Python爬虫实战教程:爬取网易新闻
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Amauri
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
此文属于入门级级别的爬虫,老司机们就不用看了。
本次主要是爬取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选的分类是国内新闻。然后鼠标右键点击查看源代码,发现源代码中并没有页面正中的新闻列表。这说明此网页采用的是异步的方式。也就是通过api接口获取的数据。
那么确认了之后可以使用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现了:"... special/00804KVA/cm_guonei_03.js? .... "之类的地址,点开Response发现正是我们要找的api接口。 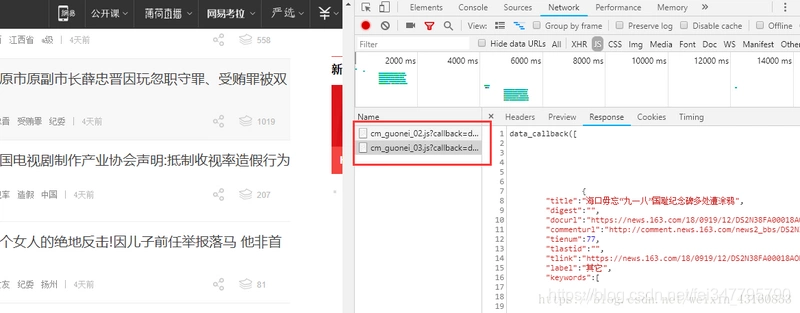
可以看到这些接口的地址都有一定的规律:“cm_guonei_03.js”、 “cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的连接也就是我们本次抓取所要请求的地址。
接下来只需要用到的python的两个库:
requests
json
BeautifulSoup
requests库就是用来进行网络请求的,说白了就是模拟浏览器来获取资源。
由于我们采集的是api接口,它的格式为json,所以要用到json库来解析。BeautifulSoup是用来解析html文档的,可以很方便的帮我们获取指定div的内容。
下面开始编写我们爬虫:
第一步先导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
接着我们定义一个获取指定页码内数据的方法:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样子就得到每个页码对应的内容列表:
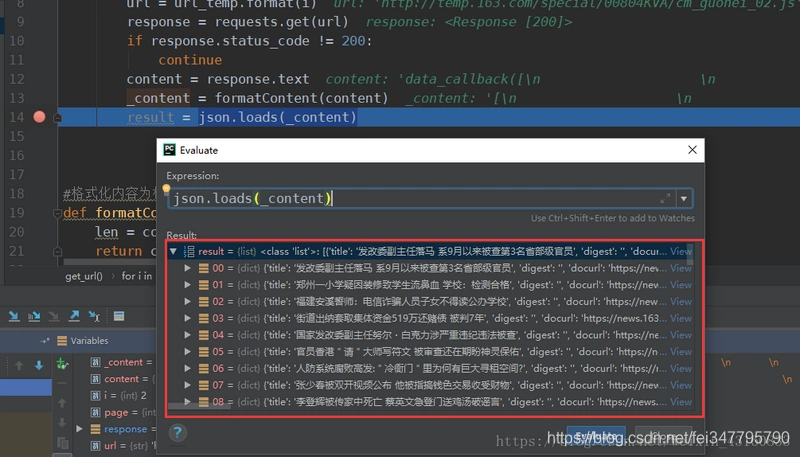
之后通过分析数据可知下图圈出来的则是需要抓取的标题、发布时间以及新闻内容页面。
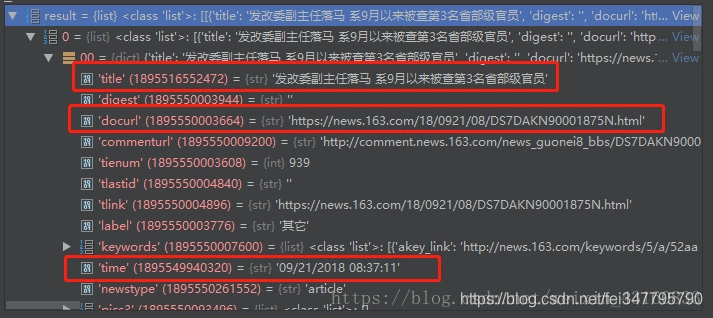
既然现在已经获取到了内容页的url,那么接下来开始抓取新闻正文。
在抓取正文之前要先分析一下正文的html页面,找到正文、作者、来源在html文档中的位置。
我们看到文章来源在文档中的位置为:id = "ne_article_source" 的 a 标签。 作者位置为:class = "ep-editor" 的 span 标签。 正文位置为:class = "post_text" 的 div 标签。
下面试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到此为止我们所要抓取的所有数据都已经采集了。
那么接下来当然是把它们保存下来,为了方便我直接采取文本的形式来保存。下面是最终的结果:

格式为json字符串,“标题” : [ ‘日期’, ‘url’, ‘来源’, ‘作者’, ‘正文’ ]。
要注意的是目前实现的方式是完全同步的,线性的方式,存在的问题就是采集会非常慢。主要延迟是在网络IO上,可以升级为异步IO,异步采集。
Python爬虫实战教程:爬取网易新闻的更多相关文章
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python 爬虫实战1 爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 抓取糗事百科热门段子 过滤带有图片的段子 实现每按一次回车显示一个段子的发布时间,发布人 ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- python 爬虫实战4 爬取淘宝MM照片
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http:/ ...
- 芝麻HTTP:Python爬虫实战之爬取百度贴吧帖子
本篇目标 1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定 首先,我们先观察一下百度贴吧的任意一个帖子. 比如:http:// ...
随机推荐
- 【AHOI 2013】差异
Problem Description 给定一个长度为 \(n\) 的字符串 \(S\),令 \(T_i\) 表示它从第 \(i\) 个字符开始的后缀.求 \(\sum_{1\leqslant i&l ...
- GeoServer 2.15.0版本跨域问题解决方法
geoserver默认不开启跨域设置,开启步骤如下: 1.修改配置文件web.xml,该配置文件的路径如下 \webapps\geoserver\WEB-INF\web.xml 2.搜索:cross- ...
- js实现弹出框跟随鼠标移动
又是新的一天网上冲浪,在bing的搜索页面下看到这样一个效果: 即弹出框随着鼠标的移动而移动.思路大概为: 调用onmousemove函数,将鼠标的当前位置赋予弹出框即可 //html <div ...
- 【戾气满满】Ubuntu 18.04使用QT通过FreeTDS+unixODBC连接MSSQL填坑记(含泪亲测可用)
前言 照例废话几句,想玩下QT,但是学习吧总得想点事情做啊,单纯学习语法用法这些?反正我是学不下去的,脑袋一拍,就先学下怎么连接数据库吧!然而万万没想到,我这是给自己挖了一个深深的坑啊! 学习自然去官 ...
- vue中监听路由参数的变化
在vue项目中,假使我们在同一个路由下,只是改变路由后面的参数值,期望达到数据的更新. mounted: () =>{ this.id = this.$route.query.id; this. ...
- CVE-2019-0708漏洞复现
前言: 该漏洞前段时间已经热闹了好一阵子了,HW期间更是使用此漏洞来进行钓鱼等一系列活动,可为大家也是对此漏洞的关心程度,接下里就简单的演示下利用此漏洞进行DOS攻击.当然还有RCE的操作,这只演示下 ...
- Hyper-V “SP2019SER”无法更改状态。操作失败,错误代码为“32788”。
卸载Hyper-V,然后重装,再重启已有的Hyper-V服务器,报错如下: 尝试启动选定的虚拟机时出错.“SP2019SER”无法更改状态. 原因:卸载后导致虚拟网卡出现问题导致的. 解决办法: 右击 ...
- 一图了解 CODING 2.0:企业级持续交付解决方案
近日,CODING 在 KubeCon 2019 上海站上正式推出了 DevOps 的一站式解决方案:CODING 2.0. CODING 2.0 进行了产品.产品理念.功能.首页的升级,对用户服务进 ...
- log file sync等待超高案例浅析
监控工具DPA发现海外一台Oracle数据库服务器DB Commit Time指标告警,超过红色告警线(40毫秒左右,黄色告警是10毫秒,红色告警线是20毫秒),如下截图所示,生成了对应的时段的AWR ...
- 关于字符串的格式化----format与%
格式化字符串一般有两种方法 1.%(d整数,s字符,f浮点数) 2.format 用处极为广泛且限制不多 注意:第一种对于数组的传递会报TypeError,所以必须传递数组 a = (1, 2, 3) ...