Python只读取文本中文字符
#coding=utf-8
import re with open('aaa.txt','r',encoding="utf-8") as f:
#data = f.read().decode('gbk').encode('utf-8')
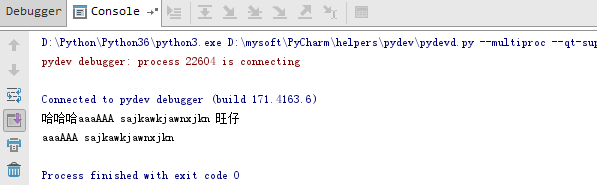
data = f.read()
print(data)
#str = re.sub(r'(\\u\d+)',"",data)
#data = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", data)
#data = re.sub('[\W_+]', "", data)
data = re.sub('[\u4E00-\u9FA5]',"", data)
print(data)
#过滤掉除了中文以外的字符
import re """
python 3.5版本
正则匹配中文,固定形式:\u4E00-\u9FA5
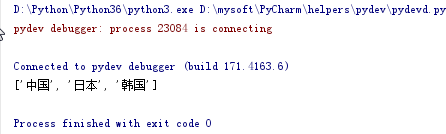
""" text = "aqweded***中国***xsa***日本***韩国"
regStr = ".*?([\u4E00-\u9FA5]+).*?"
aa = re.findall(regStr, text)
if aa:
print(aa)
#提取字符串里的中文,返回数组
#coding=utf-8
import re with open('aaa.txt','r',encoding="utf-8") as f:
#data = f.read().decode('gbk').encode('utf-8')
data = f.read()
print(data)
data = re.sub("[A-Za-z0-9\!\%\[\]\,\。\ ]", "", data)
#data = re.sub('[\u4E00-\u9FA5]',"", data)
print(data)

# -*- coding: utf-8 -*-
import re
#过滤掉除了中文以外的字符
str = "hello,world!!%[545]你好234世界。。。"
str = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", str)
print(str)
#提取字符串里的中文,返回数组
pattern="[\u4e00-\u9fa5]+"
regex = re.compile(pattern)
results = regex.findall("adf中文adf发京东方")
print(results)
Python只读取文本中文字符的更多相关文章
- python匹配某个中文字符
python2.7对中文的支持不好是众所周知的,现在遇到这样一个需求,要匹配某个中文字符.查了一个资料,思路就是转化为unicode进行比较,记录如下: line = '参考答案: A' # gbk ...
- python json.dumps 中文字符乱码
场景:微信公众号推送消息,中文乱码. Date:2017-05-11 10:58:40.033000,\u4f60\u597d 解决方法: python dumps默认使用的ascii编码 ...
- python正则匹配——中文字符的匹配
# -*- coding:utf-8 -*- import re '''python 3.5版本 正则匹配中文,固定形式:\u4E00-\u9FA5 ''' words = 'study in 山海大 ...
- python随机生成中文字符
第一种方法:Unicode码 在unicode码中,汉字的范围是(0x4E00, 9FBF) import random def Unicode(): val = random.randint(0x4 ...
- Python中文字符问题
Python中对中文字符的操作时常会使程序出现乱码 不全然管用的处理方法: 读取数据时使用encode编码为Bytes以保护数据 使用时转化为string并使用decode解码 如: title = ...
- Python: 在CSV文件中写入中文字符
0.2 2016.09.26 11:28* 字数 216 阅读 8053评论 2喜欢 5 最近一段时间的学习中发现,Python基本和中文字符杠上了.如果能把各种编码问题解决了,基本上也算对Pytho ...
- python中文字符乱码(GB2312,GBK,GB18030相关的问题)
转自博主 crifan http://againinput4.blog.163.com/blog/static/1727994912011111011432810/ 在玩wordpress的一个博客搬 ...
- Python中文字符的理解:str()、repr()、print
Python中文字符的理解:str().repr().print 字数1384 阅读4 评论0 喜欢0 都说Python人不把文字编码这块从头到尾.从古至今全研究通透的话是完全玩不转的.我终于深刻的理 ...
- python 连接数据库-设置oracle ,mysql 中文字符问题
import cx_Oracle import MySQLdb def conn_oracle(): cnn = cx_Oracle.connect('用户名','密码','ip:端口号/数据库') ...
随机推荐
- SpringCloud之Spring Cloud Stream:消息驱动
Spring Cloud Stream 是一个构建消息驱动微服务的框架,该框架在Spring Boot的基础上整合了Spring Integrationg来连接消息代理中间件(RabbitMQ, Ka ...
- CodeForces - 519D(思维+前缀和)
题意 https://vjudge.net/problem/CodeForces-519D 给定每个小写字母一个数值,给定一个只包含小写字母的字符串 s,求 s 的子串 t 个数,使 t满足: 首位字 ...
- Mac上打开终端的7种简单方法
终端机是用于给Mac命令的便捷工具,尽管它可能会吓倒许多人.毕竟,这不像输入句子然后Mac响应那样简单.如果您有兴趣学习使用Terminal或只想输入一两个命令,我们在下面列出了一些文章,可以帮助您使 ...
- 【zabbix告警监控】配置zabbix监控nginx服务
zabbix监控nginx,nginx需要添加--with-http_stub_status模块 使用zabbix监控nginx,首先nginx需要配置开启ngx_status.但是我这边nginx安 ...
- 灵魂拷问:创建 Java 字符串,用""还是构造函数
在逛 programcreek 的时候,我发现了一些小而精悍的主题.比如说:创建 Java 字符串,用 "" 还是构造函数?像这类灵魂拷问的主题,非常值得深入地研究一下. 01.& ...
- RocketMq在SparkStreaming中的应用总结
其实Rocketmq的给第三方的插件已经全了,如果大家有兴趣的话请移步https://github.com/apache/rocketmq-externals.本文主要是结合笔者已有的rmq在spar ...
- SourceTree Mac安装跳过注册步骤
1.打开sourcetree2.关闭sourcetree3.命令终端输入defaults write com.torusknot.SourceTreeNotMAS completedWelcomeWi ...
- pycharm报错:Process finished with exit code -1073741819 (0xC0000005)解决办法
这个是几个月前的问题了,有小伙伴在CSDN问我咋解决的,那我今天在这边把这个问题解决办法分享下吧,免得大家把很多时间都浪费在安装排坑上面,有些坑虽然解决了还真不知道啥原因. 我的pycharm一直用的 ...
- Reinforcement Learning by Sutton 第三章习题答案
好不容易写完了 想看全部的欢迎点击下面的github https://github.com/LyWangPX/Solutions-of-Reinforcement-Learning-An-Introd ...
- log4j日志打印的配置文件简单使用
log4j.properties #将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义在下面的代码 log4j.rootLogger=DEBUG,c ...