spark源码阅读---Utils.getCallSite
1 作用
当该方法在spark内部代码中调用时,会返回当前调用spark代码的用户类的名称,以及其所调用的spark方法。所谓用户类,就是我们这些用户使用spark api的类。
2 内部实现
2.1 涉及到的java或scala知识
(1)Thread.currentThread.getStackTrace():返回一个表示该线程堆栈转储的堆栈跟踪元素数组。如果该线程尚未启动或已经终止,则该方法将返回一个零长度数组。如果返回的数组不是零长度的,则其第一个元素代表堆栈顶,它是该序列中最新的方法调用。最后一个元素代表堆栈底,是该序列中最旧的方法调用。返回数组的每个元素是一个StackTraceElement对象,存储了该方法由哪个类声明,方法名,以及文件名,文件第几行。如下:

(2)System.getProperty():返回一个系统属性值,其实就是一个配置参数值。
(3)case class:是scala中一种特殊的class。
2.2 spark源码部分
(1)该方法传入一个参数skipClass函数,用来判断哪些类名需要跳过,默认的判断函数也在Utils文件内部,如下:
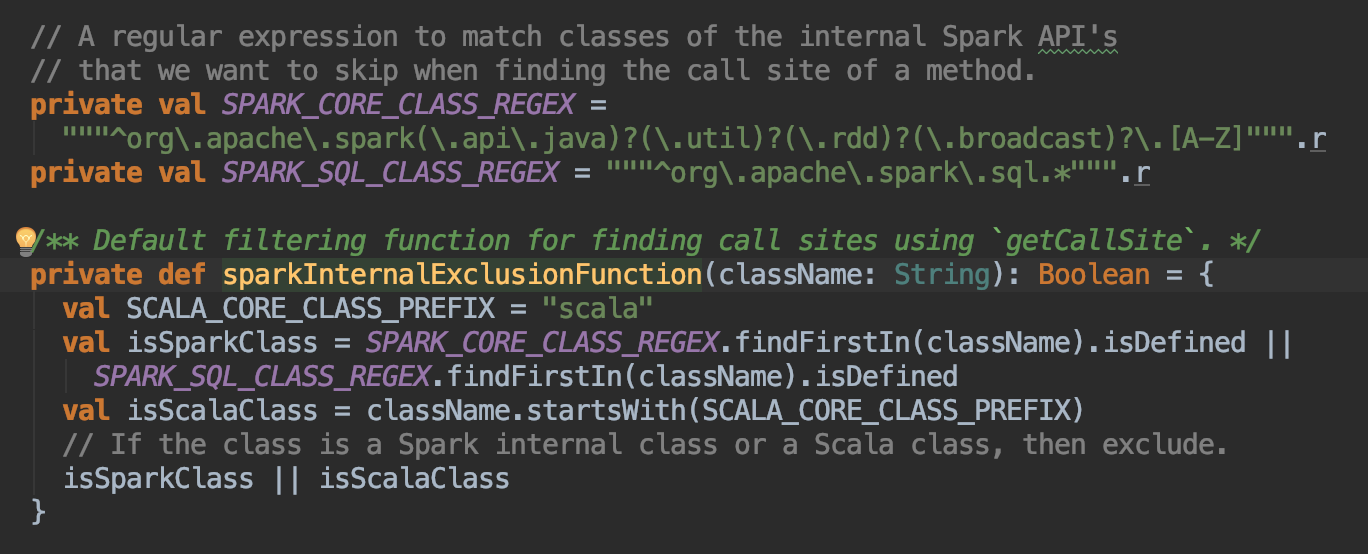
可见,默认的判断函数是通过正则表达式来判断的,其将会过滤出spark和scala的原生类。
(2)该方法维护了lastSparkMethod以及firstUserFile,firstUserLine,callStack。其中lastSparkMethod是表示直接被用户api调用的spark方法,firstUserFile是最深的(直接调用spark api的)用户方法的文件名,callStack存储了调用栈信息,callStack[0]就是lastSparkMethod,其后为所有的用户方法。源码如下:
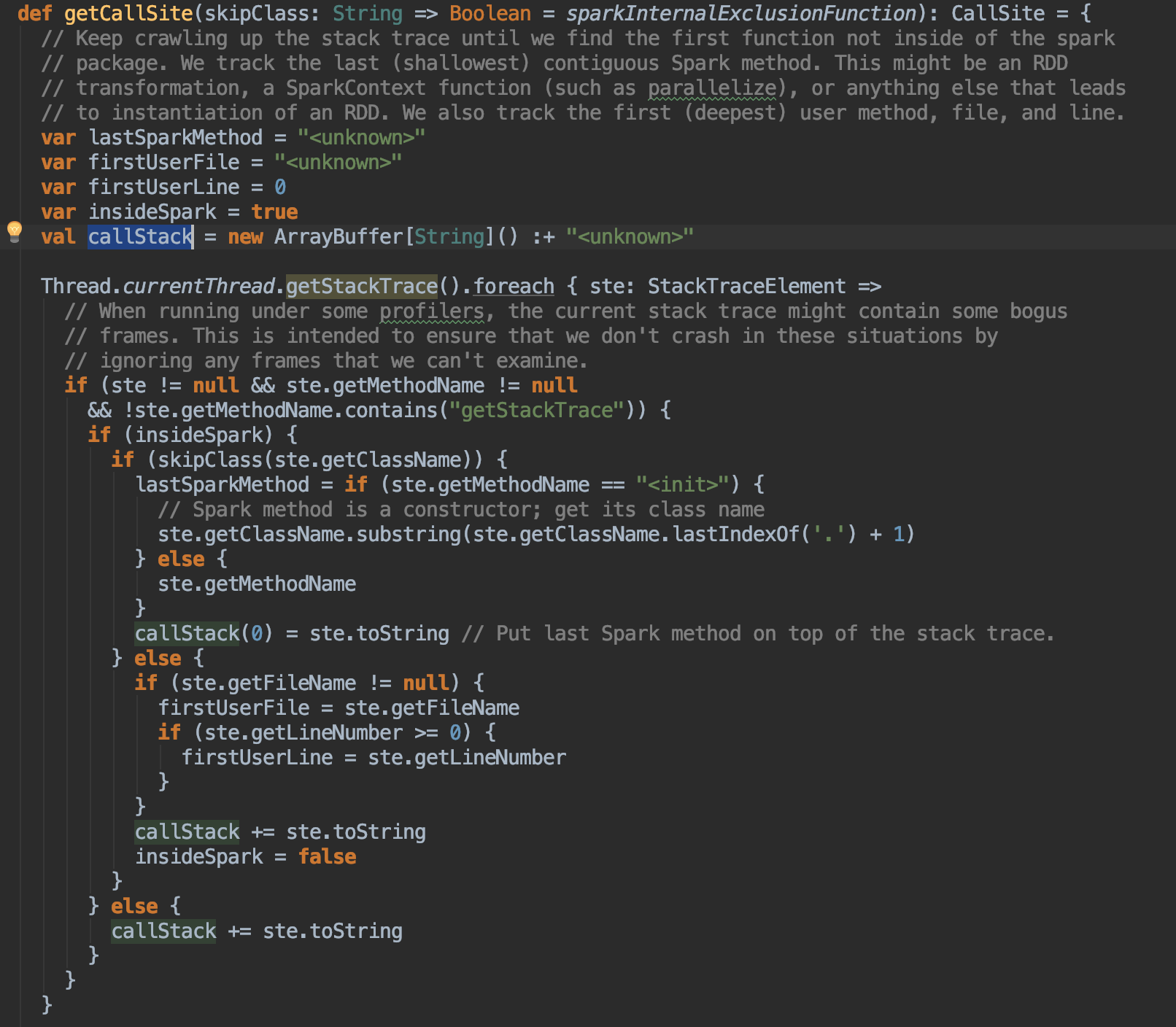
(3)该方法的最后工作,是根据上面得到的信息封装一个CallSite类:

CallSite类是一个case class:

spark源码阅读---Utils.getCallSite的更多相关文章
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- win7+idea+maven搭建spark源码阅读环境
1.参考. 利用IDEA工具编译Spark源码(1.60~2.20) https://blog.csdn.net/He11o_Liu/article/details/78739699 Maven编译打 ...
- spark源码阅读
根据spark2.2的编译顺序来确定源码阅读顺序,只阅读核心的基本部分. 1.common目录 ①Tags②Sketch③Networking④Shuffle Streaming Service⑤Un ...
- spark源码阅读--SparkContext启动过程
##SparkContext启动过程 基于spark 2.1.0 scala 2.11.8 spark源码的体系结构实在是很庞大,从使用spark-submit脚本提交任务,到向yarn申请容器,启 ...
- emacs+ensime+sbt打造spark源码阅读环境
欢迎转载,转载请注明出处,徽沪一郎. 概述 Scala越来越流行, Spark也愈来愈红火, 对spark的代码进行走读也成了一个很普遍的行为.不巧的是,当前java社区中很流行的ide如eclips ...
- Spark 源码阅读——任务提交过程
当我们在使用spark编写mr作业是,最后都要涉及到调用reduce,foreach或者是count这类action来触发作业的提交,所以,当我们查看这些方法的源码时,发现底层都调用了SparkCon ...
- spark源码阅读--shuffle过程分析
ShuffleManager(一) 本篇,我们来看一下spark内核中另一个重要的模块,Shuffle管理器ShuffleManager.shuffle可以说是分布式计算中最重要的一个概念了,数据的j ...
- Spark源码阅读(1): Stage划分
Spark中job由action动作生成,那么stage是如何划分的呢?一般的解答是根据宽窄依赖划分.那么我们深入源码看看吧 一个action 例如count,会在多次runJob中传递,最终会到一个 ...
- spark源码阅读之network(1)
spark将在1.6中替换掉akka,而采用netty实现整个集群的rpc的框架,netty的内存管理和NIO支持将有效的提高spark集群的网络传输能力,为了看懂这块代码,在网上找了两本书看< ...
随机推荐
- 你必须了解的java内存管理机制(四)-垃圾回收
本文在个人技术博客不同步发布,详情可用力戳 亦可扫描屏幕右侧二维码关注个人公众号,公众号内有个人联系方式,等你来撩... 相关链接(注:文章讲解JVM以Hotspot虚拟机为例,jdk版本为1.8) ...
- MYSQL手工注入(详细步骤)—— 待补充
0x00 SQL注入的分类: (1)基于从服务器接收到的响应 ▲基于错误的 SQL 注入 ▲联合查询的类型 ▲堆查询注射 ▲SQL 盲注 ...
- Python 3.5学习笔记(第一章)
本章内容: 1.安装python 3.5 和 PyCharm 社区版 2.第一个python程序 3.变量 4.字符编码 5.用户输入 6.字符串格式化输出 7.if .else .elif 8.fo ...
- xx.exe 中的 0x014180bd 处有未经处理的异常: 0xC0000005: 读取位置 0xfeeefeee 时发生访问冲突(当指针访问异常时,应考虑是不是对象未创建)。
xx.exe 中的 0x014180bd 处有未经处理的异常: 0xC0000005: 读取位置 0xfeeefeee 时发生访问冲突
- 个人永久性免费-Excel催化剂功能第100波-透视多行数据为多列数据结构
在数据处理过程中,大量的非预期格式结构需要作转换,有大家熟知的多维转一维(准确来说应该是交叉表结构的数据转二维表标准数据表结构),也同样有一些需要透视操作的数据源,此篇同样提供更便捷的方法实现此类数据 ...
- .NET Core 3.0之深入源码理解HttpClientFactory(一)
写在前面 创建HttpClient实例的时候,在内部会创建HttpMessageHandler链,我们知道HttpMessageHandler是负责建立连接的抽象处理程序,所以HttpClient的维 ...
- c语言进阶8-数据结构
一. 数据结构的起源: 1. 为什么要学习数据结构 阿基米德说过:“给我一个支点,我就能翘起地球”.那么给我一个程序,我就能用好程序,给我一个结构,我就能把内容填充完成.打个比方,一个 ...
- C#3.0新增功能10 表达式树 07 翻译(转换)表达式
连载目录 [已更新最新开发文章,点击查看详细] 本篇将介绍如何访问表达式树中的每个节点,同时生成该表达式树的已修改副本. 以下是在两个重要方案中将使用的技巧. 第一种是了解表达式树表示的算法,以 ...
- WGS84坐标与web墨卡托投影坐标转换
许久没有使用坐标转换,记忆有些模糊了,以后还是会用到,先将WGS84与web墨卡托转换复习一下: 1.84转web墨卡托 //核心公式 平面坐标x = 经度*20037508.34/108 平面坐标y ...
- 《VR入门系列教程》之7---DK2和Crescent Bay
The DK2 于2014年春,Oculus发布了第二代开发版头显设备,代号为DK2.与DK1相比,Oculus Rift DK2的外观有很大改进,并且轻了许多,体积仍然比较大,可以罩住大部分 ...