Linux mem 2.6 Rmap 内存反向映射机制
文章目录
1. 简介
通常情况下用户态的虚拟地址和物理内存之间建立的是正向映射的关系:vma存储了虚拟地址 → 发生了page_fault以后分配物理内存page并且建立mmu映射。
但是在进行内存回收时,需要反向查找,根据目的物理内存 page,查找到所有映射到该内存的 vma 并进行映射关系的解除,才能回收对应的物理内存 page。
本节相当于 do_page_fault() 处理的一个详细解析,其中做了三件非常重要的事:
- 1、分配缺页需要的物理内存 page。
- 2、将新的 page 加入到 匿名/文件 反向映射中。
- 3、将新的 page 加入到 lru 链表中。
2. 匿名内存 Rmap 的建立

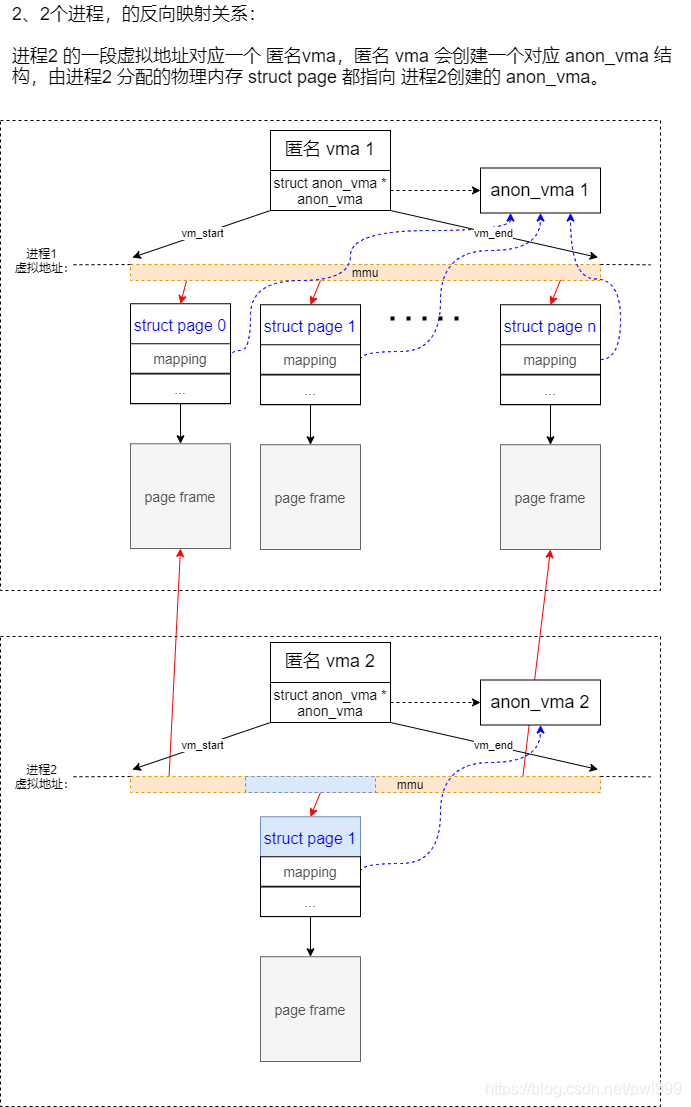
- (1) 本进程分配的物理内存 struct page 只会指向本进程 vma 对应的的 anon_vam。例如 进程1分配的物理内存 page 0-n 指向 anon_vma 1,进程2 分配的物理内存 struct page 1指向 anon_vma 2。
- (2) anon_vma 和 struct page 之间,是一对多的关系。
- (3) anon_vma 和 vma 之间,是多对多的关系:
- (3.1) 其中 一个 anon_vma 对应 多个 vma 的情况,例如:进程1 的 page 0 和 page 2-n 同时被 vma1 和 vma2 映射,那么 一个 anon_vma1 会对应 vma1 和 vma2.
- (3.2) 其中一个 vma 对应多个 anon_vma 的情况,例如:进程2 的 vma2,同时拥有 anon_vma1 和 anon_vma2 两种区域的物理内存。


2.1 fork()

如果进程2 fork() 创建了一个 进程3,开始的时候 进程3 完全复制 进程2 “匿名 vma2” 的映射:
1、首先复制 进程2 “匿名 vma2” 的 anon_vma_chain 链表 中所有映射的 anon_vma:

2、然后把 进程3 “匿名 vma3” 加到所有映射的 anon_vma 的红黑树中:

对应代码:
- 1、首先复制内核态的MMU映射关系。因为内核空间的映射是所有进程一样的,所以只是简单的重新分配了
pgd,而内核态对应的pgd entry和p4d→pud→pmd→pte之间的映射不变,直接拷贝旧pgd entry内容到新的pgd entry使其链接到旧的p4d即可:
sys_fork()→do_fork()→copy_process()→copy_mm()→dup_mm()→mm_init()→mm_alloc_pgd()→pgd_alloc():
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *pgd;
pmd_t *u_pmds[PREALLOCATED_USER_PMDS];
pmd_t *pmds[PREALLOCATED_PMDS];
/* (1) 分配 pgd 需要的内存空间 page */
pgd = _pgd_alloc();
if (pgd == NULL)
goto out;
mm->pgd = pgd;
/*
* Make sure that pre-populating the pmds is atomic with
* respect to anything walking the pgd_list, so that they
* never see a partially populated pgd.
*/
spin_lock(&pgd_lock);
/* (2) 初始化新的pgd */
pgd_ctor(mm, pgd);
pgd_prepopulate_pmd(mm, pgd, pmds);
pgd_prepopulate_user_pmd(mm, pgd, u_pmds);
spin_unlock(&pgd_lock);
return pgd;
}
↓
static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
{
/* If the pgd points to a shared pagetable level (either the
ptes in non-PAE, or shared PMD in PAE), then just copy the
references from swapper_pg_dir. */
if (CONFIG_PGTABLE_LEVELS == 2 ||
(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||
CONFIG_PGTABLE_LEVELS >= 4) {
/* (2.1) 拷贝内核态对应的 pgd entry */
clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,
swapper_pg_dir + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
}
/* list required to sync kernel mapping updates */
if (!SHARED_KERNEL_PMD) {
pgd_set_mm(pgd, mm);
pgd_list_add(pgd);
}
}
↓
static inline void clone_pgd_range(pgd_t *dst, pgd_t *src, int count)
{
/* (2.1.1) 把init_top_pgt中的page 0(内核态pgd)中的内核映射,
拷贝到新分配的pgd的page 0(内核态pgd)
*/
memcpy(dst, src, count * sizeof(pgd_t));
#ifdef CONFIG_PAGE_TABLE_ISOLATION
if (!static_cpu_has(X86_FEATURE_PTI))
return;
/* Clone the user space pgd as well */
/* (2.1.2) 把init_top_pgt中的page 1(用户态pgd)中的内核映射,
拷贝到新分配的pgd的page 1(内核态pgd)
注意这个内核映射是部分的临时的,仅供用户态切换内核态时临时使用
新进程没有拷贝父进程用户态的映射,而只是简单拷贝了它的vma红黑树
*/
memcpy(kernel_to_user_pgdp(dst), kernel_to_user_pgdp(src),
count * sizeof(pgd_t));
#endif
}
- 2、然后再2复制用户态的MMU映射关系。fork() 初始状态下子进程的映射关系和父进程是一样的,但是因为用户空间的映射是每个进程独立的并且需要处理复杂的 page_fault 和 relaim ,所以会重新复制
pgd→p4d→pud→pmd→pte的所有条目,如果对应的地址是私有可写的 (MAP_PRIVATE + VM_MAYWRITE) ,那么这段地址就是 COW(Copy On Write),在复制映射关系时需要把对应的父子进程 PTE 设置为 只读,这样任何的写操作都会触发 do_page_fault() 来分配新的内存 page :
sys_fork()→do_fork()→copy_process()→copy_mm()→dup_mm()→dup_mmap():
static __latent_entropy int dup_mmap(struct mm_struct *mm,
struct mm_struct *oldmm)
{
struct vm_area_struct *mpnt, *tmp, *prev, **pprev;
struct rb_node **rb_link, *rb_parent;
int retval;
unsigned long charge;
LIST_HEAD(uf);
/* (1) 遍历父进程的 vma 链表,进行以下行为:
1、复制 vma 内容。
2、创建新 vma 的反向映射。(包括文件映射vma和匿名vma)
3、复制每个 vma 对应的 mmu 映射。复制所有的 pgd→p4d→pud→pmd→pte 条目,并且对 私有可写区域设置 COW。
*/
for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) {
struct file *file;
/* (1.1) 复制vma的内容 */
tmp = vm_area_dup(mpnt);
if (!tmp)
goto fail_nomem;
retval = vma_dup_policy(mpnt, tmp);
if (retval)
goto fail_nomem_policy;
tmp->vm_mm = mm;
retval = dup_userfaultfd(tmp, &uf);
if (retval)
goto fail_nomem_anon_vma_fork;
if (tmp->vm_flags & VM_WIPEONFORK) {
/* VM_WIPEONFORK gets a clean slate in the child. */
tmp->anon_vma = NULL;
if (anon_vma_prepare(tmp))
goto fail_nomem_anon_vma_fork;
/* (1.2) 如果当前是匿名 vma ,新建新的 匿名 vma 反向映射 */
} else if (anon_vma_fork(tmp, mpnt))
goto fail_nomem_anon_vma_fork;
tmp->vm_flags &= ~(VM_LOCKED | VM_LOCKONFAULT);
tmp->vm_next = tmp->vm_prev = NULL;
file = tmp->vm_file;
if (file) {
struct inode *inode = file_inode(file);
struct address_space *mapping = file->f_mapping;
vma_get_file(tmp);
if (tmp->vm_flags & VM_DENYWRITE)
atomic_dec(&inode->i_writecount);
i_mmap_lock_write(mapping);
if (tmp->vm_flags & VM_SHARED)
atomic_inc(&mapping->i_mmap_writable);
flush_dcache_mmap_lock(mapping);
/* insert tmp into the share list, just after mpnt */
/* (1.3) 如果当前是文件映射vma,新建新的 文件 vma 反向映射 */
vma_interval_tree_insert_after(tmp, mpnt,
&mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
i_mmap_unlock_write(mapping);
}
/*
* Clear hugetlb-related page reserves for children. This only
* affects MAP_PRIVATE mappings. Faults generated by the child
* are not guaranteed to succeed, even if read-only
*/
if (is_vm_hugetlb_page(tmp))
reset_vma_resv_huge_pages(tmp);
/*
* Link in the new vma and copy the page table entries.
*/
*pprev = tmp;
pprev = &tmp->vm_next;
tmp->vm_prev = prev;
prev = tmp;
__vma_link_rb(mm, tmp, rb_link, rb_parent);
rb_link = &tmp->vm_rb.rb_right;
rb_parent = &tmp->vm_rb;
mm->map_count++;
/* (1.4) 复制vma 对应的 mmu 映射,包括所有的 pgd→p4d→pud→pmd→pte 条目,并且对 私有可写区域设置 COW */
if (!(tmp->vm_flags & VM_WIPEONFORK))
retval = copy_page_range(mm, oldmm, mpnt);
if (tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
if (retval)
goto out;
}
}
首先是复制创建 匿名 vma 的反向映射:
int anon_vma_fork(struct vm_area_struct *vma, struct vm_area_struct *pvma)
{
struct anon_vma_chain *avc;
struct anon_vma *anon_vma;
int error;
/* Don't bother if the parent process has no anon_vma here. */
/* (1.2.1) 如果父进程没有对应的 anon_vma ,直接返回 */
if (!pvma->anon_vma)
return 0;
/* Drop inherited anon_vma, we'll reuse existing or allocate new. */
/* (1.2.2) 首先丢弃掉继承的 anon_vma,使用已经存在的 或者 分配新的 anon_vma */
vma->anon_vma = NULL;
/*
* First, attach the new VMA to the parent VMA's anon_vmas,
* so rmap can find non-COWed pages in child processes.
*/
/* (1.2.3) 建立新的 vma 和 映射的内存对应的 anon_vma 之间的反向映射关系 */
error = anon_vma_clone(vma, pvma);
if (error)
return error;
/* An existing anon_vma has been reused, all done then. */
/* (1.2.3) vma->anon_vma 的作用是在本进程发生 page_fault() 而分配新的 page 时,用来给 page->mapping 成员赋值的
如果 vma 已经引用了一个已存在的 anon_vma,则直接返回 */
if (vma->anon_vma)
return 0;
/* Then add our own anon_vma. */
/* (1.2.4) 否则分配一个新的 anon_vma */
anon_vma = anon_vma_alloc();
if (!anon_vma)
goto out_error;
avc = anon_vma_chain_alloc(GFP_KERNEL);
if (!avc)
goto out_error_free_anon_vma;
/*
* The root anon_vma's spinlock is the lock actually used when we
* lock any of the anon_vmas in this anon_vma tree.
*/
anon_vma->root = pvma->anon_vma->root;
anon_vma->parent = pvma->anon_vma;
/*
* With refcounts, an anon_vma can stay around longer than the
* process it belongs to. The root anon_vma needs to be pinned until
* this anon_vma is freed, because the lock lives in the root.
*/
get_anon_vma(anon_vma->root);
/* Mark this anon_vma as the one where our new (COWed) pages go. */
vma->anon_vma = anon_vma;
anon_vma_lock_write(anon_vma);
anon_vma_chain_link(vma, avc, anon_vma);
anon_vma->parent->degree++;
anon_vma_unlock_write(anon_vma);
return 0;
out_error_free_anon_vma:
put_anon_vma(anon_vma);
out_error:
unlink_anon_vmas(vma);
return -ENOMEM;
}
↓
int anon_vma_clone(struct vm_area_struct *dst, struct vm_area_struct *src)
{
struct anon_vma_chain *avc, *pavc;
struct anon_vma *root = NULL;
/* (1.2.3.1) 遍历父进程 vma 的 vac 链表 */
list_for_each_entry_reverse(pavc, &src->anon_vma_chain, same_vma) {
struct anon_vma *anon_vma;
/* (1.2.3.1.1) 分配新的 vac 中介 */
avc = anon_vma_chain_alloc(GFP_NOWAIT | __GFP_NOWARN);
if (unlikely(!avc)) {
unlock_anon_vma_root(root);
root = NULL;
avc = anon_vma_chain_alloc(GFP_KERNEL);
if (!avc)
goto enomem_failure;
}
anon_vma = pavc->anon_vma;
/* (1.2.3.1.2) 通过新的vac,建立起新的:
1、将父进程 vma 链接的 anon_vma 加入子进程的 vma 链表
2、同时将新的 vma 加入所有链接 anon_vma 的红黑树
*/
root = lock_anon_vma_root(root, anon_vma);
anon_vma_chain_link(dst, avc, anon_vma);
/*
* Reuse existing anon_vma if its degree lower than two,
* that means it has no vma and only one anon_vma child.
* 如果anon_vma的深度低于2,则重用现有的anon_vma,这意味着它没有vma,只有一个子anon_vma。
*
* Do not chose parent anon_vma, otherwise first child
* will always reuse it. Root anon_vma is never reused:
* it has self-parent reference and at least one child.
* 不要选择父进程的anon_vma,否则第一个子进程将总是重用它。Root anon_vma永远不会被重用:它有自父引用和至少一个子引用。
*/
/* (1.2.3.1.2) 选择一个父进程以外的,且深度小于2的anon_vma作为当前的 vma->anon_vma
如果现有的找不到符合条件的,稍后新建一个
*/
if (!dst->anon_vma && anon_vma != src->anon_vma &&
anon_vma->degree < 2)
dst->anon_vma = anon_vma;
}
if (dst->anon_vma)
dst->anon_vma->degree++;
unlock_anon_vma_root(root);
return 0;
enomem_failure:
/*
* dst->anon_vma is dropped here otherwise its degree can be incorrectly
* decremented in unlink_anon_vmas().
* We can safely do this because callers of anon_vma_clone() don't care
* about dst->anon_vma if anon_vma_clone() failed.
*/
dst->anon_vma = NULL;
unlink_anon_vmas(dst);
return -ENOMEM;
}
↓
static void anon_vma_chain_link(struct vm_area_struct *vma,
struct anon_vma_chain *avc,
struct anon_vma *anon_vma)
{
avc->vma = vma;
avc->anon_vma = anon_vma;
/* (1.2.3.1.2.1) 将 anon_vma 加入到 vma 的引用链表 */
list_add(&avc->same_vma, &vma->anon_vma_chain);
/* (1.2.3.1.2.2) 将 vma 加入到 anon_vma 的红黑树 */
anon_vma_interval_tree_insert(avc, &anon_vma->rb_root);
}
然后是复制创建 文件 vma 的反向映射:
/* (1.3.1) 这个就非常简单,将新的 vma 加入到对应文件映射的反向映射树 mapping->i_mmap 中
并且加入的位置在父进程的vma之后
*/
vma_interval_tree_insert_after(tmp, mpnt,
&mapping->i_mmap);
最后是mmu 映射(包括所有的 pgd→p4d→pud→pmd→pte 条目)的复制。针对私有+可写的页面,对页面进行降级成只读:
copy_page_range()→copy_pud_range()→copy_pmd_range()→copy_pte_range()→copy_one_pte():
static inline unsigned long
copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma,
unsigned long addr, int *rss)
{
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
/* (1.4.1) 如果拷贝的是`私有+可写`的页面,对页面进行降级成只读。 */
if (is_cow_mapping(vm_flags)) {
ptep_set_wrprotect(src_mm, addr, src_pte);
pte = pte_wrprotect(pte);
}
}
static inline bool is_cow_mapping(vm_flags_t flags)
{
/* 没有设置共享即是私有,并设置了可写 */
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}
static inline pte_t pte_wrprotect(pte_t pte)
{
/* 清除pte中的写权限 */
return pte_clear_flags(pte, _PAGE_RW);
}
2.2 do_page_fault()
在 进程3 匿名vma3 复制 进程2 匿名vma2 的映射后,映射被设置成了 COW,在进程3 进行写操作时会触发 page_fault() 动作,分配实际的物理内存:


- 1、do_page_fault() 的总体处理流程如下:

对应代码:
do_page_fault() → __do_page_fault() → do_user_addr_fault() → handle_mm_fault() → __handle_mm_fault() → handle_pte_fault():
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
} else {
/* See comment in pte_alloc_one_map() */
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_sem read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic
* accesses. The code below just needs a consistent view
* for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier();
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
/* (1) 情况1:发生缺页地址对应的 MMU PTE 映射为空。
*/
if (!vmf->pte) {
/* (1.1) 情况1.1:匿名内存的第一次访问 */
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
/* (1.2) 情况1.2:文件内存的第一次访问。进一步细分:
情况1.2.1:读操作,do_read_fault()
情况1.2.2:私有文件写操作,do_cow_fault()
情况1.2.3:共享文件写操作,do_shared_fault()
*/
else
return do_fault(vmf);
}
/* (2) 情况2:发生缺页地址对应的 MMU PTE 映射不为空,但是 PTE 中的 present 位没有置位。
表明当前是匿名内存被swap出去的情况
*/
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
/* NUMA 自动平衡处理 */
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry)))
goto unlock;
if (vmf->flags & FAULT_FLAG_WRITE) {
/* (3) 情况3:发生缺页地址对应的 MMU PTE 映射不为空,PTE 中的 present 位也置位,只是PTE设置了写保护而当前是写操作。进一步细分:
情况3.1:文件共享内存写操作,writenotify功能,把共享文件映射降级成只读。
----fork()进程创建的私有文件映射COW。这里包括 文件内存 和 匿名内存。---
情况3.2:文件私有内存写操作,cow,分配新page并复制旧page的内容。
情况3.3:匿名内存写操作,cow,分配新page并复制旧page的内容。
*/
if (!pte_write(entry))
return do_wp_page(vmf);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
- 2、
情况1.1do_anonymous_page()
匿名内存的第一次访问触发的异常,处理流程如下:

具体代码如下:
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
/* File mapping without ->vm_ops ? */
if (vma->vm_flags & VM_SHARED)
return VM_FAULT_SIGBUS;
/*
* Use pte_alloc() instead of pte_alloc_map(). We can't run
* pte_offset_map() on pmds where a huge pmd might be created
* from a different thread.
*
* pte_alloc_map() is safe to use under down_write(mmap_sem) or when
* parallel threads are excluded by other means.
*
* Here we only have down_read(mmap_sem).
*/
/* (1.1.1) 首先分配一个 pte 结构 */
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
/* See the comment in pte_alloc_one_map() */
if (unlikely(pmd_trans_unstable(vmf->pmd)))
return 0;
/* Use the zero-page for reads */
/* (1.1.2) 如果当前是匿名内存的读操作,可以先映射一个公共的零内存 zero-page,实际的内存分配可以进一步推迟 */
if (!(vmf->flags & FAULT_FLAG_WRITE) &&
!mm_forbids_zeropage(vma->vm_mm)) {
entry = pte_mkspecial(pfn_pte(my_zero_pfn(vmf->address),
vma->vm_page_prot));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
if (!pte_none(*vmf->pte))
goto unlock;
ret = check_stable_address_space(vma->vm_mm);
if (ret)
goto unlock;
/* Deliver the page fault to userland, check inside PT lock */
if (userfaultfd_missing(vma)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
return handle_userfault(vmf, VM_UFFD_MISSING);
}
goto setpte;
}
/* Allocate our own private page. */
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/* (1.1.3) 不是匿名内存读操作,必须要分配实际的物理内存页 page 了 */
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
if (!page)
goto oom;
if (mem_cgroup_try_charge(page, vma->vm_mm, GFP_KERNEL, &memcg, false))
goto oom_free_page;
/*
* The memory barrier inside __SetPageUptodate makes sure that
* preceeding stores to the page contents become visible before
* the set_pte_at() write.
*/
/* (1.1.4) 设置 page 中的 PG_uptodate 标志 */
__SetPageUptodate(page);
/* (1.1.5) 根据 page 的物理地址计算出 pte entry 的值 */
entry = mk_pte(page, vma->vm_page_prot);
/* (1.1.5.1) 如果是写操作,设置 pte entry 中的写允许 bit */
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
/* (1.1.6) 获取到之前分配的 pte 地址 */
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
if (!pte_none(*vmf->pte))
goto release;
ret = check_stable_address_space(vma->vm_mm);
if (ret)
goto release;
/* Deliver the page fault to userland, check inside PT lock */
if (userfaultfd_missing(vma)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
mem_cgroup_cancel_charge(page, memcg, false);
put_page(page);
return handle_userfault(vmf, VM_UFFD_MISSING);
}
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
/* (1.1.7) 将新分配的物理内存 page 加入匿名反向映射 */
page_add_new_anon_rmap(page, vma, vmf->address, false);
mem_cgroup_commit_charge(page, memcg, false, false);
/* (1.1.8) 将新分配的物理内存 page 加入LRU链表 */
lru_cache_add_active_or_unevictable(page, vma);
setpte:
/* (1.1.9) 更新对应 pte entry */
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
/* No need to invalidate - it was non-present before */
/* (1.1.9.1) 刷新对应 tlb */
update_mmu_cache(vma, vmf->address, vmf->pte);
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return ret;
release:
mem_cgroup_cancel_charge(page, memcg, false);
put_page(page);
goto unlock;
oom_free_page:
put_page(page);
oom:
return VM_FAULT_OOM;
}
将新分配的物理内存加入匿名反向映射的处理:
page_add_new_anon_rmap() → __page_set_anon_rmap():
static void __page_set_anon_rmap(struct page *page,
struct vm_area_struct *vma, unsigned long address, int exclusive)
{
struct anon_vma *anon_vma = vma->anon_vma;
BUG_ON(!anon_vma);
if (PageAnon(page))
return;
/*
* If the page isn't exclusively mapped into this vma,
* we must use the _oldest_ possible anon_vma for the
* page mapping!
*/
if (!exclusive)
anon_vma = anon_vma->root;
/* (1.1.7.1) bit0 设置为 1,表明 page->mapping 存储的是匿名 anon_vma,而不是文件映射的 address_space */
anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON;
page->mapping = (struct address_space *) anon_vma;
/* (1.1.7.2) page->index 保存了当前虚拟地址在 vma 中的偏移 */
page->index = linear_page_index(vma, address);
}
- 3、
情况2do_swap_page()
匿名内存被回收到swap分区中以后,又一次访问触发的异常,处理流程如下:

具体代码如下:
int do_swap_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page = NULL, *swapcache = NULL;
struct mem_cgroup *memcg;
struct vma_swap_readahead swap_ra;
swp_entry_t entry;
pte_t pte;
int locked;
int exclusive = 0;
int ret = 0;
bool vma_readahead = swap_use_vma_readahead();
if (vma_readahead) {
page = swap_readahead_detect(vmf, &swap_ra);
swapcache = page;
}
if (!pte_unmap_same(vma->vm_mm, vmf->pmd, vmf->pte, vmf->orig_pte)) {
if (page)
put_page(page);
goto out;
}
/* (2.1) 如果 pte 存在,但是 present 位不为1,其中存储的是 swp_entry */
entry = pte_to_swp_entry(vmf->orig_pte);
if (unlikely(non_swap_entry(entry))) {
if (is_migration_entry(entry)) {
migration_entry_wait(vma->vm_mm, vmf->pmd,
vmf->address);
} else if (is_device_private_entry(entry)) {
/*
* For un-addressable device memory we call the pgmap
* fault handler callback. The callback must migrate
* the page back to some CPU accessible page.
*/
ret = device_private_entry_fault(vma, vmf->address, entry,
vmf->flags, vmf->pmd);
} else if (is_hwpoison_entry(entry)) {
ret = VM_FAULT_HWPOISON;
} else {
print_bad_pte(vma, vmf->address, vmf->orig_pte, NULL);
ret = VM_FAULT_SIGBUS;
}
goto out;
}
delayacct_set_flag(DELAYACCT_PF_SWAPIN);
/* (2.2) 尝试从 swap cache 中查找对应的物理内存 page */
if (!page) {
page = lookup_swap_cache(entry, vma_readahead ? vma : NULL,
vmf->address);
swapcache = page;
}
/* (2.3) 如果 swap cache 查找失败,需要重新分配物理内存 page */
if (!page) {
struct swap_info_struct *si = swp_swap_info(entry);
if (si->flags & SWP_SYNCHRONOUS_IO &&
__swap_count(si, entry) == 1) {
/* skip swapcache */
/* (2.3.1) 分配新的物理内存 page */
page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, vmf->address);
if (page) {
__SetPageLocked(page);
__SetPageSwapBacked(page);
set_page_private(page, entry.val);
/* (2.3.2) 加入到 lru cache 中 */
lru_cache_add_anon(page);
/* (2.3.3) 读取 swap 中备份的内容到新的 page 中 */
swap_readpage(page, true);
}
} else {
if (vma_readahead)
page = do_swap_page_readahead(entry,
GFP_HIGHUSER_MOVABLE, vmf, &swap_ra);
else
page = swapin_readahead(entry,
GFP_HIGHUSER_MOVABLE, vma, vmf->address);
swapcache = page;
}
if (!page) {
/*
* Back out if somebody else faulted in this pte
* while we released the pte lock.
*/
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
if (likely(pte_same(*vmf->pte, vmf->orig_pte)))
ret = VM_FAULT_OOM;
delayacct_clear_flag(DELAYACCT_PF_SWAPIN);
goto unlock;
}
/* Had to read the page from swap area: Major fault */
ret = VM_FAULT_MAJOR;
count_vm_event(PGMAJFAULT);
count_memcg_event_mm(vma->vm_mm, PGMAJFAULT);
} else if (PageHWPoison(page)) {
/*
* hwpoisoned dirty swapcache pages are kept for killing
* owner processes (which may be unknown at hwpoison time)
*/
ret = VM_FAULT_HWPOISON;
delayacct_clear_flag(DELAYACCT_PF_SWAPIN);
swapcache = page;
goto out_release;
}
locked = lock_page_or_retry(page, vma->vm_mm, vmf->flags);
delayacct_clear_flag(DELAYACCT_PF_SWAPIN);
if (!locked) {
ret |= VM_FAULT_RETRY;
goto out_release;
}
/*
* Make sure try_to_free_swap or reuse_swap_page or swapoff did not
* release the swapcache from under us. The page pin, and pte_same
* test below, are not enough to exclude that. Even if it is still
* swapcache, we need to check that the page's swap has not changed.
*/
if (unlikely((!PageSwapCache(page) ||
page_private(page) != entry.val)) && swapcache)
goto out_page;
page = ksm_might_need_to_copy(page, vma, vmf->address);
if (unlikely(!page)) {
ret = VM_FAULT_OOM;
page = swapcache;
goto out_page;
}
if (mem_cgroup_try_charge(page, vma->vm_mm, GFP_KERNEL,
&memcg, false)) {
ret = VM_FAULT_OOM;
goto out_page;
}
/*
* Back out if somebody else already faulted in this pte.
*/
/* (2.4) 获取到对应 pte 的条目地址 */
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
if (unlikely(!pte_same(*vmf->pte, vmf->orig_pte)))
goto out_nomap;
if (unlikely(!PageUptodate(page))) {
ret = VM_FAULT_SIGBUS;
goto out_nomap;
}
/*
* The page isn't present yet, go ahead with the fault.
*
* Be careful about the sequence of operations here.
* To get its accounting right, reuse_swap_page() must be called
* while the page is counted on swap but not yet in mapcount i.e.
* before page_add_anon_rmap() and swap_free(); try_to_free_swap()
* must be called after the swap_free(), or it will never succeed.
*/
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
dec_mm_counter_fast(vma->vm_mm, MM_SWAPENTS);
/* (2.5) 根据 page 的物理地址计算出 pte entry 的值 */
pte = mk_pte(page, vma->vm_page_prot);
if ((vmf->flags & FAULT_FLAG_WRITE) && reuse_swap_page(page, NULL)) {
pte = maybe_mkwrite(pte_mkdirty(pte), vma);
vmf->flags &= ~FAULT_FLAG_WRITE;
ret |= VM_FAULT_WRITE;
exclusive = RMAP_EXCLUSIVE;
}
flush_icache_page(vma, page);
if (pte_swp_soft_dirty(vmf->orig_pte))
pte = pte_mksoft_dirty(pte);
/* (2.6) 更新对应 pte entry */
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
/* ksm created a completely new copy */
if (unlikely(page != swapcache && swapcache)) {
/* (2.10.1) 将 page 加入匿名反向映射 */
page_add_new_anon_rmap(page, vma, vmf->address, false);
mem_cgroup_commit_charge(page, memcg, false, false);
/* (2.10.2) 将 page lru 链表 */
lru_cache_add_active_or_unevictable(page, vma);
} else {
/* (2.10.3) 将 page 加入匿名反向映射 */
do_page_add_anon_rmap(page, vma, vmf->address, exclusive);
mem_cgroup_commit_charge(page, memcg, true, false);
activate_page(page);
}
swap_free(entry);
if (mem_cgroup_swap_full(page) ||
(vma->vm_flags & VM_LOCKED) || PageMlocked(page))
try_to_free_swap(page);
unlock_page(page);
if (page != swapcache && swapcache) {
/*
* Hold the lock to avoid the swap entry to be reused
* until we take the PT lock for the pte_same() check
* (to avoid false positives from pte_same). For
* further safety release the lock after the swap_free
* so that the swap count won't change under a
* parallel locked swapcache.
*/
unlock_page(swapcache);
put_page(swapcache);
}
if (vmf->flags & FAULT_FLAG_WRITE) {
ret |= do_wp_page(vmf);
if (ret & VM_FAULT_ERROR)
ret &= VM_FAULT_ERROR;
goto out;
}
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, vmf->address, vmf->pte);
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
out:
return ret;
out_nomap:
mem_cgroup_cancel_charge(page, memcg, false);
pte_unmap_unlock(vmf->pte, vmf->ptl);
out_page:
unlock_page(page);
out_release:
put_page(page);
if (page != swapcache && swapcache) {
unlock_page(swapcache);
put_page(swapcache);
}
return ret;
}
- 4、
情况3.3do_wp_page()
匿名内存的 COW 页面的写异常,处理流程如下:

具体代码如下:
static int do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
/* (3.2.1) 根据 pte 找到对应的物理内存 page,大部分情况下是能找到的 */
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte);
if (!vmf->page) {
/*
* VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a
* VM_PFNMAP VMA.
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable and/or call ops->pfn_mkwrite.
*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
return wp_pfn_shared(vmf);
pte_unmap_unlock(vmf->pte, vmf->ptl);
return wp_page_copy(vmf);
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
/* (3.2.2) 情况3.3:匿名内存写操作,cow,分配新page并复制旧page的内容。
最终调用 wp_page_copy()
*/
if (PageAnon(vmf->page) && !PageKsm(vmf->page)) {
int total_map_swapcount;
if (!trylock_page(vmf->page)) {
get_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
lock_page(vmf->page);
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
if (!pte_same(*vmf->pte, vmf->orig_pte)) {
unlock_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
put_page(vmf->page);
return 0;
}
put_page(vmf->page);
}
if (reuse_swap_page(vmf->page, &total_map_swapcount)) {
if (total_map_swapcount == 1) {
/*
* The page is all ours. Move it to
* our anon_vma so the rmap code will
* not search our parent or siblings.
* Protected against the rmap code by
* the page lock.
*/
page_move_anon_rmap(vmf->page, vma);
}
unlock_page(vmf->page);
wp_page_reuse(vmf);
return VM_FAULT_WRITE;
}
unlock_page(vmf->page);
/* (3.2.3) 情况3.1:文件共享内存写操作,writenotify功能,把共享文件映射降级成只读。
最终调用 wp_page_shared()
*/
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
return wp_page_shared(vmf);
}
/* (3.2.4) 情况3.2:文件私有内存写操作,cow,分配新page并复制旧page的内容。
最终调用 wp_page_copy()
*/
/*
* Ok, we need to copy. Oh, well..
*/
get_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
return wp_page_copy(vmf);
}
其中 writenotify 功能依赖 wp_page_shared() 设置了 page 的 dirty 标志,并且把 pte 恢复成可写:
wp_page_shared() → wp_page_reuse():
static inline void wp_page_reuse(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page = vmf->page;
pte_t entry;
/*
* Clear the pages cpupid information as the existing
* information potentially belongs to a now completely
* unrelated process.
*/
if (page)
page_cpupid_xchg_last(page, (1 << LAST_CPUPID_SHIFT) - 1);
flush_cache_page(vma, vmf->address, pte_pfn(vmf->orig_pte));
entry = pte_mkyoung(vmf->orig_pte);
/* (3.2.3.1) 恢复 pte 的写权限 */
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
if (ptep_set_access_flags(vma, vmf->address, vmf->pte, entry, 1))
update_mmu_cache(vma, vmf->address, vmf->pte);
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
wp_page_shared() → fault_dirty_shared_page():
static void fault_dirty_shared_page(struct vm_area_struct *vma,
struct page *page)
{
struct address_space *mapping;
bool dirtied;
bool page_mkwrite = vma->vm_ops && vma->vm_ops->page_mkwrite;
/* (3.2.3.2) 设置 page 的 dirty 标志 PG_dirty */
dirtied = set_page_dirty(page);
VM_BUG_ON_PAGE(PageAnon(page), page);
/*
* Take a local copy of the address_space - page.mapping may be zeroed
* by truncate after unlock_page(). The address_space itself remains
* pinned by vma->vm_file's reference. We rely on unlock_page()'s
* release semantics to prevent the compiler from undoing this copying.
*/
mapping = page_rmapping(page);
unlock_page(page);
if ((dirtied || page_mkwrite) && mapping) {
/*
* Some device drivers do not set page.mapping
* but still dirty their pages
*/
balance_dirty_pages_ratelimited(mapping);
}
if (!page_mkwrite)
file_update_time(vma->vm_file);
}
COW 功能依赖 wp_page_copy() 分配新的 page 并拷贝旧 page 的内容:

static int wp_page_copy(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *mm = vma->vm_mm;
struct page *old_page = vmf->page;
struct page *new_page = NULL;
pte_t entry;
int page_copied = 0;
const unsigned long mmun_start = vmf->address & PAGE_MASK;
const unsigned long mmun_end = mmun_start + PAGE_SIZE;
struct mem_cgroup *memcg;
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/* (3.2.4.1) 分配新的物理内存 page */
if (is_zero_pfn(pte_pfn(vmf->orig_pte))) {
new_page = alloc_zeroed_user_highpage_movable(vma,
vmf->address);
if (!new_page)
goto oom;
} else {
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
if (!new_page)
goto oom;
/* (3.2.4.2) 复制旧 page 的内容 */
cow_user_page(new_page, old_page, vmf->address, vma);
}
if (mem_cgroup_try_charge(new_page, mm, GFP_KERNEL, &memcg, false))
goto oom_free_new;
__SetPageUptodate(new_page);
mmu_notifier_invalidate_range_start(mm, mmun_start, mmun_end);
/*
* Re-check the pte - we dropped the lock
*/
/* (3.2.4.3) 获得 pte entry 的地址 */
vmf->pte = pte_offset_map_lock(mm, vmf->pmd, vmf->address, &vmf->ptl);
if (likely(pte_same(*vmf->pte, vmf->orig_pte))) {
if (old_page) {
if (!PageAnon(old_page)) {
dec_mm_counter_fast(mm,
mm_counter_file(old_page));
inc_mm_counter_fast(mm, MM_ANONPAGES);
}
} else {
inc_mm_counter_fast(mm, MM_ANONPAGES);
}
flush_cache_page(vma, vmf->address, pte_pfn(vmf->orig_pte));
/* (3.2.4.3) 根据新的 page 地址,计算 pte entry 的值 */
entry = mk_pte(new_page, vma->vm_page_prot);
/* (3.2.4.4) 给新的 pte entry 设置写权限 */
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/*
* Clear the pte entry and flush it first, before updating the
* pte with the new entry. This will avoid a race condition
* seen in the presence of one thread doing SMC and another
* thread doing COW.
*/
ptep_clear_flush_notify(vma, vmf->address, vmf->pte);
/* (3.2.4.5) 将新的 page 加入 匿名反向映射 */
page_add_new_anon_rmap(new_page, vma, vmf->address, false);
mem_cgroup_commit_charge(new_page, memcg, false, false);
/* (3.2.4.6) 将新的 page 加入 lru 链表 */
lru_cache_add_active_or_unevictable(new_page, vma);
/*
* We call the notify macro here because, when using secondary
* mmu page tables (such as kvm shadow page tables), we want the
* new page to be mapped directly into the secondary page table.
*/
/* (3.2.4.7) 更新 pte 和 tlb */
set_pte_at_notify(mm, vmf->address, vmf->pte, entry);
update_mmu_cache(vma, vmf->address, vmf->pte);
if (old_page) {
/*
* Only after switching the pte to the new page may
* we remove the mapcount here. Otherwise another
* process may come and find the rmap count decremented
* before the pte is switched to the new page, and
* "reuse" the old page writing into it while our pte
* here still points into it and can be read by other
* threads.
*
* The critical issue is to order this
* page_remove_rmap with the ptp_clear_flush above.
* Those stores are ordered by (if nothing else,)
* the barrier present in the atomic_add_negative
* in page_remove_rmap.
*
* Then the TLB flush in ptep_clear_flush ensures that
* no process can access the old page before the
* decremented mapcount is visible. And the old page
* cannot be reused until after the decremented
* mapcount is visible. So transitively, TLBs to
* old page will be flushed before it can be reused.
*/
/* (3.2.4.8) 将旧的 page 移除 匿名反向映射 */
page_remove_rmap(old_page, false);
}
/* Free the old page.. */
new_page = old_page;
page_copied = 1;
} else {
mem_cgroup_cancel_charge(new_page, memcg, false);
}
if (new_page)
put_page(new_page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
/*
* No need to double call mmu_notifier->invalidate_range() callback as
* the above ptep_clear_flush_notify() did already call it.
*/
mmu_notifier_invalidate_range_only_end(mm, mmun_start, mmun_end);
/* (3.2.4.9) 如有可能,释放旧的 page */
if (old_page) {
/*
* Don't let another task, with possibly unlocked vma,
* keep the mlocked page.
*/
if (page_copied && (vma->vm_flags & VM_LOCKED)) {
lock_page(old_page); /* LRU manipulation */
if (PageMlocked(old_page))
munlock_vma_page(old_page);
unlock_page(old_page);
}
put_page(old_page);
}
return page_copied ? VM_FAULT_WRITE : 0;
oom_free_new:
put_page(new_page);
oom:
if (old_page)
put_page(old_page);
return VM_FAULT_OOM;
}
3. 文件内存 Rmap 的建立

文件映射的反向映射比较简单,所有映射了文件缓冲的 vma 加入到同一颗反向查找树 address_space->i_mmmap 中,vma->vm_pgoff 指定了在文件中的偏移。
3.1 fork()
sys_fork()→do_fork()→copy_process()→copy_mm()→dup_mm()→dup_mmap():
static __latent_entropy int dup_mmap(struct mm_struct *mm,
struct mm_struct *oldmm)
{
/* (1) 遍历父进程的 vma 链表,进行以下行为:
1、复制 vma 内容。
2、创建新 vma 的反向映射。(包括文件映射vma和匿名vma)
3、复制每个 vma 对应的 mmu 映射。复制所有的 pgd→p4d→pud→pmd→pte 条目,并且对 私有可写区域设置 COW。
*/
for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) {
struct file *file;
/* (1.1) 复制vma的内容 */
tmp = vm_area_dup(mpnt);
if (!tmp)
goto fail_nomem;
retval = vma_dup_policy(mpnt, tmp);
if (retval)
goto fail_nomem_policy;
tmp->vm_mm = mm;
retval = dup_userfaultfd(tmp, &uf);
if (retval)
goto fail_nomem_anon_vma_fork;
if (tmp->vm_flags & VM_WIPEONFORK) {
/* VM_WIPEONFORK gets a clean slate in the child. */
tmp->anon_vma = NULL;
if (anon_vma_prepare(tmp))
goto fail_nomem_anon_vma_fork;
/* (1.2) 如果当前是匿名 vma ,新建新的 匿名 vma 反向映射 */
} else if (anon_vma_fork(tmp, mpnt))
goto fail_nomem_anon_vma_fork;
tmp->vm_flags &= ~(VM_LOCKED | VM_LOCKONFAULT);
tmp->vm_next = tmp->vm_prev = NULL;
file = tmp->vm_file;
if (file) {
struct inode *inode = file_inode(file);
struct address_space *mapping = file->f_mapping;
vma_get_file(tmp);
if (tmp->vm_flags & VM_DENYWRITE)
atomic_dec(&inode->i_writecount);
i_mmap_lock_write(mapping);
if (tmp->vm_flags & VM_SHARED)
atomic_inc(&mapping->i_mmap_writable);
flush_dcache_mmap_lock(mapping);
/* insert tmp into the share list, just after mpnt */
/* (1.3) 如果当前是文件映射vma,新建新的 文件 vma 反向映射 */
vma_interval_tree_insert_after(tmp, mpnt,
&mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
i_mmap_unlock_write(mapping);
}
}
}
↓
/* (1.3.1) 这个就非常简单,将新的 vma 加入到对应文件映射的反向映射树 mapping->i_mmap 中
并且加入的位置在父进程的vma之后
*/
vma_interval_tree_insert_after(tmp, mpnt,
&mapping->i_mmap);
3.2 do_page_fault()
- 1、
情况1.2do_fault()

static int do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *vm_mm = vma->vm_mm;
int ret;
/*
* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND
*/
if (!vma->vm_ops->fault) {
/*
* If we find a migration pmd entry or a none pmd entry, which
* should never happen, return SIGBUS
*/
if (unlikely(!pmd_present(*vmf->pmd)))
ret = VM_FAULT_SIGBUS;
else {
vmf->pte = pte_offset_map_lock(vmf->vma->vm_mm,
vmf->pmd,
vmf->address,
&vmf->ptl);
/*
* Make sure this is not a temporary clearing of pte
* by holding ptl and checking again. A R/M/W update
* of pte involves: take ptl, clearing the pte so that
* we don't have concurrent modification by hardware
* followed by an update.
*/
if (unlikely(pte_none(*vmf->pte)))
ret = VM_FAULT_SIGBUS;
else
ret = VM_FAULT_NOPAGE;
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
/* (1.2.1) 情况1.2.1:读操作,do_read_fault() */
} else if (!(vmf->flags & FAULT_FLAG_WRITE))
ret = do_read_fault(vmf);
/* (1.2.2) 情况1.2.2:私有文件写操作,do_cow_fault() */
else if (!(vma->vm_flags & VM_SHARED))
ret = do_cow_fault(vmf);
/* (1.2.3) 情况1.2.3:共享文件写操作,do_shared_fault() */
else
ret = do_shared_fault(vmf);
/* preallocated pagetable is unused: free it */
if (vmf->prealloc_pte) {
pte_free(vm_mm, vmf->prealloc_pte);
vmf->prealloc_pte = NULL;
}
return ret;
}
|→
static int do_read_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret = 0;
/*
* Let's call ->map_pages() first and use ->fault() as fallback
* if page by the offset is not ready to be mapped (cold cache or
* something).
*/
if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) {
ret = do_fault_around(vmf);
if (ret)
return ret;
}
/* (1.2.1.1) 分配 page,读取文件中的内容,并且加入到 address_space 缓存树 */
ret = __do_fault(vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
/* (1.2.1.2) 将 page 和 虚拟地址之间 建立 mmu 映射
将 page 加入反向映射
将 page 加入 lru 链表
*/
ret |= finish_fault(vmf);
unlock_page(vmf->page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
put_page(vmf->page);
return ret;
}
|→
static int do_cow_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
if (unlikely(anon_vma_prepare(vma)))
return VM_FAULT_OOM;
/* (1.2.2.1) 分配 cow page */
vmf->cow_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, vmf->address);
if (!vmf->cow_page)
return VM_FAULT_OOM;
if (mem_cgroup_try_charge(vmf->cow_page, vma->vm_mm, GFP_KERNEL,
&vmf->memcg, false)) {
put_page(vmf->cow_page);
return VM_FAULT_OOM;
}
/* (1.2.2.2) 分配 page,读取文件中的内容,并且加入到 address_space 缓存树 */
ret = __do_fault(vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
if (ret & VM_FAULT_DONE_COW)
return ret;
/* (1.2.2.3) 拷贝 file cache page 内容到 cow page */
copy_user_highpage(vmf->cow_page, vmf->page, vmf->address, vma);
__SetPageUptodate(vmf->cow_page);
/* (1.2.1.4) 将 cow page 和 虚拟地址之间 建立 mmu 映射
将 cow page 加入反向映射
将 cow page 加入 lru 链表
*/
ret |= finish_fault(vmf);
unlock_page(vmf->page);
put_page(vmf->page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
return ret;
uncharge_out:
mem_cgroup_cancel_charge(vmf->cow_page, vmf->memcg, false);
put_page(vmf->cow_page);
return ret;
}
|→
static int do_shared_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret, tmp;
/* (1.2.3.1) 分配 page,读取文件中的内容,并且加入到 address_space 缓存树 */
ret = __do_fault(vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
/*
* Check if the backing address space wants to know that the page is
* about to become writable
*/
/* (1.2.3.2) vma->vm_ops->page_mkwrite() */
if (vma->vm_ops->page_mkwrite) {
unlock_page(vmf->page);
tmp = do_page_mkwrite(vmf);
if (unlikely(!tmp ||
(tmp & (VM_FAULT_ERROR | VM_FAULT_NOPAGE)))) {
put_page(vmf->page);
return tmp;
}
}
/* (1.2.3.3) 将 page 和 虚拟地址之间 建立 mmu 映射
将 page 加入反向映射
将 page 加入 lru 链表
*/
ret |= finish_fault(vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE |
VM_FAULT_RETRY))) {
unlock_page(vmf->page);
put_page(vmf->page);
return ret;
}
/* (1.2.3.4) 设置 page 的 dirty 标志 PG_dirty */
fault_dirty_shared_page(vma, vmf->page);
return ret;
}
- 2、
情况3.1/3.2do_wp_page()
这部分的处理流程和代码在上一节的匿名内存中已经分析了。
3. Rmap 的查找
反向映射的遍历方法:
void rmap_walk(struct page *page, struct rmap_walk_control *rwc)
{
if (unlikely(PageKsm(page)))
/* (1) KSM 内存的反向映射遍历 */
rmap_walk_ksm(page, rwc);
else if (PageAnon(page))
/* (2) 匿名内存的反向映射遍历 */
rmap_walk_anon(page, rwc, false);
else
/* (3) 文件内存的反向映射遍历 */
rmap_walk_file(page, rwc, false);
}
|→
static void rmap_walk_anon(struct page *page, struct rmap_walk_control *rwc,
bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff_start, pgoff_end;
struct anon_vma_chain *avc;
/* (2.1) 找到 page 对应的 anon_vma 结构 */
if (locked) {
anon_vma = page_anon_vma(page);
/* anon_vma disappear under us? */
VM_BUG_ON_PAGE(!anon_vma, page);
} else {
anon_vma = rmap_walk_anon_lock(page, rwc);
}
if (!anon_vma)
return;
/* (2.2) 计算 page 在vma中的偏移 pgoff */
pgoff_start = page_to_pgoff(page);
pgoff_end = pgoff_start + hpage_nr_pages(page) - 1;
/* (2.3) 逐个遍历 anon_vma 树中符合条件的 vma */
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root,
pgoff_start, pgoff_end) {
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(page, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(page, vma, address, rwc->arg))
break;
if (rwc->done && rwc->done(page))
break;
}
if (!locked)
anon_vma_unlock_read(anon_vma);
}
|→
static void rmap_walk_file(struct page *page, struct rmap_walk_control *rwc,
bool locked)
{
/* (3.1) 找到 page 对应的 address_space mapping 结构 */
struct address_space *mapping = page_mapping(page);
pgoff_t pgoff_start, pgoff_end;
struct vm_area_struct *vma;
/*
* The page lock not only makes sure that page->mapping cannot
* suddenly be NULLified by truncation, it makes sure that the
* structure at mapping cannot be freed and reused yet,
* so we can safely take mapping->i_mmap_rwsem.
*/
VM_BUG_ON_PAGE(!PageLocked(page), page);
if (!mapping)
return;
/* (3.2) 计算 page 在文件中的偏移 pgoff */
pgoff_start = page_to_pgoff(page);
pgoff_end = pgoff_start + hpage_nr_pages(page) - 1;
if (!locked)
i_mmap_lock_read(mapping);
/* (3.3) 逐个遍历 mapping 树中符合条件的 vma */
vma_interval_tree_foreach(vma, &mapping->i_mmap,
pgoff_start, pgoff_end) {
unsigned long address = vma_address(page, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(page, vma, address, rwc->arg))
goto done;
if (rwc->done && rwc->done(page))
goto done;
}
done:
if (!locked)
i_mmap_unlock_read(mapping);
}
参考文档:
1.linux内存源码分析 - 内存回收(lru链表)
2.linux内存源码分析 - 内存回收(匿名页反向映射)
3.linux内存源码分析 - 内存碎片整理(实现流程)
4.linux内存源码分析 - 内存碎片整理(同步关系)
5.page reclaim 参数
6.kernel-4.9内存回收核心流程
7.Linux内存管理 (21)OOM
8.linux内核page结构体的PG_referenced和PG_active标志
9.Linux中的内存回收[一]
10.Page 页帧管理详解
Linux mem 2.6 Rmap 内存反向映射机制的更多相关文章
- Linux mem 2.5 Buddy 内存回收机制
文章目录 1. 简介 2. LRU 组织 2.1 LRU 链表 2.2 LRU Cache 2.3 LRU 移动操作 2.3.1 page 加入 LRU 2.3.2 其他 LRU 移动操作 3. LR ...
- Linux mem 2.4 Buddy 内存管理机制
文章目录 1. Buddy 简介 2. Buddy 初始化 2.1 Struct Page 初始化 2.2 Buddy 初始化 3. 内存释放 4. 内存分配 4.1 gfp_mask 4.2 nod ...
- Linux Mem (目录)
1.用户态相关: 1.1.用户态进程空间的创建 - execve() 详解 1.2.用户态进程空间的映射 - mmap()详解 1.3.分页寻址(Paging/MMU)机制详解 2.内核态相关: 2. ...
- Linux 匿名页的反向映射
我们知道LINUX的内存管理系统中有"反向映射"这一说,目的是为了快速去查找出一个特定的物理页在哪些进程中被映射到了什么地址,这样如果我们想把这一页换出(SWAP),或是迁移(Mi ...
- Linux内存管理 (12)反向映射RMAP
专题:Linux内存管理专题 关键词:RMAP.VMA.AV.AVC. 所谓反向映射是相对于从虚拟地址到物理地址的映射,反向映射是从物理页面到虚拟地址空间VMA的反向映射. RMAP能否实现的基础是通 ...
- linux内存源码分析 - 内存回收(匿名页反向映射)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 看完了内存压缩,最近在看内存回收这块的代码,发现内容有些多,需要分几块去详细说明,首先先说说匿名页的反向映 ...
- 在 linux x86-32 模式下分析内存映射流程
前言 虚拟内存机制已经成为了现代操作系统所不可缺少的一部分, 不仅可以为每个程序提供独立的地址空间保证安全性,更可以通过和磁盘的内存交换来提高内存的使用效率.虚拟内存管理作为linux 上的重要组成部 ...
- linux arm的高端内存映射
linux arm的高端内存映射(1) vmalloc 高端内存映射 与高端映射对立的是低端映射或所谓直接映射,内核中有关变量定义它们的它们的分界点,全局变量high_memory,该变量定义在m ...
- 在 linux x86-64 模式下分析内存映射流程
前言 在上一篇中我们分析了 linux 在 x86-32 模式下的虚拟内存映射流程,本章主要继续分析 linux 在 x86-64 模式下的虚拟内存映射流程. 讨论的平台是 x86-64, 也可以称为 ...
随机推荐
- AT2368-[AGC013B]Hamiltonish Path【构造】
正题 题目链接:https://www.luogu.com.cn/problem/AT2368 题目大意 给出 \(n\) 个点 \(m\) 条边的一张无向图,然后求一条路径满足 路径长度不小于二. ...
- 小白学习Python英语基础差怎么办,都帮你想好拉!看这里
运算符与随机数 1.module:模块 2.sys(system):系统 3.path:路径 4.import:导入 5.from:从- 定义函数与设定参数 1.birthday:出生日期 2.yea ...
- 03-Jwt在.netcore中的实现
1)jwt的加密解密过程 jwt验证的核心就是加密解密的过程,掌握了这个过程,也就掌握了jwt的原理.jwt的三部分中,header和payload是明文的,能够直接读出来,签名Signature部分 ...
- Java 将Word转为HTML的方法
本文介绍如何在JAVA程序中将Word文档通过 Document.saveToFile() 方法转换为HTML文档.编辑代码前,参考如下环境配置,导入jar包. [程序环境] 1. IntelliJ ...
- feign的一个注解居然隐藏这么多知识!
引言 最近由于业务的需要,需要接入下阿里云的一个接口,打开文档看了看这个接口看下来还是比简单的目测个把小时就可以搞定,但是接入的过程还是比较坎坷的.首先我看了看他给的示例,首先把阿里云文档推荐的dem ...
- 在Windows Server 2012R2离线安装.net framework3.5
最近新装了一台Windows Server 2012 R2的服务器,安装数据库时,出现了提示安装不上 .net framework3.5的情况,经过网络上多次的资料查找及反复试验终于找到了一个可以解决 ...
- 分布式锁Redission
Redisson 作为分布式锁 官方文档:https://github.com/redisson/redisson/wiki 引入依赖 <dependency> <groupId&g ...
- 解决nodejs的npm命令无反应的问题
最近在弄cordova,又要折腾nodejs了. 今天安装cordova模块的时候,看到nodejs的默认模块安装路径在c盘 于是想修改下,按命令 npm config set prefix . 结果 ...
- 题解 CF468C Hack it!
题目传送门 Description 设 \(f(i)\) 表示 \(i\) 的数码只和,给出 \(a\),求出 \(l,r\) 使得 \(\sum_{i=l}^{r} f(i)\equiv 0\pmo ...
- 题解 [HAOI2012]道路
题目传送门 题目大意 给出一个 \(n\) 个点 \(m\) 条边的有向图,问每一条边在多少个最短路径中出现. \(n\le 1500,m\le 5000\) 思路 算我孤陋寡闻了... 很显然,我们 ...