RabbitMQ系列(六)你不知道的RabbitMQ集群架构全解
前言
本文将系统的介绍一下RabbitMQ集群架构的特点、异常处理、搭建和使用中要注意的一些细节。
知识点
一、为什么使用集群?
二、集群的特点
三、集群异常处理
四、集群节点类型
五、集群搭建方法
六、镜像队列
一、为什么使用集群?
内建集群作为RabbitMQ最优秀的功能之一,它的作用有两个:
- 允许消费者和生产者在Rabbit节点崩溃的情况下继续运行;
- 通过增加节点来扩展Rabbit处理更多的消息,承载更多的业务量;
二、集群的特点
RabbitMQ的集群是由多个节点组成的,但我们发现不是每个节点都有所有队列的完全拷贝。
RabbitMQ节点不完全拷贝特性
为什么默认情况下RabbitMQ不将所有队列内容和状态复制到所有节点?
有两个原因:
- 存储空间——如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据。
- 性能——如果消息的发布需安全拷贝到每一个集群节点,那么新增节点对网络和磁盘负载都会有增加,这样违背了建立集群的初衷,新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
所以其他非所有者节点只知道队列的元数据,和指向该队列节点的指针。
三、集群异常处理
根据节点不无安全拷贝的特性,当集群节点崩溃时,该节点队列和关联的绑定就都丢失了,附加在该队列的消费者丢失了其订阅的信息,那么怎么处理这个问题呢?
这个问题要分为两种情况:
- 消息已经进行了持久化,那么当节点恢复,消息也恢复了;
- 消息未持久化,可以使用下文要介绍的双活冗余队列,镜像队列保证消息的可靠性;
四、集群节点类型
节点的存储类型分为两种:
- 磁盘节点
- 内存节点
磁盘节点就是配置信息和元信息存储在磁盘上,内次节点把这些信息存储在内存中,当然内次节点的性能是大大超越磁盘节点的。
单节点系统必须是磁盘节点,否则每次你重启RabbitMQ之后所有的系统配置信息都会丢失。
RabbitMQ要求集群中至少有一个磁盘节点,当节点加入和离开集群时,必须通知磁盘节点。
特殊异常:集群中唯一的磁盘节点崩溃了
如果集群中的唯一一个磁盘节点,结果这个磁盘节点还崩溃了,那会发生什么情况?
如果唯一磁盘的磁盘节点崩溃了,不能进行如下操作:
- 不能创建队列
- 不能创建交换器
- 不能创建绑定
- 不能添加用户
- 不能更改权限
- 不能添加和删除集群几点
总结:如果唯一磁盘的磁盘节点崩溃,集群是可以保持运行的,但你不能更改任何东西。
解决方案:在集群中设置两个磁盘节点,只要一个可以,你就能正常操作。
五、集群搭建方法
本章我们用Docker来创建RabbitMQ集群,一来是因为操作简便,二是因为可以更充分的利用服务器硬件资源,三来是Docker也是现在的主流部署方案,关于更多的Docker详情可以查看我的另一篇:《使用Docker部署RabbitMQ集群)》 接下来,进入我们的正文,集群搭建分为两步:
- 步骤一:安装多个RabbitMQ
- 步骤二:加入RabbitMQ节点到集群
步骤一:安装多个RabbitMQ
docker run -d --hostname rabbit1 --name myrabbit1 -p 15672:15672 -p 5672:5672 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.6.15-managementdocker run -d --hostname rabbit2 --name myrabbit2 -p 5673:5672 --link myrabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.6.15-managementdocker run -d --hostname rabbit3 --name myrabbit3 -p 5674:5672 --link myrabbit1:rabbit1 --link myrabbit2:rabbit2 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.6.15-management
具体的参数含义,参见上文“启动RabbitMQ”部分。
注意点:
- 多个容器之间使用“--link”连接,此属性不能少;
- Erlang Cookie值必须相同,也就是RABBITMQ_ERLANG_COOKIE参数的值必须相同,原因见下文“配置相同Erlang Cookie”部分;
步骤二:加入RabbitMQ节点到集群
设置节点1:
docker exec -it myrabbit1 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exit
设置节点2,加入到集群:
docker exec -it myrabbit2 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit1
rabbitmqctl start_app
exit
参数“--ram”表示设置为内存节点,忽略次参数默认为磁盘节点。
设置节点3,加入到集群:
docker exec -it myrabbit3 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit1
rabbitmqctl start_app
exit
设置好之后,使用http://物理机ip:15672 进行访问了,默认账号密码是guest/guest,效果如下图:
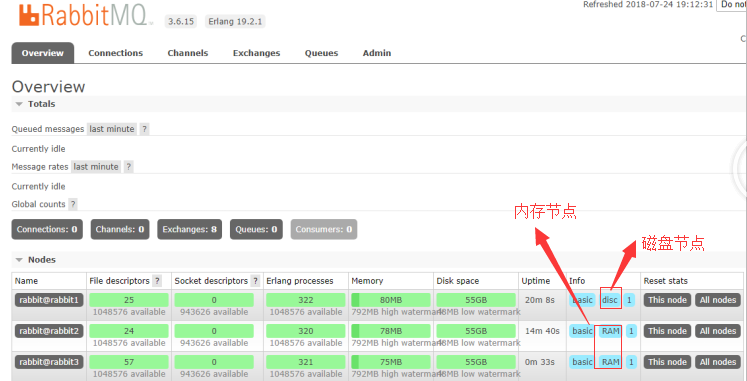
到此为止,我们已经完成了RabbitMQ集群的建立,启动了3个节点,1个磁盘节点和2个内存节点。
设置节点类型
如果你想更换节点类型可以通过命令修改,如下:
rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type dist
rabbitmqctl change_cluster_node_type ram
rabbitmqctl start_app
移除节点
如果想要把节点从集群中移除,可使用如下命令实现:
rabbitmqctl stop_app
rabbitmqctl restart
rabbitmqctl start_app
集群重启顺序
集群重启的顺序是固定的,并且是相反的。如下所述:
- 启动顺序:磁盘节点 => 内存节点
- 关闭顺序:内存节点 => 磁盘节点
最后关闭必须是磁盘节点,不然可能回造成集群启动失败、数据丢失等异常情况。
六、镜像队列
镜像队列是Rabbit2.6.0版本带来的一个新功能,允许内建双活冗余选项,与普通队列不同,镜像节点在集群中的其他节点拥有从队列拷贝,一旦主节点不可用,最老的从队列将被选举为新的主队列。
镜像队列的工作原理:在某种程度上你可以将镜像队列视为,拥有一个隐藏的fanout交换器,它指示者信道将消息分发到从队列上。
设置镜像队列
设置镜像队列命令:“rabbitmqctl set_policy 名称 匹配模式(正则) 镜像定义”, 例如,设置名称为mypolicy的镜像队列,匹配所有名称是amp开头的队列都存储在2个节点上的命令如下:
rabbitmqctl set_policy mypolicy "^amp*" '{"ha-mode":"exactly","ha-params":2}'
可以看出设置镜像队列,一共有三个参数,每个参数用空格分割。
- 参数一:名称,可以随便填;
- 参数二:队列名称的匹配规则,使用正则表达式表示;
- 参数三:为镜像队列的主体规则,是json字符串,分为三个属性:ha-mode | ha-params | ha-sync-mode,分别的解释如下:
- ha-mode:镜像模式,分类:all/exactly/nodes,all存储在所有节点;exactly存储x个节点,节点的个数由ha-params指定;nodes指定存储的节点上名称,通过ha-params指定;
- ha-params:作为参数,为ha-mode的补充;
- ha-sync-mode:镜像消息同步方式:automatic(自动),manually(手动);
设置好镜像队列存储2个节点的效果如下图:
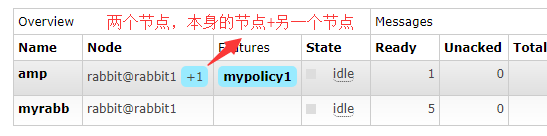
查看镜像队列
rabbitmqctl list_policies
删除镜像队列
rabbitmqctl clear_policy
参考资料
书籍:《RabbitMQ实战-高效部署分布式消息队列》——不建议程序猿购买,偏运维
https://www.cnblogs.com/luo-mao/p/5909889.html
https://www.jianshu.com/p/85543491ab00
RabbitMQ系列(六)你不知道的RabbitMQ集群架构全解的更多相关文章
- RabbitMQ系列之高可用集群
为了实现高可用,我采用LVS+双节点RabbitMq , 架构图如下: 在RabbitMQ之前放了LVS, LVS 采用 rr 轮询算法 , 目的是将请求平均分配到两个真实节点,并配置5672端口监控 ...
- rabbitmq系统学习(三)集群架构
RabbitMQ集群架构模式 主备模式 实现RabbitMQ的高可用集群,一般在并发和数据量不高的情况下,这种模型非常的好用且简单.主备模式也称为Warren模式 HaProxy配置 listen r ...
- 关于RabbitMQ分布式集群架构
RabbitMQ分布式集群架构和高可用性(HA) (一) 功能和原理 设计集群的目的 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行 通过增加更多的节点来扩展消息通信的吞吐量 1 集群配 ...
- 集群架构和CentOS7安装RabbitMQ集群(单机版)
1. 集群架构 1.1 四种内部元数据 队列元数据.交换器元数据.绑定元数据.vhost元数据. 单一节点中:会将数据存储到内存,同时将持久化元数据保存到硬盘. 集群中: 存储到磁盘上.内存中. 集群 ...
- RabbitMQ集群架构(HA)并结合.NET Core实操
一.前言 已经一年没有更新博客了,由于公司事务比较多,并且楼主我也积极在公司项目中不断实践.net core.DDD以及Abp vnext,也积累了一些吐血经验,目前我在做一家在线教育公司负责智慧校园 ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- RabbitMQ(四):使用Docker构建RabbitMQ高可用负载均衡集群
本文使用Docker搭建RabbitMQ集群,然后使用HAProxy做负载均衡,最后使用KeepAlived实现集群高可用,从而搭建起来一个完成了RabbitMQ高可用负载均衡集群.受限于自身条件,本 ...
- spring cloud系列教程第六篇-Eureka集群版
spring cloud系列教程第六篇-Eureka集群版 本文主要内容: 本文来源:本文由凯哥Java(kaigejava)发布在博客园博客的.转载请注明 1:Eureka执行步骤理解 2:集群原理 ...
- Docker 也是本地开发的一神器:部署单机版 Pulsar 和集群架构 Redis
原文链接:Docker 也是本地开发的一神器:部署单机版 Pulsar 和集群架构 Redis 一.前言: 现在互联网的技术架构中,不断出现各种各样的中间件,例如 MQ.Redis.Zookeeper ...
随机推荐
- vuex创建store并用computed获取数据
vuex中的store是一个状态管理器,用于分发数据.相当于父组件数据传递给子组件. 1.安装vuex npm i vuex --save 2.在src目录中创建store文件夹,里面创建store. ...
- python模块:csv
""" csv.py - read/write/investigate CSV files """ import re from _csv ...
- shell awk处理过滤100万条数据
背景: 100万条数据.格式如下: ID 地址 1895756546931805 安徽省六安市裕安区固镇镇佛俺村柳树队5758 安徽省蒙城县岳坊镇胡寨村小组小胡寨庄6号 183494167409969 ...
- appium+python自动化脚本
用pycharm,首先得把appium导入,操作如下(否则,运行程序后会报错,没有module appium) Settings->Project Interpreter,双击pip,搜索app ...
- Android中RecyclerView出现java.lang.IndexOutOfBoundsException
在RecyclerView更细数据时出现java.lang.IndexOutOfBoundsException: Inconsistency detected. Invalid view holder ...
- 53_并发编程-线程-GIL锁
一.GIL - 全局解释器锁 有了GIL的存在,同一时刻同一进程中只有一个线程被执行:由于线程不能使用cpu多核,可以开多个进程实现线程的并发,因为每个进程都会含有一个线程,每个进程都有自己的GI ...
- 一篇入门 -- Scala 反射
本篇文章主要让大家理解什么是Scala的反射, 以及反射的分类, 反射的一些术语概念和一些简单的反射例子. 什么是反射 我们知道, Scala是基于JVM的语言, Scala编译器会将Scala代码编 ...
- EmpireCMS_V7.5的一次审计
i春秋作家:Qclover 原文来自:EmpireCMS_V7.5的一次审计 EmpireCMS_V7.5的一次审计 1概述 最近在做审计和WAF规则的编写,在CNVD和CNNVD等漏洞平台寻找 ...
- Java线程小刀牛试
线程简介 什么是线程 现代操作系统调度的最小单元是线程,也叫轻量级进程(Light Weight Process),在一个进程里可以创建多个线程,这些线程都拥有各自的计数器.堆栈和局部变量等属性,并且 ...
- 关于Python打开IDLE出现错误的解决办法
安装好python,打开IDLE出现以下错误: 解决办法: 修改[Python目录]\Lib\idlelib\PyShell.py文件,在1300行附近,将def main():函数下面use_sub ...