web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同。这也是好多同学总是遇到问题的原因。因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标网站加以分析才可以。
今天再介绍一篇关于 web scraper 抓取数据的文章,除了 web scraper 的使用方式外,还包括一些简单的数据处理和分析。都是基础的不能再基础了。
选择这个网站一来是因为作为一个开发者在上面买了不少课,还有个原因就是它的专栏也比较有特点,需要先滚动加载,然后再点击按钮加载。
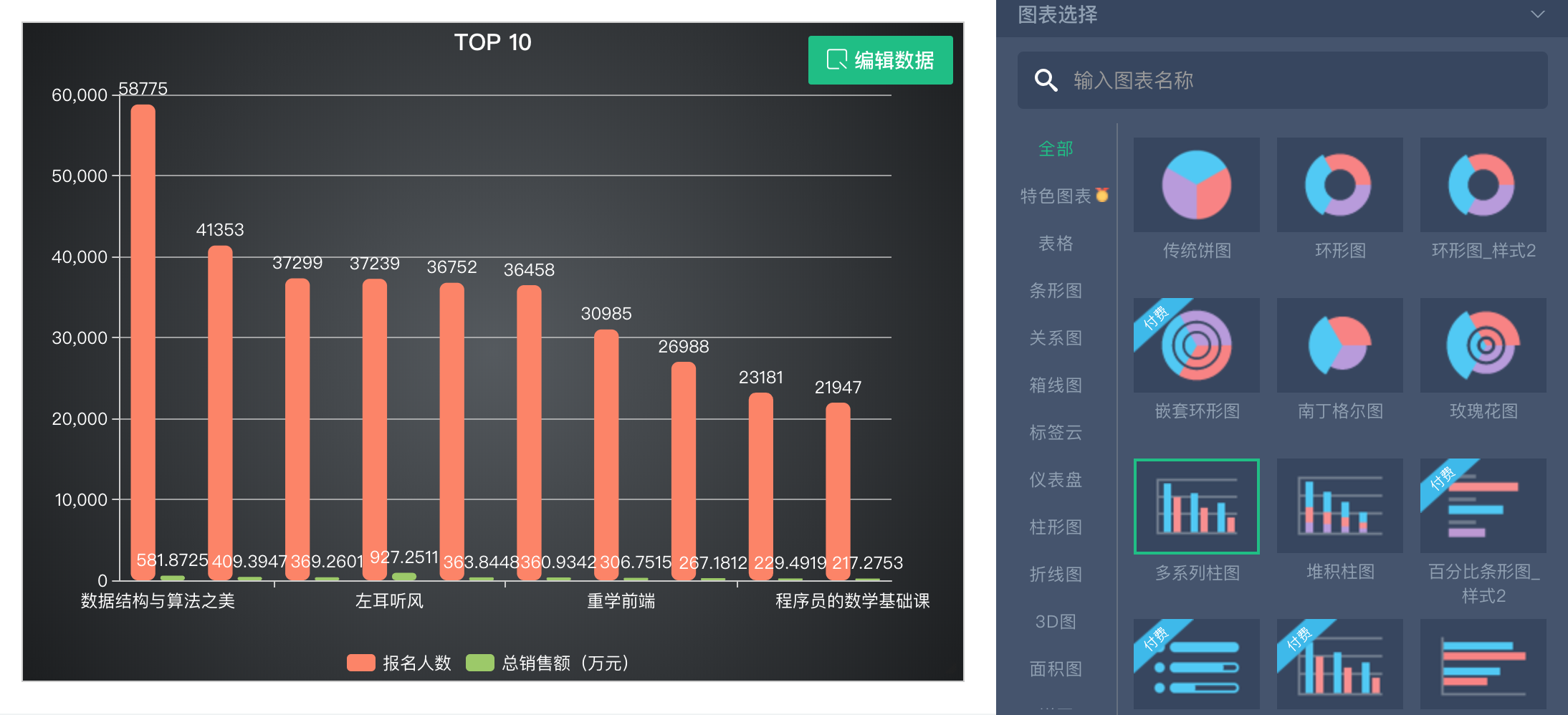
开始正式的数据抓取工作之前,先来看一下我的成果,我把抓取到的90多个专栏的订阅数和销售总价做了一个排序,然后把 TOP 10 拿出来做了一个柱状图出来。

抓取数据
今天要抓的这个网站是一个 IT 知识付费社区,极客时间,应该互联网圈的大多数同学都听说过,我还在上面买了 9 门课,虽然没怎么看过。
极客时间的首页会列出所有网课,和简书首页的加载方式一样,都是先滚动下拉加载,之后变为点击加载更多按钮加载更多。这是一种典型网站加载方式,有好多的网站都是两种方式结合的。这就给我们用 web scraper 抓数据制造了一定的麻烦,不过也很好解决。
1、创建 sitemap,设置 start url 为 https://time.geekbang.org/。
2、创建滚动加载的 Selector,这只是个辅助,帮助我们把页面加载到出现点击加载更多按钮出现,设置如下,注意类型选择 Element scroll down,选择整个课程列表区域作为 Element。
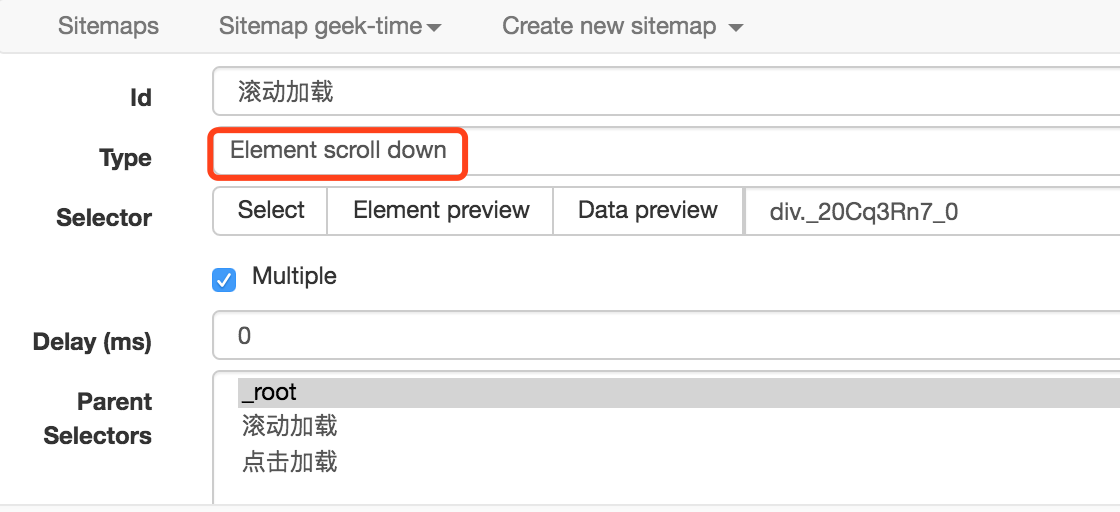
3、创建点击加载更多按钮的 Selector,这个才是真正要抓取内容的 Selector。之后会在它下面创建子选择器。创建之前,需要下拉记载页面,直到出现加载更多按钮。

首先选择元素类型为 Element click 。
Selector 选择整个课程列表,并设置为 Multiple。
Click 选择加载更多按钮,这里需要注意一点,之前的文章里也提到过,这个按钮没办法直接点击选中,因为点击后会触发页面加载动作,所以要勾选 Enable key events,然后按 S 键,来选中这个按钮。
Click type 设置为 Click more 类型。
Click element uniqueness 设置 unique CSS Selector。
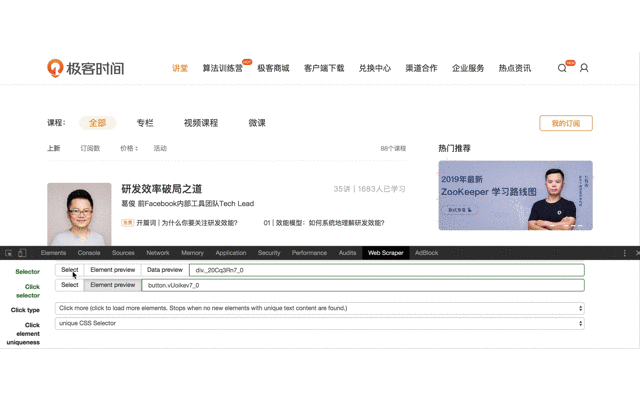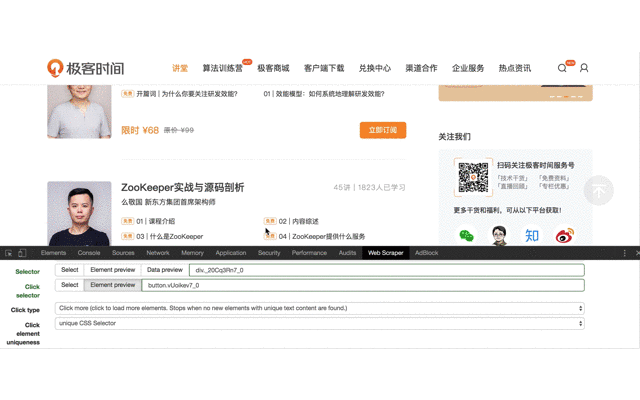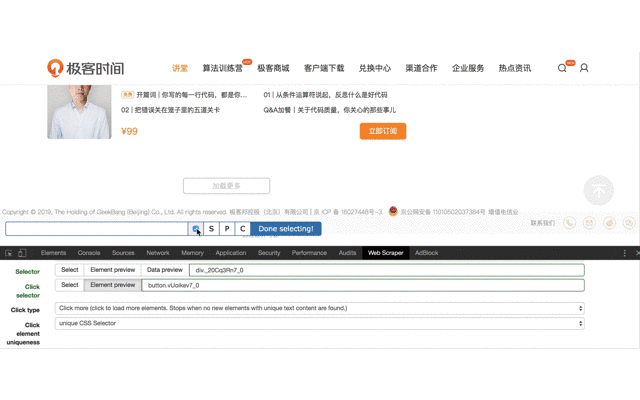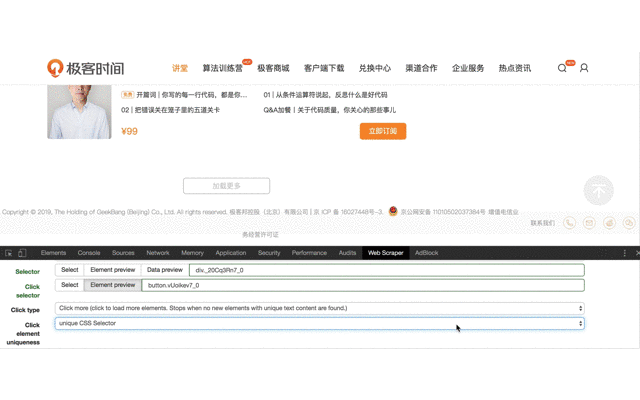
4、进入上一步创建的 Selector ,创建子选择器,用来抓取最终需要的内容。

5、最后运行抓取就可以啦。
数据清洗
这里只是很简单的演示,真正的大数据量的数据清洗工作要费力耗时的多。而且也远不止一个 Excel 能完成的,还需要程序代码的配合,大多数时候还会用到数据库,当然对于比较简单的数据或者没有开发经验的同学来说,用 Excel 也就是最简单省事的选择了。
打开 csv 文件后,第一列信息是 web scraper 自动生成的,直接删掉即可。不知道什么原因,有几条重复数据,第一步,先把重复项去掉,进入 Excel 「数据」选项卡,点击删除重复项即可。
第二步,由于抓下来的课时和报名人数在同一个元素下,没办法在 web scraper 直接放到两个列,所以只能到 Excel 中处理。我的操作思路是这样的,先复制一列出来,然后利用内容替换的方式,将其中一列的报名人数替换成空字符,替换的表达式为 讲 | *人已学习,这样此列就变成了课时列。将另外一列的课时替换为空字符串,先替换 x讲,替换内容为*讲 |,然后再替换人已学习, 那么这列就变成了报名人数列。价格就只保留当前价格,删掉无用列,并且处理掉限时、拼团、¥这些无用字符。
数据分析
因为这里抓取的数据比较简单,也没指望能分析出什么结果。 一共90几门课,也就是分析分析哪门课最受欢迎、价格最高。直接在 Excel 里排个序就好了。然后计算一下几门课程的总价格。
当然真正的商业数据分析不仅仅是一个 Excel 画个图就搞定的事儿。也不是弄两个柱状图就可以的了,一般都需要多个维度、数据关联分析、深度挖掘等。
在 Excel 中做了两个柱状图,分别统计订阅人数前十名和总销售金额的前十名。下面是最后的呈现效果。

如果不想用 Excel, 有一些在线的图表制作网站也可以将 Excel 上传做一些基本的图表,但是灵活性稍微差一点。我用了「图表秀(https://www.tubiaoxiu.com/)」,可以将 Excel 上传,而且还能对 Excel 进行编辑,可以删除列、删除行等操作,这也是相对其他在线图表平台的优势,比如百度的「图说」。下面是我做的一个简单的柱状图,除了柱状图外还支持好多种图表。
以上仅仅是一个业余选手做数据抓取和分析的过程,请酌情参考。
扫描下方二维码,关注公众号:
回复「Excel」获取本例中的 Excel 数据文件。
回复「jike」获取本例中的 sitemap。
不要吝惜你的「推荐」呦
欢迎关注,不定期更新本系列和其他文章
公众号:古时的风筝

相关阅读:
web scraper 抓取数据并做简单数据分析的更多相关文章
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- web scraper 抓取分页数据和二级页面内容
如果是刚接触 web scraper 的,可以看第一篇文章. web scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据. ...
- python 抓取数据,pandas进行数据分析并可视化展示
感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为半桶子水的水平,一直在想写什么,为什么写,怎么写. 直到现在找到了一种好的办法: 1.写什么 自己手上掌握的,工 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
- Web Scraper 翻页——控制链接批量抓取数据
 这是简易数据分析系列的第 5 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
随机推荐
- 总结Idea环境,吐血踩过的坑
1)首先是JDK环境安装,这一步千万要出错,我就是配错了CLASSPATH导致了很诡异的问题.可能结果:就是RUN到tomcat不报错,但是有404错误. 2)然后是IDEA安装,这里要十分注意如果你 ...
- Spring 常犯的十大错误,答应我 打死都不要犯好吗?
1. 错误一:太过关注底层 我们正在解决这个常见错误,是因为 “非我所创” 综合症在软件开发领域很是常见.症状包括经常重写一些常见的代码,很多开发人员都有这种症状. 虽然理解特定库的内部结构及其实现, ...
- Of efficiency and methodology
There are only too many articles and books which pertains to the discussion of efficiency and method ...
- 暴风雨中的 online :.net core 版博客站点遭遇的高并发问题进展
今天暴风雨袭击了杭州,而昨天暴风雨(高并发问题)席卷了园子,留下一片狼藉. 在前天傍晚,我们进行了 .net core 版博客站点的第二次发布尝试,在发布后通过 kestrel 直接监听取代 ngin ...
- CSS3: @font-face 介绍与使用
@font-face 是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中,随着@font-face模块的出现,我们在Web的开发中使用字体不怕只能使用Web安全字体,你们当中或许有 ...
- 全球十大OTA 谁能有一席之地?
全球十大OTA 谁能有一席之地? http://www.traveldaily.cn/article/78381/1 2014-03-05 来源:i黑马 随着旅游行业日新月异的发展,在线旅游网站的出现 ...
- Sql Or NoSql,看完这一篇你就懂了
前言 你是否在为系统的数据库来一波大流量就几乎打满CPU,日常CPU居高不下烦恼?你是否在各种NoSql间纠结不定,到底该选用那种最好?今天的你就是昨天的我,这也是写这篇文章的初衷. 这篇文章是我好几 ...
- Mybatis案例超详解(上)
Mybatis案例超详解(上) 前言: 本来是想像之前一样继续跟新Mybatis,但由于种种原因,迟迟没有更新,快开学了,学了一个暑假,博客也更新了不少,我觉得我得缓缓,先整合一些案例练练,等我再成熟 ...
- Vector使用方法简单整理
使用vector,需要引用vector库: #include<vector> 首先,创建一个可以容纳int的vector变量——arr: vector<int> arr; 接着 ...
- 深入剖析PHP7内核源码(一)- PHP架构与生命周期
PHP7 为什么这么快? 全新的zval 更节约的空间,栈上分配内存 zend_string 存储字符串的Hash值,数组查询的时候不需要进行Hash计算 在HashTable桶内直接存数据,减少了内 ...