Python - 模块 - 第十六天
Python 模块
在前面的几个章节中我们脚本上是用 python 解释器来编程,如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
下面是一个使用 python 标准库中模块的例子。
import sys
print('命令行参数如下:')
for i in sys.argv:
print(i)
print('\n\nPython 路径为:', sys.path, '\n')
注意:
- 1、import sys 引入 python 标准库中的 sys.py 模块;这是引入某一模块的方法。
- 2、sys.argv 是一个包含命令行参数的列表。
- 3、sys.path 包含了一个 Python 解释器自动查找所需模块的路径的列表。
import 语句
想使用 Python 源文件,只需在另一个源
文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
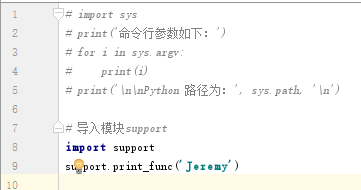
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support,需要把命令放在脚本的顶端:
support.py 文件代码
# Filename: support.py
def print_func( par ):
print ("Hello : ", par)
return
test.py 引入 support 模块:
test.py 文件代码
# Filename: test.py
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
以上实例输出结果:
$ python3 test.py
Hello : Runoob
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?
这就涉及到Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。
这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。
from … import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]
from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
深入模块
模块除了方法定义,还可以包括可执行的代码。这些代码一般用来初始化这个模块。这些代码只有在第一次被导入时才会被执行。
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用。
所以,模块的作者可以放心大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞混。
从另一个方面,当你确实知道你在做什么的话,你也可以通过 modname.itemname 这样的表示法来访问模块内的函数。
模块是可以导入其他模块的。在一个模块(或者脚本,或者其他地方)的最前面使用 import 来导入一个模块,当然这只是一个惯例,而不是强制的。被导入的模块的名称将被放入当前操作的模块的符号表中。
还有一种导入的方法,可以使用 import 直接把模块内(函数,变量的)名称导入到当前操作模块。比如:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种导入的方法不会把被导入的模块的名称放在当前的字符表中(所以在这个例子里面,fibo 这个名称是没有定义的)。
这还有一种方法,可以一次性的把模块中的所有(函数,变量)名称都导入到当前模块的字符表:
>>> from fibo import *
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这将把所有的名字都导入进来,但是那些由单一下划线(_)开头的名字不在此例。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
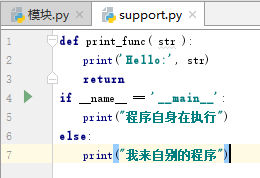
运行输出如下:

运行结果:

说明: 每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
说明:__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
>>> import fibo, sys
>>> dir(fibo)
['__name__', 'fib', 'fib2']
>>> dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
'__package__', '__stderr__', '__stdin__', '__stdout__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
'_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
'call_tracing', 'callstats', 'copyright', 'displayhook',
'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
'thread_info', 'version', 'version_info', 'warnoptions']
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
>>> a = [1, 2, 3, 4, 5]
>>> import fibo
>>> fib = fibo.fib
>>> dir() # 得到一个当前模块中定义的属性列表
['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys']
>>> a = 5 # 建立一个新的变量 'a'
>>> dir()
['__builtins__', '__doc__', '__name__', 'a', 'sys']
>>>
>>> del a # 删除变量名a
>>>
>>> dir()
['__builtins__', '__doc__', '__name__', 'sys']
>>>
标准模块
Python 本身带着一些标准的模块库,在 Python 库参考文档中将会介绍到(就是后面的"库参考文档")。
有些模块直接被构建在解析器里,这些虽然不是一些语言内置的功能,但是他却能很高效的使用,甚至是系统级调用也没问题。
这些组件会根据不同的操作系统进行不同形式的配置,比如 winreg 这个模块就只会提供给 Windows 系统。
应该注意到这有一个特别的模块 sys ,它内置在每一个 Python 解析器中。变量 sys.ps1 和 sys.ps2 定义了主提示符和副提示符所对应的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Runoob!')
Runoob!
C>
包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。
这样不同的作者都可以提供 NumPy 模块,或者是 Python 图形库。
不妨假设你想设计一套统一处理声音文件和数据的模块(或者称之为一个"包")。
现存很多种不同的音频文件格式(基本上都是通过后缀名区分的,例如: .wav,:file:.aiff,:file:.au,),所以你需要有一组不断增加的模块,用来在不同的格式之间转换。
并且针对这些音频数据,还有很多不同的操作(比如混音,添加回声,增加均衡器功能,创建人造立体声效果),所以你还需要一组怎么也写不完的模块来处理这些操作。
这里给出了一种可能的包结构(在分层的文件系统中):
sound/ 顶层包
__init__.py 初始化 sound 包
formats/ 文件格式转换子包
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ 声音效果子包
__init__.py
echo.py
surround.py
reverse.py
...
filters/ filters 子包
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo
这将会导入子模块:sound.effects.echo。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
还有一种导入子模块的方法是:
from sound.effects import echo
这同样会导入子模块: echo,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)
还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter
同样的,这种方法会导入子模块: echo,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)
注意当使用from package import item这种形式的时候,对应的item既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import语法会首先把item当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,恭喜,一个:exc:ImportError 异常被抛出了。
反之,如果使用形如import item.subitem.subsubitem这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
从一个包中导入*
设想一下,如果我们使用 from sound.effects import *会发生什么?
Python 会进入文件系统,找到这个包里面所有的子模块,一个一个的把它们都导入进来。
但是很不幸,这个方法在 Windows平台上工作的就不是非常好,因为Windows是一个大小写不区分的系统。
在这类平台上,没有人敢担保一个叫做 ECHO.py 的文件导入为模块 echo 还是 Echo 甚至 ECHO。
(例如,Windows 95就很讨厌的把每一个文件的首字母大写显示)而且 DOS 的 8+3 命名规则对长模块名称的处理会把问题搞得更纠结。
为了解决这个问题,只能烦劳包作者提供一个精确的包的索引了。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
作为包的作者,可别忘了在更新包之后保证 __all__ 也更新了啊。你说我就不这么做,我就不使用导入*这种用法,好吧,没问题,谁让你是老板呢。这里有一个例子,在:file:sounds/effects/__init__.py中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用from sound.effects import *这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
这会把 __init__.py 里面定义的所有名字导入进来。并且他不会破坏掉我们在这句话之前导入的所有明确指定的模块。看下这部分代码:
import sound.effects.echo
import sound.effects.surround
from sound.effects import *
这个例子中,在执行from...import前,包sound.effects中的echo和surround模块都被导入到当前的命名空间中了。(当然如果定义了__all__就更没问题了)
通常我们并不主张使用*这种方法来导入模块,因为这种方法经常会导致代码的可读性降低。不过这样倒的确是可以省去不少敲键的功夫,而且一些模块都设计成了只能通过特定的方法导入。
记住,使用from Package import specific_submodule这种方法永远不会有错。事实上,这也是推荐的方法。除非是你要导入的子模块有可能和其他包的子模块重名。
如果在结构中包是一个子包(比如这个例子中对于包sound来说),而你又想导入兄弟包(同级别的包)你就得使用导入绝对的路径来导入。比如,如果模块sound.filters.vocoder 要使用包sound.effects中的模块echo,你就要写成 from sound.effects import echo。
from . import echo
from .. import formats
from ..filters import equalizer
无论是隐式的还是显式的相对导入都是从当前模块开始的。主模块的名字永远是"__main__",一个Python应用程序的主模块,应当总是使用绝对路径引用。
包还提供一个额外的属性__path__。这是一个目录列表,里面每一个包含的目录都有为这个包服务的__init__.py,你得在其他__init__.py被执行前定义哦。可以修改这个变量,用来影响包含在包里面的模块和子包。
这个功能并不常用,一般用来扩展包里面的模块。
xMind小结

参考资料

Python - 模块 - 第十六天的更多相关文章
- 孤荷凌寒自学python第八十六天对selenium模块进行较详细的了解
孤荷凌寒自学python第八十六天对selenium模块进行较详细的了解 (今天由于文中所阐述的原因没有进行屏幕录屏,见谅) 为了能够使用selenium模块进行真正的操作,今天主要大范围搜索资料进行 ...
- 孤荷凌寒自学python第四十六天开始建构自己用起来更顺手一点的Python模块与类尝试第一天
孤荷凌寒自学python第四十六天开始建构自己用起来更顺手一点的Python模块与类,尝试第一天 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 按上一天的规划,这是根据过去我自学其它编程语 ...
- 孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6
孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 不过由于对python-docx模 ...
- 孤荷凌寒自学python第六十六天学习mongoDB的基本操作并进行简单封装5
孤荷凌寒自学python第六十六天学习mongoDB的基本操作并进行简单封装5并学习权限设置 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十二天. 今天继续学习mongo ...
- 孤荷凌寒自学python第五十六天通过compass客户端和mongodb shell 命令来连接远端MongoDb数据库
孤荷凌寒自学python第五十六天通过compass客户端和mongodb shell 命令来连接远端MongoDb数据库 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第二 ...
- Python 学习第十六天 html 前端内容总结
一,css知识总结 1, css属性 css的属性包括以下内容 position:规定元素的定位类型 background:属性在一个声明中设置所有的背景属性 可以设置的如下属性: (1)back ...
- python学习第十六天 --继承进阶篇
这一章节主要讲解面向对象高级编程->继承进阶篇,包括类多继承介绍和继承经典类和新式类属性的查找顺序不同之处. 多继承 上一章节我们讲到继承,子类继承父类,可以拥有父类的属性和方法,也可以进行扩展 ...
- python第七十六天--堡垒机完成
堡垒机windows ,linux 都通过测试初始化说明: #进入根目录 1.初始化表结构 #python3 bin/start.py syncdb 2.创建堡垒机用户 #python3 bin/st ...
- python第六十六天--sqlalchemy
#!usr/bin/env python #-*-coding:utf-8-*- # Author calmyan #python #2017/7/6 21:29 #__author__='Admin ...
随机推荐
- 阿里云centos7安装python3.7.4和pip3
亲测有效,针对 阿里云 centos 7 轻量服务器 python ==> 3.7.4 pip ==> 3 一,打开python官网,找到下载Python的tgz文件,有两种方式下载 ( ...
- SpringBoot+Thyemelaf开发环境正常,打包jar发到服务器就报错Template might not exist or might not be accessible
这里说一下Thyemelaf的巨坑 写了一个SpringBoot+Thyemelaf的项目,并不是前后端分离.今天想放到linux服务器上玩玩,打成jar包,然后一运行他妈居然报错了,报了一个Temp ...
- 跳跃空间(链表)排序 选择排序(selection sort),插入排序(insertion sort)
跳跃空间(链表)排序 选择排序(selection sort),插入排序(insertion sort) 选择排序(selection sort) 算法原理:有一筐苹果,先挑出最大的一个放在最后,然后 ...
- Java面试之synchronized 和 static synchronized
面试题: 答案: 不能 不能 不能 不能 能 正文 概述 通过分析这两个用法的分析,我们可以理解java中锁的概念.一个是实例锁(锁在某一个实例对象上,如果该类是单例,那么该锁也具有全局锁的概念), ...
- k8s中的client-go编译成功
要分版本的,好像1.4跟12差别好大. 1.4中用的模块管理还是vendor,12就换成mod了. 这个要记住差异. 一,从github上下载client-go的1.4版本 https://githu ...
- 解决N个人过桥时间最短问题(Java版本)
[问题描述] n个人要晚上过桥,在任何时候最多两个人一组过桥,每组要有一只手电筒.在这n个人中只有一个手电筒能用,因此要安排以某种往返的方式来返还手电筒,使更多的人可以过桥. 注意:每个人的过桥速 ...
- C#所有经典排序算法汇总
1.选择排序 选择排序 class SelectionSorter { private int min; public void Sort(int[] arr) ...
- 智能指针类模板(上)——STL中的智能指针
智能指针类模板智能指针本质上就是一个对象,它可以像原生指针那样来使用. 智能指针的意义-现代C++开发库中最重要的类模板之一-C++中自动内存管理的主要手段-能够在很大程度上避开内存相关的问题 1.内 ...
- Educational Codeforces Round 78 (Rated for Div. 2) --补题
链接 直接用数组记录每个字母的个数即可 #include<bits/stdc++.h> using namespace std; int a[26] = {0}; int b[26] = ...
- luoguP2178 [NOI2015]品酒大会(后缀数组做法)
题意 因为一个\(k\)相似必定为\(k-1,k-2....0\)相似,对于一个\(lcp\)为\(k\)后缀对\((i,j)\),我们只用把它的贡献加在\(k\)的答案上,最后求一个后缀和和后缀ma ...