Deformable Convolutional Networks
1 空洞卷积
1.1 理解空洞卷积
在图像分割领域,图像输入到CNN(典型的网络比如FCN)中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测,之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。
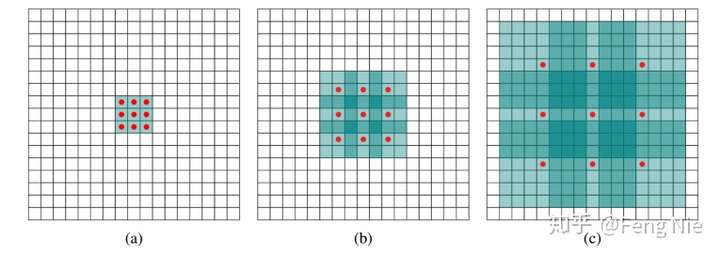
(a) 普通卷积,1-dilated convolution,卷积核的感受野为3×3
(b) 扩张卷积,2-dilated convolution,卷积核的感受野为7×7
(c) 扩张卷积,4-dilated convolution,卷积核的感受野为15×15
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样.
(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv 的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv).
(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
扩张卷积与普通的卷积相比,除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,主要用来表示扩张的大小。扩张卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于扩张卷积具有更大的感受野。
扩展卷积在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射(feature map)的大小保持不变。一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,但参数数量仅为9个,是5×5卷积参数数量的36%。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv。
1.2 Deconv和dilated conv的区别:
deconv的具体解释可参见如何理解深度学习中的deconvolution networks?,deconv的其中一个用途是做upsampling,即增大图像尺寸。而dilated conv并不是做upsampling,而是增大感受野。可以形象的做个解释:对于标准的k*k卷积操作,stride为s,分三种情况:
(1) s>1,即卷积的同时做了downsampling,卷积后图像尺寸减小;
(2) s=1,普通的步长为1的卷积,比如在tensorflow中设置padding=SAME的话,卷积的图像输入和输出有相同的尺寸大小;
(3) 0<s<1,fractionally strided convolution,相当于对图像做upsampling。比如s=0.5时,意味着在图像每个像素之间padding一个空白的像素后,stride改为1做卷积,得到的feature map尺寸增大一倍。而dilated conv不是在像素之间padding空白的像素,而是在已有的像素上,skip掉一些像素,或者输入不变,对conv的kernel参数中插一些0的weight,达到一次卷积看到的空间范围变大的目的。当然将普通的卷积stride步长设为大于1,也会达到增加感受野的效果,但是stride大于1就会导致downsampling,图像尺寸变小。
2 Deformable convolution
文章提出了可变卷积和可变ROI采样。原理是一样的,就是在这些卷积或者ROI采样层上,添加了位移变量,这个变量根据数据的情况学习,偏移后,相当于卷积核每个方块可伸缩的变化,从而改变了感受野的范围,感受野成了一个多边形。

上图是在二维平面上deformable convolution和普通的convolution的描述图。(a)是普通的卷积,卷积核大小为3*3,采样点排列非常规则,是一个正方形。(b)是可变形的卷积,给每个采样点加一个offset(这个offset通过额外的卷积层学习得到),排列变得不规则。(c)和(d)是可变形卷积的两种特例。对于(c)加上offset,达到尺度变换的效果;对于(d)加上offset,达到旋转变换的效果。
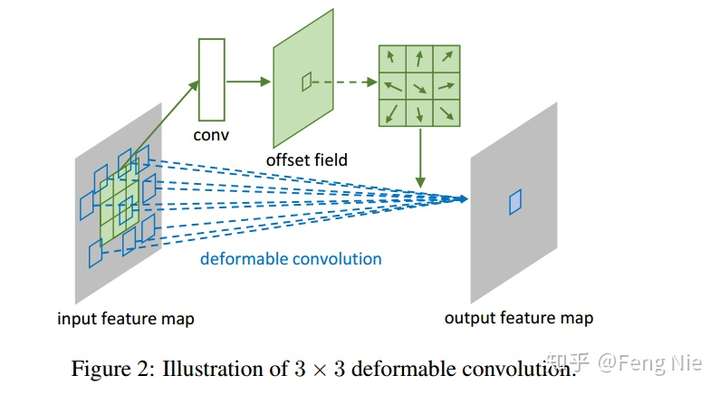
如上图所示,有一个额外的conv层来学习offset,共享input feature maps。然后input feature maps和offset共同作为deformable conv层的输入,deformable conv层操作采样点发生偏移,再进行卷积。
下面是 MXNet 中关于 deformable conv 定义的代码,可以看到,首先有一个额外的channel为72(对应着3X3的kernel size , 每个点会有 X 方向 和 Y 方向的偏移,(x,y)组合起来就对应着一个方向向量,3*3 =9 个像素点则需要 18 个output channel, 这样的 offset 需要预测4个group,因此最后的输出channel 是72) 的传统卷积学习offset(偏移量),然后前面的input feature maps和offset共同作为deformable conv层的输入,deformable conv层操作采样点发生偏移,再进行卷积。
res5a_branch2a_relu = mx.symbol.Activation(name='res5a_branch2a_relu', data=scale5a_branch2a, act_type='relu')
res5a_branch2b_offset = mx.symbol.Convolution(name='res5a_branch2b_offset', data = res5a_branch2a_relu,
num_filter=72, pad=(2, 2), kernel=(3, 3), stride=(1, 1), dilate=(2, 2), cudnn_off=True)
res5a_branch2b = mx.contrib.symbol.DeformableConvolution(name='res5a_branch2b', data=res5a_branch2a_relu, offset=res5a_branch2b_offset,
num_filter=512, pad=(2, 2), kernel=(3, 3), num_deformable_group=4,
stride=(1, 1), dilate=(2, 2), no_bias=True)<1> 先用一个(2*3*3 = 18)的传统卷积预测每个点的offset,这里18是因为每个点的offset是一个二维向量(确定方向),一共有3*3=9个点,故channel为18;
<2> 根据算出来的offset,计算新的9个点在特征图的上的值,由于可能算出来的offset为(0.3, 0.5)这种小数,也就是可能会需要知道特征图上(3.3,4.5)位置的值,所以作者用双线性差值计算这些经过offset修正的位置的响应;
<3> 最后就是与卷积核卷积得到最终的值。
3 Deformable RoI pooling
RoI pooling是把不同大小的RoI(w*h)对应的feature map 统一到固定的大小(k x k);可形变RoI pooling则是先对RoI对应的每个bin按照RoI的长宽比例的倍数进行整体偏移(同样偏移后的位置是小数,使用双线性差值来求),然后再pooling。
由于按照RoI长宽比例进行水平和竖直方向偏移,因此每一个bin的偏移量只需要一个参数来表示,具体可以用全连接来实现。
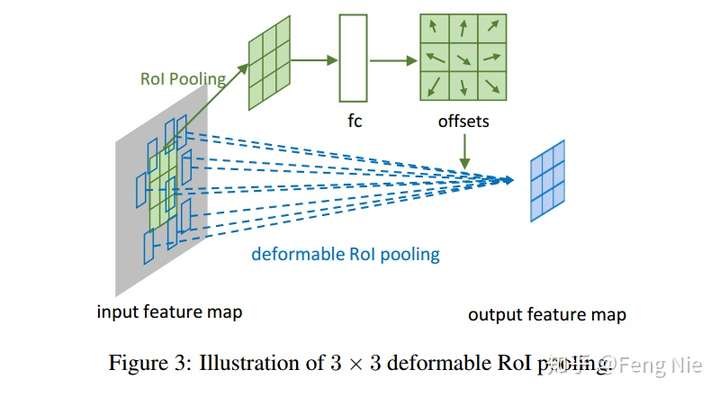
如上图所示,RoI被分为3*3个bin,被输入到一个额外的fc层来学习offset,然后通过一个deformable RoI pooling层来操作使每个bin发生偏移。
def get_deformable_roipooling(self, name, data, rois, output_dim, spatial_scale, param_name, group_size=1, pooled_size=7,
sample_per_part=4, part_size=7):
offset = mx.contrib.sym.DeformablePSROIPooling(name='offset_' + name + '_t', data=data, rois=rois, group_size=group_size, pooled_size=pooled_size,
sample_per_part=sample_per_part, no_trans=True, part_size=part_size, output_dim=output_dim,
spatial_scale=spatial_scale)
offset = mx.sym.FullyConnected(name='offset_' + name, data=offset, num_hidden=part_size * part_size * 2, lr_mult=0.01,
weight=self.shared_param_dict['offset_' + param_name + '_weight'], bias=self.shared_param_dict['offset_' + param_name + '_bias'])
offset_reshape = mx.sym.Reshape(data=offset, shape=(-1, 2, part_size, part_size), name='offset_reshape_' + name)
output = mx.contrib.sym.DeformablePSROIPooling(name='deformable_roi_pool_' + name, data=data, rois=rois, trans=offset_reshape, group_size=group_size,
pooled_size=pooled_size, sample_per_part=sample_per_part, no_trans=False, part_size=part_size, output_dim=output_dim,
spatial_scale=spatial_scale, trans_std=0.1)
return output事实上,可变形卷积单元中增加的偏移量是网络结构的一部分,通过另外一个平行的标准卷积单元计算得到,进而也可以通过梯度反向传播进行端到端的学习。加上该偏移量的学习之后,可变形卷积核的大小和位置可以根据当前需要识别的图像内容进行动态调整,其直观效果就是不同位置的卷积核采样点位置会根据图像内容发生自适应的变化,从而适应不同物体的形状、大小等几何形变,
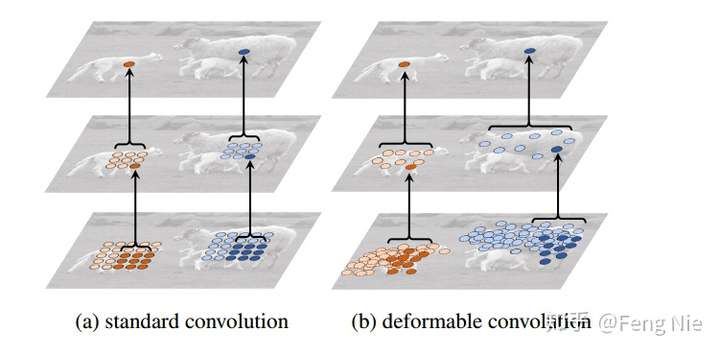
上图展示了两层的3*3卷积层的映射。对于标准的卷积,后面层的feature map上的一个点,映射到前面层所对应的感受野是规则的,无法考虑到不同目标的外形、大小不同;而可变形的卷积则考虑到了目标的形变,映射到前面层的采样点大多会覆盖在目标上面,采样到更多我们感兴趣的信息。

上图是可变形卷积采样点的一个可视化。三张图片为一组,绿点表示激活点,红点表示激活点映射到原图的采样点,三张图片分别对应背景、小目标和大目标的采样点可视化。
[1]github源码 Deformable-ConvNets
[2]论文 Deformable Convolutional Networks
Deformable Convolutional Networks的更多相关文章
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 目标检测论文阅读:Deformable Convolutional Networks
https://blog.csdn.net/qq_21949357/article/details/80538255 这篇论文其实读起来还是比较难懂的,主要是细节部分很需要推敲,尤其是deformab ...
- 深度学习方法(十三):卷积神经网络结构变化——可变形卷积网络deformable convolutional networks
上一篇我们介绍了:深度学习方法(十二):卷积神经网络结构变化--Spatial Transformer Networks,STN创造性地在CNN结构中装入了一个可学习的仿射变换,目的是增加CNN的旋转 ...
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 论文讨论&&思考《Deformable Convolutional Networks》
这篇论文真是让我又爱又恨,可以说是我看过的最认真也是最多次的几篇paper之一了,首先deformable conv的思想我觉得非常好,通过end-to-end的思想来做这件事也是极其的make se ...
- pytorch实现 | Deformable Convolutional Networks | CVPR | 2017
文章转载自微信公众号:[机器学习炼丹术],请支持原创. 这一篇文章,来讲解一下可变卷积的代码实现逻辑和可视化效果.全部基于python,没有C++.大部分代码来自:https://github.com ...
- Deformable Convolutional Networks-v1-v2(可变形卷积网络)
如何评价 MSRA 视觉组最新提出的 Deformable ConvNets V2? <Deformable Convolutional Networks>是一篇2017年Microsof ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 这篇论文
由Andrew Zisserman 教授主导的 VGG 的 ILSVRC 的大赛中的卷积神经网络取得了很好的成绩,这篇文章详细说明了网络相关事宜. 文章主要干了点什么事呢?它就是在在用卷积神经网络下, ...
随机推荐
- Leetcode 90. 子集 II
地址 https://leetcode-cn.com/problems/subsets-ii/ 给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重 ...
- LeetCode解题笔记 - 3. Longest Substring Without Repeating Characters
Given a string, find the length of the longest substring without repeating characters. Examples: Giv ...
- 【洛谷5299】[PKUWC2018] Slay the Spire(组合数学)
点此看题面 大致题意: 有\(n\)张强化牌\(a_i\)和\(n\)张攻击牌\(b_i\),每张牌有一个权值(强化牌的权值大于\(1\)),每张强化牌能使所有攻击牌的权值乘上这张强化牌的权值,每张攻 ...
- mysql执行操作时卡死
有时候使用Navicat对mysql数据库进行添加字段,truncate或其他操作时会一直卡住不动,后来查看进程才发现一直处于等待状态 先执行,列出所有进程 show full processlist ...
- 用OC实现双向链表:构造链表、插入节点、删除节点、遍历节点
一.介绍 双向链表:每一个节点前后指针域都和它的上一个节点互相指向,尾节点的next指向空,首节点的pre指向空. 二.使用 注:跟单链表差不多,简单写常用的.循环链表无法形象化打印,后面也暂不实现了 ...
- IT兄弟连 HTML5教程 HTML5技术的应用现状及HTML5平台的兴起
HTML5的优良特性很快被各种类型的网站利用,比如文件拖拽到网页上传功能,多数即使用HTML5提供的新属性就可以完成,来实现素材的免插件拖放.因此,HTML5技术实际上在国内已经获得了较广泛的应用与支 ...
- 【前端知识体系-NodeJS相关】对于EventLoop(事件轮询)机制你到底了解多少?
EventLoop 1. EventLoop的执行流程图 ┌───────────────────────┐ ┌─>│ timers │<----- 执行 setTimeout().set ...
- Koa + GraphQL 示例
初始化项目 创建 graphql-example 文件夹进入后初始化一个 package.json 文件. $ mkdir graphql-example && cd $_ $ yar ...
- serf 中去中心化系统的原理和实现
原文:https://www.infoq.cn/article/principle-and-impleme-of-de-centering-system-in-serf serf 是出自 Hashic ...
- python基础(35):协程
1. 前言 之前我们学习了线程.进程的概念,了解了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位.按道理来说我们已经算是把cpu的利用率提高很多了.但是我们知道无论是创建多进程还是创 ...