web scraper——简单的爬取数据【二】
在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧。
http://top.baidu.com/buzz?b=1&fr=20811
文本太长,大部分是图片,所以上下操作视频吧,视频爬取的是昵称不是百度热点数据
链接:https://pan.baidu.com/s/1W-8kGDznZZjoQIk1e6ikfQ
提取码:3dj7
爬取步骤
创建站点
打开百度热点,ctrl+shit+i进入检测工具,打开web scraper创建站点
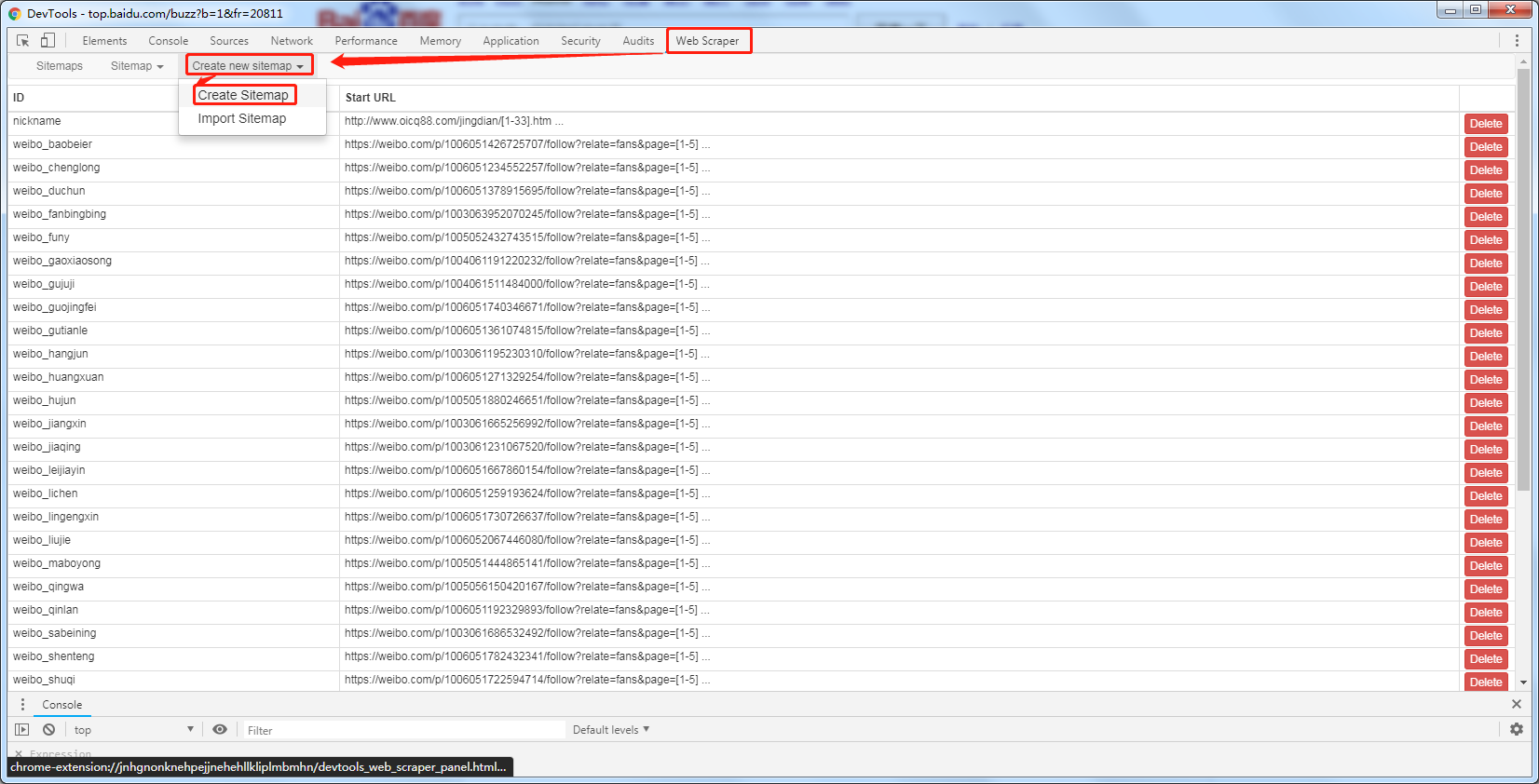
进入 创建站点页面 站点名称和爬取地址点击创建站点即可
如果要爬取分页数据那就将参数写成范围的如:
想要爬取微博某博主关注列表的1-5页的粉丝信息,通过url的跳转发现微博关注列表和<number>数字有关
https://weibo.com/p/1003061752021340/follow?relate=fans&page=<number>
所以只要把<number>写成一个范围的即可
https://weibo.com/p/1006051234552257/follow?relate=fans&page=[1-5]
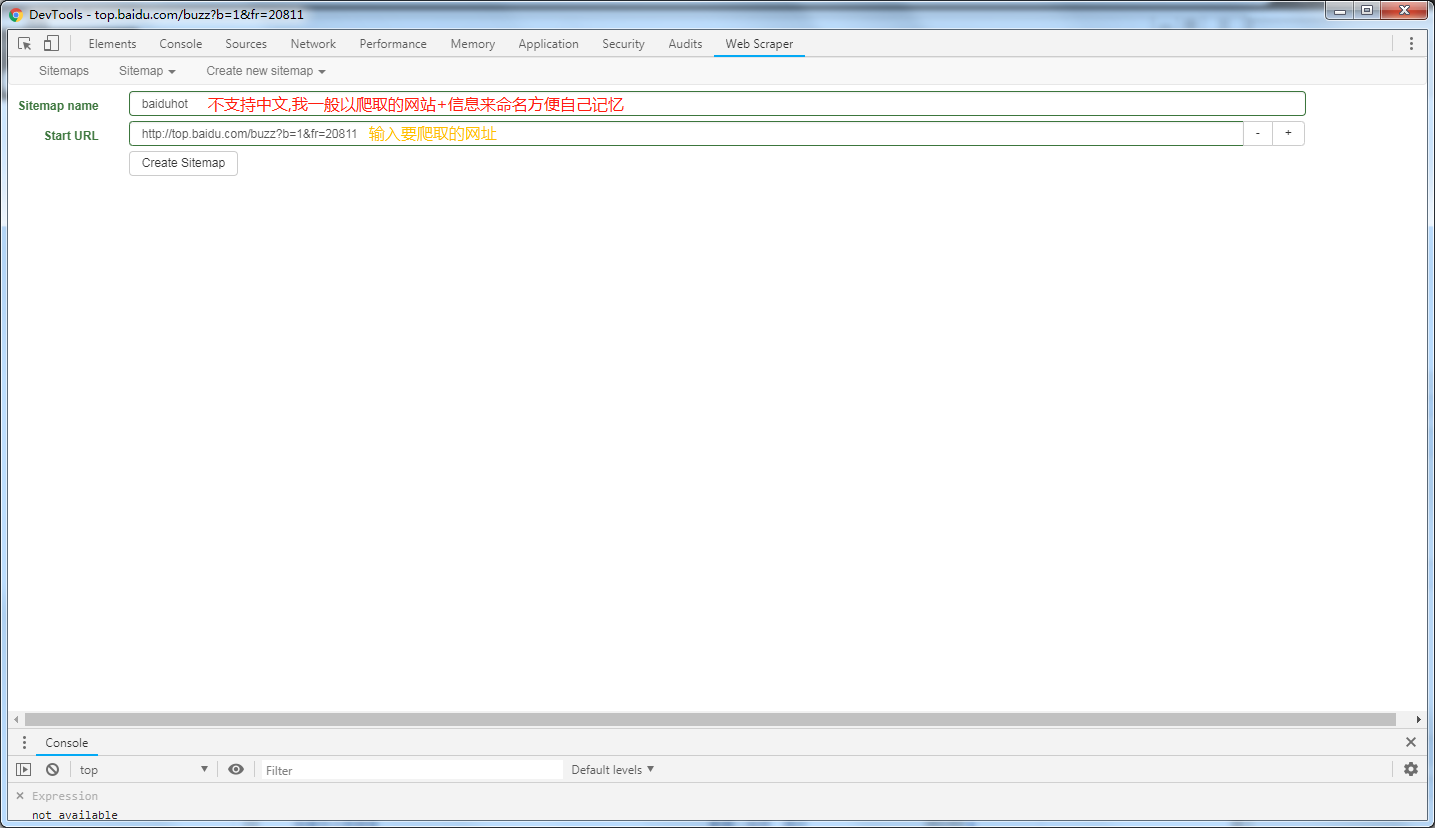
爬取数据
首先创建一个element的select
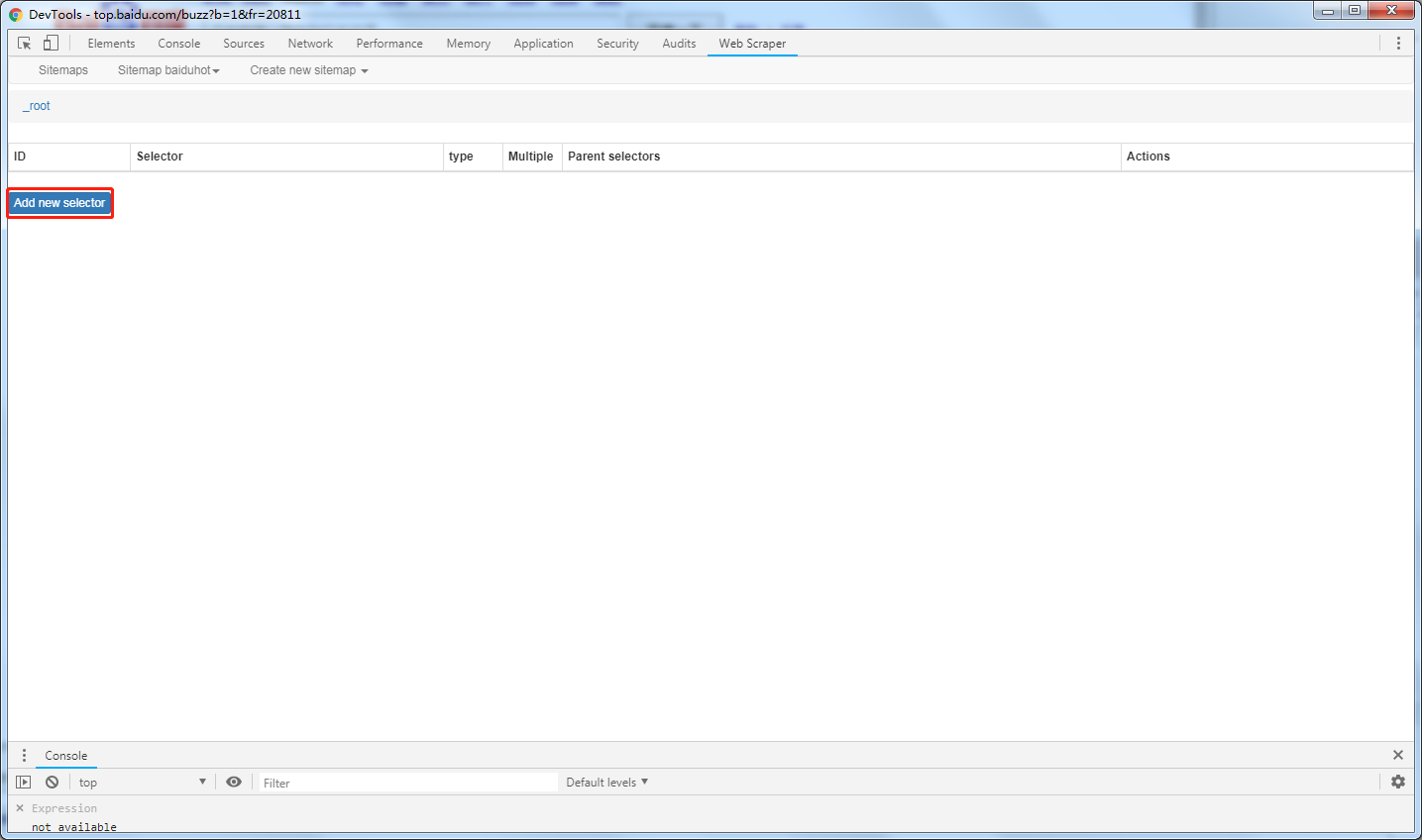
创建element信息
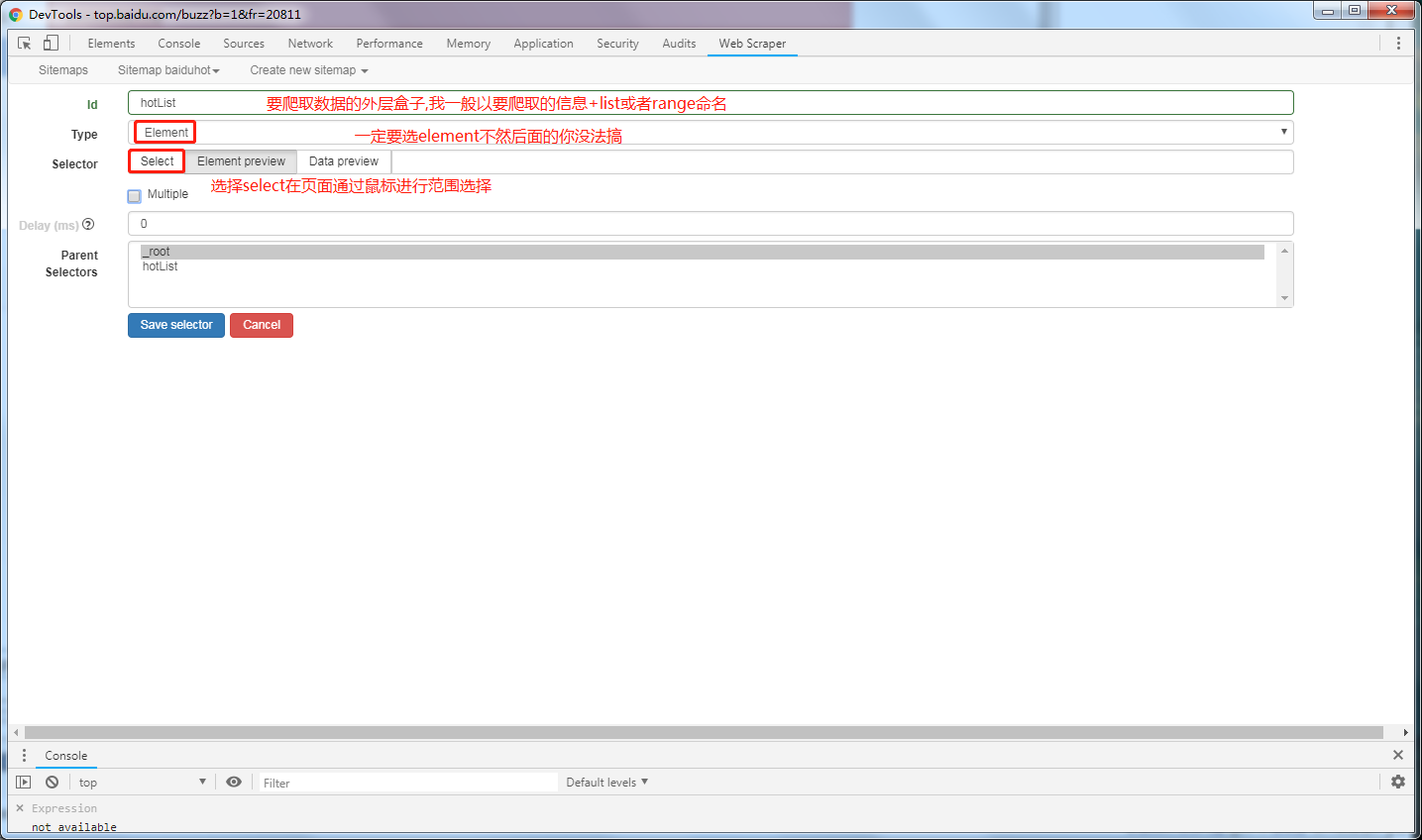
select选择最外层的盒子,确认无误后点击Done selecting!
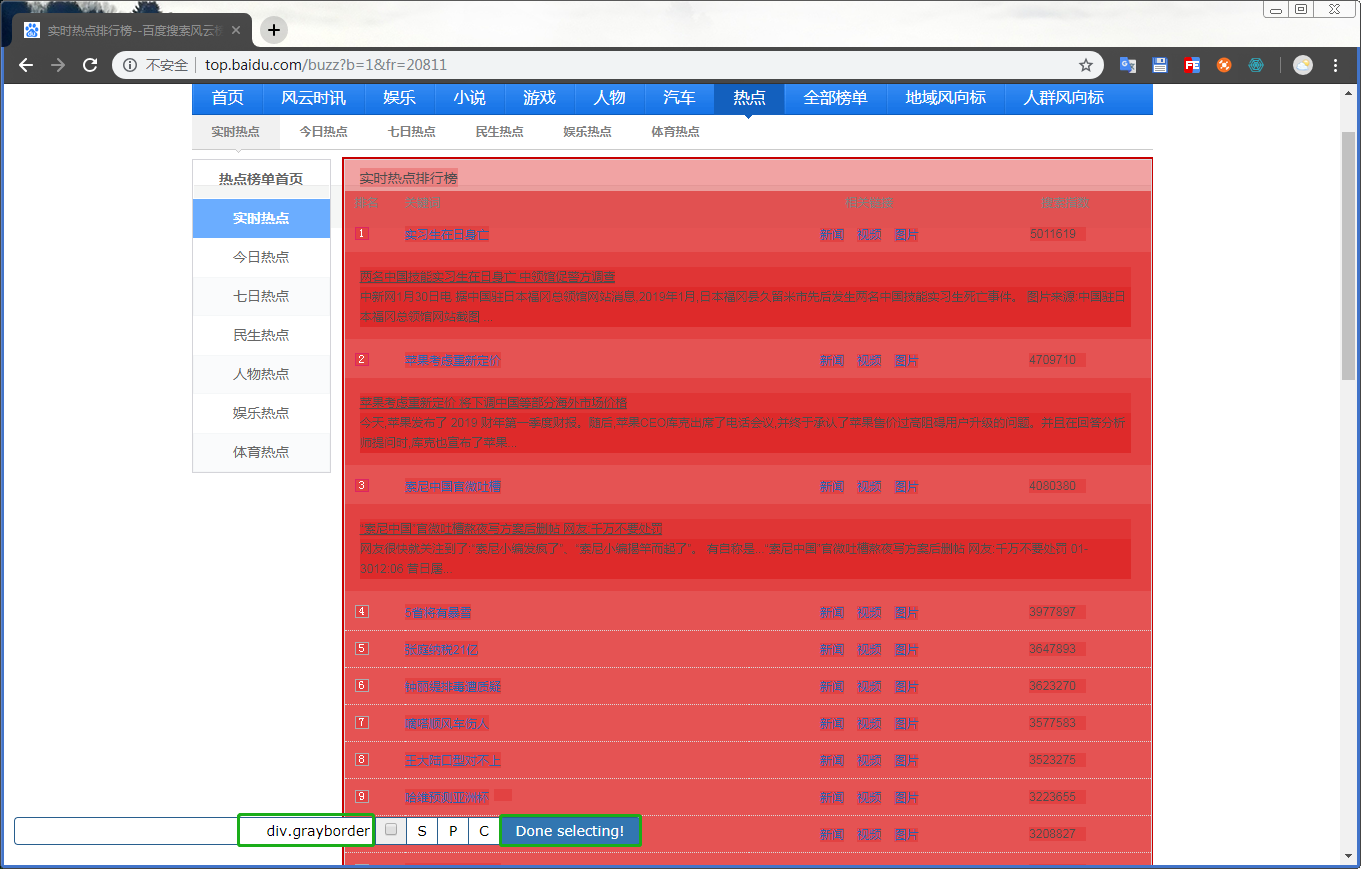
然后回到web scraper控制台,查看信息无误后勾选multiple确认无误后,创建element的select

爬取自己想要的信息,点击进入hotList里面,然后继续创建select选择
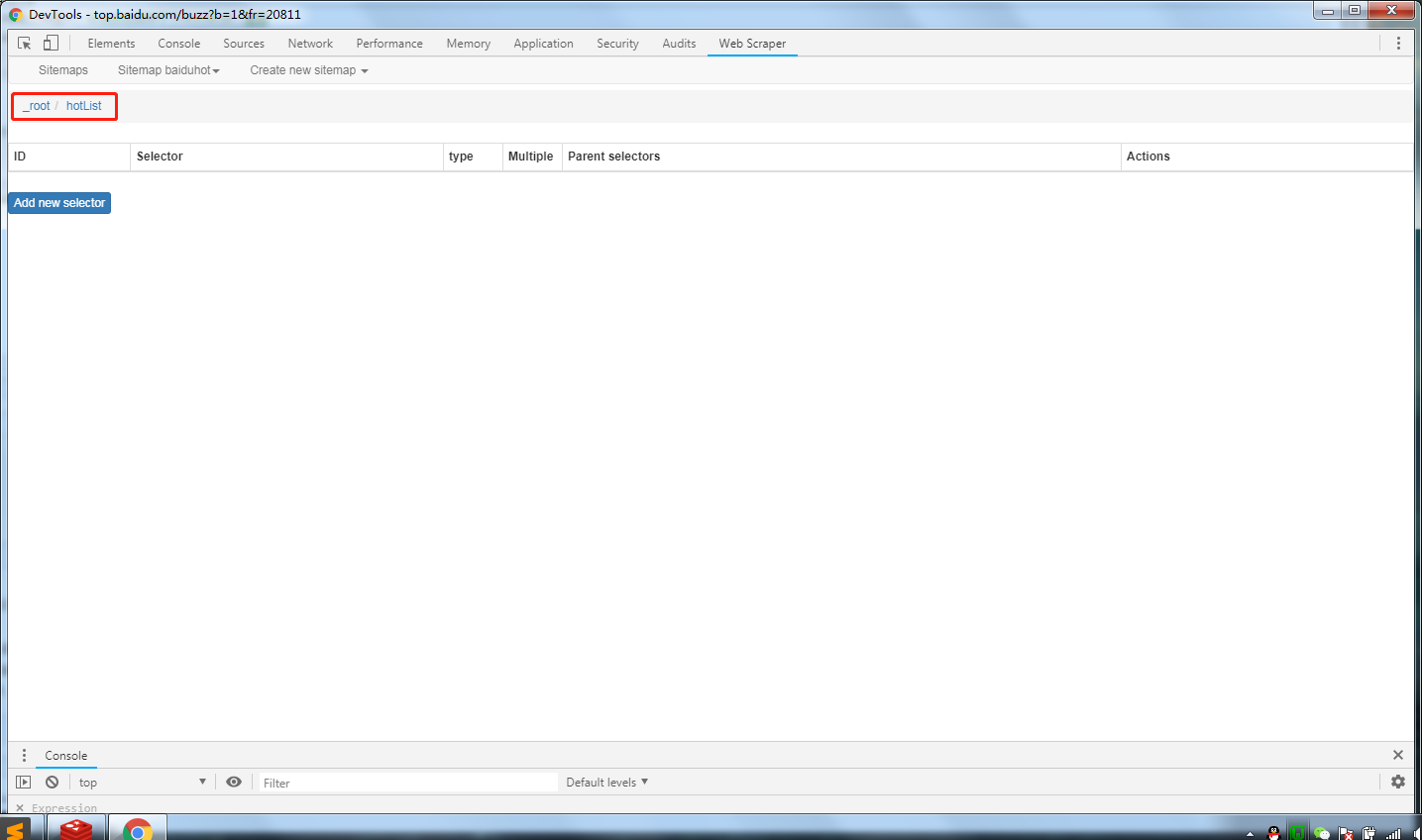
填写具体的select信息,并继续通过select来进行选择需要的数据
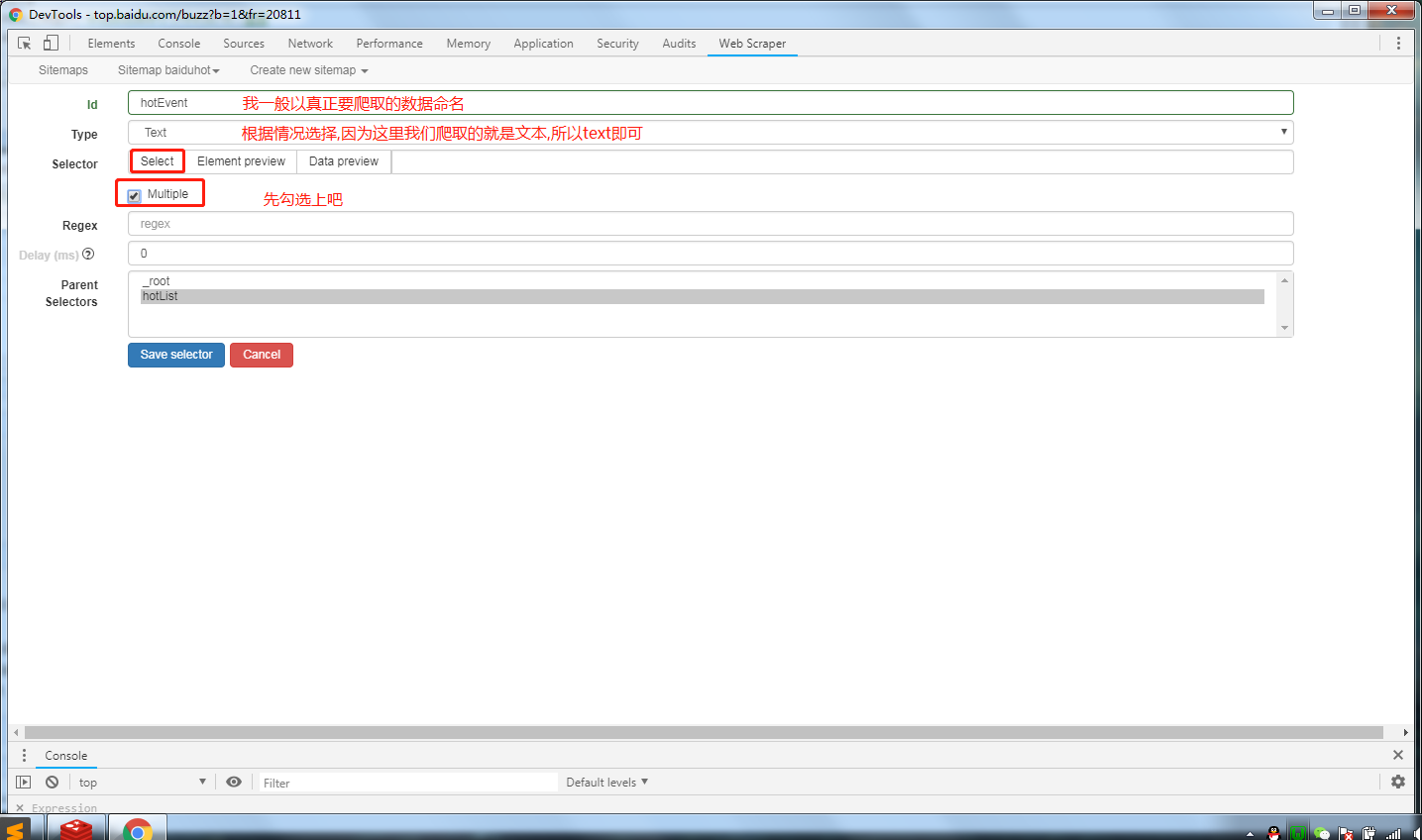
这时候页面的范围会变为黄色,鼠标移动到自己需要的信息处会有绿框将信息圈出来
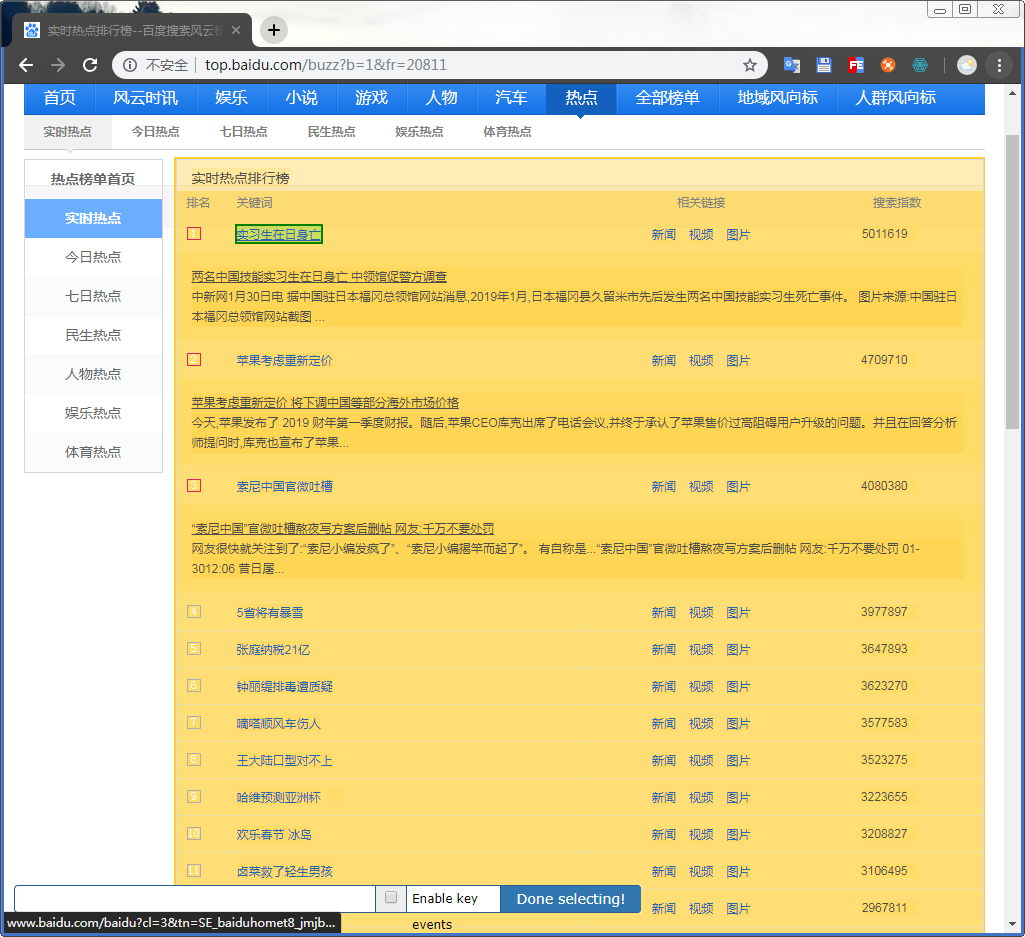
点击确认后会变为红色的,再次选择相同的会自动识别将同样标签下的包围起来,确认是自己需要的信息后直接Done selecting!
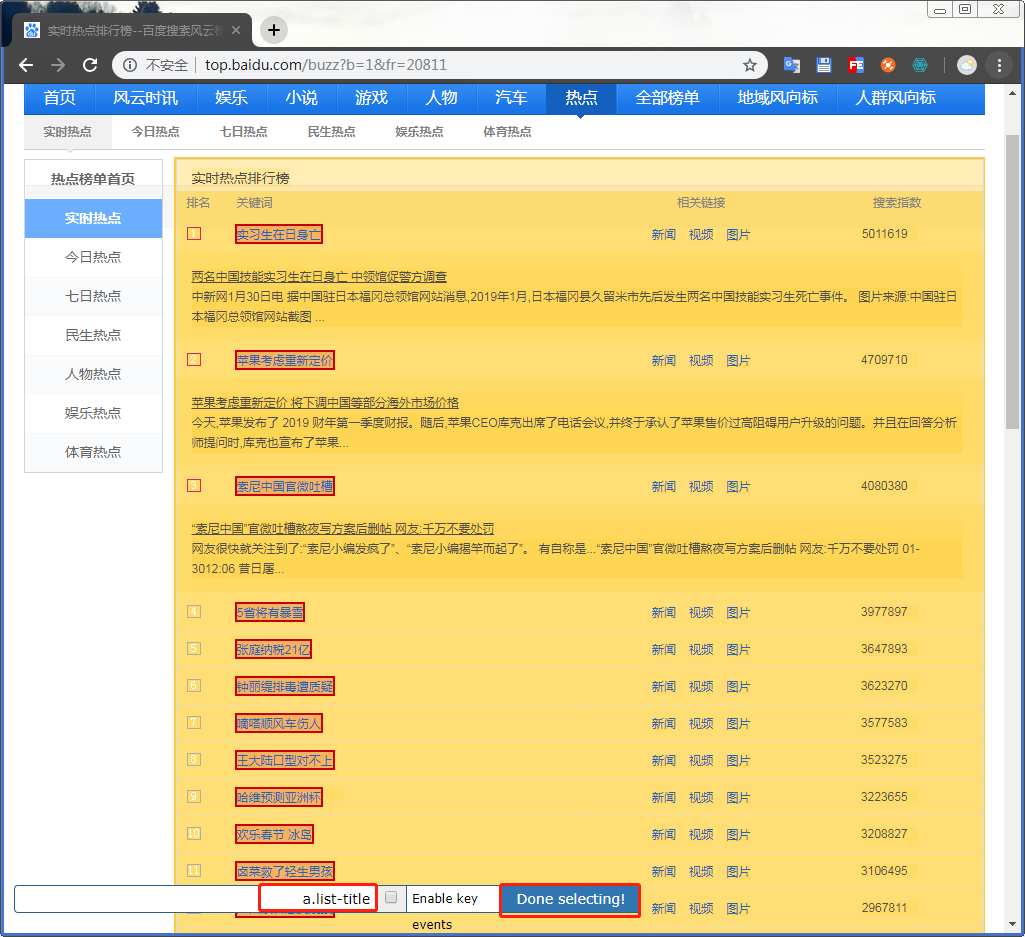
再次转到web scraper的控制台后,确认无误即可保存
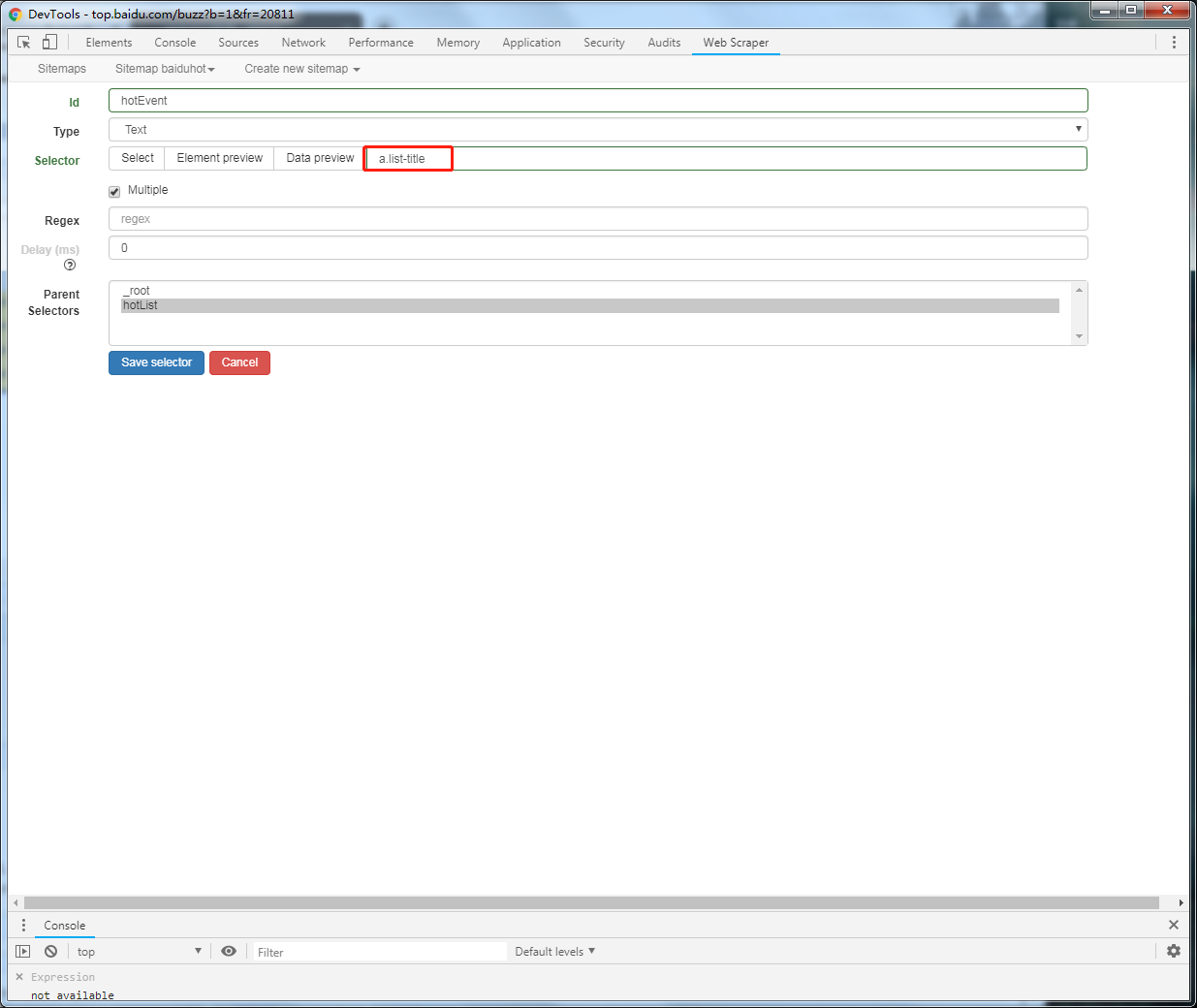
运行脚本,进行采集
默认配置即可,想修改也可以的,我一般直接默认的

点击开始脚本后,会将采集的页面弹出,采集完成右下角会出现提示,采集过程中点击refresh可以查看采集的数据
采集的数据
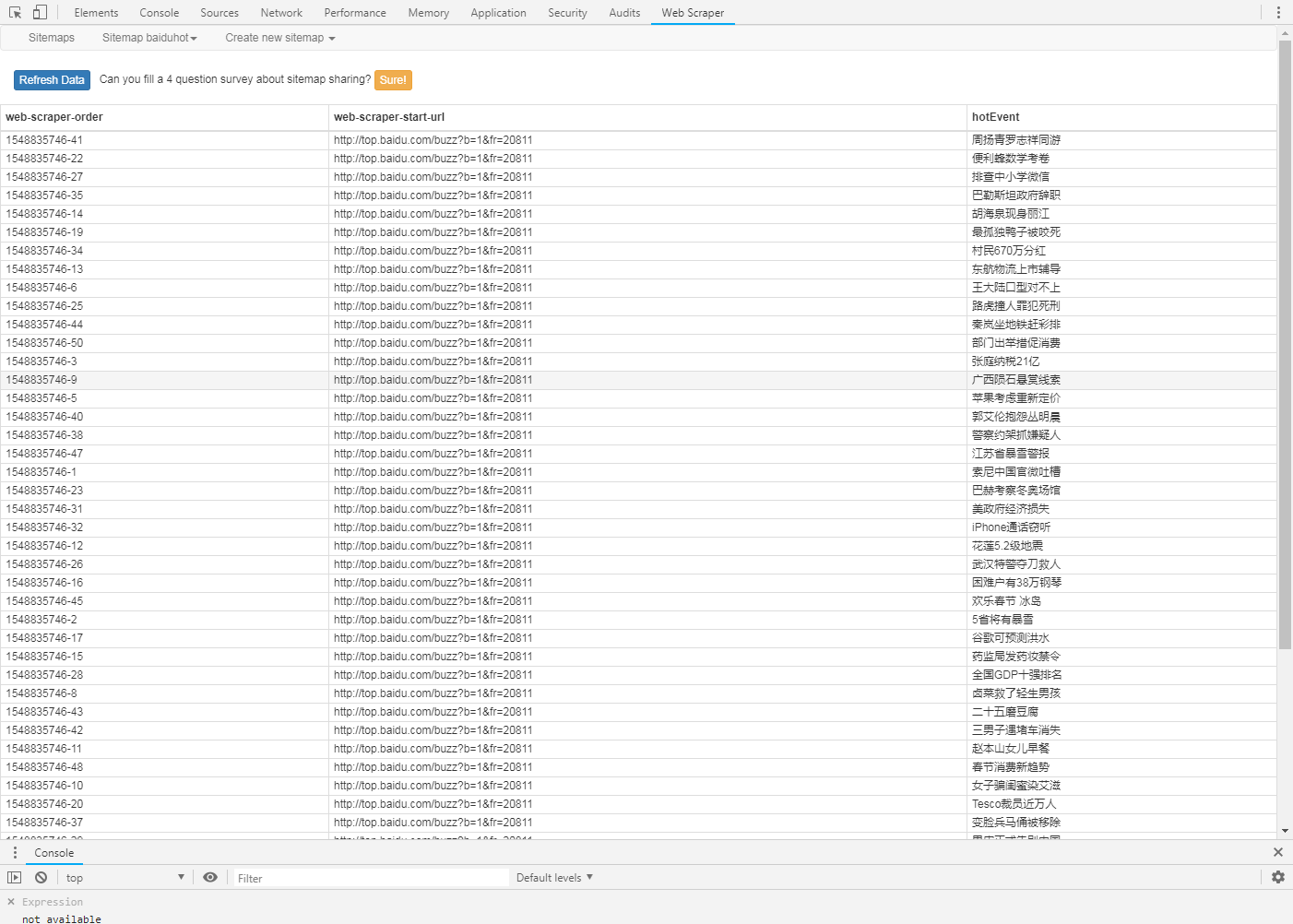
导出数据
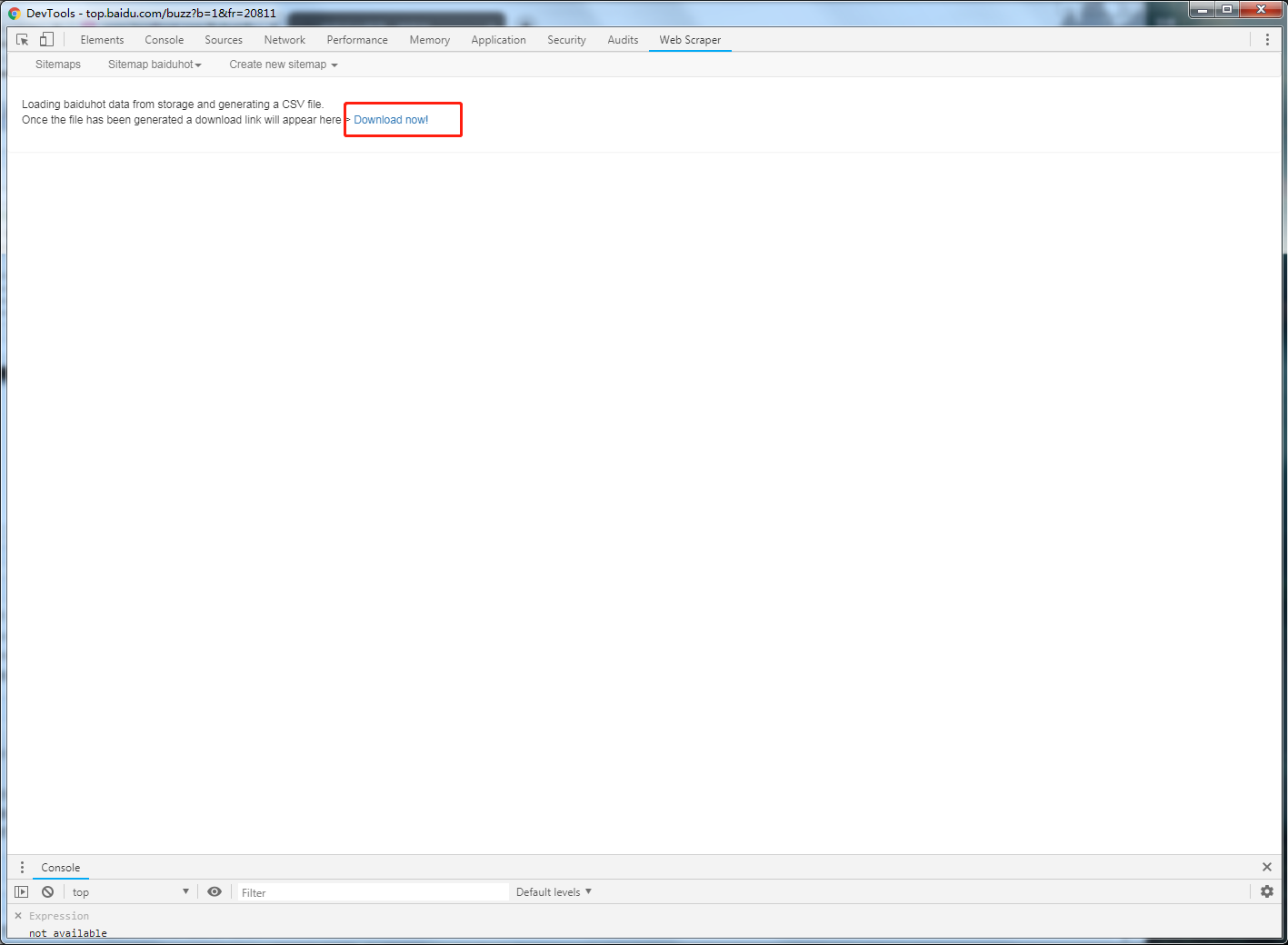
确认数据没有错误,是自己需要的即可,进行下载,以csv格式导出

点击Downolad now!即可下载
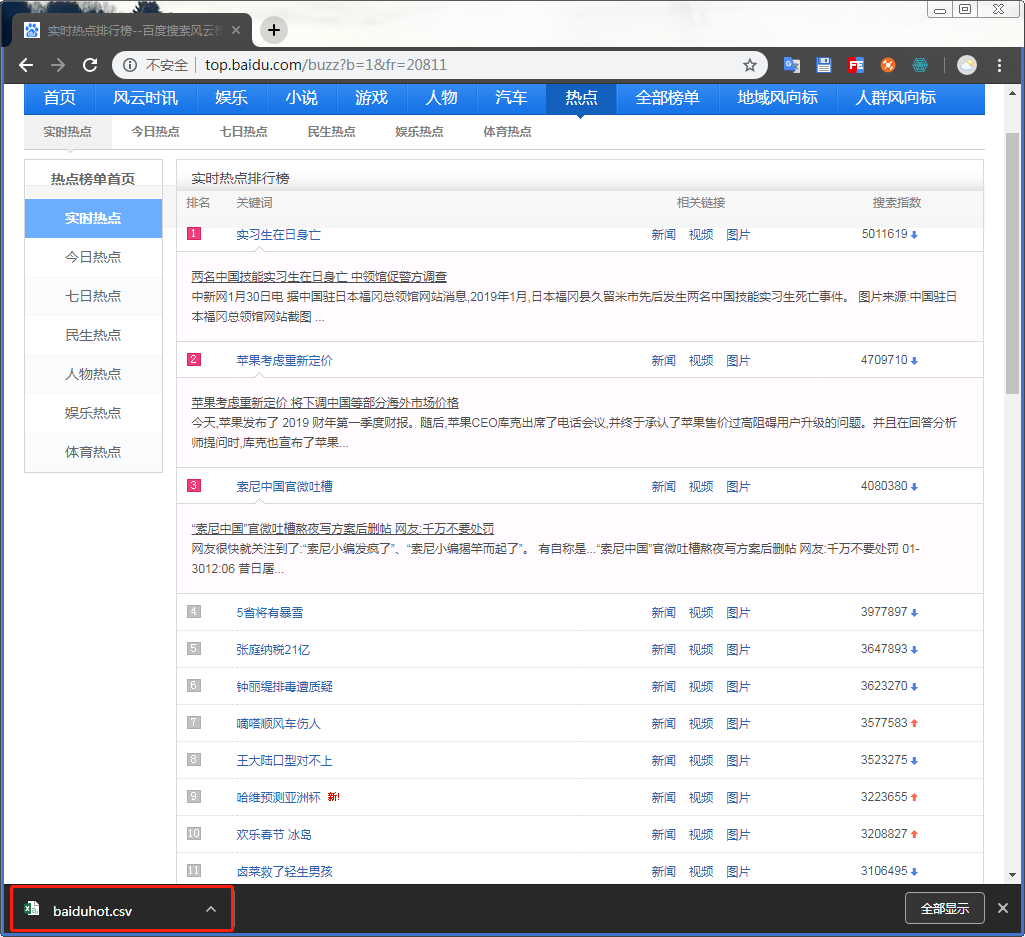
数据内容

到这里使用web scraper进行数据采集就结束了
web scraper——简单的爬取数据【二】的更多相关文章
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- scrapy爬取数据的基本流程及url地址拼接
说明:初学者,整理后方便能及时完善,冗余之处请多提建议,感谢! 了解内容: Scrapy :抓取数据的爬虫框架 异步与非阻塞的区别 异步:指的是整个过程,中间如果是非阻塞的,那就是异步 ...
- Python分页爬取数据的分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 向右奔跑 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 借助Chrome和插件爬取数据
工具 Chrome浏览器 TamperMonkey ReRes Chrome浏览器 chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程 ...
- 使用webmagic爬虫对百度百科进行简单的爬取
分析要爬取的网页源码: 1.打开要分析的网页,查看源代码,找到要爬取的内容: (选择网页里的一部分右击审查元素也行) 2.导入jar包,这个就直接去网上下吧: 3.写爬虫: package com.g ...
随机推荐
- vuex状态管理工具
父子组件之间的通信 props传递 父 向子单向传递:且每次 父组件更新时 子组件的props会跟着更新: 如果需要 子组件把数据传递给父组件,就需要在子组件上绑定自定事件 在子组件使用this ...
- django的配置文件字符串是怎么导入的?
写在开头: 每个APP都会有配置文件,像下代码Django等等这种的settings里面的配置导入都是字符串的,他们是怎么做的呢? MIDDLEWARE = [ 'django.middleware. ...
- 【学习总结】GirlsInAI ML-diary day-6-String字符串
[学习总结]GirlsInAI ML-diary 总 原博github链接-day6 认识字符串 字符串的性质 字符串的玩法 1-字符串就是字符的序列 序列,代表字符串是有顺序的!这里很重要. 比如我 ...
- Linux (Redhat / Fedora / CentOS) 更改 hostname 的方式
Linux (Redhat / Fedora / CentOS) 更改 hostname 的方式 [蔡宗融個人網站]https://www.ichiayi.com/wiki/tech/linux_ho ...
- sqlServer问题记录
1.sql 2008 无法绑定由多个部分绑定的标示符 连接中的多个表中存在同名字段,通过设置别名访问即可 2.远程无法连接到sqlserver 计算机管理->服务与应用程序->SQL Se ...
- Cookie-parser
let express = require('express'); let app =new express(); // 引入cookie-parser; let cookieParser = req ...
- 缓存session,cookie,sessionStorage,localStorage的区别
https://www.cnblogs.com/cencenyue/p/7604651.html(copy) 浅谈session,cookie,sessionStorage,localStorage的 ...
- vue.js实战——vue 实时时间
created:实例创建完成后调用,此阶段完成了数据的观测等,但尚未挂载,$el还不可用,需要初始化处理一些数据时会比较有用. mounted:el挂载到实例上后调用,一般我们的第一个业务逻辑会在这里 ...
- Linux 的相关操作
切换权限 在linux环境下,用户之前的切换使用 “su - name,若要切换到root下面,则使用sudo su 命令即可. 在linux下安装软件,经常就是装完后不知道装到哪里去了 (201 ...
- 如何确定 Hadoop map和reduce的个数--map和reduce数量之间的关系是什么?
1.map和reduce的数量过多会导致什么情况?2.Reduce可以通过什么设置来增加任务个数?3.一个task的map数量由谁来决定?4.一个task的reduce数量由谁来决定? 一般情况下,在 ...