ES异地双活方案
对于单机房而言,只要参考Elastic Search 官方文档,搭建一个集群即可,示意图如下:
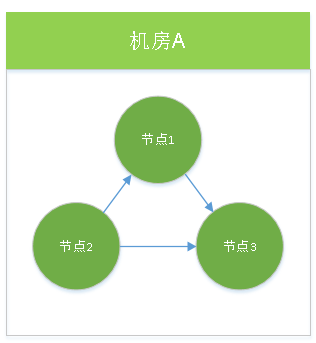
原理类似分布式选举那一套,当一个master节点宕机时,剩下2个投票选出1个新老大,整个集群可以继续服务。对于核心系统,只部署单机房总归有点不保险,万一单机房故障就废了(比如:断电断网、或光缆被挖断)。那有同学肯定会想,多弄几个机房,把集群中的节点分散到多个机房不就好了么?
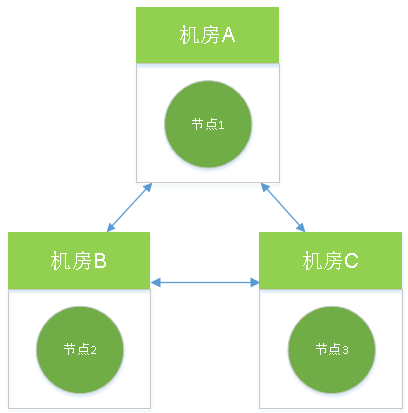
理论上讲,上面这种结构是可行的,但实际应用中,要考虑的因素会更多:
1、1个机房变3个机房,这成本就得翻好几倍了,回想一下mysql之类的解决方案,master-slave架构顶多放2个机房就可以了。
2、如果3个机房分属异地,比如:上海、广州、北京,三个城市间数据传输必然增加延时,要降低延时一般是拉专线,这样一方面成本还会继续增加,而且这么长距离传输,网络抖动是难免的,抖动期间,会增加选举"误切换"的概率。
3、3个节点之间不断的数据同步,会使三地机房间的网络流量增加,特别是某个节点挂了,重新恢复后,会在短时间内从master上同步数据,有流量风暴的隐患。
当然,官方有一个Cross Cluster Replication(CCR)的方案,架构示意图如下:
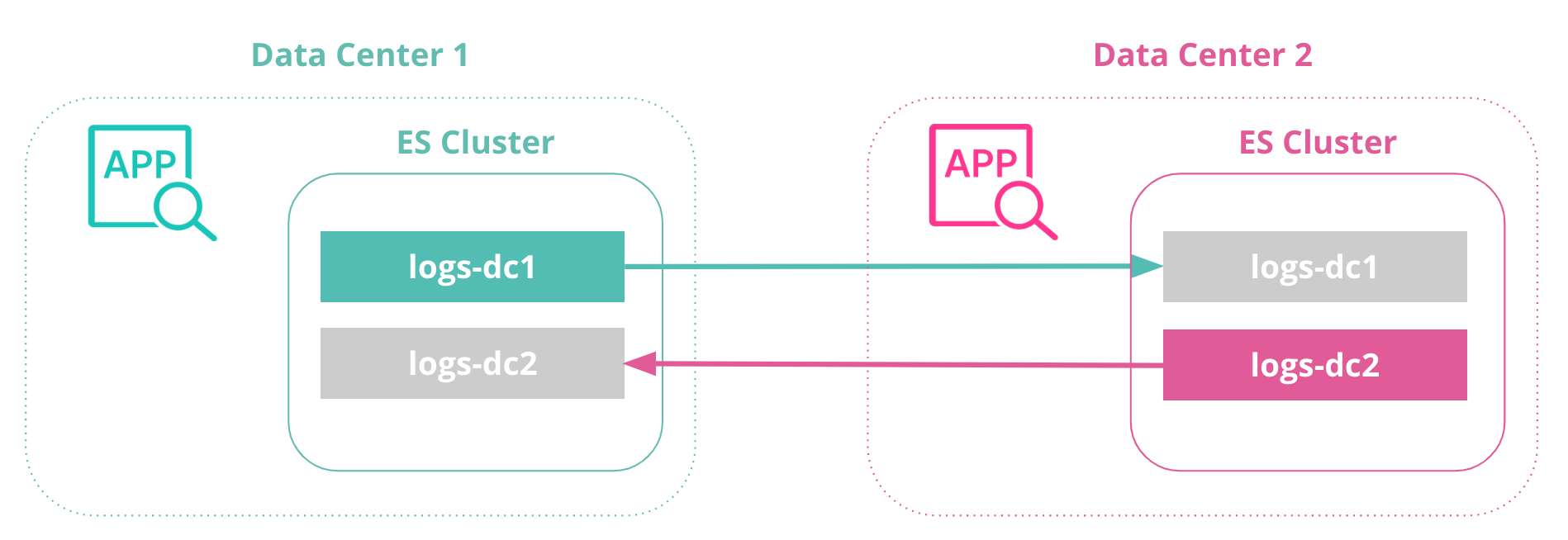
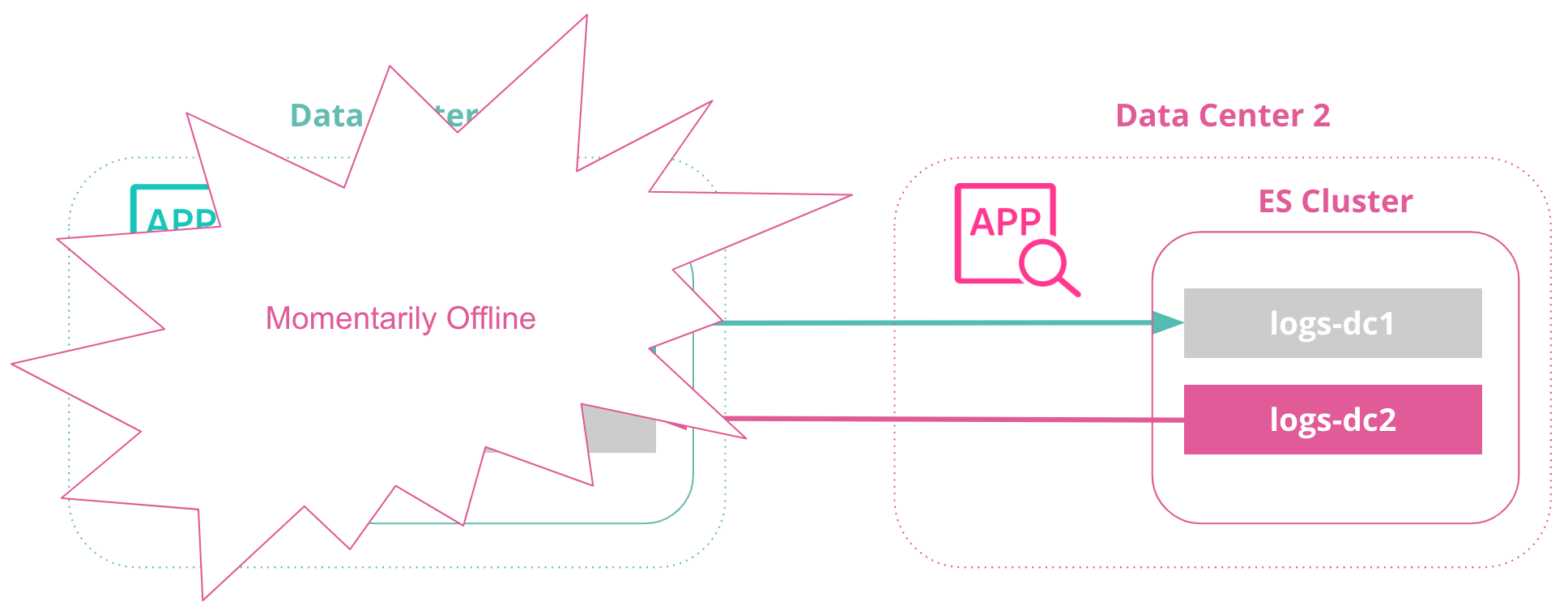
原理上讲,这其实也是把一个集群的节点分散部署在2个idc机房,另外,该方案并非免费午餐,官方的描述中,这是企业级的商业收费服务:

那么,普通屌丝公司有没有经济点的做法,即相对省钱,又能达到高可用呢?
圈内有一句名言:“没有什么是不能通过增加一个抽象层解决的,如果没有,就再加一层”。
我们把这个问题分解一下,无非就是“读”高可用,以及“写”高可用,先来看“读”:
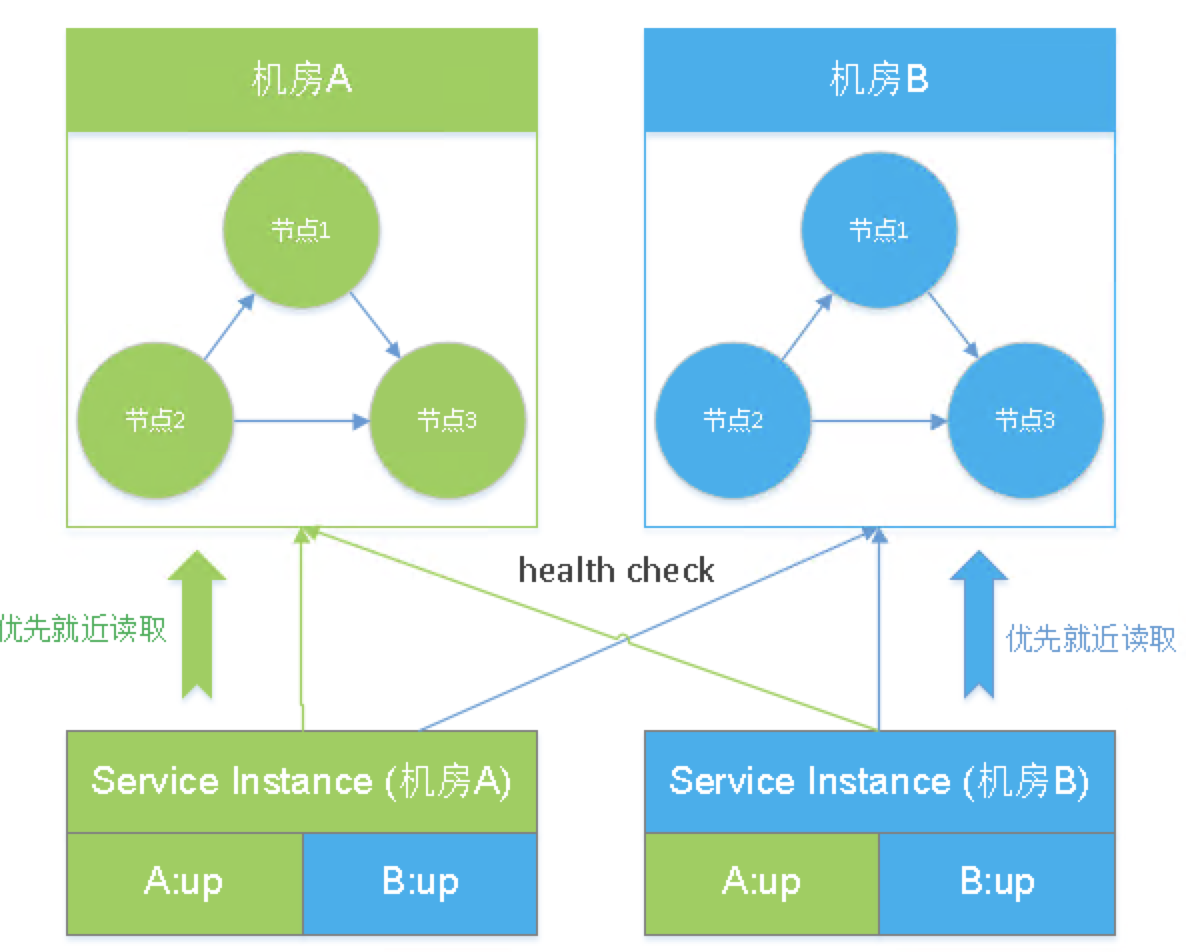
假设有2个机房A、B,每个机房各部署1个ES集群,然后有一个java服务,按现在流行的做法,不管是spring cloud也好,还是dubbo也罢,一般也是多机房部署,同样部署在A、B二个机房。可以在service内部引入一个检测机制,用2个线程,分别定时检测A、B二个机房的ES集群健康情况(类似心跳检测),然后把检测结果,写入java service实例的内部全局变量中,假设ES集群状态正常为up,如果挂了为down。这样每个机房的java service就能知道2个ES集群是否可用,然后结合自身所在的机房,优先就近访问(这1点不难做到,服务注册时,可以在meta data元数据里主动标识自身所属的ip,根据ip地址段,就能区分出所在机房)。即:如果A,B二个机房的ES集群都是up健康状态,A机房的java service访问同机房的ES实例,避免了跨机房调用。
当发生故障时,这里有2种情况,一种是某个机房的ES集群down了,但是该机房的java service还是正常的,类似下面:
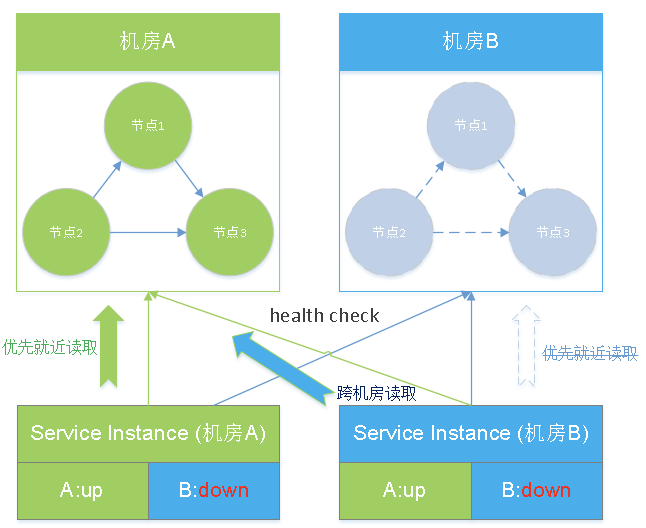
B机房的ES集群故障,这时候检查结果会标识B:down,B机房的java service此时知道本机房的ES集群有问题,退而求其次,访问另一侧机房的ES.
如果某一侧机房彻底挂了,比如:断电、断网。这时候,剩下一侧机房的java service仍然是优先访问同机房的ES,整个系统仍然可用。

解决了双机房ES"读"的问题,再来看“写”的问题,可能有同学说了,这还不简单,直接双写就行了吧,一份数据,向A、B机房的ES集群各写一份。听想来貌似可行,但是有一些细节问题 :
1、双写并非原子操作,如果A机房的ES集群写成功了,B机房的ES集群没写成功,该怎么办?
2、当B机房的ES挂了,双写不进去时,过一段时间又恢复后,故障期间的数据,B机房的ES集群怎么补进去?如果手动事后补数据,虽然可行,但是毕竟麻烦。
这里,可以引入一层MQ,类似下图这样:
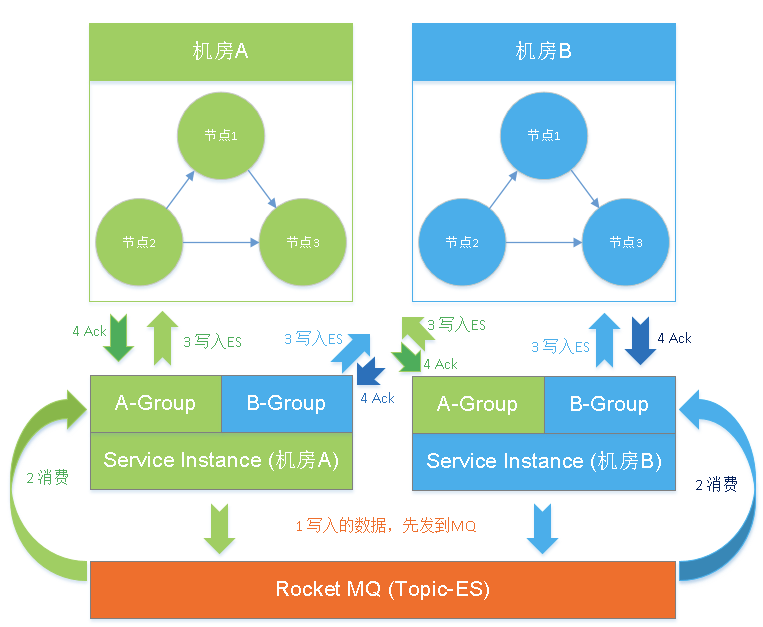
向ES写入的数据,先发到MQ,然后java service再消费这个Topic,要点在于,分成2个Consumer Group来消费,2个group分别对应于2侧的ES,即A-Group消费的Message,写入A机房的ES集群,B-Group消费的Message,写入B机房的ES集群。写入ES成功后,才Ack确认消费成功。由于2个group的消费是各自独立的(各自有各自的offset)。
当1侧ES down时,写入不成功,该Group的Message就不会Ack成功,一直压积着(而另1侧的group则不受影响),等ES恢复时,会继续消费,把故障期间的数据,自动补进去。这样就免去了事后手动补数据的麻烦。
当然,这个方案的提前是MQ本身是高可用的,不过这个不难做到,已经有一些rocket mq双机房多活的案例,不在本文讨论范围,大家可以自行搜索。
参考文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
https://zhuanlan.zhihu.com/p/82702078
ES异地双活方案的更多相关文章
- ES+Hbase对接方案概述
方案背景 Hbase的索引方案有很多,越来越多的人开始选择ES+Hbase的方案,其实该方案并没有想象中那么完美,ES并发低,同时查询速度相对Hbase也慢很多,那为什么会选择他呢,它的写入比较快,如 ...
- 571亿背后:DRC助阿里实现异地双活
571亿背后:DRC助阿里实现异地双活 赶集网SQL自动上线
- Mysql双活方案
#### 说明 Mysql主主互备即为两个mysql的互为备份机 ##### Windows下安装步骤(Linux下步骤类似,基本就是装上mysql,然后修改配置来完成主从的设置) - step1 ...
- ES数据同步方案
当业务量上升后,由于mysql对全文检索或模糊查询支持的能力不强,在系统中查询的地方,往往会出现慢sql等,拖累系统其他模块,造成性能低下. 随着ES使用普及率的升高,ES是mysql的一个有效补充. ...
- mysql异地备份方案经验总结
Mysql 数据库异地备份脚本 实验环境:关闭防火墙不然不能授权登录 Mysql-server:192.168.30.25 Mysql-client: 192.168.30.24 实验要求:对mys ...
- kafka 异步双活方案 mirror maker2 深度解析
mirror maker2背景 通常情况下,我们都是使用一套kafka集群处理业务.但有些情况需要使用另一套kafka集群来进行数据同步和备份.在kafka早先版本的时候,kafka针对这种场景就有推 ...
- 多es 集群数据迁移方案
前言 加入新公司的第二个星期的星期二 遇到另一个项目需要技术性支持:验证es多集群的数据备份方案,需要我参与验证,在这个项目中需要关注到两个集群的互通性.es集群是部署在不同的k8s环境中,K8s环境 ...
- mysql 架构 ~异地容灾
一 简介 我们来探讨下多机房下的mysql架构二 目的: 首先要清楚你的目的 1 实现异地机房的容灾备份 2 实现异地机房的双活 三 叙说 1 实现异地机房的容灾备份 ...
- MySQL两地三中心方案初步设计【转】
整体内容会按照如下的方式来进行设计: 首先说下方案的背景,我参考了一些资料(参见附件). 方案背景 随着互联网业务快速发展,多IDC的业务支撑能力和要求也逐步提升,行业内的“两地三中心”方案较为流行. ...
随机推荐
- 80个Python练手项目列表
80个Python练手项目列表 我若将死,给孩子留遗言,只留一句话:Repetition is the mother of all learning重复是学习之母.他们将来长大,学知识,技巧.爱情 ...
- Jmeter- 笔记3 - Jmeter录制功能 / 抓包
http代理服务器录制脚本: 1.新建线程组 2.添加 http代理服务器 元件 3.http代理服务器修改: 1)端口:8899,任意给个无占用的 2)目标控制器:改成刚刚新建的线程组.不改就录制会 ...
- 调试动态加载的js
用浏览器无法调试异步加载页面里包含的js文件.简单的说就是在调试工具里面看不到异步加载页面里包含的js文件 最近在一个新的web项目中开发功能.这个项目的管理界面有一个特点,框架是固定的,不会刷新 ...
- OSPF-三张表+路由器角色+router-id
验证理论: 1.剖析OSPF的三张表:邻居表,拓扑表,路由表 dis ospf peer brief dis ospf lsdb dis ip routing-table protocol ospf ...
- LeetCode 每日一题「判定字符是否唯一」
我是陈皮,一个在互联网 Coding 的 ITer,微信搜索「陈皮的JavaLib」第一时间阅读最新文章,回复[资料],即可获得我精心整理的技术资料,电子书籍,一线大厂面试资料和优秀简历模板. 题目 ...
- 一文带你了解.Net自旋锁
本文主要讲解.Net基于Thread实现自旋锁的三种方式 基于Thread.SpinWait实现自旋锁 实现原理:基于Test--And--Set原子操作实现 使用一个数据表示当前锁是否已经被获取 0 ...
- KIP-5:Apache Kylin深度集成Hudi
Q1. What are you trying to do? Articulate your objectives using absolutely no jargon. Q2. What probl ...
- 十亿级流量下,我与Redis时延小突刺的战斗史
一.背景 某一日收到上游调用方的反馈,提供的某一个Dubbo接口,每天在固定的时间点被短时间熔断,抛出的异常信息为提供方dubbo线程池被耗尽.当前dubbo接口日请求量18亿次,报错请求94W/天, ...
- Python常用数据结构(列表)
Python中常用的数据结构有序列(如列表,元组,字符串),映射(如字典)以及集合(set),是主要的三类容器 内容 序列的基本概念 列表的概念和用法 元组的概念和用法 字典的概念和用法 各类型之间的 ...
- Java并发之ReentrantLock源码解析(一)
ReentrantLock ReentrantLock是一种可重入的互斥锁,它的行为和作用与关键字synchronized有些类似,在并发场景下可以让多个线程按照一定的顺序访问同一资源.相比synch ...