Python网络爬虫——BeautifulSoup4库的使用
使用requests库获取html页面并将其转换成字符串之后,需要进一步解析html页面格式,提取有用信息。
BeautifulSoup4库,也被成为bs4库(后皆采用简写)用于解析和处理html和xml。
1.调用
bs4库中最主要的便是bs类了,每个实例化的对象都相当于一个html页面
需要采用from-import导入bs类,同时通过BeautifulSoup()创建一个bs对象
代码如下:
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com/")
r.encoding="utf-8"
soup=BeautifulSoup(r.text)
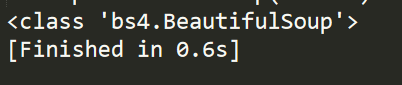
print(type(soup))
运行结果:
2.常用属性
创建的BeautifulSoup对象是一个树形结构,它包含html页面中的每一个Tag(标签)元素,可以通过<a>.<b>的形式获得
常见的属性如下:
head:
html页面<head>内容
title:
html页面标题,在<head>之中,由<title>标记
body:
html页面<body>内容
p:
html页面第一个<p>内容
strings:
html页面所有呈现在web上的字符串,即标签的内容
stripped_string:
html页面所有呈现在web上的非空字符串

接下来尝试爬取百度的标语“百度一下,你就知道”
首先我们通过requests来建立请求,可以通过查看源代码找到对应部分
如下所示:
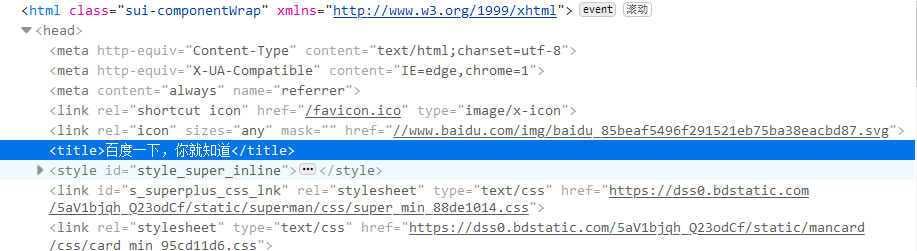
所以直接通过调用<title>标签即可
代码如下:
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com/")
r.encoding="utf-8"
soup=BeautifulSoup(r.text)
title=soup.title
print(title)
结果如图所示:

3.标签常用属性
每一个标签在bs4中也是一个对象,被称为tag对象,以糯米为例,常见结构如下:
<a class=“mnav” href="http://www.nuomi.com">糯米</a>
其中尖括号(<>)中标签的名字为 name,其他项为attrs,尖括号之间的内容为string
所以常见的标签属性分为4种
name:
字符串、标签的名字
attrs:
字典、包含了原来页面tag的所有属性,比如href
contrnts:
列表、tag下所有子tag的内容
string:
字符串、tag所包含的文本,网页中的真实文字
由于html可以在标签中嵌套其他的标签,所以string返回遵循以下原则
①如果标签内没有其他标签,string属性返回其中的内容
②如果标签内部还有标签,但只有一个标签,string返回最里面的标签内容
③如果内部超过1层嵌套标签,则返回为none
依然以百度为例,我们需要找到第一个<a>标签的string代码应当如下:
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com/")
r.encoding="utf-8"
soup=BeautifulSoup(r.text)
print(soup.a.string)
结果如图所示:

4.调用find()与find_all()
html中,同一个特标签会有很多内容,比如百度首页<a>一共有13处,但值返回第一处
所以这时候需要通过find与find_all来寻找,这两个方法都会遍历html文档按照条件返回内容
使用方法如下:
BeautifulSoup.find_all(name,attrs,recursive,string,limit)
name:以标签名字进行搜索,名字用字符串类型表示
attrs:按照标签的属性来搜索,需要列出属性的名字和值,用json方法表示
recursive:设置查找层次,只查找当前标签的西一层时使用recursiv=false
string:按照关键字查找string属性内容,采用string=开始
limit:返回结果个数,默认全部
至于find()使用方法如find_all()相同,
BeautifulSoup.find_all(name,attrs,recursive,string)
区别在于find()只搜索第一个结果,find_all()返回所有结果。
我们尝试来通过find_all()来获取所有含有“百度”这一关键词的标签
首先需要调用re库,re是python的标准库可以采用compile()对字符串的检索
所以代码如下:
import requests
import re
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com/")
r.encoding="utf-8"
soup=BeautifulSoup(r.text)
w=soup.find_all(string=re.compile("百度"))
print(w)
结果如下:

Python网络爬虫——BeautifulSoup4库的使用的更多相关文章
- Python网络爬虫:空姐网、糗百、xxx结果图与源码
如前面所述,我们上手写了空姐网爬虫,糗百爬虫,先放一下传送门: Python网络爬虫requests.bs4爬取空姐网图片Python爬虫框架Scrapy之爬取糗事百科大量段子数据Python爬虫框架 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
随机推荐
- 学习笔记15_ASP母版页
*网页母版页设计通用样式#header:{height:100px;width:1000px}#leftDiv:{float:left;width:200px}#mainDiv:{margin-lef ...
- 学习笔记47_关于Session局限性问题,Memcache
三大问题: 1.Session性能问题 2.不能稳定输出.考虑使用进程外Session 3.组成集群,登录数据进行共享 (比如说像百度,百度网盘,百度文库等是使用不同的服务机器的,怎样避免使用的时候不 ...
- 利用AXI VDMA实现OV5640摄像头采集笔记(二)
导读:摄像头采样图像数据后经过VDMA进入DDR,通过PS部分控制,经过三级缓存,将DDR中保持的图形数据通过VDMA发送出去.在FPGA的接收端口产生VID OUT时序驱动HDMI显示器显示图形. ...
- Pandas常用基本功能
Series 和 DataFrame还未构建完成的朋友可以参考我的上一篇博文:https://www.cnblogs.com/zry-yt/p/11794941.html 当我们构建好了 Series ...
- [考试反思]0822NOIP模拟测试29:延续
想保持优秀很困难 但是想持续垫底却很简单 但是你不想垫底的话持续垫底也很容易... 分AB卷,A卷共15人. skyh,tdcp,kx155,B哥145... 我:35,倒数第一. 板子专题,爆零快乐 ...
- CSS(5)---通俗讲解盒子模型
CSS(5)---盒子模型 盒子模型四个关键字:内容(content).填充(padding).边框(border).边界(margin), CSS盒子模式都具备这些属性. 一.概念 1. 概念 盒子 ...
- js动态显示当前时间+数字大小转换+小于9前面补0
<script type="text/javascript"> function getTime(){ var myDate = new Date(); // 年份 d ...
- 格式工厂转化成mp4 avc格式 暴风影音不能播放的解决方法
格式工厂转化成mp4 avc格式 暴风影音不能播放的解决方法 先转成其他mp4 确保能播放 然后再转成avc
- 如何使用24行JavaScript代码实现Redux
作者:Yazeed Bzadough 译者:小维FE 原文:freecodecamp 为了保证文章的可读性,本文采用意译而非直译. 90%的规约,10%的库. Redux是迄今为止创建的最重要的Jav ...
- html与css连接代码
demo01.html: <!DOCTYPE html><html> <head> <meta charset="utf-8"> ...