CUDA与OpenCL架构
CUDA与OpenCL架构
目录
图表清单
图 22 the performance for OpenCL and CUDA in NVIDIA GTX 285
图 23 the runtime for OpenCL and CUDA in NVIDIA GTX 285
图 24 DGEMM performance on Tesla C2050 under OpenCL and CUDA
表 9 各种实现光线投射算法的三维可视化模型的运行效果对比表
1. GPU的体系结构
1.1 GPU简介
GPU设计的初衷就是为了减轻CPU计算的负载,将一部分图形计算的功能设计到一块独立的处理器中,将矩阵变换、顶点计算和光照计算等操作从 CPU 中转移到 GPU中,从而一方面加速图形处理,另一方面减小了 CPU 的工作负载,让 CPU 有时间去处理其它的事情。
在GPU上的各个处理器采取异步并行的方式对数据流进行处理,根据费林分类法(Flynn's Taxonomy),可以将资讯流(information stream)分成指令(Instruction)和数据(Data)两种,据此又可分成四种计算机类型:
- 单一指令流单一数据流计算机(SISD):单核CPU
- 单一指令流多数据流计算机(SIMD):GPU的计算模型
- 多指令流单一数据流计算机(MISD):流水线模型
- 多指令流多数据流计算机(MIMD):多核CPU

图 1 费林分类法
1.2 GPU与CPU的差异
- 性能差异
可编程的GPU已发展成为一种高度并行化、多线程、多核的处理器,具有杰出的计算效率和极高的存储器带宽。如图 2和图 3所示CPU和GPU的计算能力差异。

图 2 峰值双精度浮点性能
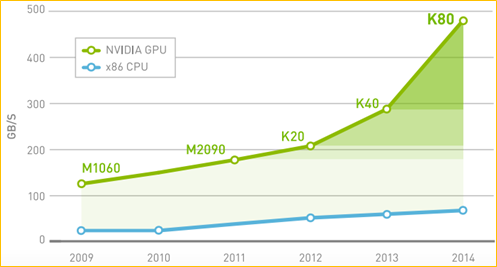
图 3 峰值内存带宽
- 差异原因
CPU 和 GPU之间浮点运算能力之所以存在这样的差异,原因就在于CPU具有复杂的控制逻辑和大容量的缓存,适合进行控制转移,处理分支繁杂的任务,而GPU专为计算密集型、高度并行化的计算而设计。因而GPU具有更多ALU(算术运算单元)和高显存带宽的设计能使更多晶体管用于数据处理,而非数据缓存和流控制,如下图所示。

图 4 GPU中的更多晶体管用于数据处理
更具体地说,GPU专用于解决可表示为数据并行计算的问题——在许多数据元素上并行执行的程序,具有极高的计算密度(数学运算与存储器运算的比率)。由于所有数据元素都执行相同的程序,因此对精密流控制的要求不高;由于在许多数据元素上运行,且具有较高的计算密度,因而可通过计算隐藏存储器访问延迟,而不必使用较大的数据缓存。
2. CUDA架构
CUDA是一种新的操作GPU计算的硬件和软件架构,它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。
2.1 硬件架构
2.1.1 GPU困境
虽然GPU通过图形应用程序的算法存在如下几个特征:算法密集、高度并行、控制简单、分多个阶段执行以及前馈(Feed Forward)流水线等,能够在高度密集型的并行计算上获得较高的性能和速度,但在2007年以前GPU要实现这样的应用还是存在许多困难的:
- GPU 只能通过一个图形的API来编程,这不仅加重了学习负担更造成那些非图像应用程序处理这些 API 的额外开销。
- 由于DRAM内存带宽,一些程序会遇到瓶颈。
- 无法在 DRAM 上进行通用写操作。
所以NVIDIA于2006年11月在G80系列中引入的Tesla统一图形和计算架构扩展了GPU,使其超越了图形领域。通过扩展处理器和存储器分区的数量,其强大的多线程处理器阵列已经成为高效的统一计算平台,同时适用于图形和通用并行计算应用程序。从G80系列开始NVIDIA加入了对CUDA的支持。
2.1.2 芯片结构
具有Tesla架构的GPU是具有芯片共享存储器的一组SIMT(单指令多线程)多处理器。它以一个可伸缩的多线程流处理器(Streaming Multiprocessors,SMs)阵列为中心实现了MIMD(多指令多数据)的异步并行机制,其中每个多处理器包含多个标量处理器(Scalar Processor,SP),为了管理运行各种不同程序的数百个线程,SIMT架构的多处理器会将各线程映射到一个标量处理器核心,各标量线程使用自己的指令地址和寄存器状态独立执行。

图 5 GPU的共享存储器的SIMT多处理器模型
如上图所示,每个多处理器(Multiprocessor)都有一个属于以下四种类型之一的芯片存储器:
- 每个处理器上有一组本地 32 位寄存器(Registers);
- 并行数据缓存或共享存储器(Shared Memory),由所有标量处理器核心共享,共享存储器空间就位于此处;
- 只读固定缓存(Constant Cache),由所有标量处理器核心共享,可加速从固定存储器空间进行的读取操作(这是设备存储器的一个只读区域);
- 一个只读纹理缓存(Texture Cache),由所有标量处理器核心共享,加速从纹理存储器空间进行的读取操作(这是设备存储器的一个只读区域),每个多处理器都会通过实现不同寻址模型和数据过滤的纹理单元访问纹理缓存。
多处理器 SIMT 单元以32个并行线程为一组来创建、管理、调度和执行线程,这样的线程组称为 warp 块(束),即以线程束为调度单位,但只有所有32个线程都在诸如内存读取这样的操作时,它们就会被挂起,如图 7所示的状态变化。当主机CPU上的CUDA程序调用内核网格时,网格的块将被枚举并分发到具有可用执行容量的多处理器;SIMT 单元会选择一个已准备好执行的 warp 块,并将下一条指令发送到该 warp 块的活动线程。一个线程块的线程在一个多处理器上并发执行,在线程块终止时,将在空闲多处理器上启动新块。

图 6 CPU五种状态的转换

图 7 线程束调度变化
2.2 软件架构
CUDA是一种新的操作GPU计算的硬件和软件架构,它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。目前Tesla架构具有在笔记本电脑、台式机、工作站和服务器上的广泛可用性,配以C/C++语言的编程环境和CUDA软件,使这种架构得以成为最优秀的超级计算平台。

图 8 CUDA软件层次结构
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA 提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
2.3 编程模型
CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU。在CUDA程序构架中,主程序还是由 CPU 来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成 GPU 能执行的程序,并传送到GPU。而这个程序在CUDA里称做核(kernel)。CUDA允许程序员定义称为核的C语言函数,从而扩展了 C 语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。
在 CUDA 程序中,主程序在调用任何 GPU 内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。
2.3.1 线程层次结构
在GPU中要执行的线程,根据最有效的数据共享来创建块(Block),其类型有一维、二维或三维。在同一个块内的线程可彼此协作,通过一些共享存储器来共享数据,并同步其执行来协调存储器访问。一个块中的所有线程都必须位于同一个处理器核心中。因而,一个处理器核心的有限存储器资源制约了每个块的线程数量。在早起的 NVIDIA 架构中,一个线程块最多可以包含 512 个线程,而在后期出现的一些设备中则最多可支持1024个线程。一般 GPGPU 程序线程数目是很多的,所以不能把所有的线程都塞到同一个块里。但一个内核可由多个大小相同的线程块同时执行,因而线程总数应等于每个块的线程数乘以块的数量。这些同样维度和大小的块将组织为一个一维或二维线程块网格(Grid)。具体框架如图 9所示。

图 9 线程块网格
核函数只能在主机端调用,其调用形式为:Kernel<<<Dg,Db, Ns, S>>>(param list)
- Dg:用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
- Db:用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。一个block中共有Db.x*Db.y*Db.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
- Ns:是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
- S:是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
如下是一个CUDA简单的求和程序:

图 10 CUDA求和程序
2.3.2 存储器层次结构
CUDA 设备拥有多个独立的存储空间,其中包括:全局存储器、本地存储器、共享存储器、常量存储器、纹理存储器和寄存器,如图 11所示。

图 11 CUDA设备上的存储器
CUDA线程可在执行过程中访问多个存储器空间的数据,如图 12所示其中:
- 每个线程都有一个私有的本地存储器。
- 每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。
- 所有线程都可访问相同的全局存储器。
- 此外还有两个只读的存储器空间,可由所有线程访问,这两个空间是常量存储器空间和纹理存储器空间。全局、固定和纹理存储器空间经过优化,适于不同的存储器用途。纹理存储器也为某些特殊的数据格式提供了不同的寻址模式以及数据过滤,方便 Host对流数据的快速存取。

图 12 存储器的应用层次
2.3.3 主机(Host)和设备(Device)
如图 13所示,CUDA 假设线程可在物理上独立的设备上执行,此类设备作为运行C语言程序的主机的协处理器操作。内核在GPU上执行,而C语言程序的其他部分在CPU上执行(即串行代码在主机上执行,而并行代码在设备上执行)。此外,CUDA还假设主机和设备均维护自己的DRAM,分别称为主机存储器和设备存储器。因而,一个程序通过调用CUDA运行库来管理对内核可见的全局、固定和纹理存储器空间。这种管理包括设备存储器的分配和取消分配,还包括主机和设备存储器之间的数据传输。

图 13 CUDA异构编程模型
2.4 CUDA软硬件
2.4.1 CUDA术语
由于CUDA中存在许多概念和术语,诸如SM、block、SP等多个概念不容易理解,将其与CPU的一些概念进行比较,如下表所示。
|
CPU |
GPU |
层次 |
|
算术逻辑和控制单元 |
流处理器(SM) |
硬件 |
|
算术单元 |
批量处理器(SP) |
硬件 |
|
进程 |
Block |
软件 |
|
线程 |
thread |
软件 |
|
调度单位 |
Warp |
软件 |

图 14 NVIDIA 630显卡CUDA信息
2.4.2 硬件利用率
当为一个GPU分配一个内核函数,我们关心的是如何才能充分利用GPU的计算能力,但由于不同的硬件有不同的计算能力,SM一次最多能容纳的线程数也不尽相同,SM一次最多能容纳的线程数量主要与底层硬件的计算能力有关,如下表显示了在不同的计算能力的设备上,每个线程块上开启不同数量的线程时设备的利用率。
|
计算能力 每个线 程块的线程数 |
1.0 |
1.1 |
1.2 |
1.3 |
2.0 |
2.1 |
3.0 |
|
64 |
67 |
67 |
50 |
50 |
33 |
33 |
50 |
|
96 |
100 |
100 |
75 |
75 |
50 |
50 |
75 |
|
128 |
100 |
100 |
100 |
100 |
67 |
67 |
100 |
|
192 |
100 |
100 |
94 |
94 |
100 |
100 |
94 |
|
256 |
100 |
100 |
100 |
100 |
100 |
100 |
100 |
|
…… |
…… |
||||||
3 OpenCL架构
3.1 简介
OpenCL(Open Computing Language),即开放运算语言,是一个统一的开放式的开发平台。OpenCL是首个提出的并行开发的开放式的、兼容的、免费的标准,它的目的是为异构系统通用提供统一开发平台。OpenCL最初是由苹果公司设想和开发,并在与AMD,IBM,英特尔和NVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。

图 15 OpenCL历史版本
3.2 框架组成
OpenCL的框架组成可以划分为三个部分,分别为OpenCL平台API、OpenCL运行时API,以及OpenCL内核编程语言。
3.2.1 平台API
平台(Platform)这个词在OpenCL中拥有非常特定的含义,它表示的是宿主机、OpenCL设备和OpenCL框架的组合。多个OpenCL平台可以共存于一台异构计算机。举个例子,CPU开发人员和GPU开发人员可以在同一个系统上分别定义自己的OpenCL框架。这时就需要一种方法来查询系统中可用的OpenCL 框架,哪些OpenCL设备是可用的,以及这些OpenCL设备的特性。相当于CUDA的主机和设备之间的关系。
此外,为了形成一个给定的OpenCL应用平台,还需要对这些框架和设备所属的子集进行控制。这些功能都是由OpenCL平台API中的函数来解决的。此外,平台API还提供了为OpenCL创建上下文的函数。OpenCL的上下文规定了OpenCL应用程序的打开方式(相当是CUDA中核函数的调用),这可以在宿主机程序代码中得到验证。
3.2.2 运行时API
平台API提供函数创建好上下文之后,运行时API主要提供使用上下文提供的功能满足各种应用需求的函数。这是一个规模庞大且内容十分复杂的函数集。运行时API的第一个任务是创建一个命令队列。命令队列与设备相关联,而且一个上下文中可以同时存在多个活动的命令队列。有了命令队列,就可以通过调用运行时API提供的函数来进行内存对象的定义以及管理内存中的对象所依赖的所有其他对象。以上是内存对象的持有操作,另外还有释放操作,也是由运行时API提供的。
此外,运行时API还提供了创建动态库所需要的程序对象的函数,正是这些动态库实现了Kernel的定义。最后,运行时层的函数会发出与命令队列交互的命令。此外,管理数据共享和对内核的执行加以限制同步点也是由运行时API处理的。
3.2.3 内核编程语言
内核编程语言是用于编写OpenCL内核代码的。除了宿主机程序之外,内核程序也十分重要,它负责完成OpenCL中的实际工作。在部分OpenCL实现中用户可以跟其他语言编写的原生内核实现交互,但多数情况下内核是需要用户使用内核编程语言编写实现的。OpenCL C编程语言就是OpenCL中的内核编程语言,该编程语言是"ISO C99 标准"的一个扩展子集,也就是说它是由 ISO C99语言派生而来的。现在的OpenCL2.1还支持C++,是基于eISO/IEC JTC1 SC22 WG21 N 3690(C++14)。
3.2.4 适合平台
- AMD
根据AMD官网所提供的内容,OpenCL在AMD显卡中只能适用X86核心的CPU架构,而对其他PowerPC和ARM架构则不适用;并且也不是所有的AMD显卡都能运行OpenCL,按其官网介绍只能是AMD Radeon、AMD FirePro和AMD Firestream三种类型的显卡;但对于操作系统则可以是Linux或Windows的系统,如表 1所示。
表 1 AMD OpenCL
|
CPU架构 |
显卡类型 |
操作系统 |
系统位数 |
|
X86 |
AMD Radeon |
Linux/ Windows |
32/64 |
|
AMD FirePro |
Linux/ Windows |
32/64 |
|
|
AMD Firestream |
Linux/ Windows |
32/64 |
- NVIDIA
NVIDIA OpenCL是一种运行于具有CUDA能力GPU上的一种底层API,即OpenCL是运行于CUDA之上的一种API,从而若适用CUDA的平台,也同样适用OpenCL。根据NVIDIA官网最新版本的CUDA 7.5适合的平台如表 2所示。
表 2 NVIDIA OpenCL
|
操作系统 |
CPU架构 |
Distribution |
|
Windows |
X86_64 |
10、8.1、7、Server 2012 R2、Server 2008 R2 |
|
Linux |
X86_64 |
Fedora、OpenSUSE、RHEL、CentOS、SLES、steamOS、Ubuntu. |
|
ppc64le |
Ubuntu |
|
|
Mac OSX |
x86_64 |
10.11、10.10、10.9 |
3.3 计算架构
OpenCL 的设计目标是为开发人员提供一套移植性强且高效运行的解决方案。为了更好的描述OpenCL设计的核心理念,Khronos Group官方将OpenCL的计算架构分解成四个模型,分别平台模型(Platform Model)、内存模型(Memory Model)、执行模型(Execution Model)以及编程模型(Programming Model)。
3.3.1 平台模型(Platform Model)
从整体上来看,主机(host)端是负责掌管整个运算的所有计算资源,因此OpenCL 应用程序首先是由主机端开始,然后由程序将各个计算命令从主机端发送给每个 GPU 设备处理单元,运行完毕之后最后由主机端结束。
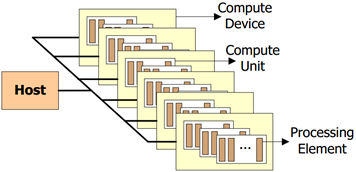
图 16 OpenCL架构的平台模型
平台模型如图 16所示。从图中可以直观的看到,最基本处理单位是Processing Element,简称PE(处理单元),而一个或多个PE组成了Compute Unit,简称CU(计算单元),进而一个或多个CU就组成了Compute Device,即OpenCL设备。最后,一个或多个OpenCL设备连接到主机,并等待着处理主机发送的计算指令,由于PE是最基本处理单位,因此每条计算指令最终都归PE进行处理,而PE是在CU中的。
3.3.2 内存模型(Memory Model)
OpenCL将内核程序中用到的内存分为图 17所示的四种不同的类型。

图 17 OpenCL内存模型
其中它们的读写特性分别为:
- Global memory:工作区内的所有工作节点都可以自由的读写其中的任何数据。OpenCL C语言提供了全局缓存(Global buffer)的内建函数。
- Constant memory: 工作区内的所有工作节点可以读取其中的任何数据但不可以对数据内容进行更改,在内核程序的执行过程中保持不变。主机端负责分配和初始化常量缓存(Constant buffer)。
- Local memory: 只有同一工作组中的工作节点才可以对该类内存进行读写操作。它既可以为 OpenCL 的执行分配一块私有内存空间,也可以直接将其映射到一块全局缓存(Global buffer)上。特点是运行速度快。
- Private memory: 只有当前的工作节点能对该内存进行访问和读写操作。一个工作节点内部的私有缓存(Private buffer)对其他节点来说是不可见的。
表 3 OpenCL各种存储器的分配方式和访问权限
|
存储器类型 |
主机 |
内核 |
||
|
分配方式 |
访问权限 |
分配方式 |
访问权限 |
|
|
Global |
动态分配 |
可读、可写 |
不可分配 |
可读、可写 |
|
Constant |
动态分配 |
可读、可写 |
静态分配 |
只读 |
|
Local |
动态分配 |
不可访问 |
静态分配 |
可读、可写 |
|
Private |
不可分配 |
不可访问 |
静态分配 |
可读、可写 |
3.3.3 执行模型(Execution Model)
OpenCL的执行模型是应用程序通过主机端对OpenCL设备端上的内核程序进行管理,该模型分为两个模块:一个是在主机端执行的管理程序,也称为Hostprogram,另一个是主机端的Hostprogram所管理的在OpenCL上执行的程序,也被称作Kernels。在执行Kernels前,先要建立一个索引空间,来对设备里的每个节点进行标识,每个节点都将执行相同的kernel程序。在每个工作组中,都有一个局部ID,每个节点在全局里还有个全局 ID,OpenCL使用NDRange来定义这个索引空间。

图 18 OpenCL执行模型
如图 18所示的OpenCL执行模型,其过程可以细分为如下的步骤完成:
- 查询连接主机上的OpenCL设备;
- 创建一个关联到OpenCL设备的context;
- 在关联的设备上创建可执行程序;
- 从程序池中选择kernel程序;
- 从主机或设备上创建存储单元;
- 如果需要将主机的数据复制到OpenCL设备上的存储单元上;
- 执行kernel程序执行;
- 从OpenCL设备上复制结果到主机上。
3.3.4 编程模型(Programming Model)
OpenCL支持两种编程模型,分别为数据并行编程模型和任务并行编程模型,并支持上面由这两种编程模型混合的混合编程模型。
- 数据并行编程模型
OpenCL提供一个分层的数据并行编程模型,即典型的SIMD计算模型,其特点是每个数据经由同样的指令序列处理,而处理数据的次序是不确定的,并且每个数据的处理是不相干的,即任一线程的计算不得依赖于其它线程的结果(包括中间结果)。
- 任务并行编程模型
任务并行模型中的每个内核是在一个独立的索引空间中执行的,也就是说,执行内核的计算机单元内只有一个工作组,其中只有一个工作项。在这样的模型中,每个线程都可以执行不同的带啊,着相当于MIMD的计算模型,适合多核心CPU。
4. CUDA与OpenCL之间的差异
CUDA和OpenCL都是实现计算机异构并行计算架构,然而CUDA是针对NVIDIA公司的GPU,而OpenCL是一种通用的计算框架。两者基本的差别为:
表 4 CUDA与OpenCL基本差别
|
CUDA |
OpenCL |
|
|
技术类型 |
控制 |
开源和VIP服务 |
|
出现时间 |
2006年 |
2008年 |
|
SDK企业 |
NVIDIA |
具体根据企业 |
|
SDK是否免费 |
Yes |
依赖企业 |
|
实现企业 |
仅NVIDIA |
Apple、NVIDIA、AMD、IBM |
|
支持系统 |
Windows, Linux, Mac OS X; 32 and 64‐bit |
依赖具体企业 |
|
支持设备类型 |
仅NVIDIA GPU |
多种类型 |
|
支持嵌入式设备 |
NO |
Yes |
4.1 硬件架构
4.1.1 芯片结构
CUDA和OpenCL的芯片结构类似,都是按等级划分的,并逐渐提高等级。然而OpenCL更具通用性并使用更加一般的技术,如OpenCL通过使用Processing Element代替CUDA的Processor,同时CUDA的模型只能在NVIDIA架构的GPU上运行。

图 19 OpenCL与CUDA芯片结构
4.1.2 存储结构
CUDA和OpenCL的存储模型如图 20所示,两者的模型类型,都是将设备和主机的存储单元独立分开,它们的都是按等级划分并需要程序员进行精确的控制,并都能通过API来查询设备的状态、容量等信息。而OpenCL模型更加抽象,并为不同的平台提供更加灵活的实现,在CUDA模型的Local Memory在OpenCL没有相关的概念。对于CUDA和OpenCL模型的类似概念,通过表 5列出两者对存储单元命名的差异。

图 20 CUDA与OpenCL存储模型
表 5 CUDA与OpenCL存储器对比
|
OpenCL |
CUDA |
|
Host memory |
Host memory |
|
Global memory |
Global or Device memory |
|
Global memory |
Local memory |
|
Constant memory |
Constant memory |
|
Global memory |
Texture memory |
|
Local memory |
Shared memory |
|
Private memory |
Registers |
4.2 软件架构
4.2.1 应用框架
一个典型的应用框架都包含有libraries、API、drivers/compilies和runtime system等来支持软件开发。CUDA和OpenCL也拥有相似的特性,都拥有runtime API和library API,但具体环境下的创建和复制API是不同的,并且OpenCL可以通过平台层查询设备的信息;CUDA的kernel可以直接通过NVIDIA 驱动执行,而OpenCL的kernel必须通过OpenCL驱动,但这样可能影响到性能。因为OpenCL毕竟是一个开源的标准,为了适应不同的CPU、GPU和设备都能够得到正常执行;而CUDA只针对NVIDIA的GPU产品。
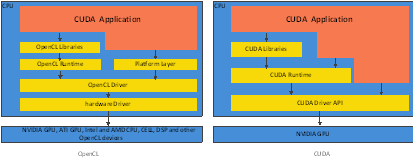
图 21 CUDA与OpenCL应用框架
4.2.2 编程模型
- 开发模型
CUDA和OpenCL应用的开发模型基本一致,都是由Host和Device程序组成。程序首先开始执行Host程序,然后由Host程序激活Device程序kernel执行。其中两者也存在一些差别,如表 6所示。
表 6 CUDA与OpenCL开发模型比较
|
CUDA |
OpenCL |
|
|
精确的host和device代码分离 |
Yes |
Yes |
|
定制的kernel编程语言 |
Yes |
Yes |
|
并行的kernel编程语言 |
Yes |
仅有OpenCL C或具体的企业语言 |
|
支持数据并行kernels |
Yes |
Yes |
|
支持任务并行kernels |
No |
Yes |
|
多编程接口 |
Yes,包括OpenCL |
仅支持标准C的API |
|
host和device结合程度 |
Yes,效率非常高 |
No,分离的编译并且kernel和API调用是不相干的 |
|
Graphics支持 |
OpenGL and Direct3D |
OpenGL |
- kernel编程
kernel程序是指Device设备上执行的代码,它是直接在设备上执行,受具体设备的限制,具体两者的差别,如表 7所示。
表 7 kernel编程差异
|
CUDA |
OpenCL |
|
|
基于开发语言版本 |
基本C和C++、C++14 |
C99 |
|
访问work-item方式 |
通过内置的变量 |
通过内置函数 |
|
内置vector类型 |
基本vector类型,没有操作和函数 |
vector、literals类型,并内置操作和函数 |
|
Voting函数 |
Yes (CC 1.2 or greater) |
No |
|
Atomic函数 |
Yes (CC 1.1 or greater) |
Only as extension |
|
异步内存空间复制和预取函数 |
No |
Yes |
|
支持C++语言功能 |
Yes,受限,但大部分功能都支持 |
No |
- Host 编程
Host端基本是串行的,CUDA和OpenCL的差别主要表现在调用Device的API的差异,所以表 8描述了两者之间API的差异。
表 8 Host端可用的API比较
|
C Runtime for CUDA |
CUDA Driver API |
OpenCL API |
|
Setup |
||
|
Initialize driver Get device(s) (Choose device) Create context |
Initialize plauorm Get devices Choose device Create context Create command queue |
|
|
Device and host memory buffer setup |
||
|
Allocate host memory Allocate device memory for input Copy host memory to device memory Allocate device memory for result |
Allocate host memory Allocate device memory for input Copy host memory to device memory Allocate device memory for result |
Allocate host memory Allocate device memory for input Copy host memory to device memory Allocate device memory for result |
|
Initialize kernel |
||
|
Load kernel module |
Load kernel source |
|
|
Execute the kernel |
||
|
Setup execution configuration |
Setup kernel arguments Setup execution configuration Invoke the kernel |
Setup kernel arguments Setup execution configuration |
|
Copy results to host |
||
|
Copy results from device memory |
Copy results from device memory |
Copy results from device memory |
|
Cleanup |
||
|
Cleanup all set up above |
Cleanup all set up above |
Cleanup all set up above |
4.3 性能
本节根据学术上对CUDA和OpenCL的研究,比较两者的性能,其中本文简单以[1-3]研究成功比较CUDA和OpenCL之间的性能差异,若需详细了解CUDA和OpenCL之间的性能差异可以参考[4-15]。
4.3.1 AES实现
Wang[1]提出一种在XTS模式的AES实现,并对OpenCL和CUDA性能进行比较。如图 22和图 23所示,总体性能CUDA要比OpenCL好10%~20%之间。

图 22 the performance for OpenCL and CUDA in NVIDIA GTX 285

图 23 the runtime for OpenCL and CUDA in NVIDIA GTX 285
4.3.2 三维可视化加速模型
上海理工大学[3]提出合理设计内核函数实现改进的光线投射算法在GPU上并行和并发运行的三维可视化加速模型,该模型实现代码可不用修改在两大主流显卡平台NVIDIA和AMD上任意移植,通过实验证明比较OpenCL与CUDA之间的性能。
表 9 各种实现光线投射算法的三维可视化模型的运行效果对比表

4.3.3 MAGMA和DGEMM算法
作者[2]已经在先前的版本中使用CUDA实现了MAGMA(Matrix Algebra on GPU and multicore architectures)和DGEMM算法,现在将其实现移植到OpenCL API,并对两者的性能进行比较。在NVIDIA处理器上进行测试,其结果是CUDA的性能要高于OpenCL。

图 24 DGEMM performance on Tesla C2050 under OpenCL and CUDA
4.4 总结
CUDA与OpenCL的功能和架构相似,只是CUDA只针对NVIDIA的产品,而OpenCL是一种通用性框架,可以使用多种品牌的产品,所以CUDA的性能一般情况下要比OpenCL的性能要高10%~20%之间。
4.4.1 CUDA与OpenCL的相似点
- 关注数据并行计算模型;
- 将主机和设备的程序和存储分离;
- 提供定制和标准C语言对设备进行编程;
- 设备、执行和存储模型是现类似的;
- OpenCL已经可以在CUDA之上进行实现了。
4.4.2 CUDA和OpenCL主要的差异点
- CUDA是属于NVIDIA公司的技术框架,只有NVIDIA的设备才能执行;
- OpenCL是一个开源的框架,其目标是定位不同的设备;
- CUDA拥有更多的API和帮助文档;
- CUDA投入市场的时间更早,所以得到更多的支持,并且在研究、产品和应用都比OpenCL丰富;
- CUDA有非常多的文档,但也更加模糊。
References
1.Wang, X., et al. AES finalists implementation for GPU and multi-core CPU based on OpenCL. in Anti-Counterfeiting, Security and Identification (ASID), 2011 IEEE International Conference on. 2011: IEEE.
2. Du, P., et al., From CUDA to OpenCL: Towards a performance-portable solution for multi-platform GPU programming. Parallel Computing, 2012. 38(8): p. 391-407.
袁健与高勃, 基于 OpenCL 的三维可视化加速模型. 小型微型计算机系统, 2015. 36(002): 第327-331页.
3. Karimi, K., N.G. Dickson and F. Hamze, A performance comparison of CUDA and OpenCL. arXiv preprint arXiv:1005.2581, 2010.
4. McConnell, S., et al. Scalability of Self-organizing Maps on a GPU cluster using OpenCL and CUDA. in Journal of Physics: Conference Series. 2012: IOP Publishing.
5. Fang, J., A.L. Varbanescu and H. Sips. A comprehensive performance comparison of CUDA and OpenCL. in Parallel Processing (ICPP), 2011 International Conference on. 2011: IEEE.
6. Oliveira, R.S., et al., Comparing CUDA, OpenCL and OpenGL implementations of the cardiac monodomain equations, in Parallel Processing and Applied Mathematics. 2012, Springer. p. 111-120.
7. Harvey, M.J. and G. De Fabritiis, Swan: A tool for porting CUDA programs to OpenCL. Computer Physics Communications, 2011. 182(4): p. 1093-1099.
8. 林乐森, 基于 OpenCL 的 AES 算法并行性分析及加速方案, 2012, 吉林大学.
9. 易卓霖, 基于 GPU 的并行支持向量机的设计与实现, 2011, 西南交通大学.
10. 蒋丽媛等, 基于 OpenCL 的连续数据无关访存密集型函数并行与优化研究. 计算机科学, 2013. 40(3): 第111-115页.
11. 詹云, 赵新灿与谭同德, 基于 OpenCL 的异构系统并行编程. 计算机工程与设计, 2012. 33(11): 第4191-4195页.
12. 王晗, 基于多核环境下的多线程并行程序设计方法研究, 2014, 中原工学院.
13. 黄文慧, 图像处理并行编程方法的研究与应用, 2012, 华南理工大学.
14. 刘寿生, 虚拟现实仿真平台异构并行计算关键技术研究, 2014, 中国海洋大学.
CUDA与OpenCL架构的更多相关文章
- GPU 的硬件基本概念,Cuda和Opencl名词关系对应
GPU 的硬件基本概念 Nvidia的版本: 实际上在 nVidia 的 GPU 里,最基本的处理单元是所谓的 SP(Streaming Processor),而一颗 nVidia 的 GPU 里,会 ...
- 【并行计算-CUDA开发】CUDA编程——GPU架构,由sp,sm,thread,block,grid,warp说起
掌握部分硬件知识,有助于程序员编写更好的CUDA程序,提升CUDA程序性能,本文目的是理清sp,sm,thread,block,grid,warp之间的关系.由于作者能力有限,难免有疏漏,恳请读者批评 ...
- 【并行计算-CUDA开发】从零开始学习OpenCL开发(一)架构
多谢大家关注 转载本文请注明:http://blog.csdn.net/leonwei/article/details/8880012 本文将作为我<从零开始做OpenCL开发>系列文章的 ...
- 从零開始学习OpenCL开发(一)架构
多谢大家关注 转载本文请注明:http://blog.csdn.net/leonwei/article/details/8880012 本文将作为我<从零開始做OpenCL开发>系列文章的 ...
- 从零开始学习OpenCL开发(一)架构
1 异构计算.GPGPU与OpenCL OpenCL是当前一个通用的由很多公司和组织共同发起的多CPU\GPU\其他芯片 异构计算(heterogeneous)的标准,它是跨平台的.旨在充分利用GPU ...
- 从零开始学习OpenCL开发(一)架构【转】
转自:http://blog.csdn.net/leonwei/article/details/8880012 多谢大家关注 转载本文请注明:http://blog.csdn.net/leonwei/ ...
- OpenCV GPU CUDA OpenCL 配置
首先,正确安装OpenCV,并且通过测试. 我理解GPU的环境配置由3个主要步骤构成. 1. 生成关联文件,即makefile或工程文件 2. 编译生成与使用硬件相关的库文件,包括动态.静态库文件. ...
- CUDA编程
目录: 1.什么是CUDA 2.为什么要用到CUDA 3.CUDA环境搭建 4.第一个CUDA程序 5. CUDA编程 5.1. 基本概念 5.2. 线程层次结构 5.3. 存储器层次结构 5.4. ...
- macOS的OpenCL高性能计算
随着深度学习.区块链的发展,人类对计算量的需求越来越高,在传统的计算模式下,压榨GPU的计算能力一直是重点. NV系列的显卡在这方面走的比较快,CUDA框架已经普及到了高性能计算的各个方面,比如Goo ...
随机推荐
- 深入了解Spring Boot 核心注解原理
SpringBoot目前是如火如荼,所以今天就跟大家来探讨下SpringBoot的核心注解@SpringBootApplication以及run方法,理解下springBoot为什么不需要XML,达到 ...
- PAT_A1119 Pre- and Post-order Traversals
Source: PAT A1119 Pre- and Post-order Traversals (30 分) Description: Suppose that all the keys in a ...
- 洛谷P1781 宇宙总统【排序+字符串】
地球历公元6036年,全宇宙准备竞选一个最贤能的人当总统,共有n个非凡拔尖的人竞选总统,现在票数已经统计完毕,请你算出谁能够当上总统. 输入输出格式 输入格式: president.in 第一行为一个 ...
- 渗透实战(周四):CSRF跨站域请求伪造
上图是广东外语外贸大学北校区内MBA中心旁边酒店房间的Wi-Fi网络环境,假设我们的Kali攻击机连入到SSID为414(房间号)的Wi-Fi网络,其IP地址:192.168.43.80 .同一Wi- ...
- form提交表单中包含time类型数据
当数据库和实体类中含有date类型的数据时 ,form提交的时间数据只是string类型的,所以不能直接写入到java实体类和数据库,经过百度找到了解决方法 ,特地挪过来: 在controller中增 ...
- ACdream 1735 输油管道
输油管道 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 262144/131072KB (Java/Others) Problem Des ...
- 敏捷迭代:Sprint燃尽图的7个图形特征及说明的问题
本文写于很多年前(2006),并在很多地方被引用.而现在,笔者对于Sprint燃尽图的理解有了戏剧性的变化--在看到很多团队滥用它之后.笔者不再建议团队做Sprint燃尽图,因为它们不仅不会增加多少有 ...
- POJ 1198/HDU 1401
双向广搜... 呃,双向广搜一般都都用了HASH判重,这样可以更快判断两个方向是否重叠了.这道题用了双向的BFS,有效地减少了状态.但代码太长了,不写,贴一个别人的代码.. #include<i ...
- linux下select,poll,epoll的使用与重点分析
好久没用I/O复用了,感觉差点儿相同都快忘完了.记得当初刚学I/O复用的时候花了好多时间.可是因为那会不太爱写博客,导致花非常多时间搞明确的东西,依旧非常easy忘记.俗话说眼过千遍不如手过一遍,的确 ...
- poj1426--Find The Multiple(广搜,智商题)
Find The Multiple Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 18527 Accepted: 749 ...