ElasticSearch进阶检索
ElasticSearch进阶检索
入门检索中讲了如何导入elastic提供的样本测试数据,下面我们用这些数据进一步检索
一、SearchAPI
ES 支持两种基本方式检索 :
1、一种是通过使用 REST request URI 发送搜索参数(uri+检索参数)
GET bank/_search 检索 bank 下所有信息,包括 type 和 docs
GET bank/_search?q=*&sort=account_number:asc 请求参数方式检索
2、另一种是通过使用 REST request body 来发送它们(uri+请求体)
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": "asc"
}
]
}
# query 查询条件
# sort 排序条件
响应结果
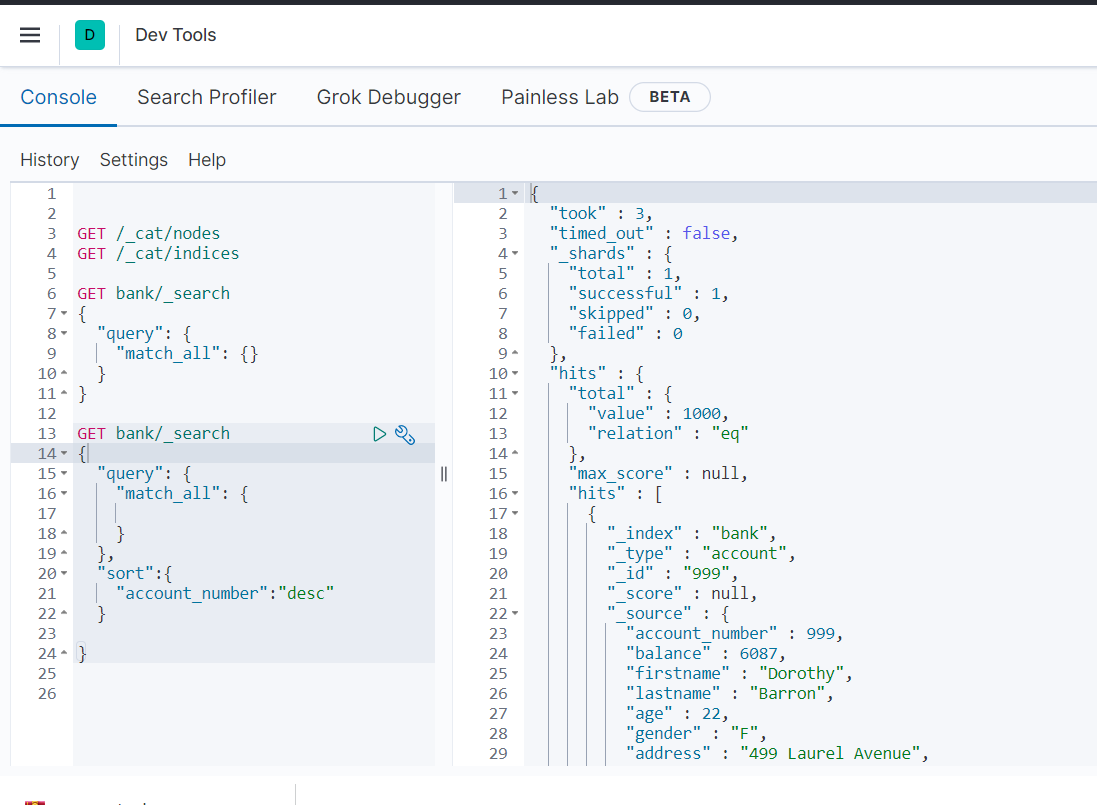
响应结果解释:
took - 执行搜索的时间(毫秒)
time_out - 告诉我们搜索是否超时
_shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片
hits - 搜索结果
hits.total - 搜索结果条数
hits.hits - 实际的搜索结果数组(默认为前 10 的文档)
sort - 结果的排序 key(键)(没有则按 score 排序)
score 和 max_score –相关性得分和最高得分(全文检索用)
二、Query DSL
1、基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特
定语言)。这个被称为 Query DSL。
一个查询语句的典型结构:
QUERY_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
如果针对于某个字段,那么它的结构如下:
{
QUERY_NAME:{
FIELD_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}
请求示例
GET bank/_search
{
"query": {
"match_all": {}
},
"from":0,
"size":5,
"sort": [
{
"balance": {
"order": "desc"
}
}
]
}
#query 定义如何查询
#match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查询类型完成复杂查询
#除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size from+size 限定完成分页
#sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准
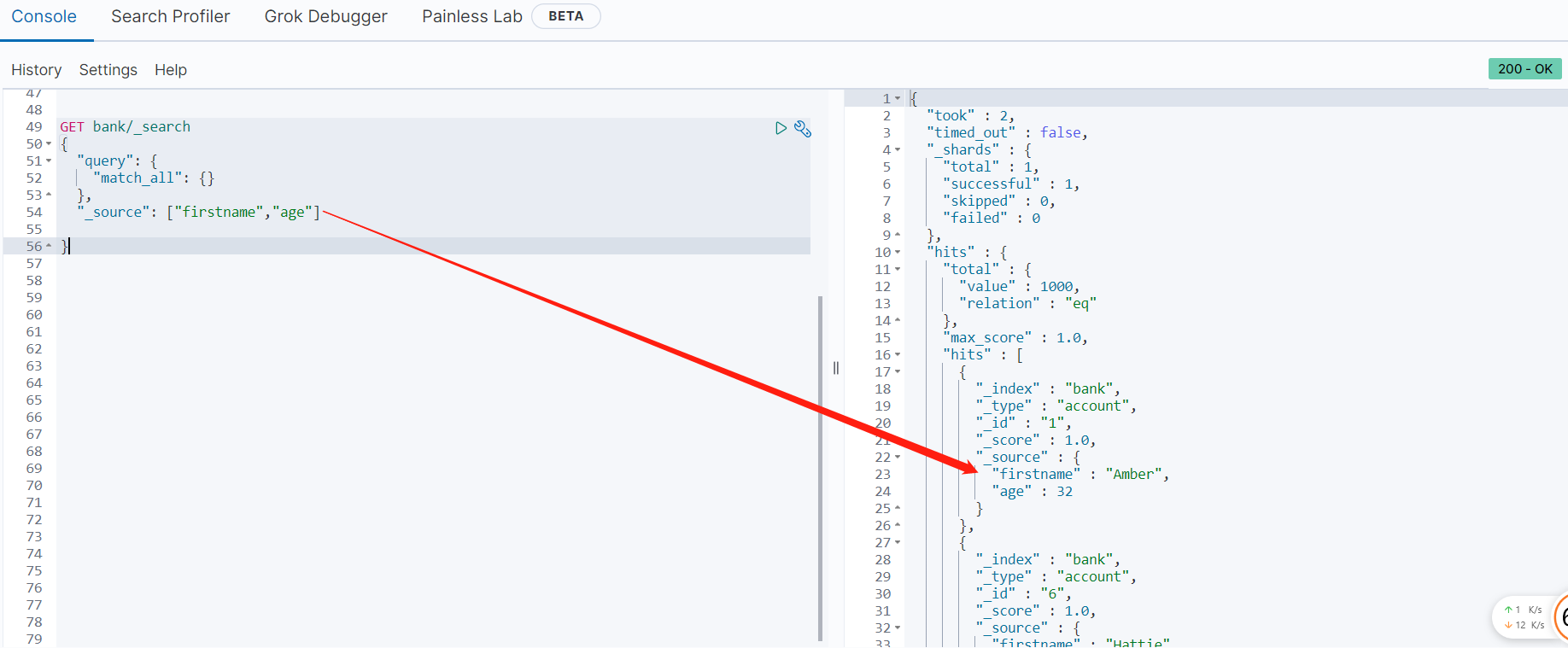
2、返回部分字段
_source:需要返回哪些字段写在数组中即可
3、match【匹配查询】
(1)对于基本数据类型的(非字符串),进行精确匹配
GET bank/_search
{
"query": {
"match": {
"account_number": 10
}
}
}
#match 返回 account_number=10 的
(2)对于字符串类型的字段,进行全文检索,模糊匹配
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
}
#最终查询出 address 中包含 mill 单词的所有记录
#match 当搜索字符串类型的时候,会进行全文检索,并且每条记录有相关性得分
(3)字符串,多个单词(分词+全文检索)
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
#最终查询出 address 中包含 mill 或者 road 或者 mill road 的所有记录,并给出相关性得分(_score),也会按照这个评分排序
(4)精确匹配文本字符串
GET bank/_search
{
"query": {
"match": {
"address.keyword": " Mill road"
}
}
}
# 查找 address完全为Mill Street 的数据
4、match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不分词)进行检索
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
#查出 address 中包含 mill road 的所有记录,并给出相关性得分
5、multi_match【多字段匹配】
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": [
"city","address"
]
}
}
}
#检索 city 或 address 匹配包含 mill 的数据,会对查询条件分词
6、bool【复合查询】
bool 用来做复合查询: 复合语句可以合并任何其它查询语句,包括复合语句,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
(1)must:必须达到must所列举的所有条件
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"firstname": "Forbes"}},
{"match": {"gender": "M"}}
]
}
}
}
(2)must_not 必须不是指定的情况
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"firstname": "Forbes"}},
{"match": {"gender": "M"}}
],
"must_not": [
{"match": {"lastname": "Wallace"}}
]
}
}
}
(3)should:应该达到 should列举的条件
如果达到会增加相关文档的评分并不会改变 查询的结果。如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"address": "mill"}},
{"match": { "gender": "M" }}
],
"should": [ {"match": { "address": "lane" }} ]
}
}
}
#应该匹配,匹配到能增加文档相关性得分,匹配不到也不会影响查询结果
7、filter【结果过滤】
不是所有的查询都需要计算相关性得分,仅用于 “filtering”(过滤)的文档。为了不计算分数 Elasticsearch 会自动检查场景并且优化查询的执行。
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"address": "mill"}}
],
"filter": [
{"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}}
]
}
}
}
#range范围查询,大于1000小于20000
8、term精确检索
避免使用 term 查询文本字段,默认情况下,Elasticsearch 会通过analysis分词将文本字段的值拆分为一部分,这使精确匹配文本字段的值变得困难。如果要查询文本字段值,请使用 match 查询代替。
和 match 一样,匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term
GET bank/_search
{
"query": {
"term": {
"age": "20"
}
}
}
9、Aggregation-执行聚合
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL聚合函数。
详细的介绍可以查看官网关于Aggregation的文档,下面提供几个示例来看一下聚合
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/search-aggregations.html
(1)搜索address中包含 mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "age"
}
},
"avg_age":{
"avg": {
"field": "age"
}
}
},
"size": 0
}
#size:0 不显示搜索数据
#aggs:执行聚合。聚合语法如下:
#"aggs": {
"aggs_name 这次聚合的名字,方便展示在结果集中": {
"AGG_TYPE 聚合的类型(avg,term,terms)": {
"field": "age"
}
}
}
(2)按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET bank/_search
{
"query": {"match_all": {}},
"aggs": {
"group_by_state": {
"terms": {
"field": "age"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
#其实就是aggs里面又加了一个aggs,第二个aggs根据第一个aggs聚合后的结果在聚合
(3)查出所有年龄分布,并且这些年龄段中 性别为M 的平均薪资和 性别为F 的平均薪资以及这个年龄
段的总体平均薪资
GET bank/_search
{
"query": {"match_all": {}},
"aggs": {
"age_avg":{
"terms": {
"field": "age",
"size": 1000
},
"aggs": {
"gender_avg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balance_avg": {
"avg": {
"field": "balance"
}
}
}
},
"balance_avg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
ElasticSearch进阶检索的更多相关文章
- ElasticSearch 进阶
目录 ElasticSearch 进阶 SearchAPI 检索信息 Query DSL 基本语法格式 查询-match 查询-match_phrase 查询-multi_match 查询-bool复 ...
- ElasticSearch入门检索
前面简介说到 elsatic是通过RestFul API接口操作数据的,可以通过postman模拟接口请求测试一下 一._cat 1.GET /_cat/nodes:查看所有节点 2.GET /_ca ...
- Elasticsearch原理学习--为什么Elasticsearch/Lucene检索可以比MySQL快?
转载于:http://vlambda.com/wz_wvS2uI5VRn.html 同样都可以对数据构建索引并通过索引查询数据,为什么Lucene或基于Lucene的Elasticsearch会比关系 ...
- 分布式搜索elasticsearch 文献检索索引 入门
1.首先,例如,下面的数据被提交给ES该指数 {"number":32768,"singer":"杨坤","size": ...
- 搭建ElasticSearch+MongoDB检索系统
ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Apach ...
- ES 19 - Elasticsearch的检索语法(_search API的使用)
目录 1 Search API的基本用法 1.1 查询所有数据 1.2 响应信息说明 1.3 timeout超时机制 1.4 查询多索引和多类型中的数据 2 URI Search的用法 2.1 GET ...
- Elasticsearch高级检索之使用单个字母数字进行分词N-gram tokenizer(不区分大小写)【实战篇】
一.前言 小编最近在做到一个检索相关的需求,要求按照一个字段的每个字母或者数字进行检索,如果是不设置分词规则的话,英文是按照单词来进行分词的. 小编以7.6.0版本做的功能哈,大家可以根据自己的版本去 ...
- elasticsearch 拼音检索能力研究
gitchennan/elasticsearch-analysis-lc-pinyin 配置参数少,功能满足需求. 对应版本 elasticsearch2.3.2 对应 elasticsearch-a ...
- ElasticSearch 分页检索
在ElasticSearch的多索引和多类别里说到我们在集群中有14个文档匹配我们的(空)搜索语句.单数仅仅有10个文档在hits数组中.我们怎样看到其它文档? 和SQL使用LIMITkeyword返 ...
随机推荐
- 互联网巨头们的 SRE 运维实践「GitHub 热点速览 v.21.27」
作者:HelloGitHub-小鱼干 本周大热点无疑是前几天 GitHub 发布的 Copilot,帮你补全代码,给你的注释提出建议,预测你即将使用的代码组件-如此神奇的 AI 技术,恰巧本周微软也开 ...
- Prometheus+Grafana企业监控系统
Prometheus+Grafana企业监控系统 作者 刘畅 实验配置: 主机名称 Ip地址 controlnode 172.16.1.70/24 slavenode1 172.16.1.71/24 ...
- ClouderaManager安装kafka报错
是因为默认的java heap size是50M,将broker_max_heap_size参数设置为512M后,重启kafka服务即可
- XCTF Guess-the-Number
一.发现是jar文件,一定想到反汇编gdui这个工具,而且运行不起来,可能是我电脑问题,我就直接反编译出来了. 也发现了flag,和对应的算法,直接拉出来,在本地运行,后得到flag 二.java代码
- Git的安装和配置 -入门
Git的版本有很多种,适应各种windows,IOS, Linux平台的安装. 我用的是linux Centos7的版本: 1. 安装命令用Yum, 非常简单就可以安装完毕. yum install ...
- python pyinsane应用
import sys from PIL import Image try: import src.abstract as pyinsane except ImportError: import pyi ...
- python 得到汉字的拼音
import pypinyin # 不带声调的(style=pypinyin.NORMAL) def pinyin(word): s = '' for i in pypinyin.pinyin(wor ...
- datax的安装和使用(windows)
github官方文档和项目:https://github.com/alibaba/DataX 下载后在windows环境下是可以直接用python编译执行的,但从github上下载的版本只支持pyth ...
- [刘阳Java]_MySQL数据优化总结_查询备忘录
数据库优化是在后端开发中必备技能,今天写一篇MySQL数据优化的总结,供大家看看 一.MySQL数据库优化分类 我们通过一个图片形式来看看数据优化一些策略问题 不难看出,优化有两条路可以选择:硬件与技 ...
- Java集合中的可变参数
可变参数: 1.在JDK1.5之后,如果我们定义一个方法需要接收多个参数,并且多个参数类型一致,我们可以对其简化成如下格式: 修饰符 返回值类型 方法名(参数类型... 形参名){} 其实这个书写完全 ...