python bytes和bytearray、编码和解码
str、bytes和bytearray简介
str是字符数据,bytes和bytearray是字节数据。它们都是序列,可以进行迭代遍历。str和bytes是不可变序列,bytearray是可变序列,可以原处修改字节。
bytes和bytearray都能使用str类型的通用函数,比如find()、replace()、islower()等,不能用的是str的格式化操作。所以,如有需要,参考字符串(string)方法整理来获取这些函数的使用方法。
str
str将各个字符组合在一起,以一种不可变序列进行存储。但是在底层它还是一个个的二进制数,是由一个个的字节组成的(也就是byte),只不过python根据指定的字符集编码"强行"将字节序列显示为字符。
python 3.x中默认str是unicode格式编码的,例如UTF-8字符集。
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
unicode编码的str,意味着能够直接存储除ascii码外的很多字符,比如中文,比如欧洲的重音符号。还意味着可以将一个unicode字符存储为多个字节,并将连续多个的字节翻译成单个对应的字符。
>>> a = "我"
>>> a
'我'
>>> ord(a)
25105
>>> a.encode()
b'\xe6\x88\x91'
根据指定字符集,底层的字节序列和字符序列间的转换过程完全无需人为的参与,python已经做好了一切。
bytes
bytes是不可变的二进制格式字节数据(注意,是字节不是字符),以整数方式表示。例如对于ascii范围内的字符"a",它存储为97。
要构造bytes类型的数据,方法之一是在字符串前面加上b或B前缀。
例如:
>>> B = b"abcd"
>>> [i for i in B]
[97, 98, 99, 100]
>>> B[0] = "A"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'bytes' object does not support item assignment
bytes和下面的bytearray都能使用str类型的绝大部分方法。例如find()、replace()等,但用法上可能会有所区别,比如str.replace()的替换参数期待的是字符,而bytes.replace()的替换参数可能是字节。例如:
>>> b'abcd'.replace(b'cd',b'XY')
b'abXY'
bytearray
bytearray是可变的二进制数据(byte)。
要构造bytearray对象,方法之一是将bytes数据作为bytearray()方法的参数,或者将str数据和编码作为参数。
例如:
>>> S = b"abcd"
>>> BA = bytearray(S)
>>> [ i for i in BA ]
[97, 98, 99, 100]
>>> BA[0] = 65
>>> BA
bytearray(b'Abcd')
unicode字符
单字节的字符(8bit位,共256个字符,ascii只用到了7个字节)能表示出来的字符毕竟有限,例如它没法表示出中文字符。
所以,各国设计了各种多字节的字符编码来表达自己国家的文字,底层仍然使用二进制数存储,然后通过设计好的编码表将二进制数转换成各种字符。比如中国有GBK的各种编码,还有全球通用的编码类型unicode、utf-8、utf-16等。
无论什么编码,内部都包含ascii编码(也有例外,比如utf-16),它只需单个字节。也就是说,ascii编码是任何其它编码表的子集。但有些编码表强制规定每个字符占多少个字节(比如unicode固定为2个字节),有些编码表动态决定每个字符占多少个字节(比如utf-8是变长的,可能占用1-4个字节空间,存储字母为1个字节,存储中文字符为3个字节)。
关于unicode和utf-X格式的编码关系,粗略地可以认为utf-X是unicode格式的一种特殊类型。实际上在存储utf数据时,内部会自动在Unicode和utf之间进行转换。
要构建Unicode类型,只需加上u或U前缀。
>>> U = u"我爱你"
>>> B = bytes(U,"utf-8")
>>> B
b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'
>>> BA = bytearray(U,"utf-8")
>>> BA
bytearray(b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0')
编码和解码
下面一张图搞懂编码、解码、编码表之间的关系。
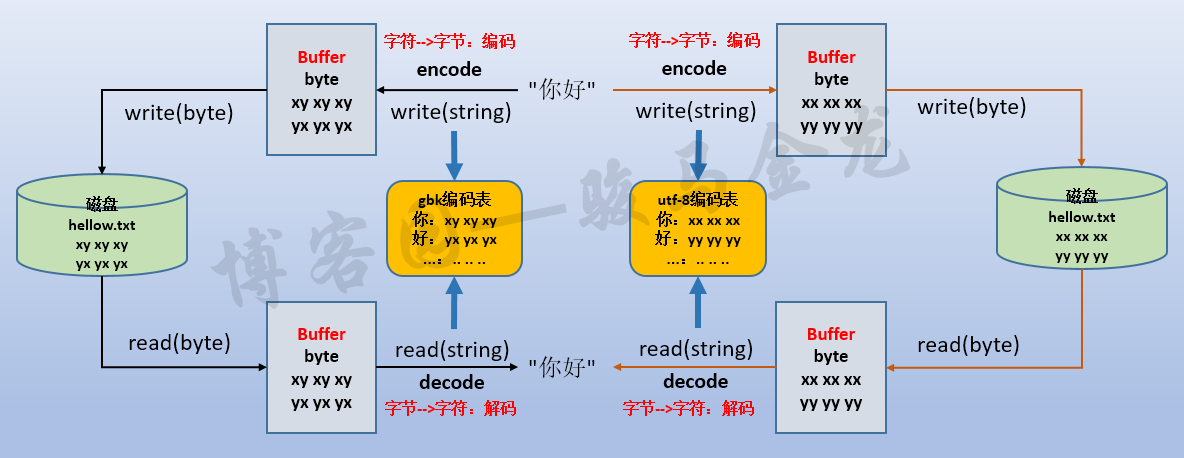
不难看出,它们是一种根据编码表进行翻译、映射的过程:
编码:str --> bytes
解码:bytes --> str
实际上,字符串类型只有encode()方法,没有decode()方法,而bytes类型只有decode()方法而没有encode()方法。
>>> set( dir(str) ) - set( dir(bytes) )
{'encode', ... , 'isidentifier', 'format'}
>>> set( dir(bytes) ) - set( dir(str) )
{'decode', 'hex', 'fromhex'}
二进制格式的数据也常称为裸数据(raw data),所以str数据经过编码后得到raw data,raw data解码后得到的str。
python中的编码、解码
上面说了,编码是将字符数据转换成字节数据(raw data),解码是将字节数据转换成字符数据。在Python中字符数据也就是字符串,即str类型,字节数据也就是bytes类型或bytearray类型。
编码时,可以使用字节类型的构造方法bytes()、bytearray()来构造字节,也可以使用str类型的encode()方法来转换。
解码时,可以使用str类型的构造方法str()来构造字符串,也可以使用bytes、bytearray()类型的decode()方法。
另外需要注意的是,编码和解码的过程中都需要指定编码表(字符集),默认采用的是utf-8字符集。
编码过程
例如,使用encode()的方式将str编码为bytes数据。
>>> str1 = "abcd"
>>> str2 = "我爱你"
# 默认编码
>>> str1.encode()
b'abcd'
>>> str2.encode()
b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'
# 显式指定使用utf-8进行编码
>>> str1.encode("utf-8")
b'abcd'
>>> str2.encode("utf-8")
b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'
# 使用utf-16编码
>>> str1.encode("utf-16")
b'\xff\xfea\x00b\x00c\x00d\x00'
>>> str2.encode("utf-16")
b'\xff\xfe\x11b1r`O'
# 使用gb2312编码
>>> str1.encode("gb2312")
b'abcd'
>>> str2.encode("gb2312")
b'\xce\xd2\xb0\xae\xc4\xe3'
# 使用gbk编码
>>> str1.encode("gbk")
b'abcd'
>>> str2.encode("gbk")
b'\xce\xd2\xb0\xae\xc4\xe3'
使用bytes()和bytearray()将str构造成bytes或bytearray数据,这两个方法都要求str->byte的过程中给定编码。
>>> bytes(str1,encoding="utf-8")
b'abcd'
>>> bytes(str1,encoding="utf-16")
b'\xff\xfea\x00b\x00c\x00d\x00'
>>> bytearray(str1,encoding="utf-8")
bytearray(b'abcd')
>>> bytearray(str2,encoding="utf-8")
bytearray(b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0')
实际上,bytes()、bytearray()这两个方法构造字节数据的时候还有点复杂,因为可以从多个数据源来构造,比如字符串、整数值、buffer。如何使用这两个方法构造字节数据,详细内容参考help(bytes)和help(bytearray)给出的说明,这里给几个简单示例。
构造bytes的方式:
# 构造空bytes对象
>>> bytes()
b''
# 使用str构造bytes序列,需要指定编码
>>> bytes("abcd",encoding="utf-8")
b'abcd'
# 使用int初始化5个字节的bytes序列
>>> bytes(5)
b'\x00\x00\x00\x00\x00'
# 使用可迭代的int序列构造字节序列
# int值必须为0-256以内的数
>>> bytes([65,66,67])
b'ABC'
# 使用bytes或buffer来构造bytes对象
>>> bytes(b'abcd')
b'abcd'
构造bytearray的方式:
# 构造空bytearray对象
>>> bytearray()
bytearray(b'')
# 使用bytes或buffer构造bytearray序列
>>> bytearray(b"abcd")
bytearray(b'abcd')
# 使用str构造bytearray序列,需要指定编码
>>> bytearray("abcd",encoding="utf-8")
bytearray(b'abcd')
# 使用int初始化5个字节的bytearray序列
>>> bytearray(5)
bytearray(b'\x00\x00\x00\x00\x00')
# 使用可迭代的int序列构造bytearray序列
# int值必须为0-256以内的数
>>> bytearray([65,66,67])
bytearray(b'ABC')
解码过程
解码是字节序列到str类型的转换。
例如,使用decode()方法进行解码"我"字,它的utf-8的编码对应为"\xe6\x88\x91":
>>> b = b'\xe6\x88\x91'
# 采用默认字符集utf-8
>>> b.decode()
'我'
# 显式指定编码表
>>> b.decode("utf-8")
'我'
使用str()进行转换。
>>> str(b,"utf-8")
'我'
关于乱码
当编码、解码的过程使用了不同的(不兼容的)编码表时,就会出现乱码。所以,解决乱码的唯一方式是指定对应的编码表进行编码、解码。
例如,使用utf-8编码"我"字,得到一个bytes序列,然后使用gbk解码这个bytes序列。
>>> "我".encode().decode("gbk")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'gbk' codec can't decode byte 0x91 in position 2: incomplete multibyte sequence
这里报错了,因为utf-8的字节序列里有gbk无法解码的字节。如果使用文本编辑器一样的工具去显化这个过程,得到的将是乱码字符。
python bytes和bytearray、编码和解码的更多相关文章
- Python中进行Base64编码和解码
Base64编码 广泛应用于MIME协议,作为电子邮件的传输编码,生成的编码可逆,后一两位可能有“=”,生成的编码都是ascii字符.优点:速度快,ascii字符,肉眼不可理解缺点:编码比较长,非常容 ...
- python中的URL编码和解码
python中的URL编码和解码:test.py # 引入urllib的request模块 import urllib.request url = 'https://www.douban.com/j/ ...
- python之路day06--python2/3小区别,小数据池的概念,编码的进阶str转为bytes类型,编码和解码
python2#print() print'abc'#range() xrange()生成器#raw_input() python3# print('abc')# range()# input() = ...
- Python中字符的编码与解码
1 文本和字节序列 我们都知道字符串,就是由一些字符组成的序列构成串,那么字符又是什么呢?计算机只能识别二进制的东西,那么计算机又为什么会显示我们的汉字,或者是某个字母呢? 由于最早发明使用计算机是美 ...
- python学习笔记09-python编码与解码
二进制编码: --->ASCII:只能存英文和拉丁字符 一个字符占一个字节:8位 ------>gb2312:只能存6700多个中文: 1980年发表 ----------->gbk ...
- 从Python的角度来看编码与解码
导语: Python2和Python3中,因为默认字符集的不同而造成的麻烦,简直是程序员的梦魇!要彻底告别这个麻烦,就需要从本质上来理解编码和解码. 为什么要有编码? 对于不会英文的中国人来说,将英文 ...
- python中字符串的编码和解码
1. 常用的编码 ASCII:只能表示一些字母,数字和特殊的字符,占一个字节 GBK:国家简体中文字符集和繁体字符集,兼容ASCII,占两个字节 Unicode:能够表示全世界上所有的字符,Unico ...
- python is == 的区别, 编码与解码.深浅拷贝
一. is == 的区别 双等表示的是判断是否相等, 注意. 这个双等比较的是具体的值.而不是内存地址 is 比较的是地址 编码回顾 除了了ASCII码以外, 其他信息不能直接转换 编码和解码的时 ...
- python字符串格式和编码与解码问题
%c 转换成字符(ASCII码值,长度为一的字符串) %r 有线使用repr()函数进行字符串转换 %s 有线使用str()函数进行字符串转换 %d or %i 转换成有符号十进制数 %u 转换成无符 ...
随机推荐
- ArcSDE
ArcSDE,即数据通路,是ArcGIS的空间数据引擎,它是在关系数据库管理系统(RDBMS)中存储和管理多用户空间数据库的通路.从空间数据管理的角度看,ArcSDE是一个连续的空间数据模型,借助这一 ...
- 计算机网络三:域名、IP地址和TCP/IP协议
一.域名 域名(Domain Name),简称域名.网域,是由一串用点分隔的字符型标志名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时 ...
- win7 ssh linux虚拟机(ubuntu12.04)
环境: 1. 管理vmware Workstation8.0 2. Ubuntu 12.04.iso安装文件 3.Ssh登录软件putty 步骤 1.安装,安装linux系统时,在“硬件”里设置“网络 ...
- git的基本使用和问题
1,填写信息git config --global user.name "用户名"git config --global user.email "邮箱" 2,创 ...
- Delegate、Thread、Task、ThreadPool几种方式创建异步任务性能对比
开始预测的结果是 Task>Delegate>ThreadPool>>Thread. (一)测试代码 static async Task<int> AsyncTas ...
- Windows 10 IoT Core 17101 for Insider 版本更新
除夕夜,微软发布了Windows 10 IoT Core 17101 for Insider 版本更新,本次更新只修正了一些Bug,没有发布新的特性. 已知的问题: F5 driver deploym ...
- FineCMS 5.0.10 多个 漏洞详细分析过程
0x01 前言 已经一个月没有写文章了,最近发生了很多事情,水文一篇.今天的这个CMS是FineCMS,版本是5.0.10版本的几个漏洞分析,从修补漏洞前和修补后的两方面去分析. 文中的evai是特意 ...
- Android JNI 学习(八):Calling Instance Methods Api
一.GetMethodID jmethodIDGetMethodID(JNIEnv *env, jclass clazz, const char *name, const char *sig); 返回 ...
- Javascript高级编程学习笔记(26)—— 函数表达式(4)私有变量
私有变量 严格来讲,JS中没有私有成员的概念,所有对象属性都是公有的. 但是JS中有私有变量的概念 所有在函数中定义的变量都可以认为是私有变量,因为不能在函数外部进行访问 私有变量包括 1.函数参数 ...
- 在谷歌安装扩展程序Axure RP Extension for Chrome后,经常无故损坏,无法使用
最近因为要看需求给的原型图,但需求只给了html格式的文件,没有给可以在Axure软件里看的格式, 所以在谷歌安装了一个Axure RP Extension for Chrome扩展程序在谷歌浏览器看 ...