MySQL实战45讲学习笔记:第三十三讲
一、引子
我经常会被问到这样一个问题:我的主机内存只有 100G,现在要对一个 200G 的大表做全表扫描,会不会把数据库主机的内存用光了?
这个问题确实值得担心,被系统 OOM(out of memory)可不是闹着玩的。但是,反过来想想,逻辑备份的时候,可不就是做整库扫描吗?如果这样就会把内存吃光,逻辑备份
不是早就挂了?
所以说,对大表做全表扫描,看来应该是没问题的。但是,这个流程到底是怎么样的呢?
二、全表扫描对 server 层的影响
假设,我们现在要对一个 200G 的 InnoDB 表 db1. t,执行一个全表扫描。当然,你要把扫描结果保存在客户端,会使用类似这样的命令:
mysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file
你已经知道了,InnoDB 的数据是保存在主键索引上的,所以全表扫描实际上是直接扫描表 t 的主键索引。这条查询语句由于没有其他的判断条件,所以查到的每一行都可以直接
放到结果集里面,然后返回给客户端。
1、MySQL 查询结果发送流程
那么,这个“结果集”存在哪里呢?
实际上,服务端并不需要保存一个完整的结果集。取数据和发数据的流程是这样的:
1. 获取一行,写到 net_buffer 中。这块内存的大小是由参数 net_buffer_length 定义的,默认是 16k。
2. 重复获取行,直到 net_buffer 写满,调用网络接口发出去。
3. 如果发送成功,就清空 net_buffer,然后继续取下一行,并写入 net_buffer。
4. 如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK,就表示本地网络栈(socketsend buffer)写满了,进入等待。直到网络栈重新可写,再继续发送。
这个过程对应的流程图如下所示。

图 1 查询结果发送流程
从这个流程中,你可以看到:
1. 一个查询在发送过程中,占用的 MySQL 内部的内存最大就是 net_buffer_length 这么大,并不会达到 200G;
2. socket send buffer 也不可能达到 200G(默认定义/proc/sys/net/core/wmem_default),如果 socket send buffer 被写满,就会暂停读数据的流程。
2、MySQL 是“边读边发的
也就是说,MySQL 是“边读边发的”,这个概念很重要。这就意味着,如果客户端接收得慢,会导致 MySQL 服务端由于结果发不出去,这个事务的执行时间变长。
比如下面这个状态,就是我故意让客户端不去读 socket receive buffer 中的内容,然后在服务端 show processlist 看到的结果。

图 2 服务端发送阻塞
如果你看到 State 的值一直处于“Sending to client”,就表示服务器端的网络栈写满了。
我在上一篇文章中曾提到,如果客户端使用–quick 参数,会使用 mysql_use_result 方法。这个方法是读一行处理一行。你可以想象一下,假设有一个业务的逻辑比较复杂,每
读一行数据以后要处理的逻辑如果很慢,就会导致客户端要过很久才会去取下一行数据,可能就会出现如图 2 所示的这种情况。
因此,对于正常的线上业务来说,如果一个查询的返回结果不会很多的话,我都建议你使用 mysql_store_result 这个接口,直接把查询结果保存到本地内存。
3、因为执行了一个大查询导致客户端占用内存近 20G如何解决
当然前提是查询返回结果不多。在第 30 篇文章评论区,有同学说到自己因为执行了一个大查询导致客户端占用内存近 20G,这种情况下就需要改用 mysql_use_result 接口了。
另一方面,如果你在自己负责维护的 MySQL 里看到很多个线程都处于“Sending toclient”这个状态,就意味着你要让业务开发同学优化查询结果,
并评估这么多的返回结果是否合理。
而如果要快速减少处于这个状态的线程的话,将 net_buffer_length 参数设置为一个更大的值是一个可选方案。
4、为什么 Sending data 要这么久?
与“Sending to client”长相很类似的一个状态是“Sending data”,这是一个经常被误会的问题。有同学问我说,在自己维护的实例上看到很多查询语句的状态是“Sending
data”,但查看网络也没什么问题啊,为什么 Sending data 要这么久?
实际上,一个查询语句的状态变化是这样的(注意:这里,我略去了其他无关的状态):
- MySQL 查询语句进入执行阶段后,首先把状态设置成“Sending data”;
- 然后,发送执行结果的列相关的信息(meta data) 给客户端;
- 再继续执行语句的流程
- 执行完成后,把状态设置成空字符串
也就是说,“Sending data”并不一定是指“正在发送数据”,而可能是处于执行器过程中的任意阶段。比如,你可以构造一个锁等待的场景,就能看到 Sending data 状态。

图 3 读全表被锁

图 4 Sending data 状态
可以看到,session B 明显是在等锁,状态显示为 Sending data。也就是说,仅当一个线程处于“等待客户端接收结果”的状态,才会显示"Sending toclient";而如果显示成“Sending data”,它的意思只是“正在执行”。
现在你知道了,查询的结果是分段发给客户端的,因此扫描全表,查询返回大量的数据,并不会把内存打爆。
在 server 层的处理逻辑我们都清楚了,在 InnoDB 引擎里面又是怎么处理的呢? 扫描全表会不会对引擎系统造成影响呢?
三、全表扫描对 InnoDB 的影响
在第 2和第 15 篇文章中,我介绍 WAL 机制的时候,和你分析了 InnoDB 内存的一个作用,是保存更新的结果,再配合 redo log,就避免了随机写盘。
1、Buffer Pool 还有一个更重要的作用,就是加速查询
内存的数据页是在 Buffer Pool (BP) 中管理的,在 WAL 里 Buffer Pool 起到了加速更新的作用。而实际上,Buffer Pool 还有一个更重要的作用,就是加速查询。
在第 2 篇文章的评论区有同学问道,由于有 WAL 机制,当事务提交的时候,磁盘上的数据页是旧的,那如果这时候马上有一个查询要来读这个数据页,是不是要马上把 redo log
应用到数据页呢?
答案是不需要。
因为这时候内存数据页的结果是最新的,直接读内存页就可以了。你看,这时候查询根本不需要读磁盘,直接从内存拿结果,速度是很快的。所以说,Buffer Pool
还有加速查询的作用。
而 Buffer Pool 对查询的加速效果,依赖于一个重要的指标,即:内存命中率。
2、内存命中率。
而 Buffer Pool 对查询的加速效果,依赖于一个重要的指标,即:内存命中率。
你可以在 show engine innodb status 结果中,查看一个系统当前的 BP 命中率。一般情况下,一个稳定服务的线上系统,要保证响应时间符合要求的话,内存命中率要在 99%以上。
执行 show engine innodb status ,可以看到“Buffer pool hit rate”字样,显示的就是当前的命中率。比如图 5 这个命中率,就是 99.0%。

图 5 show engine innodb status 显示内存命中率
如果所有查询需要的数据页都能够直接从内存得到,那是最好的,对应的命中率就是100%。但,这在实际生产上是很难做到的。
InnoDB Buffer Pool 的大小是由参数 innodb_buffer_pool_size 确定的,一般建议设置成可用物理内存的 60%~80%。
在大约十年前,单机的数据量是上百个 G,而物理内存是几个 G;现在虽然很多服务器都能有 128G 甚至更高的内存,但是单机的数据量却达到了 T 级别。
所以,innodb_buffer_pool_size 小于磁盘的数据量是很常见的。如果一个 Buffer Pool满了,而又要从磁盘读入一个数据页,那肯定是要淘汰一个旧数据页的。
3、基本 LRU 算法
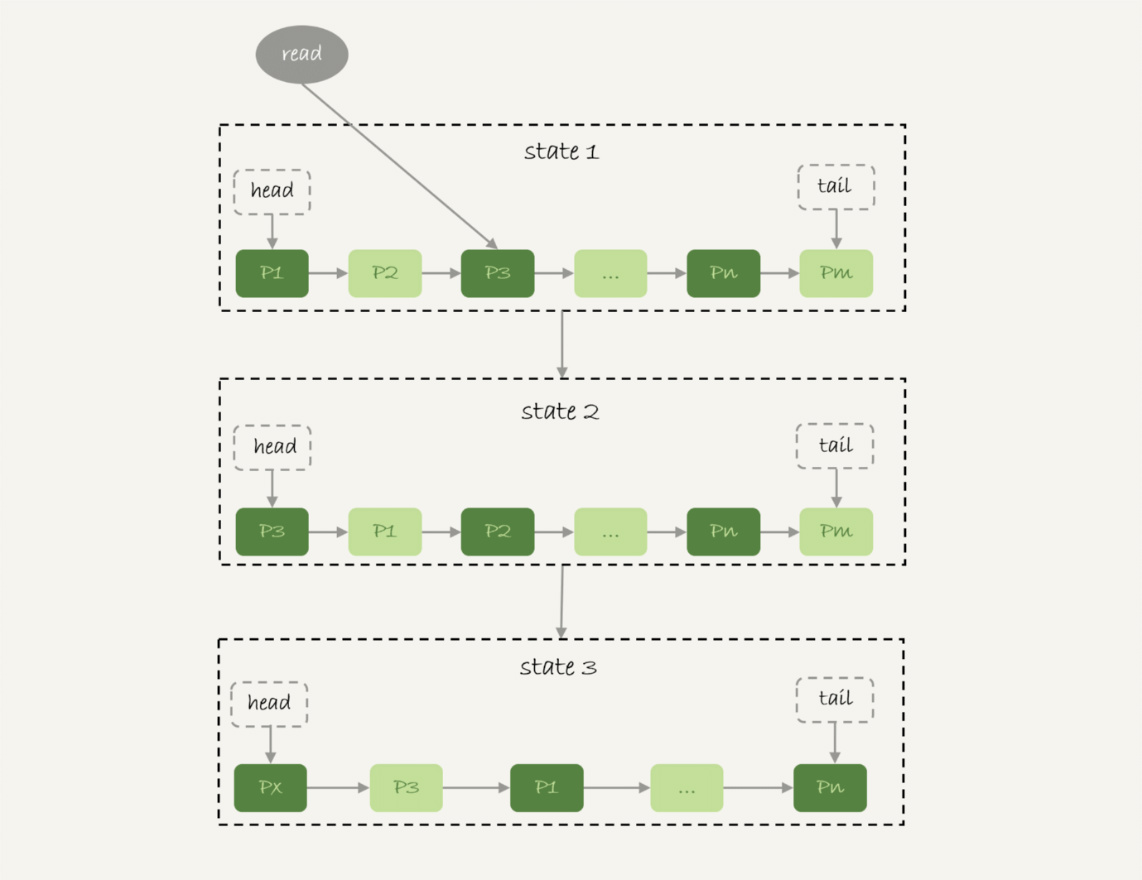
图 6 基本 LRU 算法
InnoDB 管理 Buffer Pool 的 LRU 算法,是用链表来实现的。
1. 在图 6 的状态 1 里,链表头部是 P1,表示 P1 是最近刚刚被访问过的数据页;假设内存里只能放下这么多数据页;
2. 这时候有一个读请求访问 P3,因此变成状态 2,P3 被移到最前面;
3. 状态 3 表示,这次访问的数据页是不存在于链表中的,所以需要在 Buffer Pool 中新申请一个数据页 Px,加到链表头部。但是由于内存已经满了,不能申请新的内存。于是,会清空链表末尾
Pm 这个数据页的内存,存入 Px 的内容,然后放到链表头部。
4. 从效果上看,就是最久没有被访问的数据页 Pm,被淘汰了。
这个算法乍一看上去没什么问题,但是如果考虑到要做一个全表扫描,会不会有问题呢?
假设按照这个算法,我们要扫描一个 200G 的表,而这个表是一个历史数据表,平时没有业务访问它。
那么,按照这个算法扫描的话,就会把当前的 Buffer Pool 里的数据全部淘汰掉,存入扫描过程中访问到的数据页的内容。也就是说 Buffer Pool 里面主要放的是这个历史数据表的数据。
对于一个正在做业务服务的库,这可不妙。你会看到,Buffer Pool 的内存命中率急剧下降,磁盘压力增加,SQL 语句响应变慢。
所以,InnoDB 不能直接使用这个 LRU 算法。实际上,InnoDB 对 LRU 算法做了改进。
4、改进的 LRU 算法
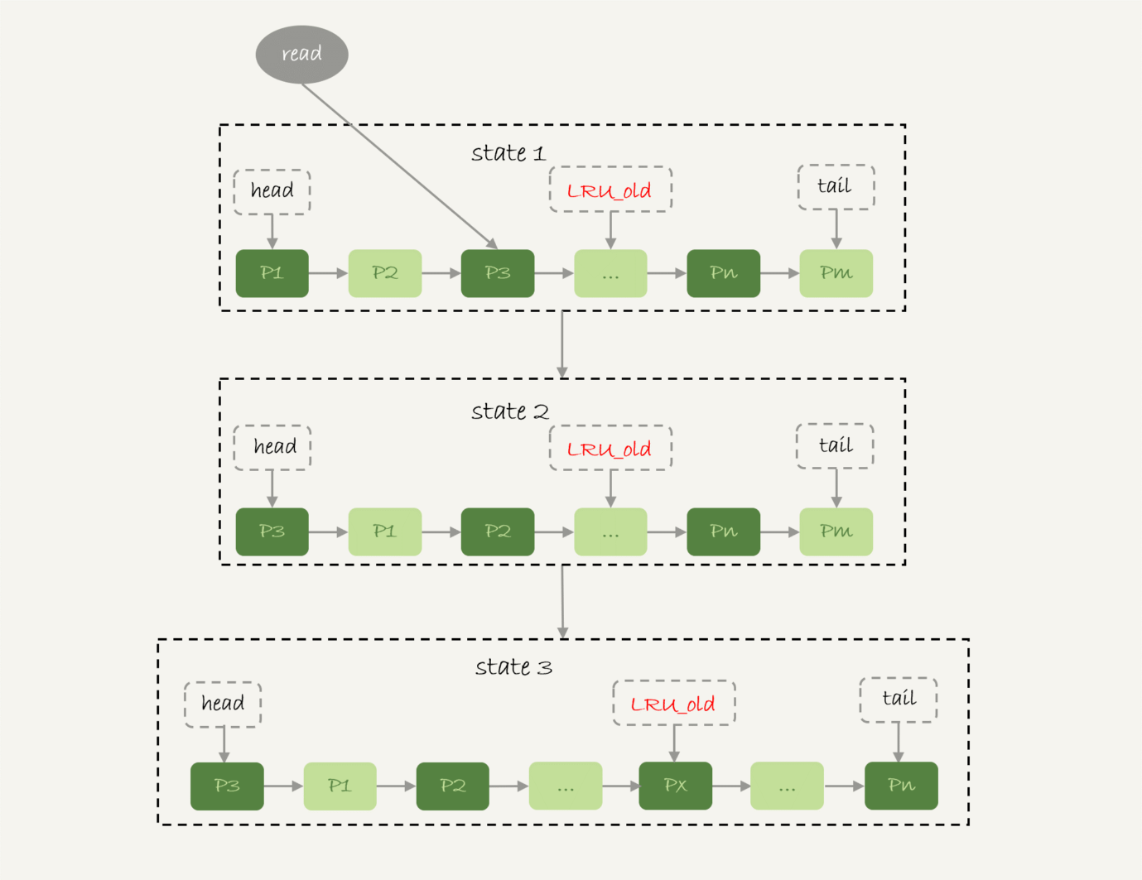
图 7 改进的 LRU 算法
在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。图中 LRU_old 指向的就是 old 区域的第一个位置,是整个链表的 5/8 处。也就是说,靠近
链表头部的 5/8 是 young 区域,靠近链表尾部的 3/8 是 old 区域。
改进后的 LRU 算法执行流程变成了下面这样。
1. 图 7 中状态 1,要访问数据页 P3,由于 P3 在 young 区域,因此和优化前的 LRU 算法一样,将其移到链表头部,变成状态 2。
2. 之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页 Pm,但是新插入的数据页 Px,是放在 LRU_old 处。
3. 处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部;
如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
这个策略,就是为了处理类似全表扫描的操作量身定制的。还是以刚刚的扫描 200G 的历史数据表为例,我们看看改进后的 LRU 算法的操作逻辑:
1. 扫描过程中,需要新插入的数据页,都被放到 old 区域 ;
2. 一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在old 区域;
3. 再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去。
可以看到,这个策略最大的收益,就是在扫描这个大表的过程中,虽然也用到了 BufferPool,但是对 young 区域完全没有影响,从而保证了 Buffer Pool 响应正常业务的查询命中率。
四、小结
今天,我用“大查询会不会把内存用光”这个问题,和你介绍了 MySQL 的查询结果,发送给客户端的过程。
由于 MySQL 采用的是边算边发的逻辑,因此对于数据量很大的查询结果来说,不会在server 端保存完整的结果集。所以,如果客户端读结果不及时,会堵住 MySQL 的查询过
程,但是不会把内存打爆。
而对于 InnoDB 引擎内部,由于有淘汰策略,大查询也不会导致内存暴涨。并且,由于InnoDB 对 LRU 算法做了改进,冷数据的全表扫描,对 Buffer Pool 的影响也能做到可控。
当然,我们前面文章有说过,全表扫描还是比较耗费 IO 资源的,所以业务高峰期还是不能直接在线上主库执行全表扫描的。
最后,我给你留一个思考题吧。
我在文章中说到,如果由于客户端压力太大,迟迟不能接收结果,会导致 MySQL 无法发送结果而影响语句执行。但,这还不是最糟糕的情况。
你可以设想出由于客户端的性能问题,对数据库影响更严重的例子吗?或者你是否经历过这样的场景?你又是怎么优化的?
你可以把你的经验和分析写在留言区,我会在下一篇文章的末尾和你讨论这个问题。感谢你的收听,也欢迎你把这篇文章分享给更多的朋友一起阅读。
五、上节提问
上期的问题是,如果一个事务被 kill 之后,持续处于回滚状态,从恢复速度的角度看,你是应该重启等它执行结束,还是应该强行重启整个 MySQL 进程。
因为重启之后该做的回滚动作还是不能少的,所以从恢复速度的角度来说,应该让它自己结束。
当然,如果这个语句可能会占用别的锁,或者由于占用 IO 资源过多,从而影响到了别的语句执行的话,就需要先做主备切换,切到新主库提供服务。
切换之后别的线程都断开了连接,自动停止执行。接下来还是等它自己执行完成。这个操作属于我们在文章中说到的,减少系统压力,加速终止逻辑。
评论区留言点赞板:
@HuaMax 的回答中提到了对其他线程的影响;
@夹心面包 @Ryoma @曾剑 同学提到了重启后依然继续做回滚操作的逻
MySQL实战45讲学习笔记:第三十三讲的更多相关文章
- MySQL实战45讲学习笔记:第十三讲
一.引子 经常会有同学来问我,我的数据库占用空间太大,我把一个最大的表删掉了一半的数据,怎么表文件的大小还是没变? 那么今天,我就和你聊聊数据库表的空间回收,看看如何解决这个问题. 这里,我们还是针对 ...
- MySQL实战45讲学习笔记:第二十三讲
一.本节概要 今天这篇文章,我会继续和你介绍在业务高峰期临时提升性能的方法.从文章标题“MySQL 是怎么保证数据不丢的?”,你就可以看出来,今天我和你介绍的方法,跟数据的可靠性有关. 在专栏前面文章 ...
- MySQL实战45讲学习笔记:第十五讲
一.引子 在今天这篇答疑文章更新前,MySQL 实战这个专栏已经更新了 14 篇.在这些文章中,大家在评论区留下了很多高质量的留言.现在,每篇文章的评论区都有热心的同学帮忙总结文章知识点,也有不少同学 ...
- MySQL实战45讲学习笔记:第二十四讲
一.引子 在前面的文章中,我不止一次地和你提到了 binlog,大家知道 binlog 可以用来归档,也可以用来做主备同步,但它的内容是什么样的呢?为什么备库执行了 binlog 就可以跟主库保持一致 ...
- MySQL实战45讲学习笔记:第二十五讲
一.引子 在上一篇文章中,我和你介绍了 binlog 的基本内容,在一个主备关系中,每个备库接收主库的 binlog 并执行. 正常情况下,只要主库执行更新生成的所有 binlog,都可以传到备库并被 ...
- MySQL实战45讲学习笔记:第二十六讲
一.引子 在上一篇文章中,我和你介绍了几种可能导致备库延迟的原因.你会发现,这些场景里,不论是偶发性的查询压力,还是备份,对备库延迟的影响一般是分钟级的,而且在备库恢复正常以后都能够追上来. 但是,如 ...
- MySQL实战45讲学习笔记:第十讲
一 .本节内容概要 前面我们介绍过索引,你已经知道了在 MySQL 中一张表其实是可以支持多个索引的.但是,你写 SQL 语句的时候,并没有主动指定使用哪个索引.也就是说,使用哪个索引是由MySQL ...
- MySQL实战45讲学习笔记:第十二讲
一.引子 平时的工作中,不知道你有没有遇到过这样的场景,一条 SQL 语句,正常执行的时候特别快,但是有时也不知道怎么回事,它就会变得特别慢,并且这样的场景很难复现,它不只随机,而且持续时间还很短. ...
- MySQL实战45讲学习笔记:第十六讲
一.今日内容概要 在你开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求.还是以我们前面举例用过的市民表为例,假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前 1000 ...
- MySQL实战45讲学习笔记:第二十二讲
一.引子 不知道你在实际运维过程中有没有碰到这样的情景:业务高峰期,生产环境的 MySQL 压力太大,没法正常响应,需要短期内.临时性地提升一些性能. 我以前做业务护航的时候,就偶尔会碰上这种场景.用 ...
随机推荐
- 使用vmware workstation安装centos 7操作系统
安装步骤 1.点击创建虚拟机,进入新建虚拟机向导,选择自定义,典型:相当于去电脑 旗舰店里店员推荐的是一样,推荐的比一定好,自定义:是手动操作的,没有linux基础最好选择自定义.点击下一步. 2.虚 ...
- Codeforces Round #598 (Div. 3) D. Binary String Minimizing 贪心
D. Binary String Minimizing You are given a binary string of length n (i. e. a string consisting of ...
- workbook数据相关操作
访问单个单元格 c = ws['A4'] #返回单元格A4,如果单元格不存在,则会自动创建 ws['A4'] = 4 #为单元格A4赋值为4 d = ws.cell(row=4, column=2, ...
- SpringBoot系列之配置文件占位符使用
SpringBoot系列之配置文件占位符使用 Springboot占位符支持的有随机数和配置的值等等,本博客主要介绍的是随机数和获取属性配置值的简单用法 随机数获取 支持的写法有: ${random. ...
- VS2019安装好后,经常打不开软件没反应解决方法
原文地址:https://blog.csdn.net/FL1623863129/article/details/89013137 VS2019于昨日正式发布,博主立马下载一个专业版尝尝鲜,但是发现项目 ...
- C# MediaPlayer
using System.Windows.Media; using Newtonsoft.Json; using System.ComponentModel; namespace ConsoleApp ...
- JMeter处理form-data类型的接口
最近的需求中,有的接口入参是form-data类型的,除了用python多进程代码进行压测,考虑用Jmeter试试看,比对一下结果. 线程数设置的是50,循环次数为100,一共发送5000次请求. H ...
- 软件设计之基于Java的连连看小游戏(二)——游戏基础界面的制作及事件的添加
上次完成到游戏首页的制作,今天完成了游戏基础界面的制作以及事件的简单添加.由于功能尚未完全实现,因此游戏界面的菜单列表只是简单地添加了一下,其余菜单列表以及倒计时等在后续的制作中逐一完善. 1.首先在 ...
- elasticsearch window下配置安装
1.首先下载elasticsearch 下载链接:https://www.elastic.co/cn/downloads/elasticsearch 第一张图是下载的,第二章图是下载msi的程序,直接 ...
- docker挡板程序实现启动多个实例进程
启动服务: docker-compose restart