聊聊缓存淘汰算法-LRU 实现原理
前言
我们常用缓存提升数据查询速度,由于缓存容量有限,当缓存容量到达上限,就需要删除部分数据挪出空间,这样新数据才可以添加进来。缓存数据不能随机删除,一般情况下我们需要根据某种算法删除缓存数据。常用淘汰算法有 LRU,LFU,FIFO,这篇文章我们聊聊 LRU 算法。
LRU 简介
LRU 是 Least Recently Used 的缩写,这种算法认为最近使用的数据是热门数据,下一次很大概率将会再次被使用。而最近很少被使用的数据,很大概率下一次不再用到。当缓存容量的满时候,优先淘汰最近很少使用的数据。
假设现在缓存内部数据如图所示:
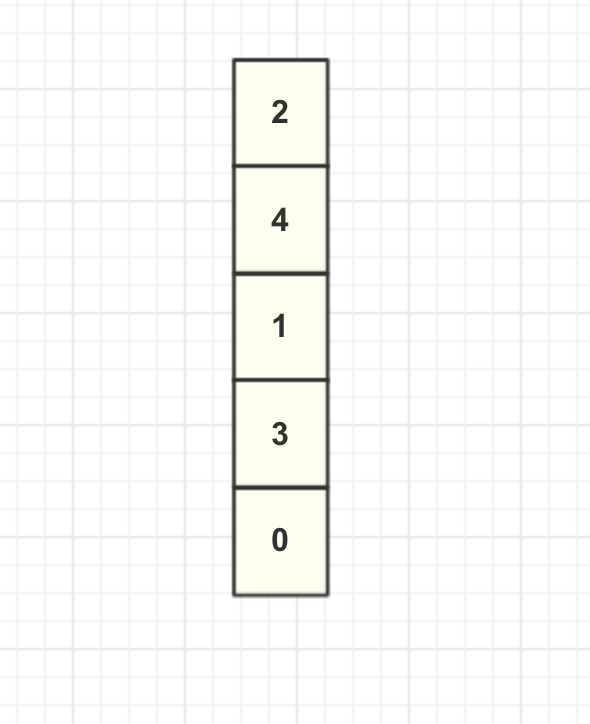
这里我们将列表第一个节点称为头结点,最后一个节点为尾结点。
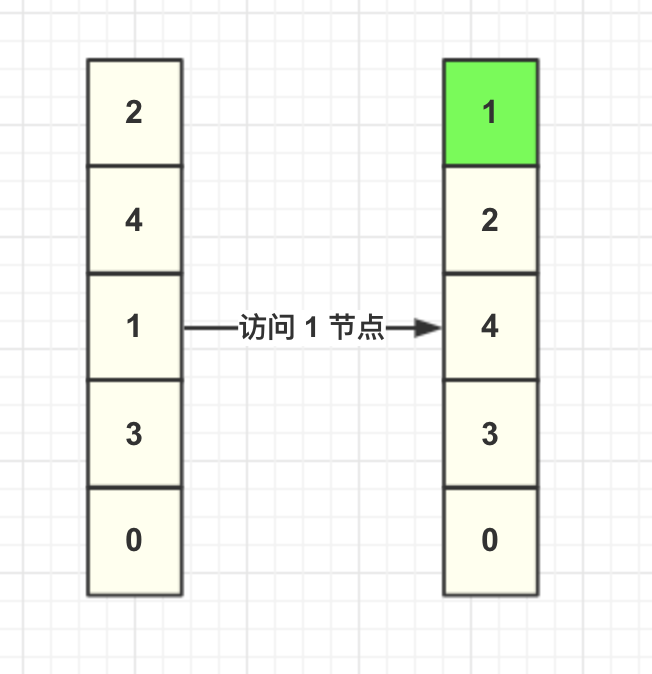
当调用缓存获取 key=1 的数据,LRU 算法需要将 1 这个节点移动到头结点,其余节点不变,如图所示。
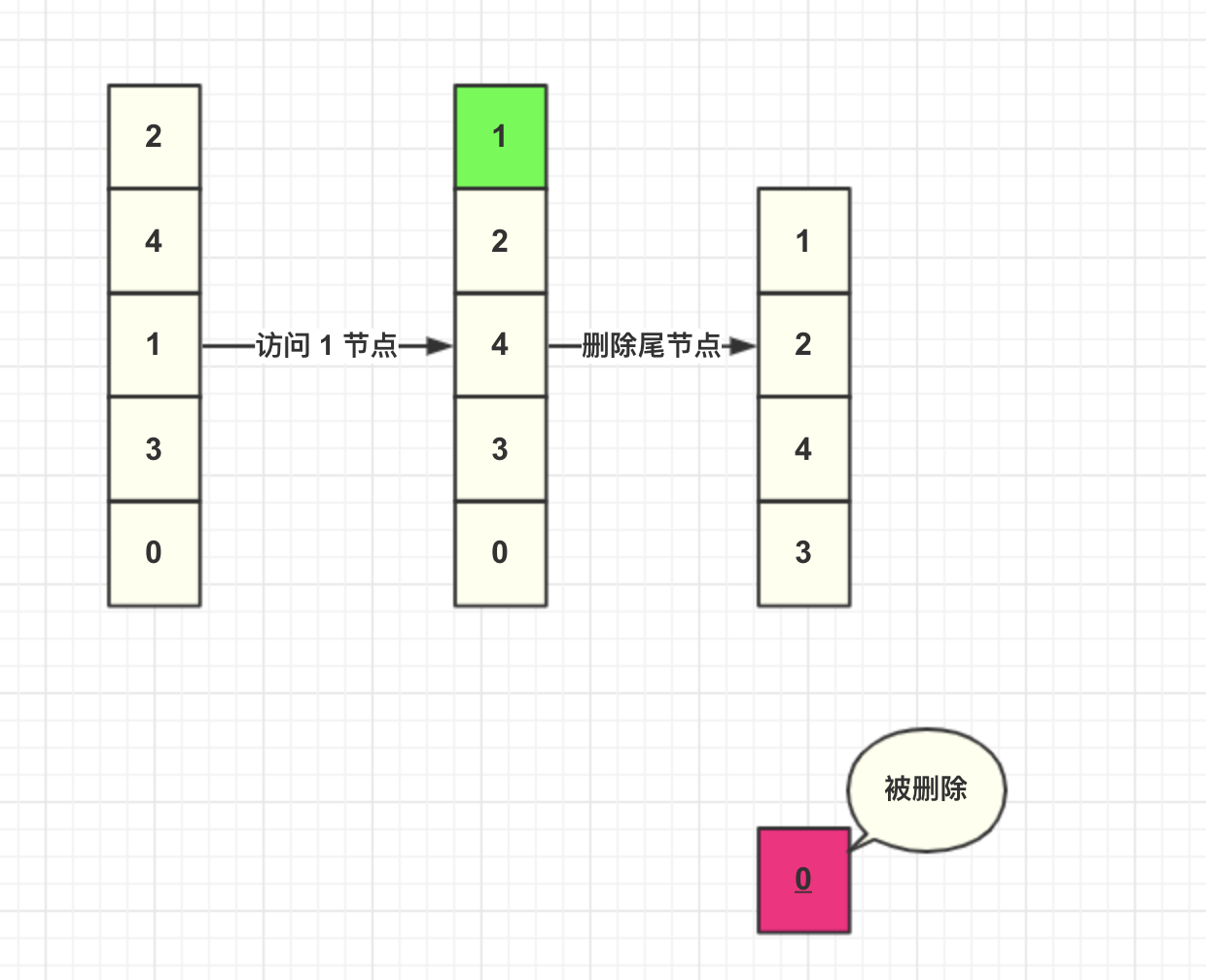
然后我们插入一个 key=8 节点,此时缓存容量到达上限,所以加入之前需要先删除数据。由于每次查询都会将数据移动到头结点,未被查询的数据就将会下沉到尾部节点,尾部的数据就可以认为是最少被访问的数据,所以删除尾结点的数据。
然后我们直接将数据添加到头结点。
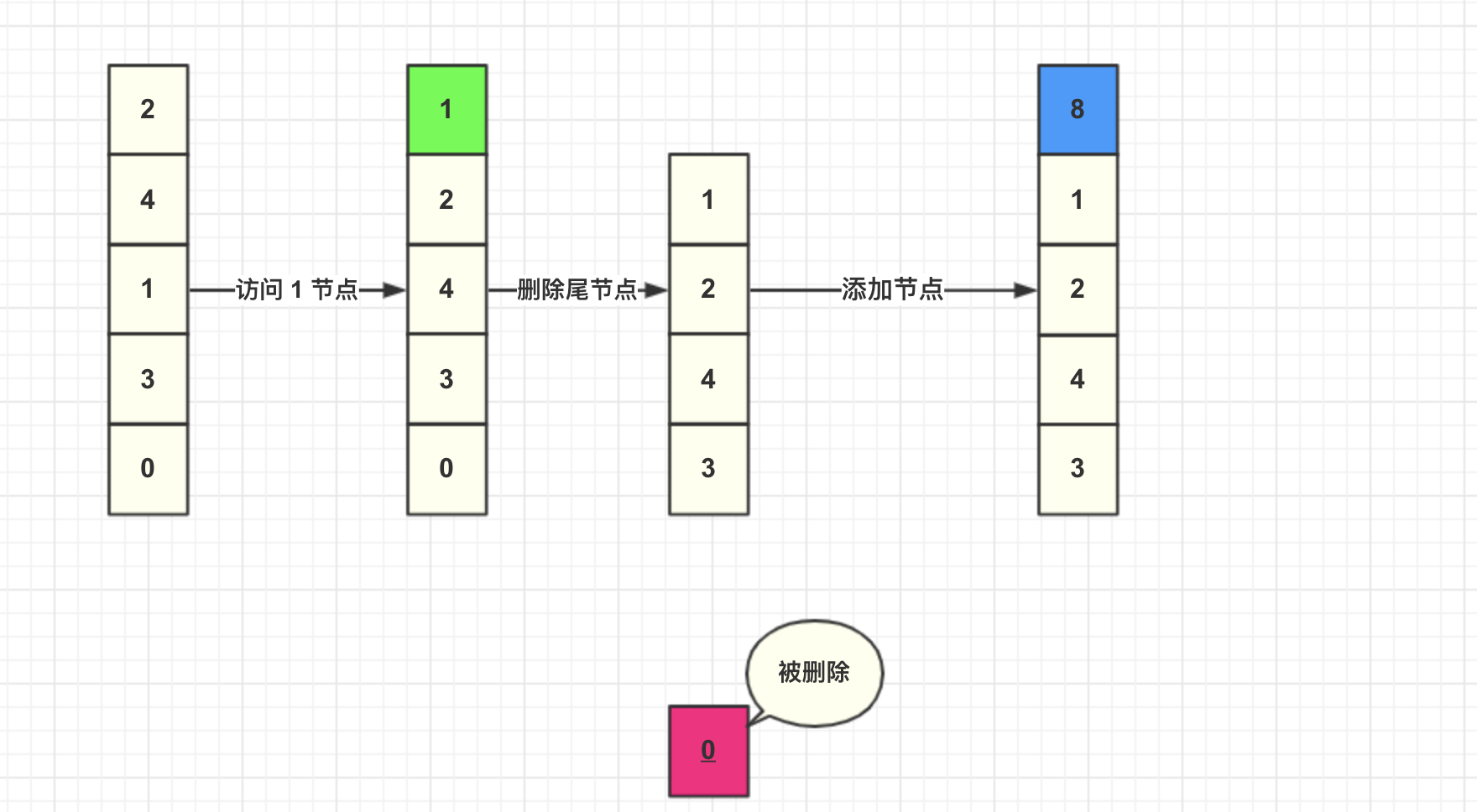
这里总结一下 LRU 算法具体步骤:
- 新数据直接插入到列表头部
- 缓存数据被命中,将数据移动到列表头部
- 缓存已满的时候,移除列表尾部数据。
LRU 算法实现
上面例子中可以看到,LRU 算法需要添加头节点,删除尾结点。而链表添加节点/删除节点时间复杂度 O(1),非常适合当做存储缓存数据容器。但是不能使用普通的单向链表,单向链表有几点劣势:
- 每次获取任意节点数据,都需要从头结点遍历下去,这就导致获取节点复杂度为 O(N)。
- 移动中间节点到头结点,我们需要知道中间节点前一个节点的信息,单向链表就不得不再次遍历获取信息。
针对以上问题,可以结合其他数据结构解决。
使用散列表存储节点,获取节点的复杂度将会降低为 O(1)。节点移动问题可以在节点中再增加前驱指针,记录上一个节点信息,这样链表就从单向链表变成了双向链表。
综上使用双向链表加散列表结合体,数据结构如图所示:
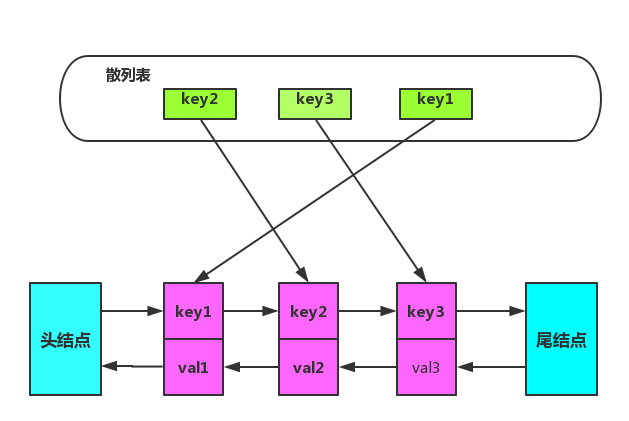
在双向链表中特意增加两个『哨兵』节点,不用来存储任何数据。使用哨兵节点,增加/删除节点的时候就可以不用考虑边界节点不存在情况,简化编程难度,降低代码复杂度。
LRU 算法实现代码如下,为了简化 key ,val 都认为 int 类型。
public class LRUCache {
Entry head, tail;
int capacity;
int size;
Map<Integer, Entry> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
// 初始化链表
initLinkedList();
size = 0;
cache = new HashMap<>(capacity + 2);
}
/**
* 如果节点不存在,返回 -1.如果存在,将节点移动到头结点,并返回节点的数据。
*
* @param key
* @return
*/
public int get(int key) {
Entry node = cache.get(key);
if (node == null) {
return -1;
}
// 存在移动节点
moveToHead(node);
return node.value;
}
/**
* 将节点加入到头结点,如果容量已满,将会删除尾结点
*
* @param key
* @param value
*/
public void put(int key, int value) {
Entry node = cache.get(key);
if (node != null) {
node.value = value;
moveToHead(node);
return;
}
// 不存在。先加进去,再移除尾结点
// 此时容量已满 删除尾结点
if (size == capacity) {
Entry lastNode = tail.pre;
deleteNode(lastNode);
cache.remove(lastNode.key);
size--;
}
// 加入头结点
Entry newNode = new Entry();
newNode.key = key;
newNode.value = value;
addNode(newNode);
cache.put(key, newNode);
size++;
}
private void moveToHead(Entry node) {
// 首先删除原来节点的关系
deleteNode(node);
addNode(node);
}
private void addNode(Entry node) {
head.next.pre = node;
node.next = head.next;
node.pre = head;
head.next = node;
}
private void deleteNode(Entry node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
public static class Entry {
public Entry pre;
public Entry next;
public int key;
public int value;
public Entry(int key, int value) {
this.key = key;
this.value = value;
}
public Entry() {
}
}
private void initLinkedList() {
head = new Entry();
tail = new Entry();
head.next = tail;
tail.pre = head;
}
public static void main(String[] args) {
LRUCache cache = new LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.get(1));
cache.put(3, 3);
System.out.println(cache.get(2));
}
}
LRU 算法分析
缓存命中率是缓存系统的非常重要指标,如果缓存系统的缓存命中率过低,将会导致查询回流到数据库,导致数据库的压力升高。
结合以上分析 LRU 算法优缺点。
LRU 算法优势在于算法实现难度不大,对于对于热点数据, LRU 效率会很好。
LRU 算法劣势在于对于偶发的批量操作,比如说批量查询历史数据,就有可能使缓存中热门数据被这些历史数据替换,造成缓存污染,导致缓存命中率下降,减慢了正常数据查询。
LRU 算法改进方案
以下方案来源与 MySQL InnoDB LRU 改进算法
将链表拆分成两部分,分为热数据区,与冷数据区,如图所示。
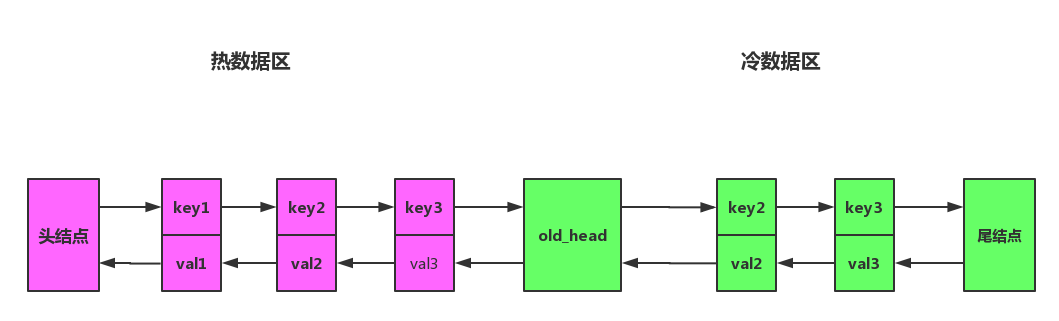
改进之后算法流程将会变成下面一样:
- 访问数据如果位于热数据区,与之前 LRU 算法一样,移动到热数据区的头结点。
- 插入数据时,若缓存已满,淘汰尾结点的数据。然后将数据插入冷数据区的头结点。
- 处于冷数据区的数据每次被访问需要做如下判断:
- 若该数据已在缓存中超过指定时间,比如说 1 s,则移动到热数据区的头结点。
- 若该数据存在在时间小于指定的时间,则位置保持不变。
对于偶发的批量查询,数据仅仅只会落入冷数据区,然后很快就会被淘汰出去。热门数据区的数据将不会受到影响,这样就解决了 LRU 算法缓存命中率下降的问题。
其他改进方法还有 LRU-K,2Q,LIRS 算法,感兴趣同学可以自行查阅。
欢迎关注我的公众号:程序通事,获得日常干货推送。如果您对我的专题内容感兴趣,也可以关注我的博客:studyidea.cn

聊聊缓存淘汰算法-LRU 实现原理的更多相关文章
- 缓存淘汰算法 LRU 和 LFU
LRU (Least Recently Used), 即最近最少使用用算法,是一种常见的 Cache 页面置换算法,有利于提高 Cache 命中率. LRU 的算法思想:对于每个页面,记录该页面自上一 ...
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
- 缓存淘汰算法---LRU
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- 缓存淘汰算法---LRU转
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- 缓存淘汰算法--LRU算法(转)
(转自:http://flychao88.iteye.com/blog/1977653) 1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访 ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
随机推荐
- setInterval、setTimeout之遗忘的第三个参数
今天看阮一峰老师的ES6入门,在一个关于promise的小demo里,老师用到了setTimeout的第三个参数,惊了有没有,定时器还有第三个参数? 喏就是下面这个demo: function tim ...
- Emacs 笔记二
Emacs 笔记二 Table of Contents 1. 前言 2. emacs基本操作(常用快捷键) 3. emacs模式讲解 4. emacs缓冲区 5. org mode 5.1. 列表 5 ...
- JIRA集成GitHub
原因: 作为管理员, 为用户提高效率的角度,配置测试此服务.让用户从JIRA内看到代码分支,提交信息,pull requests等等, 让Github的代码提交记录和JIRA的任务管理系统集成在一起, ...
- Eureka实战-4【开启http basic权限认证】
在我们实际生产环境中,都需要考虑到一个安全问题,比如用户登录,又或者是eureka server,它对外暴露的有自己的rest API,如果没有安全认证,也就意味着别人可以通过rest API随意修改 ...
- JS/Jquery关系
1. JS / JQuery介绍 Jquery是JS库,何为JS库,即把常用的js方法进行封装,封装到单独的JS文件中,要用的时候直接调用即可: 2. JS / JQuery对象 1. 定义 (1) ...
- Hyperion: Building the Largest In memory Search Tree
Introduction 索引在数据管理中起到很重要的作用,很多索引结构都会采用访问速度快而且内存消耗少的trie树,但一般常见的trie树索引结构都强调效率而忽视内存的效率,他们的效率虽然高,但内存 ...
- php无限级分类实战——评论及回复功能
经常在各大论坛或新闻板块详情页面下边看到评论功能,当然不单单是直接发表评论内容那么简单,可以对别人的评论进行回复,别人又可以对你的回复再次评论或回复,如此反复,理论上可以说是没有休止,从技术角度分析很 ...
- Timed out after 30000 ms while waiting to connect
今天使用mongo-java-drive写连接mongo的客户端,着实被上面那个错坑了一把.回顾一下解决过程: 报错: com.mongodb.MongoTimeoutException: Timed ...
- Hadoop-2.7.3-本地模式安装-wordcount例子
准备虚拟机:linux-rhel-7.4-server,由于不使用虚拟机进行联网,所以选择host-only网络模式.此处,需要再VitralBox的管理菜单中的主机网络管理器新建一个虚拟网卡.安装完 ...
- 索引的底层实现(B 树)
一.B 树 1.B-Tree介绍 B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点:重复,直到所对应的儿子指针为空,或已经是叶 ...