一脸懵逼学习keepalived(对Nginx进行热备)
1:Keepalived的官方网址:http://www.keepalived.org/
2:Keepalived:可以实现高可靠;
高可靠的概念:
HA(High Available), 高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。
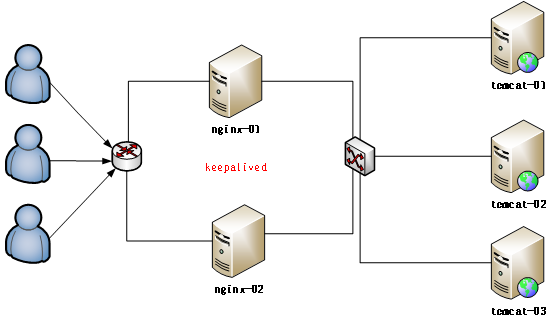
3:高可靠软件:keepalived:
keepalive是一款可以实现高可靠的软件,通常部署在2台服务器上,分为一主一备。Keepalived可以对本机上的进程进行检测,一旦Master检测出某个进程出现问题,将自己切换成Backup状态,然后通知另外一个节点切换成Master状态。
4:keepalived的安装操作:
4.1:下载keepalived官网:http://keepalived.org
首先在两台机器上面部署两个Nginx,具体操作见上篇部署一台,另一台的部署过程省略:
将keepalived上传到虚拟机以后进行解压缩操作:
[root@master package]# tar -zxvf keepalived-1.2.19.tar.gz -C /home/hadoop/
解压缩以后进入到解压缩的目录里面:
[root@master package]# cd /home/hadoop/keepalived-1.2.19/
检查安装环境,并指定将来要安装的路径:
[root@master keepalived-1.2.19]# ./configure --prefix=/home/hadoop/keepalived
最后编译和安装:
[root@master keepalived-1.2.19]# make && make install
5:将Keepalived添加到系统服务中:
拷贝执行文件:
[root@master keepalived-1.2.19]# cp /home/hadoop/keepalived/sbin/keepalived /usr/sbin/
将init.d文件拷贝到etc下,加入开机启动项:
[root@master keepalived-1.2.19]# cp /home/hadoop/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/keepalived
将keepalived文件拷贝到etc下:
[root@master keepalived-1.2.19]# cp /home/hadoop/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
创建keepalived文件夹:
[root@master hadoop]# mkdir -p /etc/keepalived
将keepalived配置文件拷贝到etc下:
[root@master hadoop]# cp /home/hadoop/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
添加可执行权限:
[root@master hadoop]# chmod +x /etc/init.d/keepalived
添加keepalived到开机启动:
[root@master hadoop]# chkconfig --add keepalived
[root@master hadoop]# chkconfig keepalived on
6:配置keepalived虚拟IP:修改配置文件:
[root@master hadoop]# vim /etc/keepalived/keepalived.conf
这里配置虚拟Ip就开始分keepalived的master节点和keepalived的backup节点:
#master节点
vrrp_instance VI_1 {
state #主节点的优先级(1-254之间),备用节点必须比主节点优先级低
advert_int 1 #组播信息发送间隔,两个节点设置必须一样
authentication { #设置验证信息,两个节点必须一致
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #指定虚拟IP, 两个节点设置必须一样,
#如果两个nginx的ip分别是192.168.199.130,,...131,则此处的虚拟ip跟它俩同一个网段即可
192.168.199.141/24
}
}
配置好master节点以后,可以配置BACKUP节点:
vrrp_instance VI_1 {
state
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.199.141/24
}
}
7:分别启动两台机器上面的keepalived:
给一个虚拟机设置两个ip地址方法:
ip addr add 192.168.199.150 dev eth0
[root@master hadoop]# service keepalived start
最后测试一下:
如果杀掉master上的keepalived 进程,你会发现,在slaver即另外一台配置keepalived的机器上的eth0网卡多了一个ip地址
查看ip地址的命令:ip addr
这里测试的时候出现问题了,因为我的电脑安装的虚拟机都是同一个,所以第一台机器的ip配置在eth0,而其他的竟然配置在了eth1,而这里需要修改一下,ip所在的位置:
解决方法:
1:编辑/etc/udev/rules.d/70-persistent-net.rules,找到与ifconfig -a得出的MAC相同的一行(NAME='eth1'这一行),把它改为"NAME=eth0 ",然后把上面一行(NAME='eth0')删除掉。
vim /etc/udev/rules.d/70-persistent-net.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:bb:41:2b", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
2:编辑/etc/sysconfig/network-script/ifcfg-eth0,把MAC改为正确的,把UUID删掉。
3:编辑/etc/sysconf/network,把hostname也改一下。
4:重启生效!
8:配置keepalived心跳检查:
原理:
Keepalived并不跟nginx耦合,它俩完全不是一家人
但是keepalived提供一个机制:让用户自定义一个shell脚本去检测用户自己的程序,返回状态给keepalived就可以了;
master节点:
vrrp_instance VI_1 {
state MASTER #指定A节点为主节点 备用节点上设置为BACKUP即可
interface eth0 #绑定虚拟IP的网络接口
virtual_router_id 51 #VRRP组名,两个节点的设置必须一样,以指明各个节点属于同一VRRP组
priority 100 #主节点的优先级(1-254之间),备用节点必须比主节点优先级低
advert_int 1 #组播信息发送间隔,两个节点设置必须一样
authentication { #设置验证信息,两个节点必须一致
auth_type PASS
auth_pass 1111
}track_script { #跟踪用户程序脚本
chk_health
}virtual_ipaddress { #指定虚拟IP, 两个节点设置必须一样,
#如果两个nginx的ip分别是192.168.199.130,,...131,则此处的虚拟ip跟它俩同一个网段即可
192.168.199.141/24
}notify_master "/home/hadoop/keepalived/sbin/notify.sh master"
notify_backup "/home/hadoop/keepalived/sbin/notify.sh backup"
notify_fault "/home/hadoop/keepalived/sbin/notify.sh fault"}
添加切换通知脚本:
[root@master keepalived]# vim /home/hadoop/keepalived/sbin/notify.sh
#!/bin/bash
case "$1" in
master)
/home/hadoop/nginx/sbin/nginx
exit 0
;;
backup)/home/hadoop/nginx/sbin/nginx -s stop
/home/hadoop/nginx/sbin/nginx
exit 0
;;
fault)
/home/hadoop/nginx/sbin/nginx -s stop
exit 0
;;
*)
echo 'Usage: notify.sh {master|backup|fault}'
exit 1
;;
esac
添加执行权限:
[root@master keepalived]# chmod +x /home/hadoop/keepalived/sbin/notify.sh
然后配置一下slaver即另一台keepalived:
global_defs {
}
vrrp_script chk_health {
script "[[ `ps -ef | grep nginx | grep -v grep | wc -l` -ge 2 ]] && exit 0 || exit 1"
interval 1
weight -2
}vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 1
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_health
}
virtual_ipaddress {
192.168.199.141/24
}
notify_master "/home/hadoop/keepalived/sbin/notify.sh master"
notify_backup "/home/hadoop/keepalived/sbin/notify.sh backup"
notify_fault "/home/hadoop/keepalived/sbin/notify.sh fault"}
最后:
在第二台机器上添加notify.sh脚本
#分别在两台机器上启动keepalived
service keepalived start
chkconfig keepalived on
一脸懵逼学习keepalived(对Nginx进行热备)的更多相关文章
- Keepalived+LVS+nginx双机热备
Keepalived简介 什么是Keepalived呢,keepalived观其名可知,保持存活,在网络里面就是保持在线了, 也就是所谓的高可用或热备,用来防止单点故障的发生. Keepalived采 ...
- [笔记]使用Keepalived实现Nginx主从热备
HA(High Available), 高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点. 1.1. 高可靠软件keepalived keepaliv ...
- 如何使用keepalived实现nginx双机热备
1.linux安装方法:yum -y install keepalived 配置开机启动:sudo chkconfig keepalived on 查看keepalivede运行日志:/var/lo ...
- keepalived+nginx双机热备+负载均衡
Reference: http://blog.csdn.net/e421083458/article/details/30092795 keepalived+nginx双机热备+负载均衡 最近因业务扩 ...
- nginx+keepalived简单双机主从热备
双机主从热备概述 可以两台机子互为热备,平时各自负责各自的服务.在做上线更新的时候,关闭一台服务器的tomcat后,nginx自动把流量切换到另外一台服务的后备机子上,从而实现无痛更新,保持服务的持续 ...
- Mysql + keepalived 实现双主热备读写分离【转】
Mysql + keepalived 实现双主热备读写分离 2013年6月16日frankwong发表评论阅读评论 架构图 系统:CentOS6.4_X86_64软件版本:Mysql-5.6.12 ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- haproxy/nginx+keepalived负载均衡 双机热备 邮件报警 实战及常见问题
Haproxy 做http和tcp反向代理和负载均衡keepalived 为两台 Haproxy 服务器做高可用/主备切换.nginx 为内网服务器做正向代理,如果业务需求有变化,也可以部分替代 ...
- Nginx+keepalived 高可用双机热备(主从模式/双主模式)
基础介绍负载均衡技术对于一个网站尤其是大型网站的web服务器集群来说是至关重要的!做好负载均衡架构,可以实现故障转移和高可用环境,避免单点故障,保证网站健康持续运行. 关于负载均衡介绍,可以参考:li ...
随机推荐
- C++ 模式设计
只写了MinGw/Linux API部分.所有相关的代码都是参考C++ API C++ 11智能指针参考http://blog.csdn.net/zy19940906/article/details/ ...
- canner CMS 系统 (公司在台湾) https://www.canner.io/
canner CMS 系统 (公司在台湾) https://www.canner.io/ https://github.com/Canner/canner 一种创新的CMS构建方式,采用 Nodej ...
- C++ URLencode library
I need a library that can URLencode a string/char array. Now, I can hex encode an ASCII array like h ...
- 计算机中内存、cache和寄存器之间的关系及区别
1. 寄存器是中央处理器内的组成部份.寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令.数据和位址.在中央处理器的控制部件中,包含的寄存 器有指令寄存器(IR)和程序计数器(PC).在中央处理器 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
- 数据库join union 区别
join 是两张表做交连后里面条件相同的部分记录产生一个记录集,union是产生的两个记录集(字段要一样的)并在一起,成为一个新的记录集. 1.JOIN和UNION区别 join 是两张表做交连后里 ...
- oracle:10g下载地址(转载)
转载地址:http://www.veryhuo.com/a/view/177074.html Oracle 10g Database和Client多平台官方下载地址 http://www.veryhu ...
- 安装elasticsearch 5.x, 6.x 常见问题(坑)的解决
本人在elasticsearch 5.x, 6.x 安装过程中遇到了一些问题: 警告提示 [2016-11-06T16:27:21,712][WARN ][o.e.b.JNANatives ] una ...
- 在 Confluence 中启用 HTTP 响应压缩
Confluence 能够支持 HTTP 的 GZip 传输编码.这个意味着 Confluence 将可以把数据压缩后传输给用户,这种配置能够针对不稳定的互联网状态下的传输速度缓慢和不稳定并且能够降低 ...
- Maven集成SSM
目录 Maven 集成SSM 添加log4j配置文件 配置web.xml 添加编码过滤器 添加put和delete请求 配置springmvc.xml 配置文件上传 配置druid连接池信息 配置sq ...