Dubbo学习系列之十二(Quartz任务调度)
Quartz词义为"石英"水晶,然后聪明的人类利用它发明了石英手表,因石英晶体在受到电流影响时,它会产生规律的振动,于是,这种时间上的规律,也被应用到了软件界,来命名了一款任务调度框架--Quartz。现实软件逻辑中,周期任务有着广泛的存在,如定时刷新配置信息,定期盘点库存,定时收发邮件等,至于定时任务处理,也有Spring的ScheduledThreadPool,还有基于注解@Scheduled的方式,ScheduledThreadPool主要是基于相对时间,不方便控制,而@Scheduled则会导致连锁错误,所以我们来用下Quartz,看看有啥优势。
工具:Idea201902/JDK11/ZK3.5.5/Gradle5.4.1/RabbitMQ3.7.13/Mysql8.0.11/Lombok0.26/Erlang21.2/postman7.5.0/Redis3.2/RocketMQ4.5.2/Sentinel1.6.3/SpringBoot2.1.6/Quartz2.3.1/Nacos1.1.3
难度: 新手--战士--老兵--大师
目标:1.使用Quartz实现物流订单定期延误检查;
步骤:
1.整体框架依旧,多模块微服务框架商城系统,一个共享模块,多个功能模块,具体见项目代码结构。
2.按照惯例,先上几个Quartz的核心概念的菜:
Job-任务:一个接口,只有一个execute方法,使用时该方法内容即为需要执行的任务逻辑,还有个关联的JobDetail接口,注意这两者并不是继承关系,Quartz在每次执行Job时,都重新创建一个Job实例,所以它不直接接受一个Job的实例,相反它接收一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。因此需要通过一个类来描述Job的实现类及其它相关的静态信息,如Job名字、描述、关联监听器等信息,JobDetail承担了这一角色,Quartz源码中描述两者关系:"Quartz不会保存一个Job接口的实例,但可以通过JobDetail来定义一个实例",JobDetail包含一个getJobClass()获得Job实例字节码的方法;
Trigger-触发器:手枪的扳机,什么时候发射,就看什么时候触发了该类设定的条件,可自由定义触发规则,多个触发器可作用于一个Job,但一个触发器只可作用于一个Job;
Scheduler-调度器:代表一个Quartz的独立运行容器,Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的);
3.先做个简单的上手小菜,定义一个HelloJob类,内容就是打印HelloWrold:
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println(System.currentTimeMillis()+"helloWorld");
}
}
再直接使用main入口,定义jobDetail -->Trigger-->Scheduler,可以看到这里并没有直接使用HelloJob类,而是以Class形式放入JobDetail 中,很明显使用的就是Java反射机制了,代码清晰简单,不解释了。
public class ScheduledTaskMain {
public static void main(String[] args) throws SchedulerException {
/*创建一个jobDetail的实例,将该实例与HelloJob Class绑定*/
JobDetail jobDetail = JobBuilder.newJob(HelloJob.class).withIdentity("HelloJob").build();
/*创建一个触发器,每2秒执行一次任务,一直持续下去*/
SimpleTrigger cronTrigger= TriggerBuilder.newTrigger().withIdentity("HelloTrigger").startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2).repeatForever()).build();
/*创建schedule实例*/
StdSchedulerFactory factory = new StdSchedulerFactory();
Scheduler scheduler = factory.getScheduler();
/*将Job和trigger放入Scheduler容器*/
scheduler.scheduleJob(jobDetail,cronTrigger);
scheduler.start();
}
}
4.愉快地跑一个:

从输出可以看到Quartz内部系列对象的创建过程,并建立了10线程的ThreadPool,最后执行了HelloWorld任务。
5.当然,我们的主菜不可能是做HelloWorld任务,那还不简单!改起来!为了试验方便,我只改动logistic模块,新建一个Job类:com.biao.mall.logistic.schedule.HelloJob2,直接注入SpringBean任务,这个任务就是定期检查过期未发的物流单,具体见deliveryService.checkDelayed()方法:
@Component
@DisallowConcurrentExecution //标识这个任务是串行执行,不是并发执行
public class HelloJob2 implements Job, Serializable {
@Autowired
private DubboDeliveryService deliveryService; /*经测试,下面这种构造方法注入deliveryService的方式会导致NPE!*/
/* @Autowired
public HelloJob2(DubboDeliveryService deliveryService){
this.deliveryService = deliveryService;
} public HelloJob2(){}
*/
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
int num = deliveryService.checkDelayed();
System.out.println("delayed num is >>> "+ num);
}
}
com.biao.mall.logistic.impl.DubboDeliveryServiceImpl中,实现deliveryService.checkDelayed()方法:
//检查延误未发的物流单,
/*仅供逻辑测试,直接查找出所有10天之前的订单,生产逻辑肯定比这复杂*/
@Override
public int checkDelayed() {
QueryWrapper qw = new QueryWrapper();
LocalDateTime timeNow = LocalDateTime.now(ZoneId.systemDefault());
qw.lt(true,"gmt_create",timeNow.minusDays(10L));
List<DubboDeliveryEntity> list = deliveryDao.selectList(qw);
return Objects.isNull(list)? 0: list.size();
}
再将ScheduledTaskMain中替换为Job2,运行结果NPE:

这就有点让人失望了,原因在哪?这是因为通过实现Job接口的方式来创建定时任务,这个类在实例化时是被Quartz实例化的,同时没有注入到Spring中。而自定义的Service是Spring容器管理的,因此就导致了被Spring所管理的Bean不能被自动注入进来,Quartz也无法感知自定义的ServiceBean的存在!
6.关于@DisallowConcurrentExecution 注解:即该Job不并发执行,比如当前一个Job未执行完,而下一个Job也满足Trigger条件,此时就会被阻塞。(详细解释请见后记)
7.该NPE解决思路,就是要将Scheduler也纳入Spring容器管理, 先定义com.biao.mall.logistic.schedule.MyJobFactory,继承自AdaptableJobFactory:
AdaptableJobFactory 是一个支持Runnable和Job对象的工厂,实现了JobFactory接口;
TriggerFiredBundle是一个接收从JobStore到QuartzSchedulerThread执行时数据的类;
@Component
public class MyJobFactory extends AdaptableJobFactory {
/**
* AutowireCapableBeanFactory接口是BeanFactory的子类
* 可以连接和填充那些生命周期不被Spring管理的已存在的bean实例
*/
private AutowireCapableBeanFactory capableBeanFactory; @Autowired
public MyJobFactory(AutowireCapableBeanFactory capableBeanFactory){
this.capableBeanFactory = capableBeanFactory;
} @Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception{
//调用父类方法
Object jobInstance = super.createJobInstance(bundle);
//进行注入(Spring接管该Bean)
capableBeanFactory.autowireBean(jobInstance);
return jobInstance;
}
}
8.再定义一个com.biao.mall.logistic.schedule.QuartzConf配置类,可以通过SchedulerFactoryBean这个桥梁来完成ApplicationContext和SchedulerContext关联,如下,再运行程序即正常执行!
@Configuration
public class QuartzConfig {
//不推荐这里注解@Autowired,使用构造函数注入
private MyJobFactory myJobFactory;
@Autowired
public QuartzConfig(MyJobFactory myJobFactory){
this.myJobFactory = myJobFactory;
}
@Bean(name = "factoryBean")
public SchedulerFactoryBean schedulerFactoryBean(){
// Spring提供SchedulerFactoryBean为Scheduler提供配置信息,并被Spring容器管理其生命周期
SchedulerFactoryBean factoryBean = new SchedulerFactoryBean();
factoryBean.setOverwriteExistingJobs(true);
//设置是否自动启动
factoryBean.setAutoStartup(false);
//设置系统启动后,Starting Quartz Scheduler的延迟时间
factoryBean.setStartupDelay(30);
// 设置自定义Job Factory,用于Spring管理Job bean
factoryBean.setJobFactory(myJobFactory);
return factoryBean;
} @Bean(name = "myScheduler")
public Scheduler getScheduler(){
Scheduler scheduler = schedulerFactoryBean().getScheduler();
return scheduler;
}
}
来看点SchedulerFactoryBean的源码(部分):
/**
* {@link FactoryBean} that creates and configures a Quartz {@link org.quartz.Scheduler},
* manages its lifecycle as part of the Spring application context, and exposes the
* Scheduler as bean reference for dependency injection.
*
* <p>Allows registration of JobDetails, Calendars and Triggers, automatically
* starting the scheduler on initialization and shutting it down on destruction.
* In scenarios that just require static registration of jobs at startup, there
* is no need to access the Scheduler instance itself in application code.
// 代码省略部分 ... ...
*/
public class SchedulerFactoryBean extends SchedulerAccessor implements FactoryBean<Scheduler>,
BeanNameAware, ApplicationContextAware, InitializingBean, DisposableBean, SmartLifecycle { public static final String PROP_THREAD_COUNT = "org.quartz.threadPool.threadCount";
public static final int DEFAULT_THREAD_COUNT = 10;
private static final ThreadLocal<ResourceLoader> configTimeResourceLoaderHolder = new ThreadLocal<>();
private static final ThreadLocal<Executor> configTimeTaskExecutorHolder = new ThreadLocal<>();
private static final ThreadLocal<DataSource> configTimeDataSourceHolder = new ThreadLocal<>();
private static final ThreadLocal<DataSource> configTimeNonTransactionalDataSourceHolder = new ThreadLocal<>();
// 代码省略部分 ... ...
//---------------------------------------------------------------------
// 实现接口InitializingBean,即SpringBean生命周期中的afterPropertiesSet()方法,dataSource是持久化属性,
@Override
public void afterPropertiesSet() throws Exception {
if (this.dataSource == null && this.nonTransactionalDataSource != null) {
this.dataSource = this.nonTransactionalDataSource;
} if (this.applicationContext != null && this.resourceLoader == null) {
this.resourceLoader = this.applicationContext;
} // 初始化Scheduler实例,将Jobs/Triggers注册
this.scheduler = prepareScheduler(prepareSchedulerFactory());
try {
registerListeners();
registerJobsAndTriggers();
}
catch (Exception ex) {
try {
this.scheduler.shutdown(true);
}
catch (Exception ex2) {
logger.debug("Scheduler shutdown exception after registration failure", ex2);
}
throw ex;
}
}
// 代码省略部分 ... ...
/**
* 初始化当前的SchedulerFactory, 应用本地定义的属性值
* @param参数schedulerFactory为需要初始化的对象
*/
private void initSchedulerFactory(StdSchedulerFactory schedulerFactory) throws SchedulerException, IOException {
Properties mergedProps = new Properties();
if (this.resourceLoader != null) {
mergedProps.setProperty(StdSchedulerFactory.PROP_SCHED_CLASS_LOAD_HELPER_CLASS,
ResourceLoaderClassLoadHelper.class.getName());
} if (this.taskExecutor != null) {
mergedProps.setProperty(StdSchedulerFactory.PROP_THREAD_POOL_CLASS,
LocalTaskExecutorThreadPool.class.getName());
}
else {
// 设置必要的默认属性,Quartz会使用显式属性设置覆盖默认属性
mergedProps.setProperty(StdSchedulerFactory.PROP_THREAD_POOL_CLASS, SimpleThreadPool.class.getName());
mergedProps.setProperty(PROP_THREAD_COUNT, Integer.toString(DEFAULT_THREAD_COUNT));
} if (this.configLocation != null) {
if (logger.isInfoEnabled()) {
logger.info("Loading Quartz config from [" + this.configLocation + "]");
}
PropertiesLoaderUtils.fillProperties(mergedProps, this.configLocation);
} CollectionUtils.mergePropertiesIntoMap(this.quartzProperties, mergedProps);
if (this.dataSource != null) {
mergedProps.put(StdSchedulerFactory.PROP_JOB_STORE_CLASS, LocalDataSourceJobStore.class.getName());
}
if (this.schedulerName != null) {
mergedProps.put(StdSchedulerFactory.PROP_SCHED_INSTANCE_NAME, this.schedulerName);
} schedulerFactory.initialize(mergedProps);
}
// 代码省略部分 ... ...
/**
* 根据给定的factory 和scheduler name生成Scheduler实例,由afterPropertiesSet调用
缺省实现将触发SchedulerFactory的getScheduler方法
* @param 参数schedulerFactory生产Scheduler的工厂
* @param schedulerName the name of the scheduler to create
* @return the Scheduler instance
* @throws SchedulerException if thrown by Quartz methods
* @see #afterPropertiesSet
* @see org.quartz.SchedulerFactory#getScheduler
*/
protected Scheduler createScheduler(SchedulerFactory schedulerFactory, @Nullable String schedulerName)
throws SchedulerException { // Override thread context ClassLoader to work around native Quartz ClassLoadHelper loading.
Thread currentThread = Thread.currentThread();
ClassLoader threadContextClassLoader = currentThread.getContextClassLoader();
boolean overrideClassLoader = (this.resourceLoader != null &&
this.resourceLoader.getClassLoader() != threadContextClassLoader);
if (overrideClassLoader) {
currentThread.setContextClassLoader(this.resourceLoader.getClassLoader());
}
try {
SchedulerRepository repository = SchedulerRepository.getInstance();
synchronized (repository) {
Scheduler existingScheduler = (schedulerName != null ? repository.lookup(schedulerName) : null);
Scheduler newScheduler = schedulerFactory.getScheduler();
if (newScheduler == existingScheduler) {
throw new IllegalStateException("Active Scheduler of name ' " + schedulerName + " ' already registered " +
"in Quartz SchedulerRepository. Cannot create a new Spring-managed Scheduler of the same name!");
}
if (!this.exposeSchedulerInRepository) {
// Need to remove it in this case, since Quartz shares the Scheduler instance by default!
SchedulerRepository.getInstance().remove(newScheduler.getSchedulerName());
}
return newScheduler;
}
}
finally {
if (overrideClassLoader) {
// 重置初始的线程ClassLoader.
currentThread.setContextClassLoader(threadContextClassLoader);
}
}
}
/**
* 将指定的或当前的ApplicationContext暴露给Quartz SchedulerContext.
*/
private void populateSchedulerContext(Scheduler scheduler) throws SchedulerException {
// 将对象放入Scheduler context.
if (this.schedulerContextMap != null) {
scheduler.getContext().putAll(this.schedulerContextMap);
}
// 在Scheduler context中注册ApplicationContext.
if (this.applicationContextSchedulerContextKey != null) {
if (this.applicationContext == null) {
throw new IllegalStateException(
"SchedulerFactoryBean needs to be set up in an ApplicationContext " +
"to be able to handle an ' applicationContextSchedulerContextKey'");
}
scheduler.getContext().put(this.applicationContextSchedulerContextKey, this.applicationContext);
}
}
/**
* 根据startupDelay设置启动Scheduler,注意这里是异步启动
* @param scheduler the Scheduler to start
* @param startupDelay the number of seconds to wait before starting
* the Scheduler asynchronously
*/
protected void startScheduler(final Scheduler scheduler, final int startupDelay) throws SchedulerException {
if (startupDelay <= 0) {
logger.info("Starting Quartz Scheduler now");
scheduler.start();
}
else {
if (logger.isInfoEnabled()) {
logger.info("Will start Quartz Scheduler [" + scheduler.getSchedulerName() +
"] in " + startupDelay + " seconds");
}
// 因这里明确需要一个守护线程,所以不使用Quartz的startDelayed方法,
// 这样当其他线程全部终止时,应用就终止,JVM也会退出
Thread schedulerThread = new Thread() {
@Override
public void run() {
try {
Thread.sleep(TimeUnit.SECONDS.toMillis(startupDelay));
}
catch (InterruptedException ex) {
Thread.currentThread().interrupt();
// 简单处理
}
if (logger.isInfoEnabled()) {
logger.info("Starting Quartz Scheduler now, after delay of " + startupDelay + " seconds");
}
try {
scheduler.start();
}
catch (SchedulerException ex) {
throw new SchedulingException("Could not start Quartz Scheduler after delay", ex);
}
}
};
schedulerThread.setName("Quartz Scheduler [" + scheduler.getSchedulerName() + "]");
schedulerThread.setDaemon(true); // 指定thread为deamon类型
schedulerThread.start();
}
}
// 代码省略部分 ... ...
}
类描述的两段:此类作为Bean工厂产生并配置Scheduler,并将其纳入Spring应用上下文中的Bean生命周期管理;提供JobDetails, Calendars and Triggers的注册,在应用启动时,自动启动Scheduler,在应用关闭时,自动停止Scheduler;
实现了ApplicationContextAware接口,即能被ApplicationContext接管,所以这之后使用ApplicationContext.getBean()也可取得Scheduler;
多个static final型的类变量,其DEFAULT_THREAD_COUNT指定了Quartz后台线程池大小,几个ThreadLocal用于保存线程Context,这也是Job能保持独立性的关键基础;
initSchedulerFactory方法初始化当前的SchedulerFactory, 应用本地定义的属性值,比如指定线程池大小;
afterPropertiesSet方法,通过实现接口InitializingBean,使用SpringBean生命周期中的afterPropertiesSet()方法来设置Scheduler;
createScheduler创建Scheduler,并交给Spring来接管,并对“同名Scheduler”异常做处理;
startScheduler异步守护线程方式启动Scheduler;
总结,Scheduler就是一个容器,有自己的内部对象和上下文,属于重量级对象,理解上可以类比SpringContext,可使用scheduler.getContext()取得上下文信息。
9.Quartz的任务管理,通过Scheduler可以start、pause、resume、stop,addJob和deleteJob等重要方法来调度Job的执行。这里只需要注意一点,如果stop之后,就无法再直接start,必须重启应用,不知道这个是否属于bug。
10.定义一个com.biao.mall.logistic.schedule.QuartzService类,来封装这些方法:
@Service
public class QuartzService {
private final String groupName = "group1"; @Autowired
@Qualifier(value = "factoryBean")
private SchedulerFactoryBean factoryBean; //以下方式也可以获取bean
// Scheduler scheduler = SpringUtil.getBean("myScheduler");
@Autowired
@Qualifier(value = "myScheduler")
private Scheduler scheduler; // 启动 Scheduler
public void startScheduleJobs() throws SchedulerException {
if (this.scheduler.isStarted()){
return;
}
this.setCheckScheduler(scheduler);
this.scheduler.start(); } // 停止 Scheduler
public void stopScheduleJobs() {
scheduler = factoryBean.getScheduler();
try {
if (!scheduler.isShutdown()){
scheduler.shutdown();
}
} catch (SchedulerException e) {
e.printStackTrace();
}
} // 添加 Job 并替换
public void addJobandReplace(){
//打印hellowrold的job
JobDetail jobDetail = JobBuilder.newJob(HelloJob.class).withIdentity("HelloJob").storeDurably(true).build();
// 第二个参数为replace,是否替换存在的同名job
// jobDetail必须是durable属性,表示任务完成之后是否依然保留到数据库,且无定义关联的trigger
try {
this.scheduler.addJob(jobDetail,true);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
// 添加 Job 不替换
public void addJobwithoutReplace(){
//打印hellowrold的job
JobDetail jobDetail = JobBuilder.newJob(HelloJob.class).withIdentity("HelloJob").storeDurably(true).build();
// 第二个参数为replace,是否替换存在的同名job
try {
this.scheduler.addJob(jobDetail,false);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
// 暂停所有 Job,还可指定具体的Job
public void pauseScheduler(){
try {
this.scheduler.pauseAll();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
// 恢复并继续所有Job执行,还可指定具体的Job
public void resumeJobs(){
try {
this.scheduler.resumeAll();
} catch (SchedulerException e) {
e.printStackTrace();
}
} //配置一个自定义的scheduler
private void setCheckScheduler(Scheduler scheduler) throws SchedulerException {
//添加HelloJob2作为任务内容
JobDetail jobDetail = JobBuilder.newJob(HelloJob2.class)
.withIdentity("job1",groupName).build();
//cron表达式制定触发规则,每10秒执行一次
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("0/10 * * * * ?");
CronTrigger cronTrigger = TriggerBuilder.newTrigger().withIdentity("trigger1",groupName)
.withSchedule(scheduleBuilder).build();
scheduler.scheduleJob(jobDetail,cronTrigger);
}
}
还有不少其他方法,就不一一列举了,注意下:
setCheckScheduler()中加入自定义的JobDetail和Trigger,并注册进Scheduler容器,如果有多个,就定义多个类似方法加入即可,然后startScheduleJobs()启动Scheduler;
cron表达式:用一个cron字符串表示一个时间规则;
11.测试:启动ZK-->Nacos-->RocketMQ-->business-->logistic, 写几个简陋的controller方法:
@RestController
public class DubboDeliveryController { // 代码省略部分 ... ... @RequestMapping("/delivery/start")
public String start() throws SchedulerException {
quartzService.startScheduleJobs();
return "startScheduleJobs success";
}
@RequestMapping("/delivery/stop")
public String stop(){
quartzService.stopScheduleJobs();
return "stopScheduleJobs success";
}
@RequestMapping("/delivery/add")
public String addJob(){
quartzService.addJobandReplace();
return "addJobandReplace success";
}
@RequestMapping("/delivery/pause")
public String pauseJob(){
quartzService.pauseScheduler();
return "pauseScheduler success";
}
@RequestMapping("/delivery/resume")
public String resumeJob(){
quartzService.resumeJobs();
return "resumeJobs success";
}
}
数据库情况:

URL给个访问:

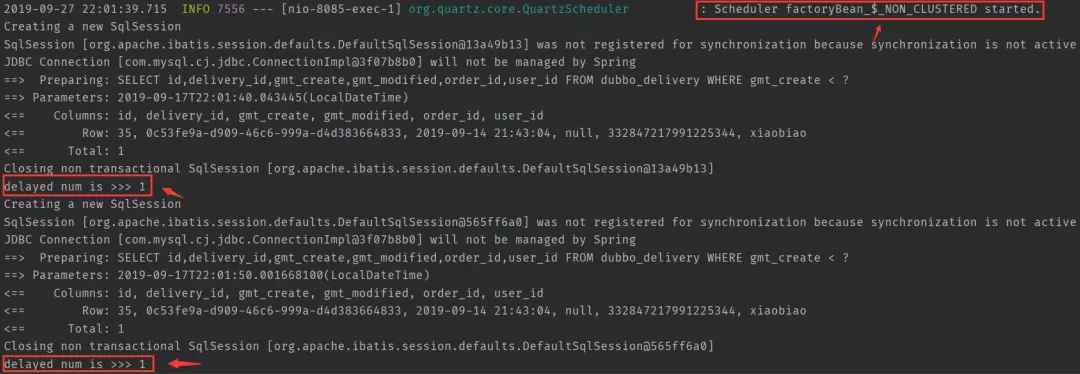
结果:
12.项目代码地址:其中的day15 https://github.com/xiexiaobiao/dubbo-project.git
后记:
1.Quartz使用FixedThreadPool(固定数线程池)来执行Job,默认数量为10(本例中可通过QuartzConfig修改),此ThreadPool接收Runnable对象,如果并发过大,就阻塞。各线程通过ThreadLocal来保存自己的独立上下文。
2.关于Job并发解释:
Job有一个StatefulJob子接口,代表有状态的任务,该接口是一个没有方法的标签接口,其目的是让Quartz知道任务的类型,以便采用不同的执行方案。无状态任务在执行时拥有自己的JobDataMap拷贝,对JobDataMap的更改不会影响下次的执行。而有状态任务共享同一个JobDataMap实例,每次任务执行对JobDataMap所做的更改会保存下来,后面的执行可以看到这个更改,也即每次执行任务后都会对后面的执行发生影响。
正因为这个原因,无状态的Job可以并发执行,而有状态的StatefulJob不能并发执行,这意味着如果前次的StatefulJob还没有执行完毕,下一次的任务将阻塞等待,直到前次任务执行完毕。有状态任务比无状态任务需要考虑更多的因素,程序往往拥有更高的复杂度,因此除非必要,应该尽量使用无状态的Job。
如果Quartz使用了数据库持久化任务调度信息,无状态的JobDataMap仅会在Scheduler注册任务时保持一次,而有状态任务对应的JobDataMap在每次执行任务后都会进行保存。
3.Quartz支持集群模式和持久化机制,可以写入后台DB进行保存和恢复。请君自行研究。另寻时间我另起一篇。
4.为什么Quartz的各个Job执行互不影响?源码注释:
"Note that Quartz instantiates a new Job for each execution, in contrast to Timer which uses a TimerTask instance that is shared between repeated executions. Just JobDetail descriptors are shared."
核心总结即“每次执行Quartz都是实例化一个新的Job”!
5.Cron表达式在线生成,轻轻松松不伤脑:http://cron.qqe2.com/
推荐阅读:

Dubbo学习系列之十二(Quartz任务调度)的更多相关文章
- Dubbo学习系列之十五(Seata分布式事务方案TCC模式)
上篇的续集. 工具: Idea201902/JDK11/Gradle5.6.2/Mysql8.0.11/Lombok0.27/Postman7.5.0/SpringBoot2.1.9/Nacos1.1 ...
- Dubbo学习系列之十六(ELK海量日志分析框架)
外卖公司如何匹配骑手和订单?淘宝如何进行商品推荐?或者读者兴趣匹配?还有海量数据存储搜索.实时日志分析.应用程序监控等场景,Elasticsearch或许可以提供一些思路,作为业界最具影响力的海量搜索 ...
- Dubbo学习系列之十(Sentinel之限流与降级)
各位看官,先提个问题,如果让你设计一套秒杀系统,核心要点是啥???我认为有三点:缓存.限流和分离.想当年12306大面积崩溃,还有如今的微博整体宕机情况,感觉就是限流降级没做好,"用有限的资 ...
- Dubbo学习系列之十八(Skywalking服务跟踪)
我们知道,微服务不是独立的存在,否则就不需要微服务这个架构了,那么当发起一次请求,如何知道这次请求的轨迹,或者说遇到响应缓慢. 请求出错的情况,我们该如何定位呢?这就涉及到APM(Applicatio ...
- WP8.1学习系列(第二十二章)——在页面之间导航
在本文中 先决条件 创建导航应用 Frame 和 Page 类 页面模板中的导航支持 在页面之间传递信息 缓存页面 摘要 后续步骤 相关主题 重要的 API Page Frame Navigation ...
- Dubbo学习系列之十四(Seata分布式事务方案AT模式)
一直说写有关最新技术的文章,但前面似乎都有点偏了,只能说算主流技术,今天这个主题,我觉得应该名副其实.分布式微服务的深水区并不是单个微服务的设计,而是服务间的数据一致性问题!解决了这个问题,才算是把分 ...
- WP8.1学习系列(第十二章)——全景控件Panorama开发指南
2014/6/18 适用于:Windows Phone 8 和 Windows Phone Silverlight 8.1 | Windows Phone OS 7.1 全景体验是本机 Windows ...
- OpenStack学习系列之十二:安装ceph并对接OpenStack
Ceph 是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统.Ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展.在国内一些公司的云环境中,通常 ...
- Dubbo学习系列之十三(Mycat数据库代理)
软件界有只猫,不用我说,各位看官肯定知道是哪只,那就是大名鼎鼎的Tomcat,现在又来了一只猫,据说是位东方萌妹子,暂且认作Tom猫的表妹,本来叫OpencloudDB,后又改名为Mycat,或许Ca ...
随机推荐
- 重启testjenkins的步骤
在linux下编译caffe的过程中,发生错误,导致linux系统蹦了,没办法,重启linux系统. 之前安装在docker下的jenkins也停掉了. 先启动jenkins的步骤如下: 1.先启动d ...
- 在开发Thinkphp5.0智慧软文个人微信个人支付宝企业支付宝接口时遇到的坑
在开发Thinkphp5.0智慧软文个人微信个人支付宝企业支付宝接口时遇到回调后提示成功但是不能自动充值的情况,现在记录一下: 两种情况 1.个人支付宝 个人微信遇到的情况 因为个人支付宝 个人微信 ...
- hello gulp,使用gulp的第一天。
昨天花了一天的时间,学习了一下gulp,今天整理一下,也分享给朋友们. 首先当然是去gulp的官网逛一圈了: http://gulpjs.com/ 中文站地址: http://www.gulpjs.c ...
- shell脚本exercise2
通过文件里面的网址,判断是否访问成功网址 #!/bin/bash check(){ code=`curl -I -m -o /dev/null -s -w %{http_code} http://$u ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- Linux系统通过FTP进行文档基本操作【华为云分享】
[摘要] Linux系统里通过FTP可以对文档进行上传,更改权限和基本的文档管理. 获得Linux系统后,不熟悉命令操作的情况下,可以通过FTP工具进行文档操作,下面以WinSCP工具为例进行讲解: ...
- KVM http网络加载镜像报错(mount: wrong fs type, bad option, bad superblock on /dev/loop0)
curl: (23) Failed writing body (7818 != 16384)loop: module loadeddracut-initqueue[579]: mount: wrong ...
- luogu P1316 丢瓶盖 |二分答案
题目描述 陶陶是个贪玩的孩子,他在地上丢了A个瓶盖,为了简化问题,我们可以当作这A个瓶盖丢在一条直线上,现在他想从这些瓶盖里找出B个,使得距离最近的2个距离最大,他想知道,最大可以到多少呢? 输入格式 ...
- 【Web技术】400- 浅谈Shadow DOM
编者按:本文作者:刘观宇,360 奇舞团高级前端工程师.技术经理,W3C CSS 工作组成员. 为什么会有Shadow DOM 你在实际的开发中很可能遇到过这样的需求:实现一个可以拖拽的滑块,以实现范 ...
- Cesium案例解析(二)——ImageryLayers影像图层
目录 1. 概述 2. 实例 2.1. ImageryLayers.html 2.2. ImageryLayers.js 2.2.1. 代码 2.2.2. 解析 3. 结果 1. 概述 Cesium支 ...