ICP&TPS:最近邻
经过了一段时间的研bai究gei。。。终于可以偷得几天闲了。
这里来补个档。
无论是ICP还是TPS,缺乏锚点的前提下。你总是要通过找另一个曲面的最近的点来实现你的work
beimat:点数*3,float:点的坐标
feimat:三角数*3,int:顶点序号
首先是一个非精确手动校准。
def handfix(thx,thy,thz,k,x,y,z):
mat1=np.zeros((3,3),dtype=float)
mat2=np.zeros((3,3),dtype=float)
mat3=np.zeros((3,3),dtype=float)
mat4=np.zeros((3,3),dtype=float)
mat4[0][0]=k
mat4[1][1]=k
mat4[2][2]=k
mat1[2][2]=1
mat2[1][1]=1
mat3[0][0]=1
mat1[0][0]=np.cos(thx)
mat1[1][0]=-np.sin(thx)
mat1[0][1]=np.sin(thx)
mat1[1][1]=np.cos(thx)
mat2[0][0]=np.cos(thy)
mat2[2][0]=-np.sin(thy)
mat2[0][2]=np.sin(thy)
mat2[2][2]=np.cos(thy)
mat3[1][1]=np.cos(thz)
mat3[2][1]=-np.sin(thz)
mat3[1][2]=np.sin(thz)
mat3[2][2]=np.cos(thz)
mat=np.dot(mat4,np.dot(mat3,np.dot(mat2,mat1)))
t=np.zeros((3),dtype=float)
t[0]=x
t[1]=y
t[2]=z
return mat,t
我们定义了四个矩阵和三类参数。
(thx,thy,thxz)&(k)&(dx,dy,dz)分别代表了绕轴旋转的量,放缩的量,平移的量。
mat=np.dot(mat4,np.dot(mat3,np.dot(mat2,mat1)))
这句话规定了,旋转,放缩的顺序。先绕x,接绕y,后绕z,整体放缩,再平移。
如果你愿意的话,你可以调整旋转的顺序。你也可以分开旋转,把旋转矩阵都整明白了,乘起来,再平移。
因为这种手动校准,我是打了“断点”。(我其实把后面全部注释掉。。。)
由于这种手动校准,通常只会出现一次,所以,我就不优化了。哈哈哈哈哈你打我啊!!!
def handfixbei(beimat,potnumber,mat,t):
beinew=copy.deepcopy(beimat)
for i in range(potnumber):
x=beimat[i]
y=np.dot(mat,x)+t
beinew[i]=y
return beinew
你要知道,这里的所谓平移只是一个整合,我一次列了七个量,有点混的说。
所以你们自己做的时候,可以把thxthythz整合一个向量输入,也可以不输入dxdydz,反正我只是将他整合成一个向量。总之这都是优化的方向。
因为这是个日抛函数,所以,嘿嘿嘿。。。反正你打不到我。
既然刚才是在整合矩阵,我们这个函数呢,就是执行Rx+t,换言之,就是给他旋转好。
好了,接下来才是重点。就是寻找最近点。
如果你愿意历遍所有点,那我们自然没有什么好讲的。
我的方法有点八叉树的意思。但是单纯的八叉树不好用。
我一次把空间分割成16*16*16块该有多好。
如果你的计算机支持的话,1000*1000*1000也不是不行。。。也行可以,但没必要。
我现在要做的事情是准备好了篮子,然后把每个点丢进去。
首先,我们要准备篮子,你得知道这个点云,占了空间中多大的位置?他是跟老和山一样大呢,还是跟我手边的快乐水一样大,这是个问题。
def maxmatdeal(beimat):
maxmat=np.zeros((3,3),dtype=float)
for i in range(3):
maxmat[i][0]=int(max(beimat[:,i])+1)
maxmat[i][1]=int(min(beimat[:,i])-1)
return maxmat
def maxmatdeta(maxmat,deta):
for i in range(3):
maxmat[i][2]=(maxmat[i][0]-maxmat[i][1])/deta
return maxmat
maxmat
三个坐标轴占三行,第一列最大值,第二列最小值,第三列细度。
除非你不想等分。。。
需要指出的是,我们将每个坐标轴都分为n+1个部分。(n就是deta)。+1的意思是,还有空间之外的部分——没有点的部分。
三列里知道两个,就足以找到你想要的篮子了。
defdetadealnew(deta,potnumber,beimat,maxmat):intmatnew=np.zeros((potnumber,3),dtype=int)potmat=[[[[]foriinrange(deta)]forjinrange(deta)]forkinrange(deta)]foriinrange(potnumber):coor=beimat[i,:]coorback=icp.findxyz(coor,maxmat)intmatnew[i,0:3]=coorbackpotmat[int(coorback[0])][int(coorback[1])][int(coorback[2])].append(i)returnpotmat,intmatnewdeffindxyz(coor,maxmat):coorback=np.zeros((3),dtype=int)foriinrange(3):coorback[i]=(coor[i]-maxmat[i][1])/maxmat[i][2]returncoorback
findxyz能输出你要找的区的编号。
coorback 返回一个三维整型:i,j,k,意思就是,你应该在三维空间里的第i,j,k格。
我们创立了一个deta*deta*deta的list,存的是序号。
中间多数格子是空的,因为我们是一个曲面,,,,稠密才是八太行的,虽然在空间里,稠密的曲面也是存在的,你化用皮阿诺曲线可得。
现在,我们可以把点集A的空间划分找到了。
然后我们把点集B,按A的标准,找每个点should在A划分里的哪一格。
再去B的对应格里,历遍,你做了这样的划分,你还不想历遍的话,我只想说,兄台有想法。。。你可以按八叉树的思想,划第二次。
EZ4ENCE ENCE ENCE~~~
如果只是这样的话,不见得work。
首先,这里默认了两个网格/点云同尺寸。
万一B比A要大可就毁了。
for i in range(3):
maxmat2[i][0]+=20
maxmat2[i][1]-=20
bigger
所以你放大一下A的上下界不就好了。
我一开始,上界上取整,下界下取整也是这个意思。
万一A,B他不在一起也毁了。A在三墩镇,B是老和山。就算A再小,b范围再大,也不可能work啊。
def beitran(maxmat1,maxmat2,way):
#way=0:auto,need to do###way=1,changing mat1###way==2,changing mat2
mat1=np.zeros((3,4),dtype=float)
mat2=np.zeros((3,4),dtype=float)
mat111=np.zeros((4,2),dtype=float) #length, midpoint
mat222=np.zeros((4,2),dtype=float)
for i in range(3):
mat1[i][i]=1
mat2[i][i]=1
mat111[i][0]=maxmat1[i][0]-maxmat1[i][1]
mat111[i][1]=(maxmat1[i][0]+maxmat1[i][1])/2
mat222[i][0]=maxmat2[i][0]-maxmat2[i][1]
mat222[i][1]=(maxmat2[i][0]+maxmat2[i][1])/2
mat111[3][0]=(mat111[0][0]*mat111[1][0]*mat111[2][0])**(1/3)
mat222[3][0]=(mat222[0][0]*mat222[1][0]*mat222[2][0])**(1/3)
if way==0:
pass#wait for define and will choose m1m2 auto
if way==1:
for i in range(3):
mat1[i][i]=mat222[3][0]/mat111[3][0]
mat1[i][3]=mat222[i][1]-mat1[i][i]*mat111[i][1]
if way==2:
for i in range(3):
mat2[i][i]=mat111[3][0]/mat222[3][0]
mat2[i][3]=mat111[i][1]-mat2[i][i]*mat222[i][1]
return mat1,mat2 def beitranbei(maxmat,beimat,potnumber):
mat=np.zeros((3,3),dtype=float)
tran=np.zeros((3),dtype=float)
mat[:,:]=maxmat[:,0:3]
tran[:]=maxmat[:,3]
beimatnew=copy.deepcopy(beimat)
tranv=np.zeros((3),dtype=float)
for i in range(potnumber):
tranv=beimat[i][:]
tranx=np.dot(mat,tranv)
for j in range(3):
beimatnew[i][j]=tranx[j]+tran[j]
return beimatnew
auto-fix
我写这些玩意,在几个大项目里用,在我用手动调整之前,我用的是这个自动调整。
他可以解决,放缩,平移,但不能解决旋转。
way=1和2代表着A往B方向靠,和B往A方向靠的区别。
那个way=0的全自动,其实我很想将两个点集都丢在原点上。可以,但没必要。
这个放缩呢,也很迷,是按照三个尺度的比例来取均值:均值有很多种,算术平均,、平方平均。。。
因为没有更好的方法——你不可能绕过旋转去解决尺寸。
我还有一个工具。
原来,我先取随机子集,在做,这样每个点就有了双重索引——原集序号,子集序号。
在痛定思痛之后,我把这套东西扔光了,变成了这样的东西。
def potmatrandom(potmat,choose,deta):
chooseset=1/choose
potmatnew=[[[[] for i in range(deta)] for j in range(deta)] for k in range(deta)]
for i in range(deta):
for j in range(deta):
for k in range(deta):
for ijk in range(len(potmat[i][j][k])):
t=random.random()
if t<chooseset:
potmatnew[i][j][k].append(potmat[i][j][k][ijk])
return potmatnew
randomchoose
deta是这个序号集的尺寸:deta*deta*deta
choose是多少取1,choose=5的话就是我有0.2的概率保留这个点。
需要指出的是,原来1000个点 ,choose=5,最后可能是200个点,也可能198或者220个。。。随机数的事情,谁说得好呢。反正多一个少一个,问题不大。
你自然可以在存序号的时候就随机。但是如果你可以有两个集——你甚至可以按1--1/2--1/4--1/8这种梯度来做多个集来平衡这个阶段的运算量和精度。
def detadealnew(deta,potnumber,beimat,maxmat):
intmatnew=np.zeros((potnumber,3),dtype=int)
potmat=[[[[] for i in range(deta)] for j in range(deta)] for k in range(deta)]
for i in range(potnumber):
coor=beimat[i,:]
coorback=icp.findxyz(coor,maxmat)
intmatnew[i,0:3]=coorback
potmat[int(coorback[0])][int(coorback[1])][int(coorback[2])].append(i)
return potmat,intmatnew
findzone
这里告诉你一个点集按照某一个划分标准(刚才说过的maxmat),的序号。
def nearestpoint(beimat1,beimat2,potnumber1,potmat2,maxmat2,deta2):
intmatnew=np.zeros((potnumber1,1),dtype=int)
floatmatnew=np.zeros((potnumber1,1),dtype=float)
for i in range(potnumber1):
#for i in range(5):
coor=beimat1[i,:] coorback=icp.findxyz(coor,maxmat2)
#print(coor,":",i,"!!!",coorback)
dis=1000000
index=-1
for j in range(len(potmat2[int(coorback[0])][int(coorback[1])][int(coorback[2])])):
coor2=beimat2[int(potmat2[int(coorback[0])][int(coorback[1])][int(coorback[2])][j]),:]
disnew=icp.distance(coor,coor2)
if disnew<dis:
dis=disnew
index=j
#if dis<100:
#print("ab",i) for i1 in range(3):
k1=coorback[0]-1+i1
for i2 in range(3):
k2=coorback[1]-1+i2
for i3 in range(3):
k3=coorback[2]-1+i3
k4=max(k1,k2,k3)
k5=min(k1,k2,k3)
if k4<deta2 and k5>=0:
for j in range(len(potmat2[k1][k2][k3])):
coor2=beimat2[int(potmat2[k1][k2][k3][j]),:]
#print(coor2,k1,k2,k3)
disnew=icp.distance(coor,coor2)
if disnew<dis:
dis=disnew
index=j
if dis<10000:
intmatnew[i][0]=index
floatmatnew[i][0]=dis
else:
#print(i)
for i1 in range(7):
k1=coorback[0]-3+i1
for i2 in range(7):
k2=coorback[1]-3+i2
for i3 in range(7):
k3=coorback[2]-3+i3
k4=max(k1,k2,k3)
k5=min(k1,k2,k3)
if k4<deta2 and k5>=0:
for j in range(len(potmat2[k1][k2][k3])):
coor2=beimat2[int(potmat2[k1][k2][k3][j]),:]
disnew=icp.distance(coor,coor2)
if disnew<dis:
dis=disnew
index=j
if dis<10000:
intmatnew[i][0]=index
floatmatnew[i][0]=dis
else:
intmatnew[i][0]=-1
floatmatnew[i][0]=0
if i/2500==i//2500:
print(i) return intmatnew,floatmatnew def distance(coor1,coor2):
dis=((coor1[0]-coor2[0])**2+(coor1[1]-coor2[1])**2+(coor1[2]-coor2[2])**2)**0.5
return dis
nearestpoint
这里就是最近点的算法
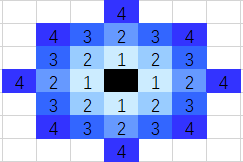
理论上,我们最好按这样的顺序,依次寻找最近点——万一推定的格子里没有点呢?
上面是最好的方法,但是费行数。
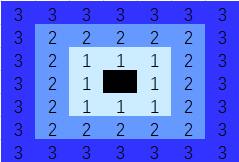
我 就这么找了,你打我啊?
需要指出的是,一定要确认,你搜索的范围,没有超过你定义的网格区域。
我一共8*8*8,我找(0,7,2)的边上的(0,8,2)这格——就没有这格好嘛!
所以,序号不能到deta,也不能小于0。。。
我尝试过很多种数据存储格式,但是都费内存。
我现在用一个整型的数组和一个浮点数组。
整型数组存的最近点的序号。
浮点数组存的距离——但接着我们就会按序号找到xyz三坐标。
这是一种整合信息的尝试——之前的数据存法很头疼
##########number and means of every one
#n: the dim of the X-set
#p: the num of the select point
#samjsq:number of sample
#samzonejsq:number of sample zone(>0)
#beimat :x,y,z for every point potnumber*3
#feimat :A,B,C for every triangle trinumber*3
#maxmat(int),maxmatfirst(float) i0=imax 3*2 #detamat :length of a part in deta 3
#potlist :potnumber in bei of ijk deta*deta*deta
#potmat :sum(potmat)=potnumber deta*deta*deta
#potsample :sample in bei of ijk deta*deta*deta #potsamlist : samjsq*5 i,j,k,beimat,samzonejsq
#potex :zone ijk we have [4]~[4]+[3] samzonejsq*5 i.j.k,sum,start(in samjsq)
#xeimat :all inf for sample samjsq*8 x,y,z,beimat,i,j,k,samzonejsq #samplezone :zone ijk inf deta*deta*deta*3 sum(sam),samjsq,sum(pot)
#nearmatlist: deta*deta*deta nearest ijk(s)
#nearpointfirst the n in xeimat2 samjsq(*1)
#yeimat :all inf for sample samjsq*16 x1,y1,z1,x2,y2,z2;bei1;bei2,i1,j1,k1,szj1,i2,j2,k2,szj2 #lsjsq into samjsq
#potjsq into samzonejsq
old-note
hhhhhhh我自己都很自闭。要命的是,虽然自闭但是自洽。。。
就是,它work,但你根本不知道该从何改起。
icp,tps都是我自己的函数文件。
import numpy as np
import cv2
import tps
import sys
import random
import xlrd
import math
import copy
import icp '''
f=open(r"C:\\Users\\28395\\Desktop\\tpstry\\3.ply",'r')
g=open(r"C:\\Users\\28395\\Desktop\\tpstry\\1.ply",'r')
[potnumber1,trinumber1,beimat1,feimat1,colmat1]=tps.freadold(f,2)
[potnumber2,trinumber2,beimat2,feimat2]=tps.fread(g,2) beimat1=tps.xspinall(beimat1,potnumber1,2087,14450,8150,8189)
beimat2=tps.xspinall(beimat2,potnumber2,214919,353923,229469,314308)
maxmat1=icp.maxmatdeal(beimat1)
maxmat2=icp.maxmatdeal(beimat2)
[mat1,mat2]=icp.beitran(maxmat1,maxmat2,1)
beimat1=icp.beitranbei(mat1,beimat1,potnumber1)
maxmat1=icp.maxmatdeal(beimat1)
[matfix,tfix]=icp.handfix(0.1,0,0.1,0.9,-5,50,-30)
#[matfix,tfix]=icp.handfix(0,0,0.1,0.9,0,50,-30)
beimat1=icp.handfixbei(beimat1,potnumber1,matfix,tfix)
maxmat1=icp.maxmatdeal(beimat1)
for i in range(3):
maxmat2[i][0]+=20
maxmat2[i][1]-=20 fname1="11.ply"
fname2="22.ply"
fname1=tps.plywrite(fname1,beimat1,feimat1,potnumber1,trinumber1)
fname2=tps.plywrite(fname2,beimat2,feimat2,potnumber2,trinumber2)
'''
f=open(r"C:\\Users\\28395\\Desktop\\tpstry\\11.ply",'r')
g=open(r"C:\\Users\\28395\\Desktop\\tpstry\\22.ply",'r')
[potnumber1,trinumber1,beimat1,feimat1]=tps.fread(f,2)
[potnumber2,trinumber2,beimat2,feimat2]=tps.fread(g,2)
maxmat1=icp.maxmatdeal(beimat1)
maxmat2=icp.maxmatdeal(beimat2)
for i in range(3):
maxmat2[i][0]+=20
maxmat2[i][1]-=20 print("end for plywrite")
deta2=32
choose2=5.5
maxmat2=icp.maxmatdeta(maxmat2,deta2) #beimat: xyz *potnumber
#intmat: i,j,k,n in bei2 *potnumber
intmat1=np.zeros((potnumber1,7),dtype=int)
floatmat1=np.zeros((potnumber1,7),dtype=float) [potmat2,intmatnew2]=icp.detadealnew(deta2,potnumber2,beimat2,maxmat2)
potmatnew2=icp.potmatrandom(potmat2,choose2,deta2)
[intmatnew1,floatmatnew1]=icp.nearestpoint(beimat1,beimat2,potnumber1,potmatnew2,maxmat2,deta2) for i in range(potnumber1):
intmat1[i][6]=intmatnew1[i][0]
floatmat1[i][3:6]=beimat2[int(intmatnew1[i][0]),:]
intmat1[i][3:6]=intmatnew2[int(intmatnew1[i][0]),:]
floatmat1[i,0:3]=beimat1[i,:]
floatmat1[i][6]=floatmatnew1[i][0]
main
前面有大段注释。
嗯?那才是重要的!
我手动调教后,就不需要每次再调了!!!!
我直接引用那个调好的不就vans了么?
嘿嘿嘿!
发出了政委的笑声。
ICP&TPS:最近邻的更多相关文章
- NDT(Normal Distribution Transform) 算法(与ICP对比)和一些常见配准算法
原文地址:http://ghx0x0.github.io/2014/12/30/NDT-match/ By GH 发表于 12月 30 2014 目前三维配准中用的较多的是ICP迭代算法,需要提供一个 ...
- ICP(迭代最近点)算法
图像配准是图像处理研究领域中的一个典型问题和技术难点,其目的在于比较或融合针对同一对象在不同条件下获取的图像,例如图像会来自不同的采集设备,取自不同的时间,不同的拍摄视角等等,有时也需要用到针对不同对 ...
- PCL学习笔记二:Registration (ICP算法)
原文:http://blog.csdn.net/u010696366/article/details/8941938 PCL Registration API Registration:不断调整,把不 ...
- MySQL 优化之 ICP (index condition pushdown:索引条件下推)
ICP技术是在MySQL5.6中引入的一种索引优化技术.它能减少在使用 二级索引 过滤where条件时的回表次数 和 减少MySQL server层和引擎层的交互次数.在索引组织表中,使用二级索引进行 ...
- ICP算法(Iterative Closest Point迭代最近点算法)
标签: 图像匹配ICP算法机器视觉 2015-12-01 21:09 2217人阅读 评论(0) 收藏 举报 分类: Computer Vision(27) 版权声明:本文为博主原创文章,未经博主允许 ...
- QPS 与 TPS 简介
QPS:Queries Per Second意思是"每秒查询率",是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准. TPS是Tra ...
- ICP 算法
ICP 算法是一种点云到点云的配准方法. 在SLAM中通过空间点云的配准(可以通过相机或者3D激光雷达获取点云数据),可以估计相机运动(机器人运动,旋转矩阵R与平移向量t),累积配准,并不断回环检测, ...
- 系统吞吐量(TPS)、用户并发量
PS:下面是性能测试的主要概念和计算公式,记录下: 一.系统吞度量要素: 一个系统的吞度量(承压能力)与request对CPU的消耗.外部接口.IO等等紧密关联. 单个reqeust 对CPU消耗越高 ...
- [转]MySQL关键性能监控(QPS/TPS)
原文链接:http://www.cnblogs.com/chenty/p/5191777.html 工作中尝尝会遇到各种数据库性能调优,除了查看某条SQL执行时间长短外,还需要对系统的整体处理能力有更 ...
随机推荐
- C++ getline函数用法详解
转载自http://c.biancheng.net/view/1345.html 虽然可以使用 cin 和 >> 运算符来输入字符串,但它可能会导致一些需要注意的问题. 当 cin 读取数 ...
- 红黑树之 原理和算法详细介绍(阿里面试-treemap使用了红黑树) 红黑树的时间复杂度是O(lgn) 高度<=2log(n+1)1、X节点左旋-将X右边的子节点变成 父节点 2、X节点右旋-将X左边的子节点变成父节点
红黑树插入删除 具体参考:红黑树原理以及插入.删除算法 附图例说明 (阿里的高德一直追着问) 或者插入的情况参考:红黑树原理以及插入.删除算法 附图例说明 红黑树与AVL树 红黑树 的时间复杂度 ...
- 面试官,我会写二分查找法!对,没有 bug 的那种!
前言科普 第一篇二分搜索论文是 1946 年发表,然而第一个没有 bug 的二分查找法却是在 1962 年才出现,中间用了 16 年的时间. 2019 年的你,在面试的过程中能手写出没有 bug 的二 ...
- C# convert between Image and Base64string
static void ImageMSDemo(string picPath) { byte[] imageArray = System.IO.File.ReadAllBytes(picPath); ...
- AQS(抽象队列同步器)
AQS(全称为AbstractQueuedSynchronizer),即抽象队列同步器,它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列. state的访问方 ...
- CMD查看redis
进入redis安装目录执行 redis-cli.exe -h 127.0.0.1 -p 6379
- 8.智能快递柜SDK(联网型锁板)
1.智能快递柜(开篇) 2.智能快递柜(终端篇) 3.智能快递柜(通信篇-HTTP) 4.智能快递柜(通信篇-SOCKET) 5.智能快递柜(通信篇-Server程序) 6.智能快递柜(平台篇) 7. ...
- SSH免密码登录和Git免密操作
SSH免密码登录和Git免密操作 每次打完包后都需要把包传到对应的服务器上从而让测试人员下载安装,但是每次ssh或scp时都需要重新输入密码:使用git代码托管平台只要修改了密码就需要输入密码.本文主 ...
- mssql sqlserver 使用sql脚本实现相邻两条数据相减的方法分享
摘要: 下文讲述使用sql脚本实现相邻两条数据相减的方法,如下所示: 实验环境:sql server 2008 R2 实现思路: 1.使用cte表达式,对当前表进行重新编号 2.使用左连接对 表达式 ...
- Python—端口检测(socket)
基于python检测端口是否在使用 原理:创建一个socket服务,连接对应的 ip:port ,如果能够连接,说明端口被占用:若端口可用,则不可连接. #!/usr/bin/evn python # ...