python网络爬虫(11)近期电影票房或热度信息爬取
目标意义
为了理解动态网站中一些数据如何获取,做一个简单的分析。
说明
思路,原始代码来源于:https://book.douban.com/subject/27061630/。
构造-下载器
构造分下载器,下载原始网页,用于原始网页的获取,动态网页中,js部分的响应获取。
通过浏览器模仿,合理制作请求头,获取网页信息即可。
代码如下:
import requests
import chardet
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
user_agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
headers={'User-Agent':user_agent}
r=requests.get(url,headers=headers)
if r.status_code is 200:
r.encoding=chardet.detect(r.content)['encoding']
return r.text
return None
构造-解析器
解析器解析数据使用。
获取的票房信息,电影名称等,使用解析器完成。
被解析的动态数据来源于js部分的代码。
js地址的获取则通过F12控制台-->网络-->JS,然后观察,得到。
地址如正上映的电影:
http://service.library.mtime.com/Movie.api?Ajax_CallBack=true&Ajax_CallBackType=Mtime.Library.Services&Ajax_CallBackMethod=GetMovieOverviewRating&Ajax_CrossDomain=1&Ajax_RequestUrl=http://movie.mtime.com/257982/&t=201907121611461266&Ajax_CallBackArgument0=257982
返回信息中,解析出json格式的部分,通过json的一些方法,获取其中的票房等信息。
其中,json解析工具地址如:https://www.json.cn/
未上映的电影是同理的。
这些数据的解析有差异,所以定制了函数分支,处理解析过程中可能遇到的不同情景。
代码如下:
import re
import json
class HtmlParser(object):
def parser_url(self,page_url,response):
pattern=re.compile(r'(http://movie.mtime.com/(\d+)/)')
urls=pattern.findall(response)
if urls != None:
return list(set(urls))#Duplicate removal
else:
return None def parser_json(self,url,response):
#parsing json. input page_url as js url and response for parsing
pattern=re.compile(r'=(.*?);')
result=pattern.findall(response)[0]
if result != None:
value=json.loads(result)
isRelease=value.get('value').get('isRelease')
if isRelease:
isRelease=1
return self.parser_json_release(value,url)
else:
isRelease=0
return self.parser_json_notRelease(value,url)
return None
def parser_json_release(self,value,url):
isRelease=1
movieTitle=value.get('value').get('movieTitle')
RatingFinal=value.get('value').get('movieRating').get('RatingFinal')
try:
TotalBoxOffice=value.get('value').get('boxOffice').get('TotalBoxOffice')
TotalBoxOfficeUnit=value.get('value').get('boxOffice').get('TotalBoxOfficeUnit')
except:
TotalBoxOffice="None"
TotalBoxOfficeUnit="None"
return isRelease,movieTitle,RatingFinal,TotalBoxOffice,TotalBoxOfficeUnit,url def parser_json_notRelease(self,value,url):
isRelease=0
movieTitle=value.get('value').get('movieTitle')
try:
RatingFinal=Ranking=value.get('value').get('hotValue').get('Ranking')
except:
RatingFinal=-1
TotalBoxOffice='None'
TotalBoxOfficeUnit='None'
return isRelease,movieTitle,RatingFinal,TotalBoxOffice,TotalBoxOfficeUnit,url
构造-存储器
存储方案为Sqlite,所以在解析器中isRelease部分,使用了0和1进行的存储。
存储需要连接sqlite3,创建数据库,获取执行数据库语句的方法,插入数据等。
按照原作者思路,存储时,先暂时存储到内存中,条数大于10以后,将内存中的数据插入到sqlite数据库中。
代码如下:
import sqlite3
class DataOutput(object):
def __init__(self):
self.cx=sqlite3.connect("MTime.db")
self.create_table('MTime')
self.datas=[] def create_table(self,table_name):
values='''
id integer primary key autoincrement,
isRelease boolean not null,
movieTitle varchar(50) not null,
RatingFinal_HotValue real not null default 0.0,
TotalBoxOffice varchar(20),
TotalBoxOfficeUnit varchar(10),
sourceUrl varchar(300)
'''
self.cx.execute('create table if not exists %s(%s)' %(table_name,values)) def store_data(self,data):
if data is None:
return
self.datas.append(data)
if len(self.datas)>10:
self.output_db('MTime') def output_db(self,table_name):
for data in self.datas:
cmd="insert into %s (isRelease,movieTitle,RatingFinal_HotValue,TotalBoxOffice,TotalBoxOfficeUnit,sourceUrl) values %s" %(table_name,data)
self.cx.execute(cmd)
self.datas.remove(data)
self.cx.commit() def output_end(self):
if len(self.datas)>0:
self.output_db('MTime')
self.cx.close()
主函数部分
创建以上对象作为初始化
然后获取根路径。从根路径下找到百余条电影网址信息。
对每个电影网址信息一一解析,然后存储。
import HtmlDownloader
import HtmlParser
import DataOutput
import time
class Spider(object):
def __init__(self):
self.downloader=HtmlDownloader.HtmlDownloader()
self.parser=HtmlParser.HtmlParser()
self.output=DataOutput.DataOutput() def crawl(self,root_url):
content=self.downloader.download(root_url)
urls=self.parser.parser_url(root_url, content)
for url in urls:
print('.')
t=time.strftime("%Y%m%d%H%M%S1266",time.localtime())
rank_url='http://service.library.mtime.com/Movie.api'\
'?Ajax_CallBack=true'\
'&Ajax_CallBackType=Mtime.Library.Services'\
'&Ajax_CallBackMethod=GetMovieOverviewRating'\
'&Ajax_CrossDomain=1'\
'&Ajax_RequestUrl=%s'\
'&t=%s'\
'&Ajax_CallBackArgument0=%s' %(url[0],t,url[1])
rank_content=self.downloader.download(rank_url)
try:
data=self.parser.parser_json(rank_url, rank_content)
except:
print(rank_url)
self.output.store_data(data) self.output.output_end()
print('ed')
if __name__=='__main__':
spider=Spider()
spider.crawl('http://theater.mtime.com/China_Beijing/')
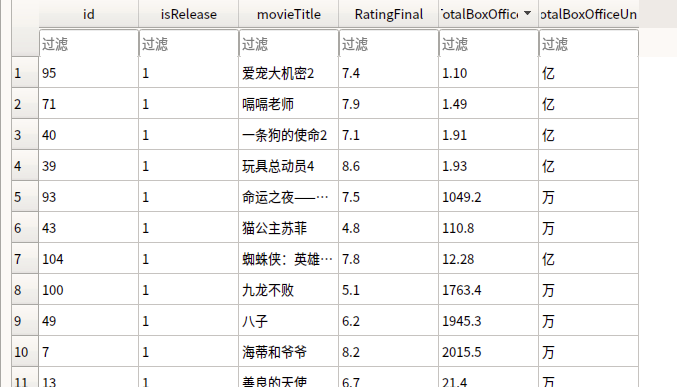
当前效果
如下:
python网络爬虫(11)近期电影票房或热度信息爬取的更多相关文章
- Python 网络爬虫 004 (编程) 如何编写一个网络爬虫,来下载(或叫:爬取)一个站点里的所有网页
爬取目标站点里所有的网页 使用的系统:Windows 10 64位 Python语言版本:Python 3.5.0 V 使用的编程Python的集成开发环境:PyCharm 2016 04 一 . 首 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- 从零开始学Python网络爬虫PDF高清完整版免费下载|百度网盘
百度网盘:从零开始学Python网络爬虫PDF高清完整版免费下载 提取码:wy36 目录 前言第1章 Python零基础语法入门 11.1 Python与PyCharm安装 11.1.1 Python ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
随机推荐
- VMware Workstation克隆linux虚拟机操作
1.删除MAC地址,修改IP [root@xuegod63 network-scripts]# vim ifcfg-eth0 [root@xuegod63 network-scripts]# cat ...
- 【转载】MySQL Replication 环境安装与配置
安装[root@msr01 ~]# yum install mysql-serverInstalled:mysql-server.x86_64 0:5.1.73-3.el6_5 Dependency ...
- Call asynchronous method in constructor
using System; using System.ComponentModel; using System.Threading.Tasks; public sealed class NotifyT ...
- c# Unity依赖注入WebService
1.IOC与DI简介 IOC全称是Inversion Of Control(控制反转),不是一种技术,只是一种思想,一个重要的面相对象编程的法则,它能知道我们如何设计出松耦合,更优良的程序.传统应用程 ...
- apache卸载
windows下apache如何完整卸载? 原创 2014年08月14日 21:30:38 13960 1.运行services.msc,在服务中停止 apache 服务. 2.运行命令行程序,输入 ...
- WPF 使用Trigger遇到的问题
1. 在style中使用trigger无效的场景 原因是直接在对象上设置值将导致style中的值无效,去掉TextBlock对象的Foreground后,Trigger将正常工作 <TextBl ...
- 零元学Expression Blend 4 - Chapter 9 用实例了解布局容器系列-「Canvas」
原文:零元学Expression Blend 4 - Chapter 9 用实例了解布局容器系列-「Canvas」 本系列将教大家以实做案例认识Blend 4 的布局容器,此章介绍的布局容器是Blen ...
- ADB命令笔记本
ADB即Android Debug Bridge,作为电脑操作手机的工具,被Android开发者和众多国内xxx安全管家所使用.在此记录一些常见的命令,随时更新,方便以后查找.(万一以后我也要开发一款 ...
- Android零基础入门第42节:自定义BaseAdapter
原文:Android零基础入门第42节:自定义BaseAdapter 在ListView的使用中,有时候还需要在里面加入按钮等控件,实现单独的操作.也就是说,这个ListView不再只是展示数据,也不 ...
- ORA-02085: database link string connect to string
ORA-02085: database link string connects to string Cause: a database link connected to a database wi ...