jieba、NLTK学习笔记
中文分词 - jiebaimport re
import jieba news_CN = '''
央视315晚会曝光湖北省知名的神丹牌、莲田牌“土鸡蛋”实为普通鸡蛋冒充,同时在商标上玩猫腻,
分别注册“鲜土”、注册“好土”商标,让消费者误以为是“土鸡蛋”。3月15日晚间,新京报记者就此
事致电湖北神丹健康食品有限公司方面,其工作人员表示不知情,需要了解清楚情况,截至发稿暂未
取得最新回应。新京报记者还查询发现,湖北神丹健康食品有限公司为农业产业化国家重点龙头企
业、高新技术企业,此前曾因涉嫌虚假宣传“中国最大的蛋品企业”而被罚6万元。
''' # 字符串清洗
string = re.sub('[^\w]', '', news_CN) #使用正则去符号,之后都是用这个str字符串 # 分词
seg_list = jieba.cut(string, cut_all=False, HMM=False) #精确模式(默认)| 全模式
#seg_list = jieba.cut_for_search(string, HMM=False) #搜索引擎模式,粒度较细
#jieba.lcut(), jieba.lcut_for_search() #直接返回list,不加返回生成器
print('/'.join(seg_list)) # 返回词语在原文中出现位置
seg_list = jieba.tokenize(u'自然语言处理非常有用') #[('自然语言', 0, 4), ...] # 词性标注
import jieba.posseg as psg
seg_list = psg.cut(news_CN)
'''psg.POSTokenizer(tokenizer=None)
#tokenizer参数可使用 jieba.Tokenizer(dictionary=DEFUALT_DICT) #新建自定义分词器,可用于同时使用不同字典
#jieba.posseg.dt为默认词性标注分词器
'''
print(' '.join(['{0}/{1}'.format(w, t) for w, t in seg_list])) '''
path = ''
file=open(path,'r')
jieba.load_userdict(file)
file.close()
'''
# 加载自定义词
'''
userdict.txt
一个词占一行
每一行分三部分:词语、词频(可省略)、词性(可省略)
用空格隔开,顺序不可颠倒
file_name
若为路径或二进制方式打开的文件,则文件必须为UTF-8编码
'''
# 结巴默认词库位置: {basepath}\Lib\site-packages\jieba\dict.txt
#如果不知道新加词汇的词频词性的话,可写成:词 3 n
jieba.set_dictionary('./data/dict.txt.big') #加载系统词典
jieba.load_userdict(['神丹牌','莲花牌','土鸡蛋','新京报']) #载入词典, filename='userdict.txt'
jieba.add_word('自定义词', freq=None, tag=None) #动态修改词典
jieba.del_word('自定义词')
jieba.get_FREQ('神丹牌')
jieba.suggest_freq(('龙头企业','高新技术企业'), True) #调节单个词语的词频,使其能(或不能)被分出来 seg_list = jieba.cut(string, cut_all=False) #精确模式 str 为之前的字符串
print('/'.join(seg_list)) #词典中指定的词不会拆分 # 基于TF-IDF算法的关键词抽取
import jieba.analyse as aly
#aly.TFIDF(idf_path=None)
aly.set_idf_path('./data/idf.txt.big') #加载自定义idf词典
aly.set_stop_words('./data/stop_words.utf8') #加载停用词典
keywords = aly.extract_tags(news_CN, topK=10, withWeight=True, allowPOS=()) #allowPOS为保留词性,为空不过滤
keywords = aly.textrank(news_CN, topK=10, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v')) #为空过滤所有 from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
corpus = [
'This is the first document.',
'This is the second document.',
'And the third one.'
]
#words = CountVectorizer().fit_transform(corpus)
#tfidf = TfidfTransformer().fit_transform(words) #稀疏矩阵
tfidf = TfidfTransformer().fit_transform(corpus) #结果一样
print(tfidf) # 并行分词
# 按行多进程并行,基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
jieba.enable_parallel(4)
jieba.disable_parallel()
英文分词 - NLTK
import nltk # ------------------------------------
#先分句再分词
text = "And now for something completely different. I love you."
sentences = nltk.sent_tokenize(text)
words = []
for sent in sentences:
words.append(nltk.word_tokenize(sent))
#words_tagged += nltk.pos_tag(nltk.word_tokenize(sent)) # ------------------------------------
#分词
words = nltk.word_tokenize("good good study, day day up!") # ------------------------------------
#词性标注
tagged = nltk.pos_tag(words)
print (tagged[0:6]) for word in tagged:
if 'NNP' == word[1]: #首字母大写都判为专有名词了
print(word) #命名实体识别
entities = nltk.chunk.ne_chunk(tagged) #树
print (entities) # ------------------------------------
#词频统计
words = nltk.word_tokenize("good good study, day day up!")
fdist = nltk.FreqDist(words)
fdist.N() #总词数
fdist.B() #词典大小
fdist['good'] #频数
fdist.freq('good') * 100 #频率
fdist.tabulate(5, cumulative=False) #前5个词的频数分布
fdist.plot(5, cumulative=True) #前5个词的累计频数分布图
#词组统计
bgrams = nltk.bigrams(words)
bgfdist = nltk.FreqDist(list(bgrams))
bgfdist.plot(10) #前十词组
基于TF-IDF算法的关键词提取
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
其中需要说明的是:
1.sentence 为待提取的文本
2.topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
3.withWeight 为是否一并返回关键词权重值,默认值为 False
4.allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
#设置逆文档频率语料库
#jieba.analyse.set_idf_path(file_name)
#劳动防护 13.900677652 勞動防護 13.900677652 ...
#设置停用词语料库
#jieba.analyse.set_stop_words(file_name) import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open(u'人民的名义.txt','r',encoding='utf-8').read()
jieba.analyse.set_stop_words("stopwords.txt")
tags = jieba.analyse.extract_tags(content, topK=10,withWeight=True)
for tag in tags:
print("tag:%s\t\t weight:%f"%(tag[0],tag[1]))

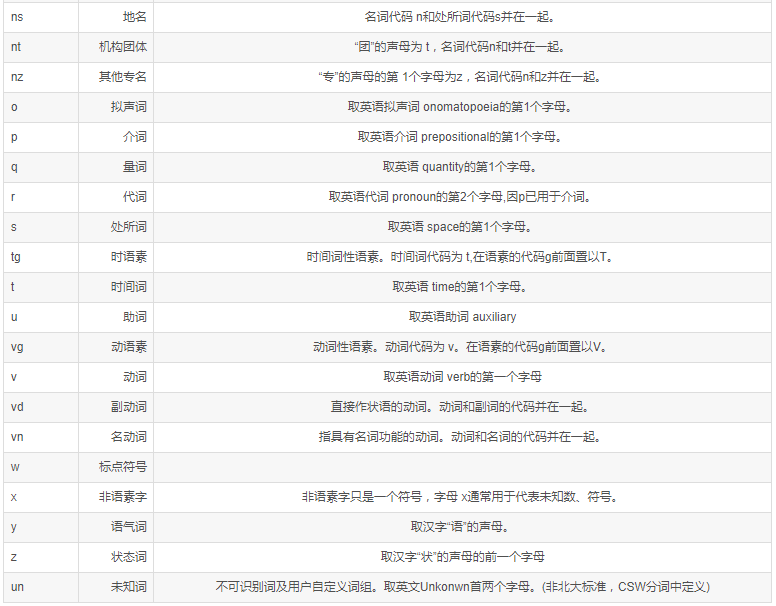
英文分词 - NLTK - 词形还原、词性还原、词干提取
转自:NLTK英文分词尝试
NLP Lemmatisation(词性还原) 和 Stemming(词干提取) NLTK pos_tag word_tokenize
Python nltk.WordNetLemmatizer() Examples
import re, time, collections, nltk
from sklearn.datasets import fetch_20newsgroups
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords # -----------------------------------
''' 词形还原 '''
# 正则表达式过滤特殊符号用空格符占位,双引号、单引号、句点、逗号
pat_letter = re.compile(r'[^a-zA-Z \']+')
# 还原常见缩写单词
pat_is = re.compile("(it|he|she|that|this|there|here)(\'s)", re.I)
pat_s = re.compile("(?<=[a-zA-Z])\'s") # 找出字母后面的字母
pat_s2 = re.compile("(?<=s)\'s?")
pat_not = re.compile("(?<=[a-zA-Z])n\'t") # not的缩写
pat_would = re.compile("(?<=[a-zA-Z])\'d") # would的缩写
pat_will = re.compile("(?<=[a-zA-Z])\'ll") # will的缩写
pat_am = re.compile("(?<=[I|i])\'m") # am的缩写
pat_are = re.compile("(?<=[a-zA-Z])\'re") # are的缩写
pat_have = re.compile("(?<=[a-zA-Z])\'ve") # have的缩写 def replace_abbreviations(text):
new_text = text
new_text = pat_letter.sub(' ', text).strip().lower()
new_text = pat_is.sub(r"\1 is", new_text)
new_text = pat_s.sub("", new_text)
new_text = pat_s2.sub("", new_text)
new_text = pat_not.sub(" not", new_text)
new_text = pat_would.sub(" would", new_text)
new_text = pat_will.sub(" will", new_text)
new_text = pat_am.sub(" am", new_text)
new_text = pat_are.sub(" are", new_text)
new_text = pat_have.sub(" have", new_text)
new_text = new_text.replace('\'', ' ')
return new_text # -----------------------------------
''' 词干提取 '''
# 基于Porter词干提取算法
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
porter_stemmer.stem('leaves') #输出:leav,实际:leaf
porter_stemmer.stem('maximum') # 基于Lancaster 词干提取算法
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
lancaster_stemmer.stem('maximum') # 基于Snowball 词干提取算法
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
snowball_stemmer.stem('maximum') # -----------------------------------
''' 词性还原 '''
def lemmatize_all(sentence, stopWords):
# lemmatize()方法将word单词还原成pos词性的形式
wnl = WordNetLemmatizer()
for word, tag in nltk.pos_tag(word_tokenize(sentence)):
if word in stopWords:
continue
elif tag.startswith('NN'):
#pos = nltk.corpus.wordnet.NOUN
yield wnl.lemmatize(word, pos='n')
elif tag.startswith('VB'):
#pos = nltk.corpus.wordnet.VERB
yield wnl.lemmatize(word, pos='v')
elif tag.startswith('JJ'):
#pos = nltk.corpus.wordnet.ADJ
yield wnl.lemmatize(word, pos='a')
elif tag.startswith('R'):
#pos = nltk.corpus.wordnet.ADV
yield wnl.lemmatize(word, pos='r')
else:
#按词性剔除
continue
#yield word #查看词性说明
nltk.help.upenn_tagset('JJ') # -----------------------------------
''' 词频统计 '''
def word_frequency_count(contents, stopWords):
word_count_dict = collections.defaultdict(lambda:0)
for text in contents:
new_text = replace_abbreviations(text)
words = lemmatize_all(new_text, stopWords)
word_dict = collections.Counter(words)
for key in word_dict:
word_count_dict[key] += word_dict[key]
return word_count_dict if __name__=='__main__':
t0 = time.time()
news = fetch_20newsgroups(subset='all')
stopWords = set(stopwords.words('english')) | set(['the','a'])
word_count_dict = word_frequency_count(news.data[:30], stopWords)
#print('高频词:', word_count_dict.most_common())
word_items = list(word_count_dict.items())
word_items.sort(key=lambda x:-x[1])
print('高频词:', word_items[:50])
print('总耗时:', time.time() - t0)
实例1:根据人名预测性别
from nltk.corpus import names
from nltk.classify import NaiveBayesClassifier
# 导入数据 [(u'Aaron', 'male'), (u'Abbey', 'male')]
data = ([(name, 'male') for name in names.words('male.txt')] +
[(name, 'female') for name in names.words('female.txt')]) # 提取特征
def gender_features(word):
return {'last_letter': word[-1]} train_set = [(gender_features(n), g) for (n,g) in data] # 训练模型
classifier = NaiveBayesClassifier.train(train_set)
classifier.classify(gender_features('Frank'))
实例2:确定积极评论和消极评论所占的比例
from nltk.classify import NaiveBayesClassifier
positive_vocab = [ 'awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)' ]
negative_vocab = [ 'bad', 'terrible','useless', 'hate', ':(' ]
neutral_vocab = [ 'movie','the','sound','was','is','actors','did','know','words','not' ] def word_feats(words):
return dict([(word, True) for word in words]) positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab]
negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab]
neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab] train_set = negative_features + positive_features + neutral_features
classifier = NaiveBayesClassifier.train(train_set) neg = 0
pos = 0
sentence = "Awesome movie, I liked it"
sentence = sentence.lower()
words = sentence.split(' ')
for word in words:
classResult = classifier.classify(word_feats(word))
if classResult == 'neg':
neg = neg + 1
if classResult == 'pos':
pos = pos + 1 print('Positive: ' + str(float(pos) / len(words)))
print('Negative: ' + str(float(neg) / len(words)))
参考链接:
官方文档:Natural Language Toolkit — NLTK 3.3 documentation
解决jieba分词 load_userdict 加载自定义词库太慢的问题
jieba、NLTK学习笔记的更多相关文章
- NLTK学习笔记(三):NLTK的一些工具
主要总结一下简单的工具:条件频率分布.正则表达式.词干提取器和归并器. 条件分布频率 <自然语言学习>很多地方都用到了条件分布频率,nltk提供了两种常用的接口:FreqDist 和 Co ...
- NLTK学习笔记(六):利用机器学习进行文本分类
目录 一.监督式分类:建立在训练语料基础上的分类 特征提取器和朴素贝叶斯分类器 过拟合:当特征过多 错误分析 二.实例:文本分类和词性标注 文本分类 词性标注:"决策树"分类器 三 ...
- NLTK学习笔记(一):语言处理和Python
目录 [TOC] nltk资料下载 import nltk nltk.download() 其中,download() 参数默认是all,可以在脚本里面加上nltk.download(需要的资料库) ...
- NLTK学习笔记(四):自然语言处理的一些算法研究
自然语言处理中算法设计有两大部分:分而治之 和 转化 思想.一个是将大问题简化为小问题,另一个是将问题抽象化,向向已知转化.前者的例子:归并排序:后者的例子:判断相邻元素是否相同(与排序). 这次总结 ...
- NLTK学习笔记(八):文法--词关系研究的工具
[TOC] 对于一门语言来说,一句话有无限可能.问题是我们只能通过有限的程序来分析结构和含义.尝试将"语言"理解为:仅仅是所有合乎文法的句子的大集合.在这个思路的基础上,类似于 w ...
- NLTK学习笔记(七):文本信息提取
目录 实体识别:分块技术 分块语法的构建 树状图 IOB标记 开发和评估分块器 命名实体识别和信息提取 如何构建一个系统,用于从非结构化的文本中提取结构化的信息和数据?哪些方法使用这类行为?哪些语料库 ...
- NLTK学习笔记(五):分类和标注词汇
目录 词性标注器 标注语料库 表示已经标注的标识符:nltk.tag.str2tuple('word/类型') 读取已经标注的语料库 名词.动词.形容词等 尝试找出每个名词类型中最频繁的名词 探索已经 ...
- NLTK学习笔记(二):文本、语料资源和WordNet汇总
目录 语料库基本函数表 文本语料库分类 常见语料库及其用法 载入自定义语料库 词典资源 停用词语料库 WordNet面向语义的英语字典 语义相似度 语料库基本函数表 示例 描述 fileids() 语 ...
- 学习笔记之Data Science
Data science - Wikipedia https://en.wikipedia.org/wiki/Data_science Data science, also known as data ...
随机推荐
- The Preliminary Contest for ICPC Asia Shanghai 2019
传送门 B. Light bulbs 题意: 起初\(n\)个位置状态为\(0\),\(m\)次操作,每次操作更换区间状态:\(0\)到\(1\),\(1\)到\(0\). 共有\(T,T\leq 1 ...
- axios使用get方法给后端传值,登录功能的实现
前端使用vue实现页面,使用axios进行前后端交互 后端使用node.js提供接口 数据库使用navicat for mysql 前端代码:(组件中使用axios前后端交互) import axio ...
- SpringCloud学习笔记(二、SpringCloud Config)
目录: 配置中心简介 SpringCloud Config服务端 SpringCloud Config客户端 动态配置属性bean 一些补充(源码分析):Spring事件监听.健康检查health() ...
- AcWing 901. 滑雪
地址 https://www.acwing.com/problem/content/description/903/ 题目描述给定一个R行C列的矩阵,表示一个矩形网格滑雪场. 矩阵中第 i 行第 j ...
- python爬虫之爬取网站到数据库
一.根据已有程序运行得到的结果 完整代码如下: import sqlite3; class DB(object): """数据库访问方法的实现""&q ...
- matlab练习程序(图像投影到点云)
最近接触点云比较多,如果把图像投影到点云应该挺有意思. 首先需要载入图像,然后做个球或其他什么形状的点云,这里可以参考球坐标公式. 最后通过pcshow将像素输出到点云上即可. 原图: 投影后的点云: ...
- golang数据结构之栈
stack.go package stack import ( "errors" "fmt" ) type Stack struct { MaxTop int ...
- 分析Runtime的属性Property
一.介绍 在OC中我们可以给任意的一个类以@property的格式声明属性,当然对于这个属性也会采用某一些属性关键字进行修饰,那么属性的真正的面目是啥样子的呢?其实,runtime源码中可以看到,pr ...
- 【计算机网络】UDP基础知识总结
1. UDP概念相关 [!NOTE] UDP(User Datagram Protocol),又叫用户数据报协议. UDP是一个无连接的.不可靠.基于数据报的传输协议.UDP只是报文(报文可以理解为一 ...
- 计算机组成原理——中央处理器(CPU)考研题
(一) CPU的功能和基本结构 (二) 指令执行过程 (三) 数据通路的功能和基本结构 (四) 控制器的功能和工作原理 1. 硬布线控制器2. 微程序控制器微程序.微指 ...