069 在SparkStreaming的窗口分析
一:说明
1.图例说明
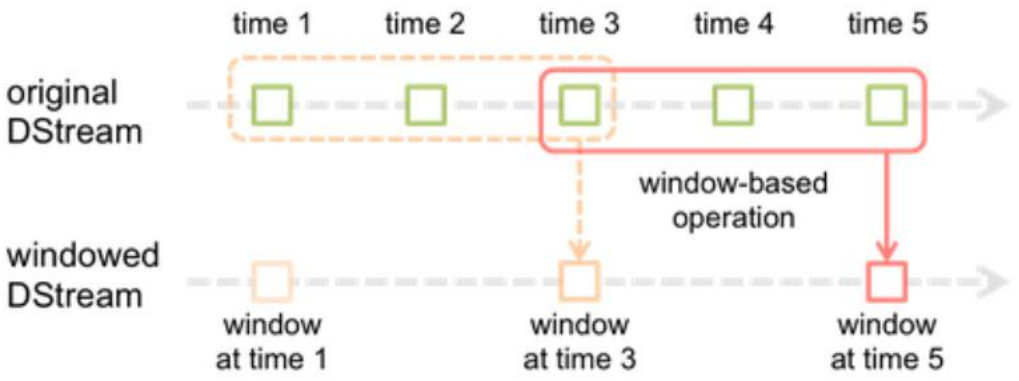
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------

2.对比说明
DStream:
batchInterval: 批次产生间隔时间
Window DStream:
windowInterval: 窗口间隔时间, 必须是父DStream的batchInterval的倍数(k >= 1, 整数)
slideInterval:窗口滑动间隔时间, 必须是父DStream的batchInterval的倍数(k >= 1, 整数)
3.API
使用CTRL+F3,可以参考这篇文档的快捷键:https://blog.csdn.net/qq_36901488/article/details/80704245
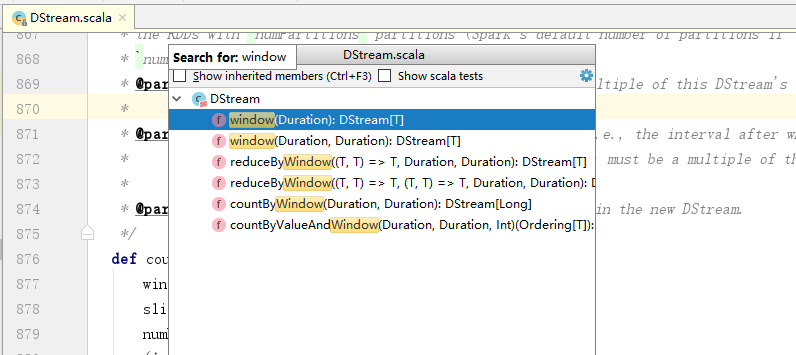
二:程序
1.程序
package com.window.it
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils object ReduceWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("StreamingWindowOfKafka")
.setMaster("local[*]")
val sc = SparkContext.getOrCreate(conf)
val ssc = new StreamingContext(sc, Seconds(5))
// 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/452512") val kafkaParams = Map(
"group.id" -> "streaming-kafka-78912151",
"zookeeper.connect" -> "linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset" -> "smallest"
)
val topics = Map("beifeng" -> 4) // topics中value是读取数据的线程数量,所以必须大于等于1
val dstream = KafkaUtils.createStream[String, String, kafka.serializer.StringDecoder, kafka.serializer.StringDecoder](
ssc, // 给定SparkStreaming上下文
kafkaParams, // 给定连接kafka的参数信息 ===> 通过Kafka HighLevelConsumerAPI连接
topics, // 给定读取对应topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 // 指定数据接收器接收到kafka的数据后保存的存储级别
).map(_._2) val resultWordCount = dstream
.filter(line => line.nonEmpty)
.flatMap(line => line.split(" ").map((_, 1)))
.reduceByKeyAndWindow(
(a: Int, b: Int) => a + b,
Seconds(15), // 窗口大小
Seconds(10) // 滑动大小
)
resultWordCount.print() // 这个也是打印数据 // 启动开始处理
ssc.start()
ssc.awaitTermination() // 等等结束,监控一个线程的中断操作
}
}
2.效果
这里主要看的是页面的DAG。
069 在SparkStreaming的窗口分析的更多相关文章
- SparkStreaming实时日志分析--实时热搜词
Overview 整个项目的整体架构如下: 关于SparkStreaming的部分: Flume传数据到SparkStreaming:为了简单使用的是push-based的方式.这种方式可能会丢失数据 ...
- SparkStreaming 源码分析
SparkStreaming 分析 (基于1.5版本源码) SparkStreaming 介绍 SparkStreaming是一个流式批处理框架,它的核心执行引擎是Spark,适合处理实时数据与历史数 ...
- windows窗口分析,父窗口,子窗口,所有者窗口
(本文尝试通过一些简单的实验,来分析Windows的窗口机制,并对微软的设计理由进行一定的猜测,需要读者具备C++.Windows编程及MFC经验,还得有一定动手能力.文中可能出现一些术语不统一的现象 ...
- DirectStream、Stream的区别-SparkStreaming源码分析02
转http://hadoop1989.com/2016/03/15/KafkaStreaming/ 在Spark1.3之前,默认的Spark接收Kafka数据的方式是基于Receiver的,在这之后的 ...
- Flink Streaming基于滚动窗口的事件时间分析
使用flink-1.9.0进行的测试,在不同的并行度下,Flink对事件时间的处理逻辑不同.包括1.1在并行度为1的本地模式分析和1.2在多并行度的本地模式分析两部分.通过理论结合源码进行验证,得到具 ...
- LR12.53—第7课:分析场景
第7课:分析场景 在前面的课程中,您学习如何设计,控制和执行方案运行.一旦您已加载您的服务器,你要分析的运行,并确定需要被淘汰,以提高系统性能的问题. 在图表和报告中有关方案的性能您的分析会议上提出的 ...
- 小项目一---Python日志分析
日志分析 概述 分析的前提 半结构化数据 文本分析 提取数据(信息提取) 一.空格分隔 with open('xxx.log')as f: for line in f: for field in ...
- win32程序之窗口程序,以及消息机制
win32程序值窗口程序,以及消息机制 一丶简介 通过上一讲.我们了解了窗口其实是绘制出来的.而且是不断绘制的过程. 所以窗口的本质是绘制. 但是我们现在看到的窗口程序.都可以点击关闭按钮. 使用鼠标 ...
- FusionInsight大数据开发---SparkStreaming概述
SparkStreaming概述 SparkStreaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性.高吞吐量.可容错性等特点. SparkStreaming原理 Spa ...
随机推荐
- reportNG定制化之失败截图及日志
先从github上拉下 reportNg的源代码 reportng 拉下源码后我们使用IDEA进行导入 1.reportng.properties 增加部分类表项 这里我们直接在末尾添加 log=L ...
- 开通博客的第一天上传我的C#基础笔记。
1.索引器 string arrStr = "sddfdfgfh"; 索引器的目的就是为了方便而已,可以在该类型的对象后面直接写[]访问该对象里面的成员 Console.Wr ...
- JsonResponse
1.JsonResponse class JsonResponse(data, encoder=DjangoJSONEncoder, safe=True, json_dumps_params=None ...
- 公历和农历转换的JS代码(车)
<!-- function CalConv(M) { FIRSTYEAR = 1936; LASTYEAR = 2031; LunarCal = [ new tagLunarCal(23, 3, ...
- 自定义你的 Confluence 6 站点
本部分对 Confluence 全站进行自定义的相关内容进行了说明.这部分只能是具有 Confluence 的管理员权限的用户才能进行操作 —— 系统管理员或者 Confluence 管理员. 有关对 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- node.js 的热更新
1.安装 npm i supervisor -gd 2.运行 supervisor server.js //server.js 是你自己的服务的js文件
- Java 产生一个大于等于200,小于300的随机数,且是10的整数倍
public class Random200_300 { public static void main(String[] args) { int r1 = 0; while (true) { r1 ...
- 如何录制Chrome或者Linux下的应用
说明: PortMapping的这种用法其实早就有了,开始我一直没注意到这点,后面才发现了这个功能,特别在<性能测试进阶指南Loadrunner11实战>第二版中更新. 不是所有的对象都能 ...
- Python关键字及其用法
Python有哪些关键字 -Python常用的关键字 and, del, from, not, while, as, elif, global, or, with, assert, else, if ...