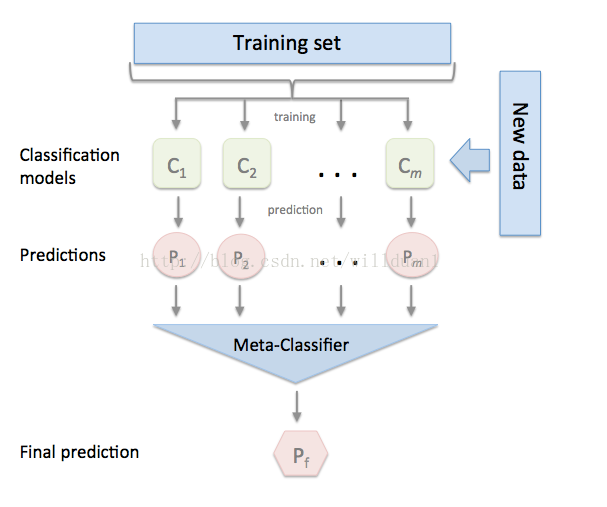
Dream team: Stacking for combining classifiers梦之队:组合分类器
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

https://www.cnblogs.com/zhizhan/p/5051881.html转载
stacked 产生方法是一种截然不同的组合多个模型的方法,它讲的是组合学习器的概念,但是使用的相对于bagging和boosting较少,它不像bagging和boosting,而是组合不同的模型,具体的过程如下:
1.划分训练数据集为两个不相交的集合。
2. 在第一个集合上训练多个学习器。
3. 在第二个集合上测试这几个学习器
4. 把第三步得到的预测结果作为输入,把正确的回应作为输出,训练一个高层学习器,
这里需要注意的是1-3步的效果与cross-validation,我们不是用赢家通吃,而是使用非线性组合学习器的方法
将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
下面我们介绍一款功能强大的stacking利器,mlxtend库,它可以很快地完成对sklearn模型地stacking。
混合技术达到0.9825准确性,标准差0.0123,非常低

from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_breast_cancer
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics cancer=load_breast_cancer()
X, y = cancer.data,cancer.target train_x, test_x, train_y, test_y=train_test_split(X,y,test_size=0.3,random_state=0)
parameters= [{'learning_rate':[0.01,0.1,0.3],
'n_estimators':[1000,1200,1500,2000,2500],
'max_depth':range(1,10,1),
'gamma':[0.01,0.1,0.3,0.5],
'eta': [0.025,0.1,0.2,0.3]}] clf = GridSearchCV(XGBClassifier(
min_child_weight=1,
subsample=0.6,
colsample_bytree=0.6,
objective= 'binary:logistic', #逻辑回归损失函数
scale_pos_weight=1,
reg_alpha=0,
reg_lambda=1,
seed=27
),
param_grid=parameters,scoring='roc_auc') clf.fit(train_x,train_y) y_pred=clf.predict(test_x) print("accuracy on the training subset:{:.3f}".format(clf.score(train_x,train_y)))
print("accuracy on the test subset:{:.3f}".format(clf.score(test_x,test_y))) print(clf.best_params_)
y_pre= clf.predict(test_x)
y_pro= clf.predict_proba(test_x)[:,1]
print ("AUC Score : %f" % metrics.roc_auc_score(test_y, y_pro))
print("Accuracy : %.4g" % metrics.accuracy_score(test_y, y_pre)) '''
accuracy on the training subset:1.000
accuracy on the test subset:0.998
{'gamma': 0.5, 'learning_rate': 0.01, 'max_depth': 2, 'n_estimators': 1000}
AUC Score : 0.998089
Accuracy : 0.9708
''' best_xgb=XGBClassifier(min_child_weight=1,
subsample=0.6,
colsample_bytree=0.6,
objective= 'binary:logistic', #逻辑回归损失函数
scale_pos_weight=1,
reg_alpha=0,
reg_lambda=1,
seed=27,gamma=0.5,learning_rate=0.01,max_depth=2,n_estimators=1000) best_xgb.fit(train_x,train_y) print("accuracy on the training subset:{:.3f}".format(best_xgb.score(train_x,train_y)))
print("accuracy on the test subset:{:.3f}".format(best_xgb.score(test_x,test_y))) '''
accuracy on the training subset:0.995
accuracy on the test subset:0.979
'''
主要有以下几种使用方法吧:
I. 最基本的使用方法,即使用前面分类器产生的特征输出作为最后总的meta-classifier的输入数据
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr) print('3-fold cross validation:\n') for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']): scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
II. 另一种使用第一层基本分类器产生的类别概率值作为meta-classfier的输入,这种情况下需要将StackingClassifier的参数设置为 use_probas=True。如果将参数设置为 average_probas=True,那么这些基分类器对每一个类别产生的概率值会被平均,否则会拼接。
例如有两个基分类器产生的概率输出为:
classifier 1: [0.2, 0.5, 0.3]
classifier 2: [0.3, 0.4, 0.4]
1) average = True :
产生的meta-feature 为:[0.25, 0.45, 0.35]
2) average = False:
产生的meta-feature为:[0.2, 0.5, 0.3, 0.3, 0.4, 0.4]
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas=False,
meta_classifier=lr) print('3-fold cross validation:\n') for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']): scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
III. 另外一种方法是对训练基中的特征维度进行操作的,这次不是给每一个基分类器全部的特征,而是给不同的基分类器分不同的特征,即比如基分类器1训练前半部分特征,基分类器2训练后半部分特征(可以通过sklearn 的pipelines 实现)。最终通过StackingClassifier组合起来。
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression iris = load_iris()
X = iris.data
y = iris.target pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
LogisticRegression()) sclf = StackingClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression()) sclf.fit(X, y)
StackingClassifier 使用API及参数解析:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
参数:
classifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
meta_classifier : 目标分类器,即将前面分类器合起来的分类器
use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
average_probas : bool (default: False),用来设置上一个参数当使用概率值输出的时候是否使用平均值。
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
属性:
clfs_ : 每个基分类器的属性,list, shape 为 [n_classifiers]。
meta_clf_ : 最终目标分类器的属性
方法:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的GridSearch方法,那么返回分类器的各项参数。
predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracy
set_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样
一套弱系统能变成一个强系统吗?
当你处在一个复杂的分类问题面前时,金融市场通常会出现这种情况,在搜索解决方案时可能会出现不同的方法。 虽然这些方法可以估计分类,但有时候它们都不比其他分类好。 在这种情况下,合理的选择是将它们全部保留下来,然后通过整合这些部分来创建最终系统。 这种多样化的方法是最方便的做法之一:在几个系统之间划分决定,以避免把所有的鸡蛋放在一个篮子里。
一旦我对这种情况有了大量的估计,我怎样才能将N个子系统的决策结合起来? 作为一个快速的答案,我可以做出平均决定并使用它。 但是,是否有不同的方式充分利用我的子系统? 当然有!
Can a set of weak systems turn into a single strong system?
When you’re in front of a complex classification problem, as is often the case with financial markets, different approaches may appear while searching for a solution. Although these approaches can estimate the classification, sometimes none of them are better than the rest. In this case, a reasonable choice is to keep them all, and then create a final system by integrating the pieces. This method of diversification is one of the most convenient practices: divide the decision among several systems in order to avoid putting all your eggs in one basket.
Once I have a number of estimates for the one case, how can I combine the decisions of the N sub-systems? As a quick answer, I can take the decision average and use this. But are there different ways of making the most out of my sub-systems? Of course there are!
Think outside the box!
Several classifiers with a common objective are called multiclassifiers. In Machine Learning, multiclassifiers are sets of different classifiers which make estimates and are fused together, obtaining a result that is a combination of them. Lots of terms are used to refer to multiclassifiers: multi-models, multiple classifier systems, combining classifiers, decision committee, etc. They can be divided into two main groups:
- Ensemble methods: Refers to sets of systems that combine to create a new system using the same learning technique. Bagging and Boosting are the most extended ones.
- Hybrid methods: Takes a set of different learners and combines them using new learning techniques. Stacking (or Stacked Generalization) is one of the main hybrid multiclassifiers.
创造性思考!
几个具有共同目标的分类器称为多分类器。 在机器学习中,多分类器是一组不同的分类器,它们进行估算并融合在一起,得到一个结合它们的结果。 许多术语用于指多分类器:多模型,多分类器系统,组合分类器,决策委员会等。它们可以分为两大类:
集成方法:指使用相同的学习技术组合成一组系统来创建新系统。 套袋和提升是最延伸的。
混合方法:采用一组不同的学习者并使用新的学习技术进行组合。 堆叠(或堆叠泛化)是主要的混合多分类器之一。
How to build a multiclassifier motivated by Stacking.
Imagine that I would like to estimate the EURUSD’s trends(欧元兑美元趋势). First of all, I turn my issue into a classification problem, so I split the price data into two types (or classes): up and down movements. Guessing every daily movement is not my intention. I only want to detect the main trends: up for trading Long (class = 1) and down for trading Short (class = 0).

I have done this split a posteriori; by which I mean that all historical data have been used to decide the classes, so it takes into account some future information. Therefore, I’m not able to assure iup or down movement at the current moment. For this reason an estimate for the today’s class is required.
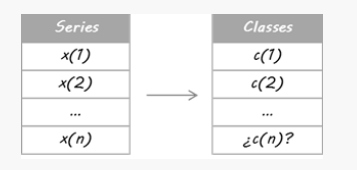
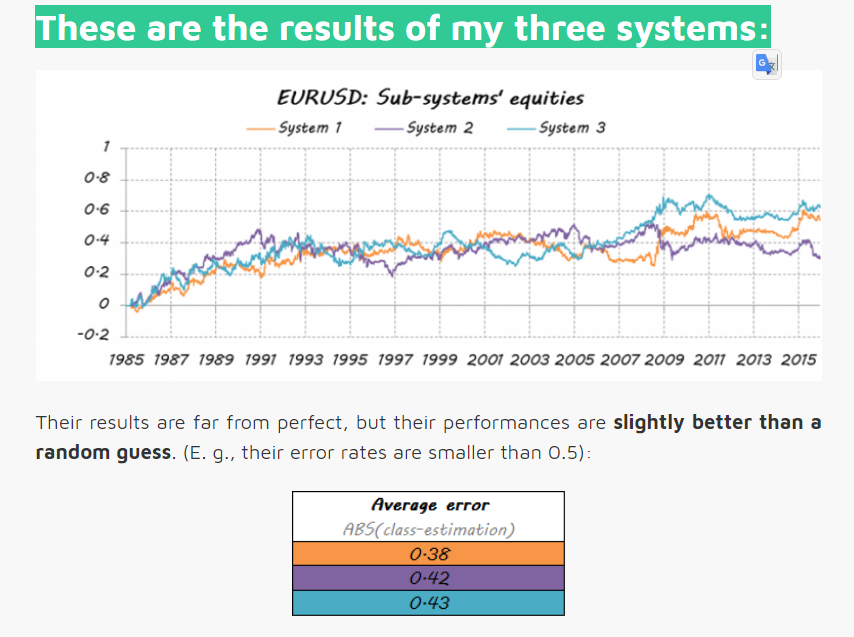
For the purpose of this example I have designed three independent systems. They are three different learners using separate sets of attributes. It does not matter if you use the same learner algorithm or if they share some/all attributes; the key is that they must be different enough in order to guarantee diversification.

Then, they trade based on those probabilities: If E is above 50%, it means Long entry, more the bigger E is. If E is under 50%, it is Short entry, more the smaller E is.
These are the results of my three systems:

一组穷人可以组成梦之队吗?
构建多分类器的目的是获得比任何单个分类器都能获得的更好的预测性能。让我们看看是否是这种情况。
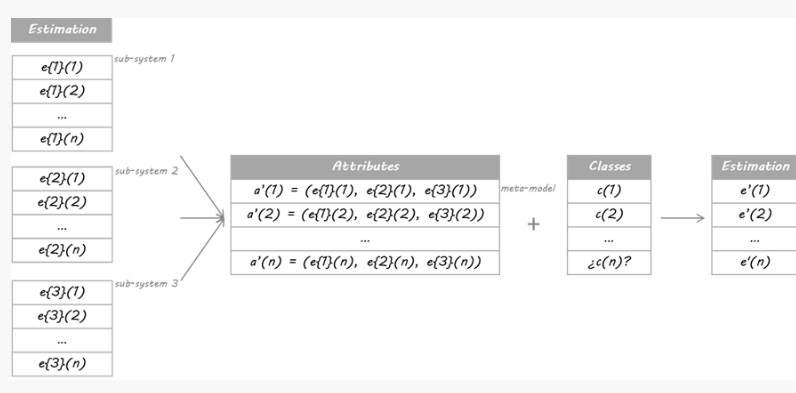
我将在本例中使用的方法基于Stacking算法。 Stacking的思想是,称为级别0模型的主分类器的输出将被用作称为元模型的另一分类器的属性以近似相同的分类问题。元模型留下来找出合并机制。它将负责连接0级模型的回复和真实分类。
严格的过程包括将训练集分成不相交的集合。然后训练每个级别0的学习者关于整个数据,排除一组,并将其应用于排除组。通过对每组重复,为每个学习者获得每个数据的估计。这些估计值将成为训练元模型或1级模型的属性。由于我的数据是一个时间序列,因此我决定使用第1天到第d-1天的集合来构建第d天的估计。
Can a set of poor players make up a dream team?
The purpose of building a multiclassifier is to obtain better predictive performance than what could be obtained from any single classifier. Let’s see if this is the case.
The method I am going to use in this example is based on the Stacking algorithm. The idea of Stacking is that the output of primary classifiers, called level 0 models, will be used as attributes for another classifier, called meta-model, to approximate the same classification problem. The meta-model is left to figure out the combining mechanism. It will be in charge of connecting the level 0 models’ replies and the real classification.
The rigorous process consists in splitting the training set into disjoint sets. Then train each level 0 learner on the whole data, excluding one set, and apply it over the excluded set. By repeating for each set, an estimate for each data is obtained for each learner. These estimates will be the attributes for training the meta-model or level 1 model. As my data was a time series, I decided to build the estimation for day d just using the set from day 1 to day d-1.
这与哪种模式配合使用?
元模型可以是分类树,随机森林,支持向量机......任何分类学习者都是有效的。 对于这个例子,我选择了使用最近邻居算法。 这意味着元模型将估计新数据的类别,以发现过去数据中0级分类的类似配置,然后将分配这些类似情况的类别。
让我们看看我的梦之队的成绩是多么的好......
Which model does this work with?
The meta-model can be a classification tree, a random forest, a support vector machine… Any classification learner is valid. For this example I chose to use a nearest neighbours algorithm. It means that the meta-model will estimate the class of the new data finding similar configurations of the level 0 classifications in past data, and then will assign the class of these similar situations.
Let’s see how good my dream team result is…

Conclusion
This is just one example of the huge amount of available multiclassifiers. They can help you not only to join your partial solutions into a unique answer by means of a modern and original technique, but to create a real dream team. There’s also an important margin for improvement in the way that the individual pieces are integrated into a single system.
So, next time you need to combine, spend more than a moment working on the possibilities. Avoid the traditional average by force of habit and explore more complex methods. They may surprise you with extra performance.
结论
这只是大量可用多分类器的一个例子。 他们不仅可以帮助您通过现代和独创的技术将您的部分解决方案融入到独特的答案中,而且可以创建一个真正的梦幻团队。 单个组件被集成到一个系统中的方式也有一个重要的改进余地。
所以,下次你需要结合时,花更多的时间来研究可能性。 通过习惯的力量避免传统的平均水平,并探索更复杂的方法。 他们可能会为你带来额外的表现
数据比赛大杀器----模型融合(stacking&blending)
英文版本
http://mlwave.com/kaggle-ensembling-guide/
这里写链接内容
这个是上面英文翻译过来的汉语翻译版本
kaggle比赛集成指南
http://m.blog.csdn.net/article/details?id=53054686
搜狗比赛第五名的stacking思路
http://prozhuchen.com/2016/12/28/CCF%E5%A4%A7%E8%B5%9B%E6%90%9C%E7%8B%97%E7%94%A8%E6%88%B7%E7%94%BB%E5%83%8F%E6%80%BB%E7%BB%93/
kaggle官方博客 stacking融合
http://blog.kaggle.com/2016/12/27/a-kagglers-guide-to-model-stacking-in-practice/
汉语版翻译如下
Kaggler的“实践中模型堆叠指南”

介绍
堆叠(也称为元组合)是用于组合来自多个预测模型的信息以生成新模型的模型组合技术。通常,堆叠模型(也称为二级模型)因为它的平滑性和突出每个基本模型在其中执行得最好的能力,并且抹黑其执行不佳的每个基本模型,所以将优于每个单个模型。因此,当基本模型显著不同时,堆叠是最有效的。关于在实践中怎样的堆叠是最常用的,这里我提供一个简单的例子和指导。
本教程最初发布在Ben的博客GormAnalysis上。
https://github.com/ben519/MLPB/tree/master/Problems/Classify%20Dart%20Throwers
请随意借鉴本文中使用的来自机器学习问题参考书的相关代码和数据集。
另外的python 版本的blending
https://github.com/emanuele/kaggle_pbr
动机
假设有四个人在板子上投了187个飞镖。对于其中的150个飞镖,我们可以看到每个是谁投掷的以及飞镖落在了哪。而其余的,我们只能看到飞镖落在了哪里。我们的任务就基于它们的着陆点来猜测谁投掷的每个未标记的飞镖。
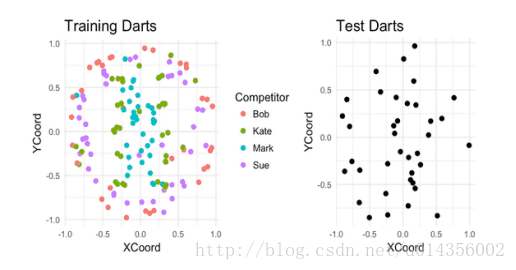
K最近邻(基本模型1)
让我们使用K最近邻模型来尝试解决这个分类问题。为了选择K的最佳值,我们将使用5重交叉验证结合网格搜索,其中K =(1,2,… 30)。在伪代码中:
1.将训练数据分成五个大小相等的数据集。调用这些交叉测试。
2.对于K = 1,2,… 10
1.对于每个交叉测试
1.组合其他四个交叉用作训练交叉
2.在训练交叉上使用K最近邻模型(使用K的当前值)
3.对交叉测试进行预测,并测量所得预测的准确率
2.从五个交叉测试预测中计算平均准确率
3.保持K值具有最好的平均CV准确率
使用我们的虚构数据,我们发现K = 1具有最佳的CV性能(67%的准确性)。使用K = 1,我们现在训练整个训练数据集的模型,并对测试数据集进行预测。 最终,这将给我们约70%的分类精度。
支持向量机(基本型2)
现在让我们再次使用支持向量机解决这个问题。此外,我们将添加一个DistFromCenter功能,用于测量每个点距板中心的距离,以帮助使数据线性可分。 使用R的LiblineaR包,我们得到两个超参数来调优:
类型
1.L2-正则化L2丢失支持向量分类(双重)
2.L2正则化L2丢失支持向量分类(原始)
3.L2-正则化L1损失支持向量分类(双重)
4.Crammer和Singer的支持向量分类
5.L1正则化L2丢失支持向量分类
成本
正则化常数的倒数
我们将测试的参数组合网格是5个列出的SVM类型的笛卡尔乘积,成本值为(.01,.1,10,100,1000,2000)。 那是
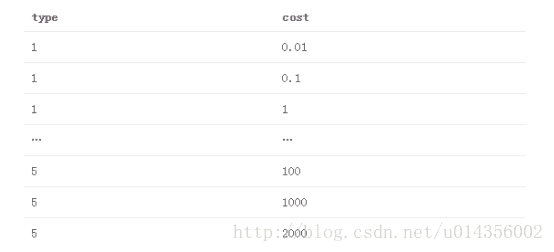
使用与我们的K最近邻模型相同的CV +网格搜索方法,这里我们找到最好的超参数为type = 4,cost = 1000。再次,我们使用这些参数训练的模型,并对测试数据集进行预测。这将在测试数据集上给我们约61%的CV分类精度和78%的分类准确性。
堆叠(元组合)
让我们来看看每个模型分为Bob,Sue,Mark或Kate的板区域。
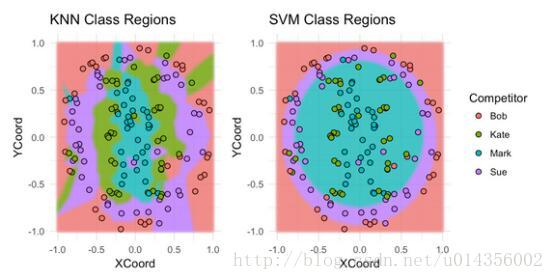
不出所料,SVM在分类Bob的投掷和Sue的投掷方面做得很好,但是在分类Kate的投掷和Mark的投掷方面做得不好。对于最近邻模型,情况正好相反。 提示:堆叠这些模型可能会卓有成效。
一共有几个思考如何实现堆叠的派别。在我们的示例问题中我是根据自己的喜好来应用的:
1.将训练数据分成五个交叉测试
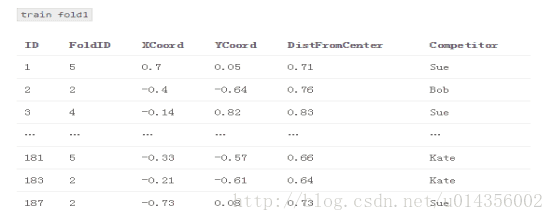
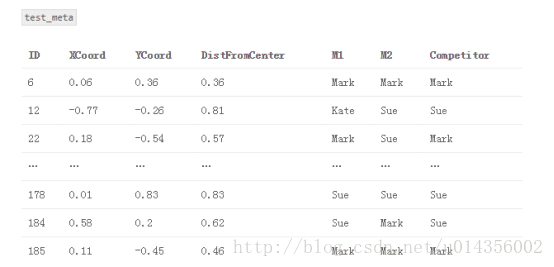
2.创建一个名为“train_meta”的数据集,其具有与训练数据集相同的行ID和交叉ID、空列M1和M2。 类似地,创建一个名为“test_meta”的数据集,其具有与测试数据集相同的行ID、空列M1和M2
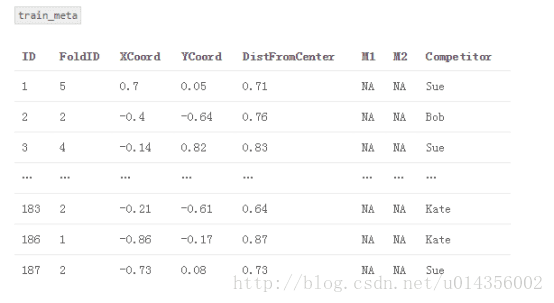
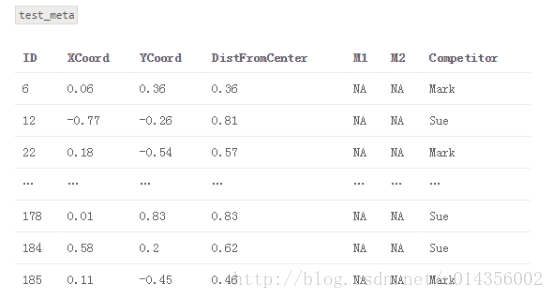
3.对于每个交叉测试
{Fold1,Fold2,… Fold5}
3.1组合其他四个交叉用作训练交叉
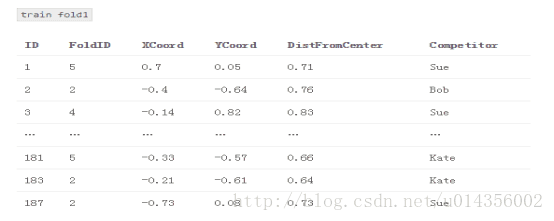
3.2对于每个基本模型
M1:K-最近邻(k = 1)
M2:支持向量机(type = 4,cost = 1000)
3.2.1将基本模型交叉训练,并在交叉测试进行预测。 将这些预测存储在train_meta中以用作堆叠模型的特征
train_meta与M1和M2填补fold1
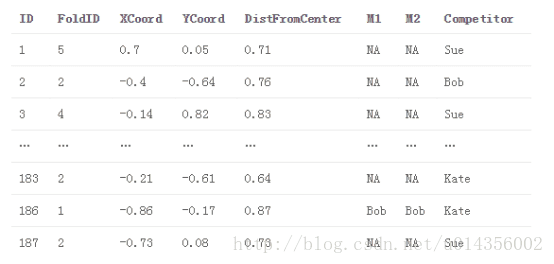
4.将每个基本模型拟合到完整训练数据集,并对测试数据集进行预测。 将这些预测存储在test_meta内
5.使用M1和M2作为特征,将新模型S(即,堆叠模型)适配到train_meta,可选地,包括来自原始训练数据集或特征工程的其他特征。
S:逻辑回归(来自LiblineaR包,类型= 6,成本= 100)。 适配train_meta
6.使用堆叠模型S对test_meta进行最终预测
test_meta与堆叠模型预测
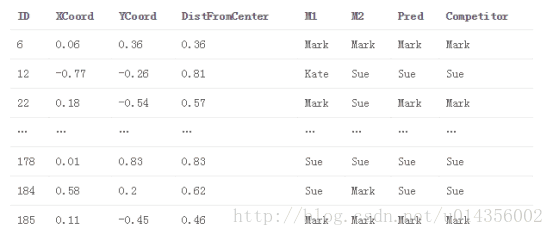
主要观点是,我们使用基础模型的预测作为堆叠模型的特征(即元特征)。 因此,堆叠模型能够辨别哪个模型表现良好,哪个模型表现不佳。还要注意的是,train_meta的行i中的元特征不依赖于行i中的目标值,因为它们是在使用基本模型拟合过程中排除target_i的信息中产生的。
或者,我们可以在测试数据集适合每个交叉测试之后立即使用每个基本模型进行预测。 在我们的例子中,这将产生五个K-最近邻模型和五个SVM模型的测试集预测。然后,我们将平均每个模型的预测以生成我们的M1和M2元特征。 这样做的一个好处是,它比第一种方法耗时少(因为我们不必在整个训练数据集上重新训练每个模型)。 它也有助于我们的训练元特征和测试元特征遵循类似的分布。然而,测试元M1和M2在第一种方法中可能更准确,因为每个基础模型在全训练数据集上训练(相对于训练数据集的80%,在第二方法中为5次)。
堆栈模型超参数调优
那么,如何调整堆叠模型的超参数? 关于基本模型,就像我们以前做的,我们可以使用交叉验证+网格搜索调整他们的超参数。 我们使用什么交叉并不重要,但使用我们用于堆叠的相同交叉通常很方便。调整堆叠模型的超参数是让事情变得有趣的地方。在实践中,大多数人(包括我自己)只需使用交叉验证+网格搜索,使用相同的精确CV交叉用于生成元特征。 这种方法有一个微妙的缺陷 - 你能找到它吗?
事实上,在我们的堆叠CV过程中有一点点数据泄漏。 想想堆叠模型的第一轮交叉验证。我们将模型S拟合为{fold2,fold3,fold4,fold5},对fold1进行预测并评估效果。但是{fold2,fold3,fold4,fold5}中的元功能取决于fold1中的目标值。因此,我们试图预测的目标值本身就嵌入到我们用来拟合我们模型的特征中。这是泄漏,在理论上S可以从元特征推导出关于目标值的信息,其方式将使其过拟合训练数据,而不能很好地推广到袋外样本。 然而,你必须努力工作来想出一个这种泄漏足够大、导致堆叠模型过度拟合的例子。 在实践中,每个人都忽略了这个理论上的漏洞(坦白地说,我认为大多数人不知道它甚至存在!)
堆叠模型选择和特性
你如何知道选择何种型号作为堆叠器以及元特征要包括哪些功能? 在我看来,这更像是一门艺术而不是一门科学。 你最好的办法是尝试不同的东西,熟悉什么是有效的,什么不是。另一个问题是,除了元特征,你应该为堆叠模型包括什么其他功能(如果有)?这也是一种艺术。看看我们的例子,很明显,DistFromCenter在确定哪个模型将会很好地发挥作用。KNN似乎在分类投掷于中心附近的飞镖上做得更好,SVM模型在分类远离中心的飞镖上表现得更好。 让我们来看看使用逻辑回归来堆叠我们的模型。 我们将使用基本模型预测作为元特征,并使用DistFromCenter作为附加功能。
果然,堆叠模型的性能优于两种基本模型 - 75%CV精度和86%测试精度。 就像我们对基本模型一样,现在让我们来看看它的覆盖训练数据的分类区域。
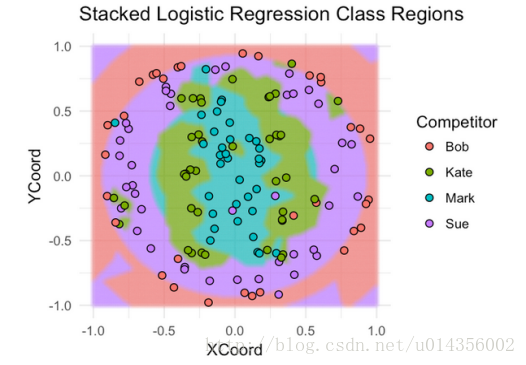
这里的好处是,逻辑回归堆叠模型捕获每个基本模型的最好的方面,这就是为什么它的执行优于任何孤立的基本模型。
实践中的堆叠
为了包装,让我们来谈谈如何、何时、以及为什么在现实世界中使用堆叠。 就个人而言,我大多在Kaggle的机器学习竞赛中使用堆叠。一般来说,堆叠产生小的收益与大量增加的复杂性不值得为大多数企业使用。 但堆叠几乎总是富有成果,所以它几乎总是用于顶部Kaggle解决方案。 事实上,当你有一队人试图在一个模型上合作时,堆叠对Kaggle真的很有效。采用一组单独的交叉,然后每个团队成员使用那些交叉建立他们自己的模型。 然后每个模型可以使用单个堆叠脚本组合。这是极好的,因为它防止团队成员踩在彼此的脚趾,尴尬地试图将他们的想法拼接到相同的代码库。
最后一位。 假设我们有具有(用户,产品)对的数据集,并且我们想要预测用户在购买给定产品的情况下,他/她与该产品一起展示广告的几率。一个有效的功能可能是,使用培训数据,有多少百分比的产品广告给用户,而他实际上在过去就已经购买?因此,对于训练数据中的样本(user1,productA),我们要解决一个像UserPurchasePercentage这样的功能,但是我们必须小心,不要在数据中引入泄漏。 我们按照接下来这样做:
1.将训练数据拆分成交叉
2.对于每个交叉测试
1.标识交叉测试中的唯一一组用户
2.使用剩余的交叉计算UserPurchasePercentage(每个用户购买的广告产品的百分比)
3.通过(fold id,用户id)将UserPurchasePercentage映射回培训数据
现在我们可以使用UserPurchasePercentage作为我们的梯度提升模型(或任何我们想要的模型)的一个特性。我们刚刚做的是有效地建立一个预测模型,基于user_i在过去购买的广告产品的百分比,预测他将购买product_x的概率,并使用这些预测作为我们的真实模型的元特征。这是一个微妙而有效并且我经常在实践和Kaggle实现的有效的堆叠形式 -
python风控评分卡建模和风控常识

微信扫二维码,免费学习更多python资源

Dream team: Stacking for combining classifiers梦之队:组合分类器的更多相关文章
- dnc开源梦之队2018 开源项目精选集
dnc开源梦之队2018 dnc开源项目选择标准 dnc = .NET Core.dotnet core 1.支持dnc 2.x,Github star数量100以上,最近2月活跃更新 2.轻量级.示 ...
- Final互评------《I do》---- 二次元梦之队
一.基于NABCD评论作品,及改进建议 1.根据(不限于)NABCD评论作品的选题; N(Need,需求):该产品是一款休闲类的解密游戏,背景是编程知识.作为一款休闲游戏,有着基本的娱乐功能,可以给用 ...
- 互评Final版本——二次元梦之队——“I Do”
基于NABCD评论作品,及改进建议 1.根据(不限于)NABCD评论作品的选题; (1)N(Need,需求) 当今的许多科技大佬从少年时代就已经开始了自己的编程生涯,我国许多人也意识到了拥有编程能力的 ...
- 互评Beta版本——二次元梦之队——“I Do”
基于NABCD评论作品,及改进建议 1.根据(不限于)NABCD评论作品的选题 (1)N(Need,需求) 这是一款可以教学新手入门编程的软件,不断的通关让他们慢慢学会编程,可以让没有接触过编程的人了 ...
- 互评Alpha版本——二次元梦之队——“I Do”
基于NABCD评论作品,及改进建议 1.根据(不限于)NABCD评论作品的选题 (1)N(Need,需求) 随着智能科技的发展和普及,编程教育的重要性已经逐渐凸显出来.美国前总统奥巴马曾说“编程应当与 ...
- 【Dream Counting, 2006 Dec-数数的梦】数位dp
题意:给定两个数,问区间[A,B]中0~9分别出现了多少次.A,B<=10^18 题解:应该是最裸的数位dp吧..一开始没有记忆化tle了TAT 我们可以求出区间[0,B]的,再减去区间[0,A ...
- 2017ACM暑期多校联合训练 - Team 1 1006 HDU 6038 Function (排列组合)
题目链接 Problem Description You are given a permutation a from 0 to n−1 and a permutation b from 0 to m ...
- A Dream (PKUWC 2018)
A Dream (PKUWC 2018) 这是一个梦. 从没有几分节日气氛的圣诞,做到了大雪纷飞的数九寒天. 忘了罢! 不记得时间,不记得地点.随着记忆的褪去,一切也只会不复存在. Day-34? D ...
- Team Dipper
Team Dipper Dipper 来自追梦的7星,We Are From Now On! 说什么?图小了?没问题满足你! No.1 沉默深邃之境的术士,源自奥术之境的PHP探寻者 03150225 ...
随机推荐
- .net core 2.0 MVC区域
区域 创建对应的目录结构 Areas System Controllers Views 在Startup.cs 注册路由 在控制器上方加上`[Area("system")]` // ...
- GitHub大佬:供计算机学习鉴黄功能的图片数据库
ps:学无止境 想要构建一套鉴黄系统,必须有大量的真实图片供计算机进行学习,以便于区分开正常图片和黄色图片. 近期有位加拿大程序员在Github上传了图片列表,里面包含了大量图片地址可以供计算机进行学 ...
- IntelliJ IDEA Tomcat启动VM Options配置
-server -XX:PermSize=512M -XX:MaxPermSize=1024m -Dfile.encoding=UTF-8 JDK8中用metaspace代替permsize,因此在许 ...
- Cash Machine POJ - 1276 多重背包二进制优化
题意:多重背包模型 n种物品 每个m个 问背包容量下最多拿多少 这里要用二进制优化不然会超时 #include<iostream> #include<cstdio> #in ...
- 洛谷3704 [SDOI2017] 数字表格 【莫比乌斯反演】
题目分析: 比较有意思,但是套路的数学题. 题目要求$ \prod_{i=1}^{n} \prod_{j=1}^{m}Fib(gcd(i,j)) $. 注意到$ gcd(i,j) $有大量重复,采用莫 ...
- 实验九 在JSP中使用数据库
实验性质:验证性 实验学时: 1学时 实验地点: 一 .实验目的与要求 1. 掌握在JSP中使用数据库的方法. 2. 掌握JSP对数据库的基本操作:增.删.改.查. 二. 实验内容 1.JSP访问数据 ...
- Matplotlib学习---用matplotlib画折线图(line chart)
这里利用Jake Vanderplas所著的<Python数据科学手册>一书中的数据,学习画图. 数据地址:https://raw.githubusercontent.com/jakevd ...
- 志愿者招募 HYSBZ - 1061(公式建图费用流)
转自神犇:https://www.cnblogs.com/jianglangcaijin/p/3799759.html 题意:申奥成功后,布布经过不懈努力,终于 成为奥组委下属公司人力资源部门的主管. ...
- Nagios 监控windows server Apache 服务
监控机需要使用check_apachestatus.pl插件插件下载地址:https://exchange.nagios.org/directory/Tutorials/Other-Tutorials ...
- 【总结】字符串hash
序列字符串\(Hash\) 直接hash即可qwq 预处理:\(Hash[3][i]\)(\(Hash\)值),\(Pow[3][i]\)(用来乘系数) 判断相等:\(box_1=Hash[3][i] ...