MongoDB学习笔记(七、MongoDB总结)
1、为什么要NoSQL:nosql能解决sql中那些解决不了的问题
NoSQL是什么:Not Only SQL,本质上还是数据库,但它不会遵循传统数据库的规则(如:SQL标准、ACID属性[事务]、表结构等)。
优点:
- 处理大量数据时性能高。
- 对磁盘读写要求不高,可以运行在便宜的PC机上,降低服务器成本。
缺点:
- 对事务的支持不够友好
- 复杂的关联查询难以实现
| 传统SQL |
1、吞吐量小,无法支持高并发读写 2、结构要求严谨(增改一个字段麻烦),复杂系统中难以维护此关系 |
| NoSQL |
1、吞吐量大,支持海量数据的快速读写(基于内存操作数据) 2、增改字段非常容易 |
2、MongoDB简介
MongoDB是NoSQL的一种,它是一个文档型数据库。
| MySQL | MongoDB |
| db | database(数据库) |
| table | collection(集合) |
| row | document(文档) |
| column | field(字段) |
| index | index(索引) |
| join | 无关联(可以用DBRef实现) |
| primaryKey | primaryKey(主键,客户端默认使用_id,ObjectId) |
特性:
- 数据存储方式:面向集合文档存储数据,以独有的bson格式存储
- 可扩展性:可扩展性好,修改数据后不会影响生产环境的程序运行
- 语言特性:强大且面向对象的查询语言,基本覆盖了sql语言所有能力
- 索引和查询计划:完整的索引支持和查询计划
- 集群、分片、内部故障支持:支持集群之间的数据复制、自动故障转移、支持数据的分片,提升系统扩展性
- 数据操作方式:使用内存映射存储引擎,把IO操作转换成内存操作(不是只用内存,而是通过内存提高读写性能)
3、MongoDB应用场景
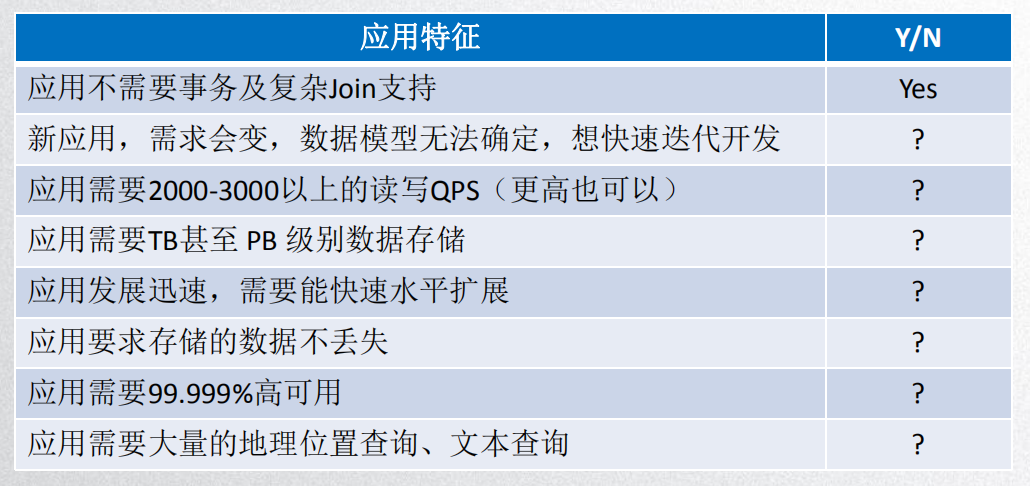
只要满足以上两点,选择MongoDB就绝对不会错!!!
但系统需要高一致的事务性,不推荐使用(如:银行、财务系统)。
系统结构固定且有复杂的关联查询系统,不推荐使用。
4、MongoDB数据结构

5、增删改查
a、新增,insert():
db.collectionName.insert(document)
document有两种方式:
1、直接放入数据:
db.collectionName.insert({
......
})
2、新定义变量再放入数据:
var user = {
......
}
db.collectionName.insert(user)
b、查询,find()、aggregate():
db.collectionName.find(
query(查询的条件),
<projection>(可用自参数指定返回字段,0=不展示,1=展示;0和1不能同时出现)
)
查询选择器:

常用的查询方法:
1、sort():排序,1=升序,-1=降序。
2、skip(count)、limit(count):跳过和限制。
3、distinct('fieldName'):查询唯一值。
关联查询:
DBRef插入数据: {'$ref':'collectionName', '$id':'所在集合的_id值', '$db':'dbName(可选)'}
DBRef查询数据: db.collectionName.findOne({'name':'zd'}).userId.fetch()
聚合查询:
1、分组: $group,将数据分组后再统计结果。
- $sum、$avg、$min、$max:获取分组集合中的总和、平均值、最大值、最小值
- $push:将指定表达式添加到一个数组中
- $addToSet:将指定表达式添加到集合中(无重复)
- $first:返回每组第一个文档,如有排序按照排序返回,没有则按照文档的默认顺序
- $last:同$first,但返回最后一个文档
2、投影: $project,输出指定字段(0=不显示,1显示)。
3、过滤: $match,只输出指定条件(使用MongoDB标准查询选择器)。
4、限制: $limit,只输出指定个数。
5、跳过: $skip,跳过输出指定个数。
6、排序: $sort,排序(1=升序,-1=降序)。
7、拆分: $unwind,将文档数组类型字段拆分成多条。
c、删改,update():
db.collectionName.update(
<query>, // 类似于sql的where
<updateSelector> // 类似于sql的set
{
upsert:<boolean>, // true=query不存在插入新的,false=不插入新的(默认)
multi:<boolean>, // true=只更新找到的第一条记录,false=全部更新(默认)
writeCocern:<document> // 写入的安全配置
}
)
修改选择器(uupdateSelector):

修改的原子性:
日常开发中,你可能会经常使用以下操作:
int row = update();
if (row > 0) {
findByName();
}
正常清下下的确没有问题,但高并发场景下这样写便会有问题,因为一但update()完毕后就可以拿到锁了,而这时可能就会有其他操作把此用户的数据修改;
故findByName()可能并能拿到update()之后的数据,而是拿到了最终的结果,这样可能会影响业务。
而MongoDB提供了原子性的更新:
db.collectionName.findAndModify({
query:{}, // 查询选择器
update:{}, // 需要更新的值,不能与remove同事出现
remove:true|false, // 删除符合条件的文档,不能与update同时出现
new:true|false, // true=返回更新后的文档,false=旧的文档
sort:{}, // 排序
fields:{}, // 显示或隐藏指定的值
upsert:true|false // 同update的upsert
})
6、ObjectId()
因新增数据返回的是受影响的函数,无法返回ObjectId;这里有一个小技巧,通过update代替insert获取ObjectId
db.collectionName.update(
{'':''}, // 永远不满足的查询条件
{'username':'zd'}, // 这里写需要新增的数据
{'upsert':true} // 因为查询条件永不满足,所以upsert=true便可新增数据
)
7、MongoDB存储引擎
a、WiredTiger:
WiredTiger引擎是文档并发级别,其数据写入方式是以检查点为单位,每1min创建一个检查点将数据快照写入磁盘。
因检查点的特性所以服务器宕机的话最大可能会丢失1min左右的数据,针对这一情况MongoDB采用journal来进一步的优化。
journal会记录检查点之间所有的操作日志,用于数据同步;其日志文件最小128B,当日志文件小于128B则不启用压缩算法,反之则启用snappy算法压缩。
压缩算法:以消耗CPU资源换取磁盘空间,分块压缩算法压缩集合,snappy压缩算法压缩索引(前缀压缩算法)。
内存使用情况:(RAM - 1GB) * 0.5 或 256M ,默认使用较大的那一个。
b、MMAPv1:
MMAPv1存储引擎的数据都是连续存储在磁盘上,当document需要更大的空间时,MongoDB必须重新分配空间;此间还涉及到数据的移动和索引的更新,不仅比直接更新更耗费时间,而且还会导致磁盘碎片。
因MMAPv1的特性MongoDB会为每个document分配两倍的空间。
内存使用情况:使用全部内存。
c、InMemory:
基于内存的一种存储引擎,它是文档级别的并发,默认使用内存为 RAM * 0.5 - 1GB。
8、Journal原理分析
Journal流程分析:首先找到数据文件中最后一个检查点,然后在Journal中检索与其相匹配的记录,最后将Journal中未匹配的数据恢复。
工作原理:https://www.processon.com/view/5c349f6ee4b048f108c78a52
9、MongoDB索引
索引主要用于排序和检索(1=升序,-1=降序),其分为4种:
- 单键索引:db.collectionName.createIndex({'name':-1})
- 复合索引:db.collectionName.createIndex({'name':-1, 'age':1})
- 多键索引:db.collectionName.createIndex({'address.city':-1})
- 哈希索引:db.collectionName.createIndex({'name':'hashed'})
db.collectionName.createIndex(
{'name':1}, // 索引名称
{
'background':true, // 是否后台构建索引
'unique':true, // 是否是唯一索引
'sparse':true // 是否为稀疏索引
}
)
索引的删除:
- 删除指定姓名:db.collectionName.dropIndex('indexName')
- 删除集合上的索引(_id删不掉):db.collectionName.dropIndexs()
- 重建集合上的索引:db.collectionName.reIndex()
- 查询集合上的索引:db.collectionName.getIndexs()
关于索引的建议:
- 根据需求建立索引,它有用但也有成本,不要对那些写多读少的建立索引。
- 尽量保证每个查询的stage都为IXSCAN,追求扫描文档数(totalDocsExamined) = 返回文档数(nReturned)。
- MongoDB在一次查询中只使用一个索引,如果多条件查询的尽量使用复合索引。
- 在数据量多的时候建立索引是非常消耗资源的,所以尽量在数据量小的时候就把索引建好。
10、可复制集
在MongoDB中可复制集是服务器分布和维护数据的方法,其实就是主从复制的升级。
优点:
- 它可以尽可能的避免数据丢失,保障数据的安全性,提高系统安全性。(最少3个节点,最大50个)
- 它具有自动化灾备机制,在主节点宕机后会选举出一个新的主节点,提高系统的健壮性。(7个选举节点上限)
- 读写分离,提高系统性能。
原理:
a、oplog:保存操作记录及时间戳。
b、数据同步:主从保持长轮询。
- 从节点查看本机oplog最新的时间戳
- 查看主节点oplog中晚于此时间戳的文档
- 加载这些文档,并根据log执行写操作
c、心跳机制:每2秒进行一次心跳检测,发现故障后会进行选举和故障转移。
d、选举制度:当主节点故障后,其余节点根据优先级和bully算法选举出新的主节点,在此之间集群服务是只读的。
11、读写分离
MongoDB读数据的方式分为5种:
- PRIMARY(默认):读操作都在主节点,若主节点不可用则报错。
- PRIMARY_PREFERRED:首选主节点,若主节点不可用则转移到其它从节点。
- SECONDARY:读从节点,不可用则报错。
- SECONDARY_PREFERRED(推荐):首选从节点,若是特殊情况则在主节点读(但主节点架构)。
- NEAREST:最邻近主节点。
12、分片
分片架构的三个主要角色:
- 分片:分片架构中唯一存储数据的角色,它可以是单台服务器也可以是一个可复制集(生成环境推荐使用可复制集),每个分区上只存储部分数据。
- 路由:由于分片只存储部分数据,所以需要一个工具(工具为mongos)来将请求处理到对应的分片中,而路由就充当这一角色。
- 配置服务器:存储集群的元数据(数据库、集合、分片的位置范围等日志信息),配置服务器最低3台。
分片键选择的一些建议:
a、不推荐点:
- 不要使用自增长的字段作为分片键,避免热点问题。
- 不能使用粗粒度的分片键,避免数据块无法分割。
- 不能使用完全随机的分片键值,这样会造成查询性能低下。
b、推荐点:
- 使用与常用查询相关的字段作为分片键,且包含唯一字段(如业务主键,id等)。
- 索引对于分区同样重要,每个分片集合上要有同样的索引,分片键默认成为索引。
- 分片集合只允许在id和分片键上创建唯一索引。
13、MongoDB最佳实践
尽量选取稳定新版本64位的MongoDB。
数据模式设计;提倡单文档设计,将关联关系作为内嵌文档或者内嵌数组;当关联数据量较大时,考虑通过表关联实现,dbref或者自定义实现关联。
避免使用skip跳过大量数据
- 通过查询条件尽量缩小数据范围。
- 利用上一次的结果作为条件来查询下一页的结果。
避免单独使用不适用索引的查询符($ne、$nin、$where等)。
根据业务场景选择合适的写入策略,在数据安全和性能之间找到平衡点。
建立索引很重要。
生产环境中建议打开profile,便于优化系统性能。
生产环境中建议打开auth模式,保障系统安全。
不要将MongoDB和其他服务部署在同一台机器上(虽然MongoDB 占用的最大内存是可以配置的)。
单机一定要开启journal日志,数据量不太大的业务场景中,推荐多机器使用副本集,并开启读写分离。
分片键的注意事项。
MongoDB学习笔记(七、MongoDB总结)的更多相关文章
- Mongodb学习笔记一(Mongodb环境配置)
Mongodb学习 说明: MongoDB由databases组成,database由collections组成,collection由documents组成,document由fileds组成.Mo ...
- MongoDB学习笔记七:管理
[启动和停止MongoDB]『从命令行启动』执行mongod,启动MongoDB服务器.mongod有很多可配置的启动选项:在命令行运行mongod --help可以查看所有选项.一些主要选项如下: ...
- MongoDB学习笔记(一) MongoDB介绍及安装(摘)
MongoDB是一个高性能,开源,无模式的文档型数据库,是当前NoSql数据库中比较热门的一种.它在许多场景下可用于替代传统的关系型数据库或键/值存储方式.Mongo使用C++开发.Mongo的官方网 ...
- Mongodb学习笔记二(Mongodb基本命令)
第二章 基本命令 一.Mongodb命令 说明:Mongodb命令是区分大小写的,使用的命名规则是驼峰命名法. 对于database和collection无需主动创建,在插入数据时,如果databas ...
- MongoDb 学习笔记(一) --- MongoDb 数据库介绍、安装、使用
1.数据库和文件的主要区别 . 数据库有数据库表.行和列的概念,让我们存储操作数据更方便 . 数据库提供了非常方便的接口,可以让 nodejs.php java .net 很方便的实现增加修改删除功能 ...
- MongoDB学习笔记一(MongoDB介绍 + 基本指令 + 查询语句)
什么是MongoDB MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB 旨在为WEB应用提供可扩 ...
- MongoDB学习笔记(一) MongoDB介绍及安装
转自:http://database.51cto.com/art/201103/247882.htm http://baike.baidu.com/link?url=b6B3dVSCnQauCX-Ep ...
- MongoDB学习笔记-认识MongoDB
学习参考地址 http://www.runoob.com/mongodb NoSql 流行的数据库Oracle,SqlServer,MySql为关系性数据库,相对的,也有非关系性数据库,统称为NoSq ...
- Mongodb学习笔记三(Mongodb索引操作及性能测试)
第三章 索引操作及性能测试 索引在大数据下的重要性就不多说了 下面测试中用到了mongodb的一个客户端工具Robomongo,大家可以在网上选择下载.官网下载地址:http://www.robomo ...
- Mongodb学习笔记四(Mongodb聚合函数)
第四章 Mongodb聚合函数 插入 测试数据 ;j<;j++){ for(var i=1;i<3;i++){ var person={ Name:"jack"+i, ...
随机推荐
- Local Model Poisoning Attacks to Byzantine-Robust Federated Learning
In federated learning, multiple client devices jointly learn a machine learning model: each client d ...
- 大数据学习笔记——Java篇之基础知识
Java / 计算机基础知识整理 在进行知识梳理同时也是个人的第一篇技术博客之前,首先祝贺一下,经历了一年左右的学习,从完完全全的计算机小白,现在终于可以做一些产出了!可以说也是颇为感慨,个人认为,学 ...
- 判断机器CPU的大小端模式并将数据转换成小端形式
首先看一下概念 Little-Endian 就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端 Big-Endian 就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端. 第一 ...
- Linux命令-grep,sed,awk
grep (global search regular expression[RE] and print out the line) 正则表达式全局搜索并将行打印出来 在文件中查找包含字符串" ...
- 《漫画ERP》经典文章摘抄
1.对企业来说,应用ERP的价值就在于通过系统的计划和控制功能,结合企业的流程优化,有效的配置各项资源,以加快对市场的响应,降低成本,提高效率和效益,从而提升企业的竞争力:
- kvm磁盘管理
kvm磁盘管理 kvm虚拟机虚拟磁盘格式转换 各种格式说明介绍 row:裸格式,占用空间较大,不支持快照功能,性能较好,不方便传输(顺序读写) 50G 2G 传输50G qcow2:cow 占用空间小 ...
- NGUI 源码分析- UIWidgetInspector
NGUI Version 3.9.0 //---------------------------------------------- // NGUI: Next-Gen UI kit // Copy ...
- Castle DynamicProxy基本用法(AOP)
本文介绍AOP编程的基本概念.Castle DynamicProxy(DP)的基本用法,使用第三方扩展实现对异步(async)的支持,结合Autofac演示如何实现AOP编程. AOP 百科中关于AO ...
- 源码角度分析-newFixedThreadPool线程池导致的内存飙升问题
前言 使用无界队列的线程池会导致内存飙升吗?面试官经常会问这个问题,本文将基于源码,去分析newFixedThreadPool线程池导致的内存飙升问题,希望能加深大家的理解. (想自学习编程的小伙伴请 ...
- Spring Boot Request method DELETE not supported
1: 开启HiddenHttpMethodFilter 最新版本的spring boot 默认不开启 restful 分割api @Bean @ConditionalOnMissingBean({Hi ...