Game Engine Architecture 3
【Game Engine Architecture 3】
1、Computing performance—typically measured in millions of instructions per second (MIPS) or floating-point operations per second (FLOPS)—has been improving at a staggeringly rapid and consistent rate over the past four decades.
In the late 1970s, the Intel 8087 floating-point coprocessor could muster only about 50 kFLOPS(5 x104^ FLOPS), while at roughly the same time a Cray-1 supercomputer the size of a large refrigerator could opeate at a rate of roughly 160 MFLOPS (1.6 x10^8 FLOPS).
Today, the CPU in game consoles like the Playstation 4 or the Xbox One produces roughly 100 GFLOPS (10^11 FLOPS) of processing power, and the fastest supercomputer, currently China’s Sunway TaihuLight, has a LINPACK benchmark score of 93 PFLOPS (peta-FLOPS, or a staggering 9.3x10^16 floating-point operations per second).
This is an improvement of seven orders of magnitude for personal computers, and eight orders of magnitude for supercomputers.
Writing software that runs correctly and efficiently on parallel computing hardware is significantly more difficult than writing software for the serial computers of yesteryear. It requires a deep understanding of how the hardware actually works.
2、Implicit parallelism & Explicit parallelism
Implicit parallelism refers to the use of parallel hardware components within a CPU for the purpose of improving the performance of a single instruction stream. This is also known as instruction level parallelism (ILP), because the CPU executes instructions from a single stream (a single thread) but each instruction is executed with some degree of hardware parallelism.
隐式并行,只有一个 instruction stream,通过硬件的并行处理业加速该指令流的执行。
Explicit parallelism refers to the use of duplicated hardware components within a CPU, computer or computer system, for the purpose of running more than one instruction stream simultaneously. In other words, explicitly parallel hardware is designed to run concurrent software more efficiently than would be possible on a serial computing platform.
显式并行,同时运行多个 instruction tream.
3、Task Parallelism & Data Parallelism
4、Flynn’s Taxonomy
SISD,Instruction指的是ALU,D指的是 InstructionStream。单个ALU,多个 InsStream。
MIMD,Instruction指的是ALU,D指的是 InstructionStream。多个 ALU,多个 InsStream | 单个分时 ALU,多个 InsStream。
SIMD,Instructino指的是ALU,D指的是 ALU的位宽可以容纳多个数据。单个 ALU,单个InsStream,但ALU位宽增加。
MISD,Instructino指的是ALU,D指的是 InstructionStream。多个ALAU,单个 DataStream。
上述四种并行架构中,第三种SIMD的D比较特殊,它指的并不是多个Stream,而是ALU位宽增加。
• Single instruction, single data (SISD): A single instruction stream operating on a single data stream.


• Multiple instruction, multiple data (MIMD): Multiple instruction streams operating on multiple independent data streams.

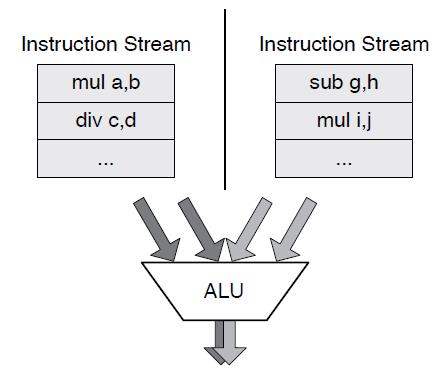

• Single instruction, multiple data (SIMD): A single instruction stream operating on multiple data streams (i.e., performing the same sequence of operations on multiple independent streams of data simultaneously).
single “wide ALU” known as a vector processing unit (VPU) performs aciton.
SIMD是比较特殊的一类,并包含多个 instruction stream。


• Multiple instruction, single data (MISD): Multiple instruction streams all operating on a single data stream. (MISD is rarely used in games, but one common application is to provide fault tolerance via redundancy.)

5、Concurrency vs Parallelism
concurrent software doesn’t require parallel hardware, and parallel hardware isn’t only for running concurrent software.
As long as our system involves multiple readers and/or multiple writers of a shared data object, we have a concurrent system. Concurrency can be achieved via preemptive multitasking (on serial or parallel hardware) or via true parallelism (in which each thread executes on a distinct core)
6、4.2 Implicit Parallelism
1)pipeline architecture
Pipelining is a form of parallelism known as instruction-level parallelism (ILP).
Latency,Denoting latencies with the time variable T, we can write for a pipeline with N stages:
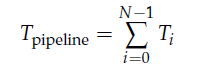
Throughput,The throughput or bandwidth of a pipeline is a measure of how many instructions it can process per unit time. The throughput of a pipeline is determined by the latency of its slowest stage:

2)supersscalar
3)very long intruction word(VLIW) architecture
8、Pipeline Dependencies
1)data dependencies

Ideally, we’d like to issue the mov, imul and add instructions on three consecutive clock cycles, to keep the pipeline as busy as possible. But in this case, the results of the imul instruction are used by the add instruction that follows it, so the CPU must wait until the imul has made it all the way through the pipeline before issuing the add. This is called stall.
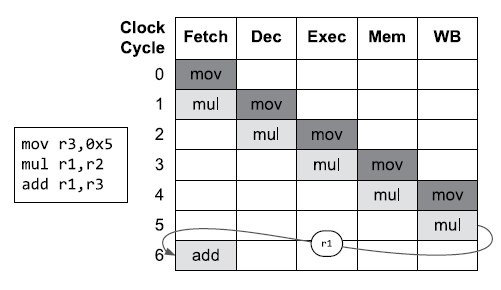
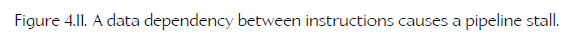
data-dependencies stall 问题的解决方案
<1> instruction reordering,compiler 特性,programmer、compiler
<2> out-of-order execution,CPU 特性,compiler optimizations and out-of-order execution can cause bugs in a concurrent program.
2)control dependencies(branch dependencies)
branch dependencies 问题的解决方案
<1> speculative execution, also known as branch predication. 先计算其中一条分支,有50%算对的概率,从而提前完成。
<2> predication. 使用mask,将分支取消。
3)structual dependencies(resource dependencies)
11、Superscalar CPUs
a scalar processor. This means that it can start executing at most one instruction per clock cycle. Yes, multiple instructions are “in flight” at any given moment, but only one new instruction is sent down the pipeline every clock cycle.
duplicate most of the components on the chip, in such a way that two instructions could be launched each clock cycle. This is called a superscalar architecture.
The CPU still fetches instructions from a single instruction stream. the next two instructions are fetched and dispatched during each clock cycle.
Specular CPU 只有一个 instruction stream,即一条pipeline,通过扩展 pipeline上每一个stage的组件,以及每次从instruction stream中读取多个指令,来提升CPU性能。

In addition to data and branch dependencies, a superscalar CPU is prone to a third kind of dependency known as a resource dependency. 比如有两个 ALU,但只有一个FPU。
A two-way superscalar CPU requires roughly two times the silicon real-estate of a comparable scalar CPU design. In order to free up transistors, most superscalar CPUs are therefore reduced instruction set (RISC) processors.
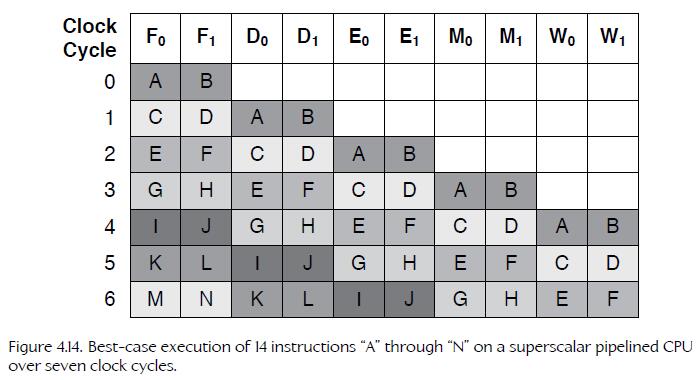
12、Very Long Instruction Word
a CPU that has multiple compute elements (ALUs, FPUs, VPUs) on-chip.


13、Hyperthreading
what if the CPU could select its instructions from two separate instruction streams at once? This is the principle behind a hyperthreaded (HT) CPU core.
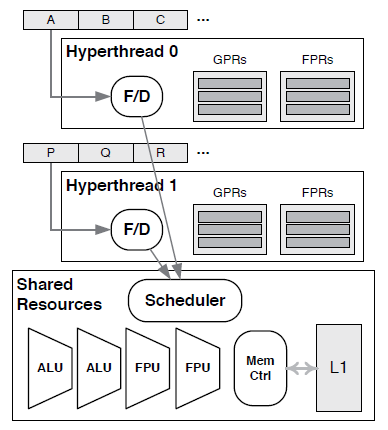

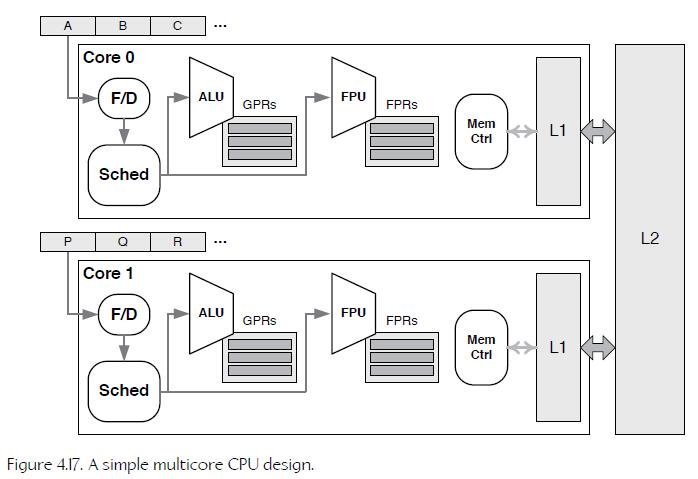
14、Multicore CPUs
When more than one core is included on a single CPU die, we call it a multicore CPU.
each core might employ a simple serial design, a pipelined design, a superscalar architecture, a VLIW design, or might be a hyperthreaded core. Figure 4.17 illustrates a simple example of a multicore CPU design.
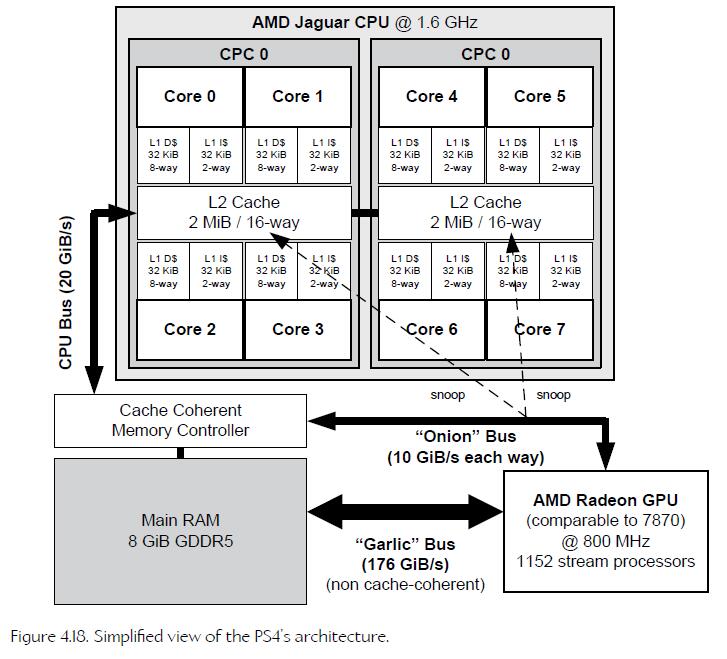
下面是 ps4、xbox one x 的处理器架构。

15、Symmetric vs Asymmetric Multiprocessing
In symmetric multiprocessing (SMP), the available CPU cores in the machine (provided by any combination of hyperthreading, multicore CPUs or multiple CPUs on a single motherboard) are homogeneous in terms of design and ISA, and are treated equally by the operating system. Any thread can be scheduled to execute on any core.
The PlayStation 4 and the Xbox One are examples of SMP. Both of these consoles contain eight cores, of which seven are available for use by the programmer, and the application is free to run threads on any of the available cores.
asymmetric multiprocessing (AMP), the CPU cores are not necessarily homogeneous, and the operating system does not treat them equally. In AMP, one “master” CPU core typically runs the operating system, and the other cores are treated as “slaves” to which workloads are distributed by the master core.
The cell broadband engine (CBE) used in the PlayStation 3 is an example of AMP; it employs a main CPU known as the “power processing unit” (PPU) which is based on the PowerPC ISA, along with eight coprocessors known as “synergystic processing units” (SPUs) which are based around a completely different ISA.
16、Kernel
The “core” of the operating system—the part that handles all of the most fundamental and lowest-level operations—is called the kernel.


17、Kernel Mode vs User Mode
The kernel and its device drives run in a special mode called protected mode, privileged mode or kernel mode, while all other programs in the system (including all other parts of the operating system that aren’t part of the kernel) operate in user mode.
privileged mode has full access to all of the hardware in the computer, whereas user mode software is restricted in various ways in order to ensure stability of the computer system as a whole.
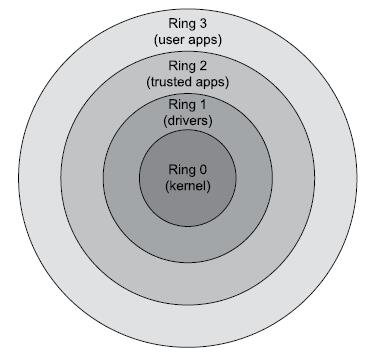
operating systems may implement multiple protection rings.
The kernel runs in ring 0, which is the most trusted ring and has all possible privileges within the system.
Device drivers might run in ring 1, trusted programs with I/O permissions might run in ring 2, while all other “untrusted” user programs run in ring 3.

18、Interrupts
An interrupt is a signal sent to the CPU in order to notify it of an important low-level event. When such an event occurs, an interrupt request (IRQ) is raised. If the operating system wishes to respond to the event, it pauses (interrupts) whatever processing had been going on, and calls a special kind of function called an interrupt service routine (ISR).
There are two kinds of interrupt: hardware interrupts and software interrupts.
For hardware interrupts there may be a tiny delay between the moment when a hardware interrupt is physically raised and when the CPU is in a suitable state to handle it.
A software interrupt can be triggered explicitly by executing an “interrupt” machine language instruction. Or one may be triggered in response to an erroneous condition detected by the CPU while running a piece of software—these are called traps or sometimes exceptions.
19、kernel Calls
On most modern operating systems, the user program doesn’t execute a software interrupt or system call instruction manually. Instead, a user program calls a kernel API function, which in turn marshalls the arguments and trips the software interrupt.
20、Preemptive Multitasking
multiprogramming would allow one program to run while another was waiting for a time-consuming request to be satisifed by a peripheral device. Classic Mac OS and versions of Windows prior to Windows NT and Windows 95.
in multiprogramming One “rogue” program could consume all of the CPU’s time if it failed to yield to other programs periodically. The PDP-6 Monitor and Multics operating systems solved this problem by introducing a technique known as preemptive multitasking. This technology was later adopted by the UNIX operating system and all of its variants, along with later versions of Mac OS and Windows.
21、Anatomy of a Process
• a set of permissions, such as which user “owns” each process and to which user group it belongs;
• a reference to the process’s parent process, if any,
• the current working directory for the process,
22、Virtual Memory Map of a Process
Every process has its own virtual page table. pages owned by the kernel are protected from inadvertent or deliberate corruption by a user process because they are mapped to a special range of addresses known as kernel space which can only be accessed by code running in kernel mode.
23、Shared Library
Most operating systems also support the concept of shared libraries. In this case, the program contains only references to the library’s API functions, not a copy of the library’s machine code.
Shared libraries are called dynamic link libraries (DLL) under Windows.
The first time a shared library is needed by a process, the OS loads that library into physical memory, and maps a view of it into the process’s virtual address space. The addresses of the functions and global variables provided by the shared library are patched into the program’s machine code, allowing it to call them as if they had been statically linked into the executable.
a second process is run that uses the same shared library. Rather than loading a copy of the library’s code and global variables, the already-loaded physical pages are simply mapped into the virtual address space of the new process.
24、Kernel Pages
the address space of a process is actually divided into two large contiguous blocks—user space and kernel space.
For example, on 32-bit Windows, user space corresponds to the address range from address 0x0 through 0x7FFFFFFF (the lower 2 GiB of the address space), while kernel space corresponds to addresses between 0x80000000 and 0xFFFFFFFF (the upper 2 GiB of the space).
User space is mapped through a virtual page table that is unique to each process. However, kernel space uses a separate virtual page table that is shared between all processes. This is done so that all processes in the system have a consistent “view” of the kernel’s internal data.
25、Process & Thread
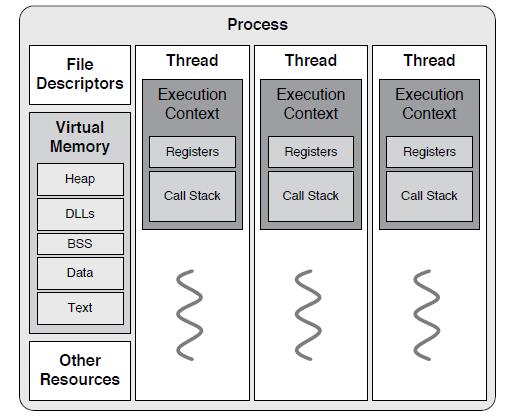

26、Thread libraries
5)Yield. A function that yields the remainder of the thread’s time slice so other threads can get a chance to run.
6) Join. A function that puts the calling thread to sleep until another thread or group of threads has terminated.
27、Polling, Blocking and Yielding
a thread might need to wait for a time-consuming operation to complete, or for some resource to become available. In such a situation, we have three options:
1)The thread can poll
2)it can block,
put our thread to sleep so that it doesn’t waste CPU resources and rely on the kernel to wake it back up when the condition becomes true at some future time.
3)it can yield while polling.
28、sorts of OS functions that block.
• Opening a file. Most functions that open a file such as fopen() will block the calling thread until the file has actually been opened
• Explicit sleeping. Variants include usleep() (Linux), Sleep() (Windows) std::this_thread::sleep_until() (C++11 standard library) and pthread_sleep() (POSIX threads).
• Joining with another thread.
• Waiting for a mutex lock.
书上少说一种情况,即等待网络回包。
29、yielding
This technique falls part-way between polling and blocking. The thread polls the condition in a loop, but on each iteration it relinquishes the remainder of its time slice by calling pthread_yield() (POSIX), Sleep(0) or SwitchToThread() (Windows), or an equivalent system call.

30、Context Switching
• Running. The thread is actively running on a core.
• Runnable. The thread is able to run, but it is waiting to receive a time slice on a core.
• Blocked. The thread is asleep, waiting for some condition to become true.
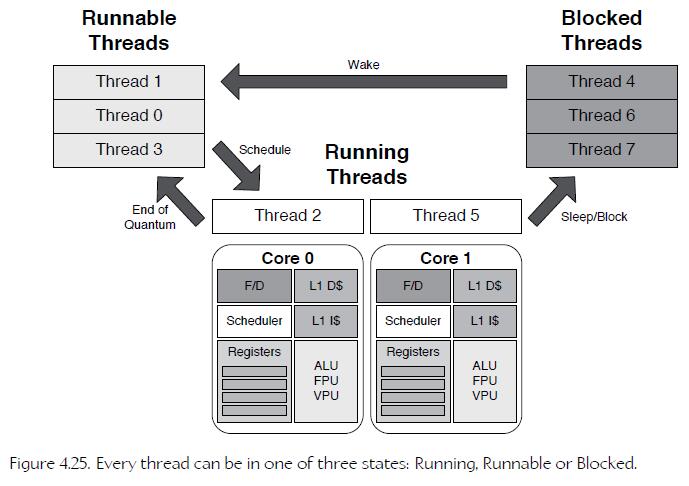
Whenever a thread transitions away from the Running state to either Runnable or Blocked, the contents of the CPU’s registers are saved to a memory block that has been reserved for the thread by the kernel.
Later, when a Runnable thread transitions back to the Running state, the kernel repopulates the CPU’s registers with that thread’s saved register contents.
31、Thread Priorities and Affinity
Different operating systems offer different numbers of priority levels. For example, Windows threads can belong to one of six priority classes, and there are seven distinct priority levels within each class. These two values are combined to produce a total of 32 distinct “base priorities” which are used when scheduling threads.
Another way in which programmers can control thread scheduling is via a thread’s affinity. This setting requests that the kernel either lock a thread to a particular core, or that it should at least prefer one or more cores over the others when scheduling the thread.
32、Thread Local Storage
the OS grants each thread its own TLS block, all mapped into the process’s virtual address space at different numerical addresses, and a system call is provided that allows any one thread to obtain the address of its private TLS block.
33、Fiber
A fiber has a call stack and register state (an execution context), just like a thread. However, the big difference is that a fiber is never scheduled directly by the kernel. Instead, fibers run within the context of a thread, and are scheduled cooperatively, by each other.
When a thread calls the function ConvertThreadToFiber(), a new fiber is created within the context of the calling thread. This “bootstraps” the process so that it can create and schedule more fibers.
Other fibers are created by calling CreateFiber() and passing it the address of a function that will serve as its entry point.
Any running fiber can cooperatively schedule a different fiber to run within its thread by calling SwitchToFiber(). This is the only way that fibers can switch between the Active and Inactive states.
When a fiber is no longer needed, it can be destroyed by calling DeleteFiber().
34、Fiber State
fiber can be in one of two states: Active or Inactive.
fibers don’t themselves have a Blocked state, the way threads do. In other words, it’s not possible to put a fiber to sleep waiting on a condition. Only its thread can be put to sleep.
Making a blocking OS call from within a fiber is usually a pretty big no-no. Doing so would put the fiber’s enclosing thread to sleep, thereby preventing that fiber from doing anything—including scheduling other fibers to run cooperatively.
35、Fiber Migration
A fiber can migrate from thread to thread, but only by passing through its Inactive state.
As an example, consider a fiber F that is running within the context of thread A. Fiber F calls SwitchToFiber(G) to activate a different fiber named G inside thread A. This puts fiber F into its Inactive state (meaning it is no longer associated with any thread). Now let’s assume that another thread named B is running fiber H. If fiber H calls SwitchToFiber(F), then fiber F has effectively migrated from thread A to thread B.
these facilities are provided by the kernel.
36、User-Level Threads and Coroutines
User-level threads are implemented entirely in user space. The kernel knows nothing about them.
When a coroutine yields, its execution context is maintained in memory. The next time the coroutine is called (by being yielded to by some other coroutine) it continues from where it left off.
37、kernel thread 的两种含意。
1) On Linux, a “kernel thread” is a special kind of thread created for internal use by the kernel itself, which runs only while the CPU is in privileged mode. In this sense of the term, any thread that runs in privileged mode is a kernel thread, and any thread that runs in user mode (in the context of a single-threaded or multithreaded process) is a “user thread.”
2) The term “kernel thread” can also be used to refer to any thread that is known to and scheduled by the kernel. Using this definition, a kernel thread can execute in either kernel space or user space, and the term “user thread” only applies to a flow of control that is managed entirely by a user-space program without the kernel being involved at all, such as a coroutine.
Game Engine Architecture 3的更多相关文章
- Game Engine Architecture 11
[Game Engine Architecture 11] 1.three most-common techniques used in modern game engines. 1)Cel Anim ...
- Game Engine Architecture 10
[Game Engine Architecture 10] 1.Full-Screen Antialiasing (FSAA) also known as super-sampled antialia ...
- Game Engine Architecture 9
[Game Engine Architecture 9] 1.Formatted Output with OutputDebugString() int VDebugPrintF(const char ...
- Game Engine Architecture 8
[Game Engine Architecture 8] 1.Differences across Operating Systems • UNIX uses a forward slash (/) ...
- Game Engine Architecture 7
[Game Engine Architecture 7] 1.SRT Transformations When a quaternion is combined with a translation ...
- Game Engine Architecture 6
[Game Engine Architecture 6] 1.Data-Parallel Computations A GPU is a specialized coprocessor designe ...
- Game Engine Architecture 5
[Game Engine Architecture 5] 1.Memory Ordering Semantics These mysterious and vexing problems can on ...
- Game Engine Architecture 4
[Game Engine Architecture 4] 1.a model of multiple semi-independent flows of control simply matches ...
- Game Engine Architecture 2
[Game Engine Architecture 2] 1.endian swap 函数 floating-point endian-swapping:将浮点指针reinterpert_cast 成 ...
随机推荐
- JS中冒号的作用
JS中冒号的作用1.声明对象的成员2.switch语句分支3.三元表达式 1.声明对象的成员 var Book = { Name: '法', Price: 100, Discount : functi ...
- 使用Netty开发RPC的技术原理
本片文字摘抄自https://www.cnblogs.com/jietang/p/5615681.html 1.定义RPC请求消息.应答消息结构,里面要包括RPC的接口定义模块,包括远程调用的类名.方 ...
- C++ 重定义、重载、覆盖
想要用好C++继承和类自身函数实现就必须了解C++得三个概念重定义(redefine).重载(overload).重写(override). 一 基本感念 1 重定义(redefine) 派生类对基类 ...
- python3学习笔记12(变量作用域)
变量作用域 参考http://www.runoob.com/python3/python3-function.html Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量 ...
- python32模拟鼠标和键盘操作
前言Windows pywin32允许你像vc一样的形式来使用python开发win32应用.代码风格可以类似win32 sdk,也可以类似MFC,由你选择.如果你仍不放弃vc一样的代码过程在pyth ...
- [转]AJAX POST请求中参数以form data和request payload形式在servlet中的获取方式
转载至 http://blog.csdn.net/mhmyqn/article/details/25561535 最近在写接收第三方的json数据, 因为对java不熟悉,有时候能通过request能 ...
- 织梦dede文章列表调用标签的用法和规则
织梦dede列表标签在任何模板的网站中都可能会使用到,而且我们在仿站的时候也经常要使用到列表标签.这里主机吧就给大家讲一下文章列表以及图片列表.软件列表以及分类信息列表标签的用法,和结合div+css ...
- CentOS 7修改系统时间及硬件时间
转载于:https://www.cnblogs.com/LouisZJ/p/8554991.html [root@nginx ~]# timedatectl --help timedatectl [O ...
- DataStrom框架深造
根据前一版DataStrom的使用,继续进行了改造和升级;前一版框架只是对服务按照名称注册和调用固化接口 最近研究后台框架,接触了ZBUS框架,我很喜欢ZBUS的前一版,该作者继续升级,已经在向AMQ ...
- CSS ——padding
css样式中使用padding(内边距)会将盒子撑开? 解决办法:在样式中添加box-sizing:border-box;