SpringCloud升级之路2020.0.x版-31. FeignClient 实现断路器以及线程隔离限流的思路

在前面一节,我们实现了 FeignClient 粘合 resilience4j 的 Retry 实现重试。细心的读者可能会问,为何在这里的实现,不把断路器和线程限流一起加上呢:
@Bean
public FeignDecorators.Builder defaultBuilder(
Environment environment,
RetryRegistry retryRegistry
) {
//获取微服务名称
String name = environment.getProperty("feign.client.name");
Retry retry = null;
try {
retry = retryRegistry.retry(name, name);
} catch (ConfigurationNotFoundException e) {
retry = retryRegistry.retry(name);
}
//覆盖其中的异常判断,只针对 feign.RetryableException 进行重试,所有需要重试的异常我们都在 DefaultErrorDecoder 以及 Resilience4jFeignClient 中封装成了 RetryableException
retry = Retry.of(name, RetryConfig.from(retry.getRetryConfig()).retryOnException(throwable -> {
return throwable instanceof feign.RetryableException;
}).build());
return FeignDecorators.builder().withRetry(
retry
);
}
主要原因是,这里增加断路器以及线程隔离,其粒度是微服务级别的,这样的坏处是:
- 微服务中只要有一个实例一直异常,整个微服务就会被断路
- 微服务只要有一个方法一直异常,整个微服务就会被断路
- 微服务的某个实例比较慢,其他实例正常,但是轮询的负载均衡模式导致线程池被这个实例的请求堵满。由于这一个慢实例,倒是整个微服务的请求都被拖慢
回顾我们想要实现的微服务重试、断路、线程隔离
请求重试
来看几个场景:
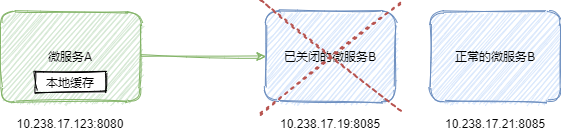
1.在线发布服务的时候,或者某个服务出现问题下线的时候,旧服务实例已经在注册中心下线并且实例已经关闭,但是其他微服务本地有服务实例缓存或者正在使用这个服务实例进行调用,这时候一般会因为无法建立 TCP 连接而抛出一个 java.io.IOException,不同框架使用的是这个异常的不同子异常,但是提示信息一般有 connect time out 或者 no route to host。这时候如果重试,并且重试的实例不是这个实例而是正常的实例,就能调用成功。如下图所示:
2.当调用一个微服务返回了非 2XX 的响应码:
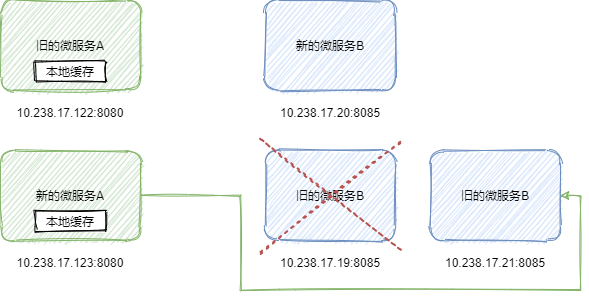
a) 4XX:在发布接口更新的时候,可能调用方和被调用方都需要发布。假设新的接口参数发生变化,没有兼容老的调用的时候,就会有异常,一般是参数错误,即返回 4XX 的响应码。例如新的调用方调用老的被调用方。针对这种情况,重试可以解决。但是为了保险,我们对于这种请求已经发出的,只重试 GET 方法(即查询方法,或者明确标注可以重试的非 GET 方法),对于非 GET 请求我们不重试。如下图所示:
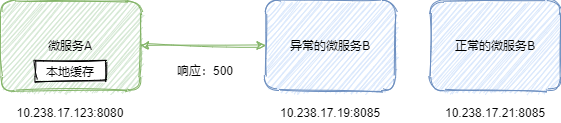
b) 5XX:当某个实例发生异常的时候,例如连不上数据库,JVM Stop-the-world 等等,就会有 5XX 的异常。针对这种情况,重试也可以解决。同样为了保险,我们对于这种请求已经发出的,只重试 GET 方法(即查询方法,或者明确标注可以重试的非 GET 方法),对于非 GET 请求我们不重试。如下图所示:
3.断路器打开的异常:后面我们会知道,我们的断路器是针对微服务某个实例某个方法级别的,如果抛出了断路器打开的异常,请求其实并没有发出去,我们可以直接重试。
4.限流异常:后面我们会知道,我们给调用每个微服务实例都做了单独的线程池隔离,如果线程池满了拒绝请求,会抛出限流异常,针对这种异常也需要直接重试。
这些场景在线上在线发布更新的时候,以及流量突然到来导致某些实例出现问题的时候,还是很常见的。如果没有重试,用户会经常看到异常页面,影响用户体验。所以这些场景下的重试还是很必要的。对于重试,我们使用 resilience4j 作为我们整个框架实现重试机制的核心。
微服务实例级别的线程隔离
再看下面一个场景:
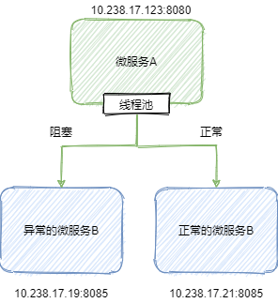
微服务 A 通过同一个线程池调用微服务 B 的所有实例。如果有一个实例有问题,阻塞了请求,或者是响应非常慢。那么久而久之,这个线程池会被发送到这个异常实例的请求而占满,但是实际上微服务 B 是有正常工作的实例的。
为了防止这种情况,也为了限制调用每个微服务实例的并发(也就是限流),我们使用不同线程池调用不同的微服务的不同实例。这个也是通过 resilience4j 实现的。
微服务实例方法粒度的断路器
如果一个实例在一段时间内压力过大导致请求慢,或者实例正在关闭,以及实例有问题导致请求响应大多是 500,那么即使我们有重试机制,如果很多请求都是按照请求到有问题的实例 -> 失败 -> 重试其他实例,这样效率也是很低的。这就需要使用断路器。
在实际应用中我们发现,大部分异常情况下,是某个微服务的某些实例的某些接口有异常,而这些问题实例上的其他接口往往是可用的。所以我们的断路器不能直接将这个实例整个断路,更不能将整个微服务断路。所以,我们使用 resilience4j 实现的是微服务实例方法级别的断路器(即不同微服务,不同实例的不同方法是不同的断路器)
使用 resilience4j 的断路器和线程限流器
下面我们先来看下断路器的相关配置,来理解下 resilience4j 断路器的原理:
//判断一个异常是否记录为断路器失败,默认所有异常都是失败,这个相当于黑名单
private Predicate<Throwable> recordExceptionPredicate = throwable -> true;
//判断一个返回对象是否记录为断路器失败,默认只要正常返回对象就不认为是失败
private transient Predicate<Object> recordResultPredicate = (Object object) -> false;
//判断一个异常是否可以不认为是断路器失败,默认所有异常都是失败,这个相当于白名单
private Predicate<Throwable> ignoreExceptionPredicate = throwable -> false;
//获取当前时间函数
private Function<Clock, Long> currentTimestampFunction = clock -> System.nanoTime();
//当前时间的单位
private TimeUnit timestampUnit = TimeUnit.NANOSECONDS;
//异常名单,指定一个 Exception 的 list,所有这个集合中的异常或者这些异常的子类,在调用的时候被抛出,都会被记录为失败。其他异常不会被认为是失败,或者在 ignoreExceptions 中配置的异常也不会被认为是失败。默认是所有异常都认为是失败。
private Class<? extends Throwable>[] recordExceptions = new Class[0];
//异常白名单,在这个名单中的所有异常及其子类,都不会认为是请求失败,就算在 recordExceptions 中配置了这些异常也没用。默认白名单为空。
private Class<? extends Throwable>[] ignoreExceptions = new Class[0];
//失败请求百分比,超过这个比例,`CircuitBreaker`就会变成`OPEN`状态,默认为 50%
private float failureRateThreshold = 50;
//当`CircuitBreaker`处于`HALF_OPEN`状态的时候,允许通过的请求数量
private int permittedNumberOfCallsInHalfOpenState = 10;
//滑动窗口大小,如果配置`COUNT_BASED`默认值100就代表是最近100个请求,如果配置`TIME_BASED`默认值100就代表是最近100s的请求。
private int slidingWindowSize = 100;
//滑动窗口类型,`COUNT_BASED`代表是基于计数的滑动窗口,`TIME_BASED`代表是基于计时的滑动窗口
private SlidingWindowType slidingWindowType = SlidingWindowType.COUNT_BASED;
//最小请求个数。只有在滑动窗口内,请求个数达到这个个数,才会触发`CircuitBreaker`对于是否打开断路器的判断。
private int minimumNumberOfCalls = 100;
//对应 RuntimeException 的 writableStackTrace 属性,即生成异常的时候,是否缓存异常堆栈
//断路器相关的异常都是继承 RuntimeException,这里统一指定这些异常的 writableStackTrace
//设置为 false,异常会没有异常堆栈,但是会提升性能
private boolean writableStackTraceEnabled = true;
//如果设置为`true`代表是否自动从`OPEN`状态变成`HALF_OPEN`,即使没有请求过来。
private boolean automaticTransitionFromOpenToHalfOpenEnabled = false;
//在断路器 OPEN 状态等待时间函数,默认是固定 60s,在等待与时间后,会退出 OPEN 状态
private IntervalFunction waitIntervalFunctionInOpenState = IntervalFunction.of(Duration.ofSeconds(60));
//当返回某些对象或者异常时,直接将状态转化为另一状态,默认是没有配置任何状态转换机制
private Function<Either<Object, Throwable>, TransitionCheckResult> transitionOnResult = any -> TransitionCheckResult.noTransition();
//当慢调用达到这个百分比的时候,`CircuitBreaker`就会变成`OPEN`状态
//默认情况下,慢调用不会导致`CircuitBreaker`就会变成`OPEN`状态,因为默认配置是百分之 100
private float slowCallRateThreshold = 100;
//慢调用时间,当一个调用慢于这个时间时,会被记录为慢调用
private Duration slowCallDurationThreshold = Duration.ofSeconds(60);
//`CircuitBreaker` 保持 `HALF_OPEN` 的时间。默认为 0, 即保持 `HALF_OPEN` 状态,直到 minimumNumberOfCalls 成功或失败为止。
private Duration maxWaitDurationInHalfOpenState = Duration.ofSeconds(0);
然后是线程隔离的相关配置:
//以下五个参数对应 Java 线程池的配置,我们这里就不再赘述了
private int maxThreadPoolSize = Runtime.getRuntime().availableProcessors();
private int coreThreadPoolSize = Runtime.getRuntime().availableProcessors();
private int queueCapacity = 100;
private Duration keepAliveDuration = Duration.ofMillis(20);
private RejectedExecutionHandler rejectedExecutionHandler = new ThreadPoolExecutor.AbortPolicy();
//对应 RuntimeException 的 writableStackTrace 属性,即生成异常的时候,是否缓存异常堆栈
//限流器相关的异常都是继承 RuntimeException,这里统一指定这些异常的 writableStackTrace
//设置为 false,异常会没有异常堆栈,但是会提升性能
private boolean writableStackTraceEnabled = true;
//Java 很多 Context 传递都基于 ThreadLocal,但是这里相当于切换线程了,某些任务需要维持上下文,可以通过实现 ContextPropagator 加入这里即可
private List<ContextPropagator> contextPropagators = new ArrayList<>();
在添加了上一节所说的 resilience4j-spring-cloud2 依赖之后,我们可以这样配置断路器和线程隔离:
resilience4j.circuitbreaker:
configs:
default:
registerHealthIndicator: true
slidingWindowSize: 10
minimumNumberOfCalls: 5
slidingWindowType: TIME_BASED
permittedNumberOfCallsInHalfOpenState: 3
automaticTransitionFromOpenToHalfOpenEnabled: true
waitDurationInOpenState: 2s
failureRateThreshold: 30
eventConsumerBufferSize: 10
recordExceptions:
- java.lang.Exception
resilience4j.thread-pool-bulkhead:
configs:
default:
maxThreadPoolSize: 50
coreThreadPoolSize: 10
queueCapacity: 1000
如何实现微服务实例方法粒度的断路器
我们要实现的是每个微服务的每个实例的每个方法都是不同的断路器,我们需要拿到:
- 微服务名
- 实例 ID,或者能唯一标识一个实例的字符串
- 方法名:可以是 URL 路径,或者是方法全限定名。
我们这里方法名采用的是方法全限定名称,而不是 URL 路径,因为有些 FeignClient 将参数放在了路径上面,例如使用 @PathVriable,如果参数是类似于用户 ID 这样的,那么一个用户就会有一个独立的断路器,这不是我们期望的。所以采用方法全限定名规避这个问题。
那么在哪里才能获取到这些呢?回顾下 FeignClient 的核心流程,我们发现需要在实际调用的时候,负载均衡器调用完成之后,才能获取到实例 ID。也就是在 org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient 调用完成之后。所以,我们在这里植入我们的断路器代码实现断路器。
另外就是配置粒度,可以每个 FeignClient 单独配置即可,不用到方法这一级别。举个例子如下:
resilience4j.circuitbreaker:
configs:
default:
slidingWindowSize: 10
feign-client-1:
slidingWindowSize: 100
下面这段代码,contextId 即 feign-client-1 这种,不同的微服务实例方法 serviceInstanceMethodId 不同。如果 contextId 对应的配置没找到,就会抛出 ConfigurationNotFoundException,这时候我们就读取并使用 default 配置。
try {
circuitBreaker = circuitBreakerRegistry.circuitBreaker(serviceInstanceMethodId, contextId);
} catch (ConfigurationNotFoundException e) {
circuitBreaker = circuitBreakerRegistry.circuitBreaker(serviceInstanceMethodId);
}
如何实现微服务实例线程限流器
对于线程隔离限流器,我们只需要微服务名和实例 ID,同时这些线程池只做调用,所以其实和断路器一样,可以放在 org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient 调用完成之后,植入线程限流器相关代码实现。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

SpringCloud升级之路2020.0.x版-31. FeignClient 实现断路器以及线程隔离限流的思路的更多相关文章
- SpringCloud升级之路2020.0.x版-30. FeignClient 实现重试
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 需要重试的场景 微服务系统中,会遇到在线发布,一般的发布更新策略是:启动一个新的,启动成功 ...
- SpringCloud升级之路2020.0.x版-32. 改进负载均衡算法
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在前面一节,我们梳理了实现 Feign 断路器以及线程隔离的思路,这一节,我们先不看如何源 ...
- SpringCloud升级之路2020.0.x版-33. 实现重试、断路器以及线程隔离源码
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在前面两节,我们梳理了实现 Feign 断路器以及线程隔离的思路,并说明了如何优化目前的负 ...
- SpringCloud升级之路2020.0.x版-1.背景
本系列为之前系列的整理重启版,随着项目的发展以及项目中的使用,之前系列里面很多东西发生了变化,并且还有一些东西之前系列并没有提到,所以重启这个系列重新整理下,欢迎各位留言交流,谢谢!~ Spring ...
- SpringCloud升级之路2020.0.x版-41. SpringCloudGateway 基本流程讲解(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 接下来,将进入我们升级之路的又一大模块,即网关模块.网关模块我们废弃了已经进入维护状态的 ...
- SpringCloud升级之路2020.0.x版-6.微服务特性相关的依赖说明
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford spring-cl ...
- SpringCloud升级之路2020.0.x版-10.使用Log4j2以及一些核心配置
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford 我们使用 Log4 ...
- SpringCloud升级之路2020.0.x版-29.Spring Cloud OpenFeign 的解析(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在使用云原生的很多微服务中,比较小规模的可能直接依靠云服务中的负载均衡器进行内部域名与服务 ...
- SpringCloud升级之路2020.0.x版-34.验证重试配置正确性(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在前面一节,我们利用 resilience4j 粘合了 OpenFeign 实现了断路器. ...
随机推荐
- python 文件夹扫描
扫描指定文件夹下的文件.或者匹配指定后缀和前缀的函数. 假设要扫描指定文件夹下的文件,包含子文件夹,调用scan_files("/export/home/test/") 假设要扫描 ...
- Python守护线程简述
thread模块不支持守护线程的概念,当主线程退出时,所有的子线程都将终止,不管它们是否仍在工作,如果你不希望发生这种行为,就要引入守护线程的概念. threading模块支持守护线程,其工作方式是: ...
- 鸿蒙内核源码分析(系统调用篇) | 开发者永远的口头禅 | 百篇博客分析OpenHarmony源码 | v37.03
百篇博客系列篇.本篇为: v37.xx 鸿蒙内核源码分析(系统调用篇) | 开发者永远的口头禅 | 51.c.h .o 任务管理相关篇为: v03.xx 鸿蒙内核源码分析(时钟任务篇) | 触发调度谁 ...
- docker 入门(docker 镜像 、容器、仓库)
一.关于docker 镜像 .容器.仓库之间的关系 镜像(Image): 类似于虚拟机 的镜像 容器(Container): 类似于操作系统(或者说是独立的软件), 由镜像可以创建大量的容器. 仓库( ...
- CF25E-Test【AC自动机,bfs】
正题 题目链接:https://www.luogu.com.cn/problem/CF25E 题目大意 给出三个串,然后求一个最短的串包含这三个串. \(1\leq |s_1|,|s_2|,|s_3| ...
- P4630-[APIO2018]Duathlon铁人两项【圆方树】
正题 题目链接:https://www.luogu.com.cn/problem/P4630 题目大意 \(n\)个点\(m\)条边的一张无向图,求有多少对三元组\((s,c,f)\)满足\(s\ne ...
- P2350-[HAOI2012]外星人【线性筛】
正题 题目链接:https://www.luogu.com.cn/problem/P2350 题目大意 给出\(N\)质因数分解之后的结果,求每次\(N=\varphi(N)\),多少次后\(N=1\ ...
- P3343-[ZJOI2015]地震后的幻想乡【dp,数学期望】
正题 题目链接:https://www.luogu.com.cn/problem/P3343 题目大意 给出\(n\)个点的一张无向图,每条边被修复的时间是\([0,1]\)的一个随机实数,求这张图联 ...
- MacOS下terminal防止ssh自动断开的方法和自动断开的原因
之前换了个工作环境,用terminal连接远程服务器的时候老是出现自动断开的情况,搞得我很是郁闷.因为之前在家的时候,并没有出现过类似情况.后来在网上找了很久,发现国外网站上有个大神说应该是有些路由器 ...
- Python3入门系列之-----环境搭建
前 言 最近一直在学习Python,想用笔记的方式记录自己踩过的那些坑.俗话说:好记性不如烂笔头. 分享给想学Python的小伙伴.目前本人在学习Python+selenium.接口自动化,有兴趣的 ...