kafka经典入门
| 问题导读
1.Kafka独特设计在什么地方?
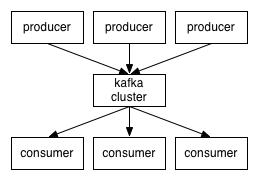
一、基本概念 介绍 Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。 这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语:
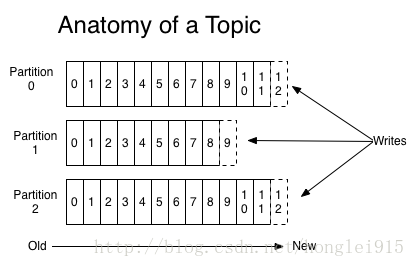
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。 Topics 和Logs 先来看一下Kafka提供的一个抽象概念:topic. 每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。 实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。 以上特点的结合,使Kafka consumers非常的轻量级:它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。 将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。 分布式 每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。 Producers Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。 Consumers 发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
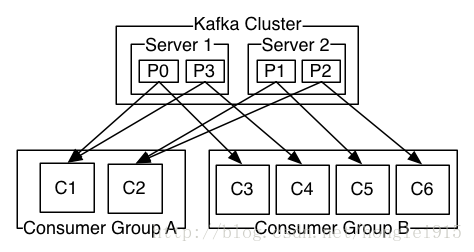
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumerB组有4个 相比传统的消息系统,Kafka可以很好的保证有序性。 在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。 Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。 ########################################### 二、环境搭建 Step 1: 下载Kafka 点击下载最新的版本并解压.
复制代码 Step 2: 启动服务 Kafka用到了Zookeeper,所有首先启动Zookper,下面简单的启用一个单实例的Zookkeeper服务。可以在命令的结尾加个&符号,这样就可以启动后离开控制台。
复制代码 现在启动Kafka:
复制代码 Step 3: 创建 topic 创建一个叫做“test”的topic,它只有一个分区,一个副本。
复制代码 可以通过list命令查看创建的topic:
复制代码 除了手动创建topic,还可以配置broker让它自动创建topic. Step 4:发送消息. Kafka 使用一个简单的命令行producer,从文件中或者从标准输入中读取消息并发送到服务端。默认的每条命令将发送一条消息。 运行producer并在控制台中输一些消息,这些消息将被发送到服务端:
复制代码 ctrl+c可以退出发送。 Step 5: 启动consumer Kafka also has a command line consumer that will dump out messages to standard output.
复制代码 你在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息。 Step 6: 搭建一个多个broker的集群 刚才只是启动了单个broker,现在启动有3个broker组成的集群,这些broker节点也都是在本机上的:
复制代码 在拷贝出的新文件中添加以下参数:
复制代码
复制代码 broker.id在集群中唯一的标注一个节点,因为在同一个机器上,所以必须制定不同的端口和日志文件,避免数据被覆盖。 We already have Zookeeper and our single node started, so we just need to start the two new nodes:
复制代码 创建一个拥有3个副本的topic:
复制代码 现在我们搭建了一个集群,怎么知道每个节点的信息呢?运行“"describe topics”命令就可以了:
复制代码
复制代码 下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
复制代码
复制代码 消费这些消息:
复制代码
复制代码 测试一下容错能力.Broker 1作为leader运行,现在我们kill掉它:
复制代码 另外一个节点被选做了leader,node 1 不再出现在 in-sync 副本列表中:
复制代码 虽然最初负责续写消息的leader down掉了,但之前的消息还是可以消费的:
复制代码 看来Kafka的容错机制还是不错的。 ################################################ 三、搭建Kafka开发环境 我们搭建了kafka的服务器,并可以使用Kafka的命令行工具创建topic,发送和接收消息。下面我们来搭建kafka的开发环境。 搭建开发环境需要引入kafka的jar包,一种方式是将Kafka安装包中lib下的jar包加入到项目的classpath中,这种比较简单了。不过我们使用另一种更加流行的方式:使用maven管理jar包依赖。
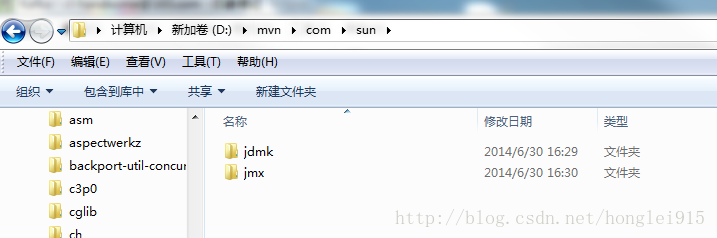
复制代码 添加依赖后你会发现有两个jar包的依赖找不到。没关系我都帮你想好了,点击这里下载这两个jar包,解压后你有两种选择,第一种是使用mvn的install命令将jar包安装到本地仓库,另一种是直接将解压后的文件夹拷贝到mvn本地仓库的com文件夹下,比如我的本地仓库是d:\mvn,完成后我的目录结构是这样的:
配置程序 首先是一个充当配置文件作用的接口,配置了Kafka的各种连接参数:
复制代码 producer
复制代码 consumer
复制代码 简单的发送接收 运行下面这个程序,就可以进行简单的发送接收消息了:
复制代码 高级别的consumer 下面是比较负载的发送接收的程序:
复制代码 ############################################################ 四、数据持久化 不要畏惧文件系统! Kafka大量依赖文件系统去存储和缓存消息。对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能。实际上硬盘的快慢完全取决于使用它的方式。设计良好的硬盘架构可以和内存一样快。 在6块7200转的SATA RAID-5磁盘阵列的线性写速度差不多是600MB/s,但是随即写的速度却是100k/s,差了差不多6000倍。现代的操作系统都对次做了大量的优化,使用了 read-ahead 和 write-behind的技巧,读取的时候成块的预读取数据,写的时候将各种微小琐碎的逻辑写入组织合并成一次较大的物理写入。对此的深入讨论可以查看这里,它们发现线性的访问磁盘,很多时候比随机的内存访问快得多。 为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,现代操作系统乐于把所有空闲内存用作磁盘缓存,虽然这可能在缓存回收和重新分配时牺牲一些性能。所有的磁盘读写操作都会经过这个缓存,这不太可能被绕开除非直接使用I/O。所以虽然每个程序都在自己的线程里只缓存了一份数据,但在操作系统的缓存里还有一份,这等于存了两份数据。 另外再来讨论一下JVM,以下两个事实是众所周知的: •Java对象占用空间是非常大的,差不多是要存储的数据的两倍甚至更高。 •随着堆中数据量的增加,垃圾回收回变的越来越困难。 基于以上分析,如果把数据缓存在内存里,因为需要存储两份,不得不使用两倍的内存空间,Kafka基于JVM,又不得不将空间再次加倍,再加上要避免GC带来的性能影响,在一个32G内存的机器上,不得不使用到28-30G的内存空间。并且当系统重启的时候,又必须要将数据刷到内存中( 10GB 内存差不多要用10分钟),就算使用冷刷新(不是一次性刷进内存,而是在使用数据的时候没有就刷到内存)也会导致最初的时候新能非常慢。但是使用文件系统,即使系统重启了,也不需要刷新数据。使用文件系统也简化了维护数据一致性的逻辑。 所以与传统的将数据缓存在内存中然后刷到硬盘的设计不同,Kafka直接将数据写到了文件系统的日志中。 常量时间的操作效率 在大多数的消息系统中,数据持久化的机制往往是为每个cosumer提供一个B树或者其他的随机读写的数据结构。B树当然是很棒的,但是也带了一些代价:比如B树的复杂度是O(log N),O(log N)通常被认为就是常量复杂度了,但对于硬盘操作来说并非如此。磁盘进行一次搜索需要10ms,每个硬盘在同一时间只能进行一次搜索,这样并发处理就成了问题。虽然存储系统使用缓存进行了大量优化,但是对于树结构的性能的观察结果却表明,它的性能往往随着数据的增长而线性下降,数据增长一倍,速度就会降低一倍。 直观的讲,对于主要用于日志处理的消息系统,数据的持久化可以简单的通过将数据追加到文件中实现,读的时候从文件中读就好了。这样做的好处是读和写都是 O(1) 的,并且读操作不会阻塞写操作和其他操作。这样带来的性能优势是很明显的,因为性能和数据的大小没有关系了。 既然可以使用几乎没有容量限制(相对于内存来说)的硬盘空间建立消息系统,就可以在没有性能损失的情况下提供一些一般消息系统不具备的特性。比如,一般的消息系统都是在消息被消费后立即删除,Kafka却可以将消息保存一段时间(比如一星期),这给consumer提供了很好的机动性和灵活性,这点在今后的文章中会有详述。 ############################################################ 五、消息传输的事务定义 之前讨论了consumer和producer是怎么工作的,现在来讨论一下数据传输方面。数据传输的事务定义通常有以下三种级别:
大多数消息系统声称可以做到“精确的一次”,但是仔细阅读它们的的文档可以看到里面存在误导,比如没有说明当consumer或producer失败时怎么样,或者当有多个consumer并行时怎么样,或写入硬盘的数据丢失时又会怎么样。kafka的做法要更先进一些。当发布消息时,Kafka有一个“committed”的概念,一旦消息被提交了,只要消息被写入的分区的所在的副本broker是活动的,数据就不会丢失。关于副本的活动的概念,下节文档会讨论。现在假设broker是不会down的。 如果producer发布消息时发生了网络错误,但又不确定实在提交之前发生的还是提交之后发生的,这种情况虽然不常见,但是必须考虑进去,现在Kafka版本还没有解决这个问题,将来的版本正在努力尝试解决。 并不是所有的情况都需要“精确的一次”这样高的级别,Kafka允许producer灵活的指定级别。比如producer可以指定必须等待消息被提交的通知,或者完全的异步发送消息而不等待任何通知,或者仅仅等待leader声明它拿到了消息(followers没有必要)。 现在从consumer的方面考虑这个问题,所有的副本都有相同的日志文件和相同的offset,consumer维护自己消费的消息的offset,如果consumer不会崩溃当然可以在内存中保存这个值,当然谁也不能保证这点。如果consumer崩溃了,会有另外一个consumer接着消费消息,它需要从一个合适的offset继续处理。这种情况下可以有以下选择:
############################################################ 六、性能优化 Kafka在提高效率方面做了很大努力。Kafka的一个主要使用场景是处理网站活动日志,吞吐量是非常大的,每个页面都会产生好多次写操作。读方面,假设每个消息只被消费一次,读的量的也是很大的,Kafka也尽量使读的操作更轻量化。 我们之前讨论了磁盘的性能问题,线性读写的情况下影响磁盘性能问题大约有两个方面:太多的琐碎的I/O操作和太多的字节拷贝。I/O问题发生在客户端和服务端之间,也发生在服务端内部的持久化的操作中。 消息集(message set) 另外一个性能优化是在字节拷贝方面。在低负载的情况下这不是问题,但是在高负载的情况下它的影响还是很大的。为了避免这个问题,Kafka使用了标准的二进制消息格式,这个格式可以在producer,broker和producer之间共享而无需做任何改动。 zero copy 为了更好的理解sendfile的好处,我们先来看下一般将数据从文件发送到socket的数据流向:
这显然是低效率的,有4次拷贝和2次系统调用。Sendfile通过直接将数据从页面缓存发送网卡接口缓存,避免了重复拷贝,大大的优化了性能。 数据压缩 ########################################################## 七、Producer和Consumer Kafka Producer消息发送 客户端控制消息将被分发到哪个分区。可以通过负载均衡随机的选择,或者使用分区函数。Kafka允许用户实现分区函数,指定分区的key,将消息hash到不同的分区上(当然有需要的话,也可以覆盖这个分区函数自己实现逻辑).比如如果你指定的key是user id,那么同一个用户发送的消息都被发送到同一个分区上。经过分区之后,consumer就可以有目的的消费某个分区的消息。 异步发送 既然缓存是在producer端进行的,那么当producer崩溃时,这些消息就会丢失。Kafka0.8.1的异步发送模式还不支持回调,就不能在发送出错时进行处理。Kafka 0.9可能会增加这样的回调函数。见Proposed Producer API. Kafka Consumer 推还是拉? 一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式。 Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略。 Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发送)。 消费状态跟踪 但是这样会不会有什么问题呢?如果一条消息发送出去之后就立即被标记为消费过的,一旦consumer处理消息时失败了(比如程序崩溃)消息就丢失了。为了解决这个问题,很多消息系统提供了另外一个个功能:当消息被发送出去之后仅仅被标记为已发送状态,当接到consumer已经消费成功的通知后才标记为已被消费的状态。这虽然解决了消息丢失的问题,但产生了新问题,首先如果consumer处理消息成功了但是向broker发送响应时失败了,这条消息将被消费两次。第二个问题时,broker必须维护每条消息的状态,并且每次都要先锁住消息然后更改状态然后释放锁。这样麻烦又来了,且不说要维护大量的状态数据,比如如果消息发送出去但没有收到消费成功的通知,这条消息将一直处于被锁定的状态, 这带来了另外一个好处:consumer可以把offset调成一个较老的值,去重新消费老的消息。这对传统的消息系统来说看起来有些不可思议,但确实是非常有用的,谁规定了一条消息只能被消费一次呢?consumer发现解析数据的程序有bug,在修改bug后再来解析一次消息,看起来是很合理的额呀! 离线处理消息 ######################################################### 八、主从同步 Kafka允许topic的分区拥有若干副本,这个数量是可以配置的,你可以为每个topci配置副本的数量。Kafka会自动在每个个副本上备份数据,所以当一个节点down掉时数据依然是可用的。 Kafka的副本功能不是必须的,你可以配置只有一个副本,这样其实就相当于只有一份数据。 许多分布式的消息系统自动的处理失败的请求,它们对一个节点是否 着(alive)”有着清晰的定义。Kafka判断一个节点是否活着有两个条件:
符合以上条件的节点准确的说应该是“同步中的(in sync)”,而不是模糊的说是“活着的”或是“失败的”。Leader会追踪所有“同步中”的节点,一旦一个down掉了,或是卡住了,或是延时太久,leader就会把它移除。至于延时多久算是“太久”,是由参数replica.lag.max.messages决定的,怎样算是卡住了,怎是由参数replica.lag.time.max.ms决定的。 只有当消息被所有的副本加入到日志中时,才算是“committed”,只有committed的消息才会发送给consumer,这样就不用担心一旦leader down掉了消息会丢失。Producer也可以选择是否等待消息被提交的通知,这个是由参数request.required.acks决定的。 Leader的选择 如果leaders永远不会down的话我们就不需要followers了!一旦leader down掉了,需要在followers中选择一个新的leader.但是followers本身有可能延时太久或者crash,所以必须选择高质量的follower作为leader.必须保证,一旦一个消息被提交了,但是leader down掉了,新选出的leader必须可以提供这条消息。大部分的分布式系统采用了多数投票法则选择新的leader,对于多数投票法则,就是根据所有副本节点的状况动态的选择最适合的作为leader.Kafka并不是使用这种方法。 Kafaka动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中了,才回通知外部这个消息已经被提交了。因此这个集合中的任何一个节点随时都可以被选为leader.ISR在ZooKeeper中维护。ISR中有f+1个节点,就可以允许在f个节点down掉的情况下不会丢失消息并正常提供服。ISR的成员是动态的,如果一个节点被淘汰了,当它重新达到“同步中”的状态时,他可以重新加入ISR.这种leader的选择方式是非常快速的,适合kafka的应用场景。 一个邪恶的想法:如果所有节点都down掉了怎么办?Kafka对于数据不会丢失的保证,是基于至少一个节点是存活的,一旦所有节点都down了,这个就不能保证了。
这是一个在可用性和连续性之间的权衡。如果等待ISR中的节点恢复,一旦ISR中的节点起不起来或者数据都是了,那集群就永远恢复不了了。如果等待ISR意外的节点恢复,这个节点的数据就会被作为线上数据,有可能和真实的数据有所出入,因为有些数据它可能还没同步到。Kafka目前选择了第二种策略,在未来的版本中将使这个策略的选择可配置,可以根据场景灵活的选择。 副本管理 ################################################### 九、客户端API Kafka Producer APIs
复制代码 Producer API提供了以下功能:
KafKa Consumer APIs Consumer API有两个级别。低级别的和一个指定的broker保持连接,并在接收完消息后关闭连接,这个级别是无状态的,每次读取消息都带着offset。 低级别的API
复制代码 低级别的API是高级别API实现的基础,也是为了一些对维持消费状态有特殊需求的场景,比如Hadoop consumer这样的离线consumer。 高级别的API
复制代码 这个API围绕着由KafkaStream实现的迭代器展开,每个流代表一系列从一个或多个分区多和broker上汇聚来的消息,每个流由一个线程处理,所以客户端可以在创建的时候通过参数指定想要几个流。一个流是多个分区多个broker的合并,但是每个分区的消息只会流向一个流。 每调用一次createMessageStreams都会将consumer注册到topic上,这样consumer和brokers之间的负载均衡就会进行调整。API鼓励每次调用创建更多的topic流以减少这种调整。createMessageStreamsByFilter方法注册监听可以感知新的符合filter的tipic。 ####################################################### 十、消息和日志 消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和CRC32校验码。
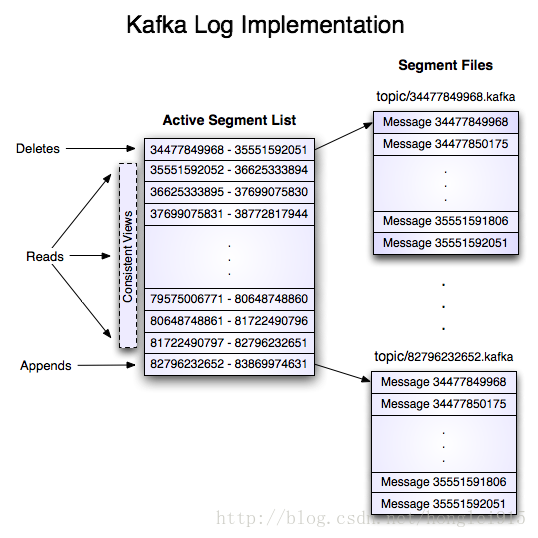
复制代码 日志一个叫做“my_topic”且有两个分区的的topic,它的日志有两个文件夹组成,my_topic_0和my_topic_1,每个文件夹里放着具体的数据文件,每个数据文件都是一系列的日志实体,每个日志实体有一个4个字节的整数N标注消息的长度,后边跟着N个字节的消息。每个消息都可以由一个64位的整数offset标注,offset标注了这条消息在发送到这个分区的消息流中的起始位置。每个日志文件的名称都是这个文件第一条日志的offset.所以第一个日志文件的名字就是00000000000.kafka.所以每相邻的两个文件名字的差就是一个数字S,S差不多就是配置文件中指定的日志文件的最大容量。
写操作消息被不断的追加到最后一个日志的末尾,当日志的大小达到一个指定的值时就会产生一个新的文件。对于写操作有两个参数,一个规定了消息的数量达到这个值时必须将数据刷新到硬盘上,另外一个规定了刷新到硬盘的时间间隔,这对数据的持久性是个保证,在系统崩溃的时候只会丢失一定数量的消息或者一个时间段的消息。 读操作 下面是发送给consumer的结果的格式:
复制代码 删除 可靠性保证 |

转自:http://www.aboutyun.com/thread-12882-1-1.html
kafka经典入门的更多相关文章
- 《javascript经典入门》-day02
<javascript经典入门>-day02 1.使用函数 1.1基本语法 function sayHello() { aler('Hello'); //...其他语句... } #关于函 ...
- 《javascript经典入门》-day01
<javascript经典入门>-day01 1.了解JavaScript 01.浏览器每次加载和显示页面时,都在内存里创建页面及其全部元素的一个内部表示体系,,也就是DOM.在DOM里, ...
- 【转】kafka概念入门[一]
转载的,原文:http://www.cnblogs.com/intsmaze/p/6386616.html ---------------------------------------------- ...
- docker安装kafka快速入门
docker安装kafka快速入门 1.安装zookeeper docker search zookeeperdocker pull zookeeperdocker run -d -v /home/s ...
- Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接. Kafka从入门到放弃(一) -- 初识别Kafka 消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者. ...
- Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者. 之前没看得可以点击链接阅读. Kafka从入门到放弃(一) -- 初识Kafka Kafka从入门到放弃(二) -- 详说生 ...
- Kafka经典三大问:数据有序丢失重复
Kafka经典三大问:数据有序丢失重复 在kafka中有三个经典的问题: 如何保证数据有序性 如何解决数据丢失问题 如何处理数据重复消费 这些不光是面试常客,更是日常使用过程中会遇到的几个问题,下面分 ...
- kafka从入门到了解
kafka从入门到了解 一.什么是kafka Apache Kafka是Apache软件基金会的开源的流处理平台,该平台提供了消息的订阅与发布的消息队列,一般用作系统间解耦.异步通信.削峰填谷等作用. ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
随机推荐
- Multiple dex files define Lokhttp3/internal/wsWebSocketProtocol
Multiple dex files define Lokhttp3/internal/wsWebSocketProtocol 老套路,先晒图 图一:如题,在编译打包时遇到了如上错误,很明显这是一个依 ...
- java读取本机磁盘及遍历磁盘文件
1. 获取本机所有盘符信息 //1. 获取本机盘符 File[] roots = File.listRoots(); for (int i = 0; i < roots.length; i++) ...
- Golang 解决 Iris 被墙的依赖包
使用 Golang 的 Iris web 框架时,用 go get github.com/kataras/iris 命令久久无法下载,最后还报一堆错误. 使用 GOPROXY 可解决问题,也可参考如 ...
- 阿里巴巴JAVA开发规范学习笔记
一.编程规约 (一)命名规约 1.类名驼峰.领域模型除外VO.BO.DTO.DO统称POJO 4.数组String[] args 8.枚举类 Enum ,其实就是特殊的常量类,构造方法强制私有 ( 二 ...
- 从零写一个编译器(九):语义分析之构造抽象语法树(AST)
项目的完整代码在 C2j-Compiler 前言 在上一篇完成了符号表的构建,下一步就是输出抽象语法树(Abstract Syntax Tree,AST) 抽象语法树(abstract syntax ...
- ServerResponse(服务器统一响应数据格式)
ServerResponse(服务器统一响应数据格式) 前言: 其实严格来说,ServerResponse应该归类到common包中.但是我实在太喜欢这玩意儿了.而且用得也非常频繁,所以忍不住推荐一下 ...
- python + selenium webdriver 复合型css样式的元素定位方法
<div class="header layout clearfix"></div> 当元素没有id,没有name,没有任何,只有一个class的时候,应该 ...
- Go组件学习——database/sql数据库连接池你用对了吗
1.案例 case1: maxOpenConns > 1 func fewConns() { db, _ := db.Open("mysql", "root:roo ...
- INSERT: 批量插入结果集方式
INSERT: 批量插入结果集 insert into table select x,y from A UNION select z,k from B ; insert into table sele ...
- 持续集成高级篇之Jekins参数化构建(二)
系列目录 上一节我们讲解了如何使用bat脚本或者powershell脚本自身的机制来达到参数化构建的目的,这在一定程序上增加了灵活性,然而缺点也相当明显:它只能适应一些相对比较固定的参数传入(比如像上 ...