UA池:User-Agent池
- 作用:尽可能多的将scrapy工程中的请求伪装成不同类型的浏览器身份。
- 操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的请求头信息中的UA进行篡改伪装
3.在配置文件中开启下载中间件:
DOWNLOADER_MIDDLEWARES = {
'redisCrwlSpiderPro.middlewares.RediscrwlspiderproDownloaderMiddleware': 543,
}
- 代码展示:
#导包
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
import random
#UA池代码的编写(单独给UA池封装一个下载中间件的一个类)
class RandomUserAgent(UserAgentMiddleware): def process_request(self, request, spider):
#从列表中随机抽选出一个ua值
ua = random.choice(user_agent_list)
#ua值进行当前拦截到请求的ua的写入操作
request.headers.setdefault('User-Agent',ua) user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
代理池
- 作用:尽可能多的将scrapy工程中的请求的IP设置成不同的。
- 操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的IP修改成某一代理IP
3.在配置文件中开启下载中间件
DOWNLOADER_MIDDLEWARES = {
'redisCrwlSpiderPro.middlewares.RediscrwlspiderproDownloaderMiddleware': 543,
}
- 代码展示:
#批量对拦截到的请求进行ip更换
#单独封装下载中间件类
class Proxy(object):
def process_request(self, request, spider):
#对拦截到请求的url进行判断(协议头到底是http还是https)
#request.url返回值:http://www.xxx.com
h = request.url.split(':')[0] #请求的协议头
if h == 'https':
ip = random.choice(PROXY_https)
request.meta['proxy'] = 'https://'+ip
else:
ip = random.choice(PROXY_http)
request.meta['proxy'] = 'http://' + ip #可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
selenium在Scrapy中的应用
- selenium在scrapy中使用的原理分析:

当引擎将国内板块url对应的请求提交给下载器后,
下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,
引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。
要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,
然后将被篡改的response对象最终交给Spiders进行解析操作。
- selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
- 代码展示:
- 爬虫文件:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#实例化一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver') #必须在整个爬虫结束后,关闭浏览器
def closed(self,spider):
print('爬虫结束')
self.bro.quit()
- 中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response
- 配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
Scrapy中的UA池,代理池,以及selenium的应用的更多相关文章
- Scrapy加Redis加IP代理池实现音乐爬虫
音乐爬虫 关注公众号"轻松学编程"了解更多. 目的:爬取歌名,歌手,歌词,歌曲url. 一.创建爬虫项目 创建一个文件夹,进入文件夹,打开cmd窗口,输入: scrapy star ...
- 爬虫开发13.UA池和代理池在scrapy中的应用
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: ( ...
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
- 14.UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - ...
- UA池和代理池
scrapy下载中间件 UA池 代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎 ...
- 14,UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 一,下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器 ...
- [爬虫]一个易用的IP代理池
一个易用的IP代理池 - stand 写爬虫时常常会遇到各种反爬虫手段, 封 IP 就是比较常见的反爬策略 遇到这种情况就需要用到代理 IP, 好用的代理通常需要花钱买, 而免费的代理经常容易失效, ...
- 【解决方案】IP代理池设计与解决方案
一.背景 爬虫服务请求量大,为了应对反爬措施,增加爬虫的爬取效率和代理IP使用率,需要设计一个IP代理池,满足以下需求: 定时任务获取第三方代理 及时剔除IP代理池中失效的IP 业务隔离IP 若IP未 ...
- Flask开发系列之Flask+redis实现IP代理池
Flask开发系列之Flask+redis实现IP代理池 代理池的要求 多站抓取,异步检测:多站抓取:指的是我们需要从各大免费的ip代理网站,把他们公开的一些免费代理抓取下来:一步检测指的是:把这些代 ...
随机推荐
- Maya API编程快速入门
一.Maya API编程简介 Autodesk® Maya® is an open product. This means that anyone outside of Autodesk can ch ...
- 【sicily】 1934. 移动小球
Description 你有一些小球,从左到右依次编号为1,2,3,...,n. 你可以执行两种指令(1或者2).其中, 1 X Y表示把小球X移动到小球Y的左边, 2 X Y表示把小球X移动到小球Y ...
- (2)dotnet开源电商系统-brnshop VS nopCommerce(dotnet两套电商来PK--第二篇:代码从哪开始-BrnMall3.0Beta)
看大牛们的源码,对于水平一般的人,还是略微有点难度的.我从我自身读码的亲身体验,写下杂散片语,希望能和大家一同进步,也为了日后记忆上的备查. 先看的是brnMall的源码结构,从哪看起呢? 首先推荐看 ...
- bootstrap 模态框日期控件datepicker被遮住问题的解决
找到日期输入框,并将 .class 属性的 z-index 改大 在JSP页添加样式: 这样就OK了:
- JDBC Druid式link
准备工作:导入包------druid-1.0.9.jar src文件夹下放下druid.properties文件 且其中的url和数据库名要配置完备 import JdbcUtils.JDBC ...
- Vim入门基础知识集锦
1. 简介 Vim(Vi[Improved])编辑器是功能强大的跨平台文本文件编辑工具,继承自Unix系统的Vi编辑器,支持Linux/Mac OS X/Windows系统,利用它可以建立.修 ...
- .NET 人工智能相关资料整理
机器学习组件:https://www.cnblogs.com/asxinyu/p/dotnet_Opensource_project_AccordNET.html ML.NET: ...
- PAT_A1146#Topological Order
Source: PAT A1146 Topological Order (25 分) Description: This is a problem given in the Graduate Entr ...
- js中call、apply、bind的区别
var Person = { name : 'alice', say : function(txt1,txt2) { console.info(txt1+txt2); console.info(thi ...
- while(Thread.activeCount() > 1)
今天看到深入理解JVM第367页多线程volatile部分照着书本敲着代码发现了一个问题 Thread.activeCount()会一直大于2 public class VolatileTest { ...