非线性函数的最小二乘拟合及在Jupyter notebook中输入公式 [原创]
突然有个想法,利用机器学习的基本方法——线性回归,来学习一阶RC电路的阶跃响应,从而得到RC电路的结构特征——时间常数τ(即R*C)。回答无疑是肯定的,但问题是怎样通过最小二乘法、正规方程,以更多的采样点数来降低信号采集噪声对τ估计值的影响。另外,由于最近在捣鼓Jupyter和numpy这些东西,正好尝试不用matlab而用Jupyter试试看。结果是意外的好用,尤其是在Jupyter脚本中插入LaTeX格式的公式的功能,真是太方便了!尝试了直接把纸上手写的公式转换到Jupyter脚本中的常见工具软件。
以下原创内容欢迎网友转载,但请注明出处: https://www.cnblogs.com/helesheng
一、理论推导
1.线性回归分析及正规方程
传统意义说,线性回归问题是用最小二乘法(即正规方程),解决线性方程组的均方误差最小化问题。已知输出输入X是由多个变量构成的行向量,W是系数向量(列向量),b为偏置
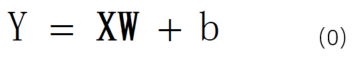
在机器学习中,把每次的输入x作为一行组成更大的矩阵,即每一行代表一个样本,该矩阵称为设计矩阵X(train)。若样本数为k,则X(train)有k行,每个样本都会得到一个输出y,将y集合成一个列向量Y(train),k个相同的b也组成列向量b。为简化表达,将b简化为附加在系数列向量W最后的常数b,X(train)则在每行的最后增加一个1,W(列向量)的最后增加一个待估计的b。为了使估计的结果:
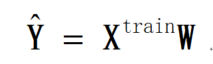
和Y(train)之差的平方和最小,有正规方程可以求解W:
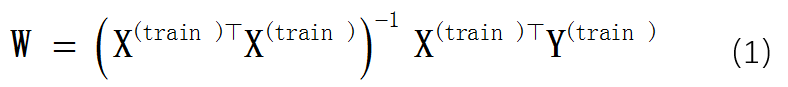
2.一阶RC电路的阶跃响应
一阶RC电路的电路模型如下图所示。
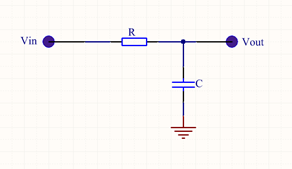
图1 一阶RC电路
幅度为Vcc的阶跃信号从Vin处输入,在Vout处测量输出。解微分方程可得自变量为时间t的响应函数。

其中时间常数τ = R*C。我希望通过测量阶跃信号输入条件下,实际RC电路的响应曲线V(t),并通过V(t)来估计时间常数τ。如果做纯理论推导,只要知道任意时刻t0的输出电压V(t0)就可以解方程(2)得到τ。但在实际电路中电压V(t0)的测量往往受到诸多干扰的影响,并不准确。是否可以测量多个t值时刻对应的V(t),并利用正规方程(1)得到一个统计意义上最优的估计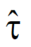 呢?是接下来要解决的问题。
呢?是接下来要解决的问题。
3.非线性函数的最小二乘估计
仔细观察适用正规方程的目标函数(0)式的特点,可以发想让非线性的要让(2)式能够使用正规方程,必须让:
1) 含有待估计的变量τ的函数充当(0)式中的系数W,而设计矩阵X(train)则可以由含有时间t或测量电压V(t)的函数充当。
2) W和X(train)之间的关系必须是简单的相乘。
显然,只有用时间t的序列充当设计矩阵X(train),才有可能使W和X(train)之间的关系必须是相乘。至于其他的非线性部分则可以通过等效变换,变换到等式的另一侧来充当Y(train)。综上,可以将(2)式变换为(3)式。
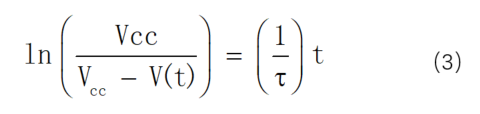
(3)式的整个左边可以计算得到Y(train);(3)式右边的时间t的序列在构成设计矩阵X(train),1/τ则构成相当于(0)式中的系数矩阵W。这样就可以通过正规方程(2)式来求解统计意义上最优的估计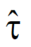 了。当然,从(3)式也可以看出,经过线性校正的模型中系数向量W只有一个元素——是个标量,偏置b也是恒等于0的。
了。当然,从(3)式也可以看出,经过线性校正的模型中系数向量W只有一个元素——是个标量,偏置b也是恒等于0的。
二、仿真模型
想利用最近正在尝试使用的Jupyter和numpy替代熟悉的Matlab,验证上述非线性函数最小二乘估计的想法。下面先建立一个模型:
1) 输入为幅度Vcc为3.3V的阶跃信号;
2) 时间常数τ为0.1秒;
3) 简单模拟采样间隔的随机性:是间隔等于delta1=0.0015秒和delta1=0.0011秒的两个序列的叠加。
4) 采样总长度为n=5倍τ;
5) 信号上叠加了幅度约为20mV的白噪声——至于为什么是20mV,将在后续部分详细介绍。
利用python和numpy进行数值仿真的代码如下:
import numpy as np
import matplotlib.pyplot as plt
tao=0.1#时间常数
vcc=3.3#电源电压
n=5#时长取时间常数tao的n倍
delta1=0.0015#第一种采样间隔
delta2=0.0011#第一种采样间隔
t1=delta1*np.arange(np.ceil(n*tao/delta1))
t2=delta2*np.arange(np.ceil(n*tao/delta2))
t=np.append(t1,t2)#为演示最小二乘拟合的功能,故意结合两种采样率下的时间点
t.sort()#对t进行排序
plt.plot(t)
s=vcc*(1-np.exp(-t/tao))#理论的波形曲线
plt.plot(t,s)#注意这里的plot函数使用了x轴和y轴两个轴,因为s中的数据不是均匀的
N_amp=np.exp(-n)*vcc
N_amp
noise = np.random.uniform(-N_amp, N_amp, (len(t)))#噪声:正负np.exp(-5)*3.3之间均匀分布
s_nr=s+noise#加入噪声后的信号
plt.plot(t,s_nr)
yt=np.log(vcc/(vcc-s_nr))
plt.plot(t,yt)
yt=np.mat(yt)
yt=yt.T
x=np.mat(t)#将X转换为矩阵数据类型
x=x.T#正规方程中的x应该是个列向量
w=(np.linalg.inv(x.T*x))*x.T*yt#求解正规方程
E_tao = np.round(1/float(w),4)#对时间常数的tao的估计,保留到4位小数
E_tao
非线性函数的最小二乘拟合
说明:
1) 其间序列包含了两个等差数列t1和t2的融合,它们的间隔互质,没有重复,目的是模拟采样时间的随机性。最后用sort()方法又对时间序列进行排序的目的是为了后续容易观察波形更直观。如果仅仅为了使用正规方程,是不需要重新排序的。
2) 校正的非线性方程(3)和原始方程(2)相比有一个重大的缺陷就是:左侧求对数的括号内的数值不能为负——如果是纯理论推导,这是不可能发生的。但假如随机噪声后的V(t)是有可能大于阶跃幅度Vcc的,此时括号内将变为一个负数,使得计算变得没有意义。我的解决之道是将假如的随机噪声幅度限制在仿真截止时刻V(t)和Vcc之差的范围内,及代码中的N_amp。由于仿真的结束时刻为n(=5)个τ,所以N_amp的值等于np.exp(-n)*vcc。
这样做没有任何理论依据,仅仅是受限于(3)和(2)式之间的非完全等价变换——属于线性化校正需要付出的代价。
3) 由于待估计的参数只有一个(1/τ)所以正规方程的解也是只有一个元素的矩阵。将其转换为标量后取倒得到最优估计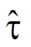 。
。
三、结果评估
加入噪声后的信号如下图所示,与通常情况的实测波形吻合度很高。
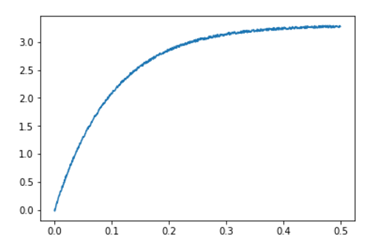
图2 模拟产生的带有噪声的阶跃响应
对这些加入噪声的信号进行线性校正后得到进行最小二乘估计的信号yt为下图所示。其基本趋势是一条斜率为(1/τ)的直线,和我预计的结果一样。

图3 对图2进行线性校正后的待估计信号
但可以明显的看到,由于(3)式左侧在V(t)的大小接近Vcc时对加入的白噪声进行了放大。因此当t递增时,由白噪声造成的信号的不确定性大大增加了。也就是在套用正规方程时,t值较大时的噪声对结果的影响大于t值较小时的噪声对结果的影响。这是使用非线性校正函数需要付出的重要代价。
另外,多次运行以上代码的得到 都是一个略小于实际τ(=0.1)的数值——约为0.099左右,也就是说, 不是无偏估计。这应该是由于线性校正函数((3)式左侧),对于噪声noise大于0和小于0的部分进行了非对称的变换造成的。这虽然造成的偏差不大,但也是使用非线性校正函数需要付出的代价。
四、Jupyter notebook
上述练习的一个重要目的是练习使用Jupyter notebook,并在其中内嵌具有很好交互性的公式等信息。以下是部分程序运行效果的截图,虽然我对markdown语法还不熟悉,格式和排版还不够漂亮,但还是能够明显的提高代码的可读性。
图4 Jupyter notebook运行效果截图
其中需要重点记录下的是公式代码的嵌入过程:
1)我首先在纸上手写了一些公式,用手机对其拍照,如:
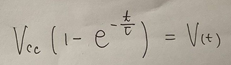
图5 手写的公式
2)用mathpix tools对这些照片截图,并扫描(mathpix tools有windows版和iOS版,均可免费试用)。Mathpix可以直接得到LaTeX格式的公式表达式。下图是iOS版本的mathpix界面截图。

图6 iOS版本的mathpix截图
3)在Jupyter notebook上部的下拉菜单中选择单元格的格式为Markdown;将LaTeX格式的公式表达式粘贴到该单元格内,并在LaTeX公式表达式的前后加上“$$”符号,运行该单元格即可得到图4所示效果的公式了。
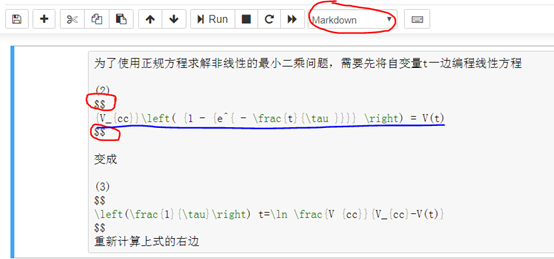
图7 在Jupyter notebook中输入LaTeX公式
五、进一步的实际测试
工作做到这里离其实并没有完,还应该做一个简单的实际电路实测一下。我会在后续的假期中抽半天时间,在STM32开发板上完成这个工作:用GPIO产生一个节约信号后,连续采集5个τ时间长度的信号,并代入正规方程求解,欢迎大家继续关注更新。
……
非线性函数的最小二乘拟合及在Jupyter notebook中输入公式 [原创]的更多相关文章
- 在jupyter notebook 中编辑公式
jupyter notebook是一个python的交互式开发环境,广泛应用于数据分析的场景下. 在jupyter notebook中,还可以很方便的编辑数学公式. 1.Markdown状态 编辑公式 ...
- 机器学习:Jupyter Notebook中numpy的使用
一.Jupyter Notebook的魔法命令 # 模块/方法 + ?或者help(模块/方法):查看模块/方法的解释文档: 1)%run # 机械学习中主要应用两个魔法命令:%run.%timeit ...
- 在jupyter notebook中同时安装python2和python3
之前讨论过在anaconda下安装多个python版本,本期来讨论下,jupyter notebook中怎样同时安装python2.7 和python3.x. 由于我之前使用的jupyter note ...
- jupyter notebook中No module named 'tensorflow'
当我们在jupyter notebook中运行时可能会遇见没有某个包的情况,如下: ---------------------------------------------------------- ...
- 解决在jupyter notebook中遇到的ImportError: matplotlib is required for plotting问题
昨天学习pandas和matplotlib的过程中, 在jupyter notebook遇到ImportError: matplotlib is required for plotting错误, 以下 ...
- 在jupyter notebook中运行R语言
要想在jupyter notebook中运行R语言其实非常简单,按顺序安装下面扩展包即可: install.package('repr','IRdisplay','evaluate','crayon' ...
- 在jupyter notebook 中同时使用安装不同版本的python内核-从而可以进行切换
在安装anaconda的时候,默认安装的是python3.6 但是cs231n课程作业是在py2.7环境下运行的.所以需要在jupyter notebook中安装并启用python2.7版本 方法: ...
- jupyter notebook中出现ValueError: signal only works in main thread 报错 即 长时间in[*] 解决办法
我在jupyter notebook中新建了一个基于py3.6的kernel用来进行tensorflow学习 但是在jupyter notebook中建立该kernel时,右上角总是显示 服务正在启动 ...
- (数据科学学习手札64)在jupyter notebook中利用kepler.gl进行空间数据可视化
一.简介 kepler.gl是由Uber开发的进行空间数据可视化的开源工具,是Uber内部进行空间数据可视化的默认工具,通过其面向Python开放的接口包keplergl,我们可以在jupyter n ...
随机推荐
- python:爬虫2——隐藏自己
一.添加浏览器 方法一: head['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, li ...
- 从surfaceflinger历史变更谈截屏
众所周知,有一个程序screencap可以截屏,这个程序十分简单,只是使用了surfaceflinger服务的截屏功能. 所以要了解截屏,看surfaceflinger服务的代码是不二首选.但是sur ...
- Spring的整体架构的认识
Spring的整体架构的认识 一).spring是用来做什么的? spirng使用基本的JavaBean来完成以前EJB所完成的事. 二).EJB EJB: Enterprise JavaBean, ...
- 防火墙和SELinux复习02
1.防火墙 防火墙主要起隔离作用,严格的过滤入站,允许出站.又分为硬件防火墙和软件防火墙,硬件防火墙主要保护一群机器,而软件防火墙主要保护本机. 防火墙相关命令:systemctl status fi ...
- labview连接mysql数据库
前期准备:安装MySQL 并设置可远程连接 第一步 安装 mysql connector odbc https://www.cr173.com/soft/50794.html 第二步:创建数据源 本机 ...
- 【Elasticsearch 7 探索之路】(四)Analyzer 分析
上一篇,什么是倒排索引以及原理是什么.本篇讲解 Analyzer,了解 Analyzer 是什么 ,分词器是什么,以及 Elasticsearch 内置的分词器,最后再讲解中文分词是怎么做的. 一.A ...
- 宋宝华:关于ARM Linux原子操作的实现
本文系转载,著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 作者: 宋宝华 来源: 微信公众号linux阅码场(id: linuxdev) 竞态无所不在 首先我们要理解竞态(ra ...
- [UWP]UIElement.Clip虽然残废,但它还可以这样玩
1. 复习一下WPF的UIElement.Clip 用了很久很久的WPF,但几乎没有主动用过它的Clip属性,我只记得它很灵活,可以裁剪出多种形状.在官方文档复习了一下,大致用法和效果如下: < ...
- 【转】Pandas常见用法总结
关键缩写和包导入 在这个速查手册中,我们使用如下缩写: df:任意的Pandas DataFrame对象 s:任意的Pandas Series对象 raw:行标签 col:列标签 引入响应模块: im ...
- 实战webpack系列说明
01.概念股 本质上,webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler). 当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(d ...