Golang中如何正确的使用sarama包操作Kafka?
Golang中如何正确的使用sarama包操作Kafka?
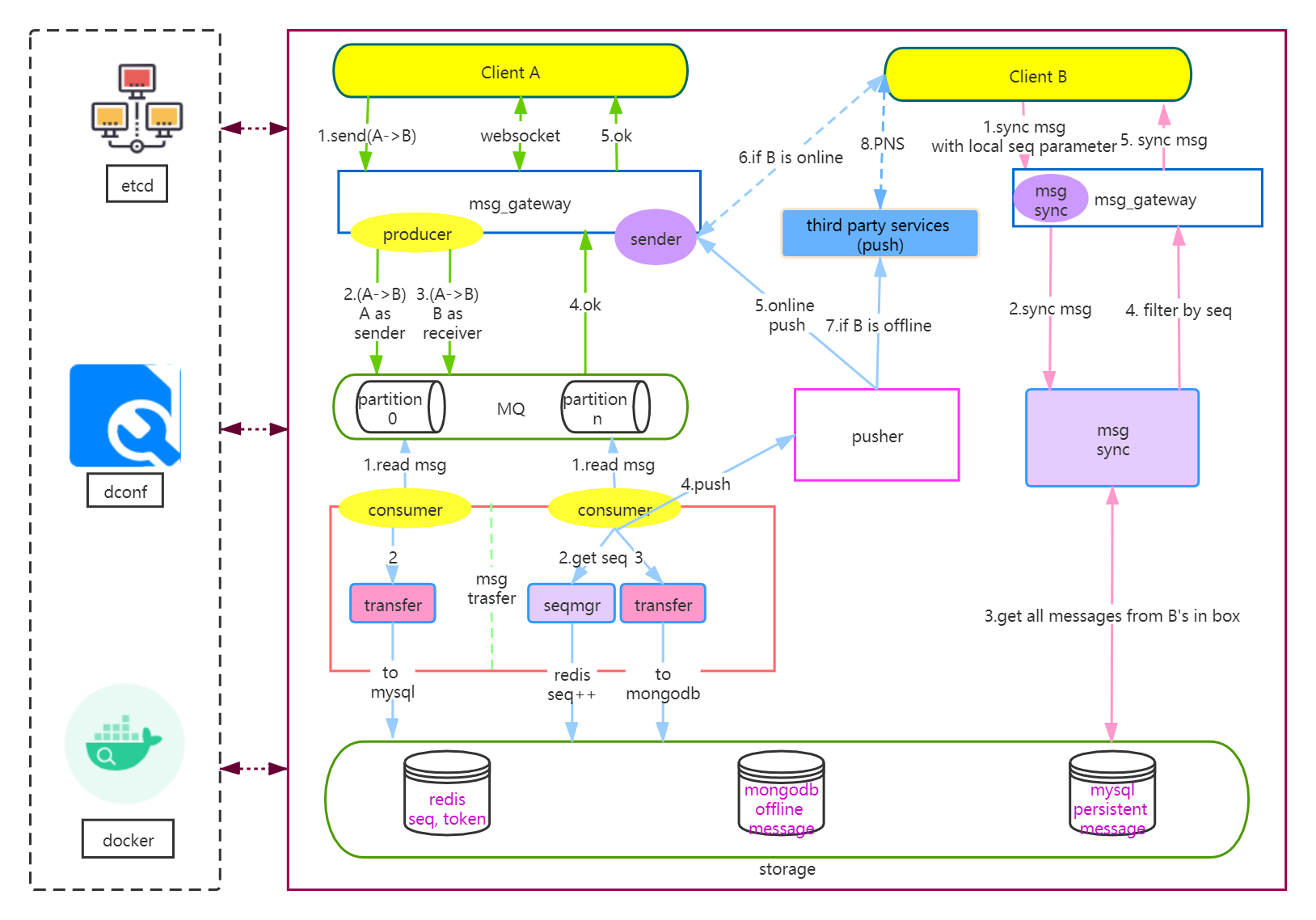
一、背景
- 重复消费的问题。
- 乱序的问题。
二、Kafka消息丢失问题描述
三、生产端丢消息问题解决
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // -1ack参数有如下取值:
const (
// NoResponse doesn't send any response, the TCP ACK is all you get.
NoResponse RequiredAcks = 0
// WaitForLocal waits for only the local commit to succeed before responding.
WaitForLocal RequiredAcks = 1
// WaitForAll waits for all in-sync replicas to commit before responding.
// The minimum number of in-sync replicas is configured on the broker via
// the `min.insync.replicas` configuration key.
WaitForAll RequiredAcks = -1
)
四、消费端丢消息问题
自动提交模式下的丢消息问题
// NewConfig returns a new configuration instance with sane defaults.
func NewConfig() *Config {
// …
c.Consumer.Offsets.AutoCommit.Enable = true. // 自动提交
c.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second // 间隔
c.Consumer.Offsets.Initial = OffsetNewest
c.Consumer.Offsets.Retry.Max = 3
// ...
}这里的自动提交,是基于被标记过的消息(sess.MarkMessage(msg, “"))
type exampleConsumerGroupHandler struct{}
func (exampleConsumerGroupHandler) Setup(_ ConsumerGroupSession) error { return nil }
func (exampleConsumerGroupHandler) Cleanup(_ ConsumerGroupSession) error { return nil }
func (h exampleConsumerGroupHandler) ConsumeClaim(sess ConsumerGroupSession, claim ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("Message topic:%q partition:%d offset:%d\n", msg.Topic, msg.Partition, msg.Offset)
// 标记消息已处理,sarama会自动提交
sess.MarkMessage(msg, "")
}
return nil
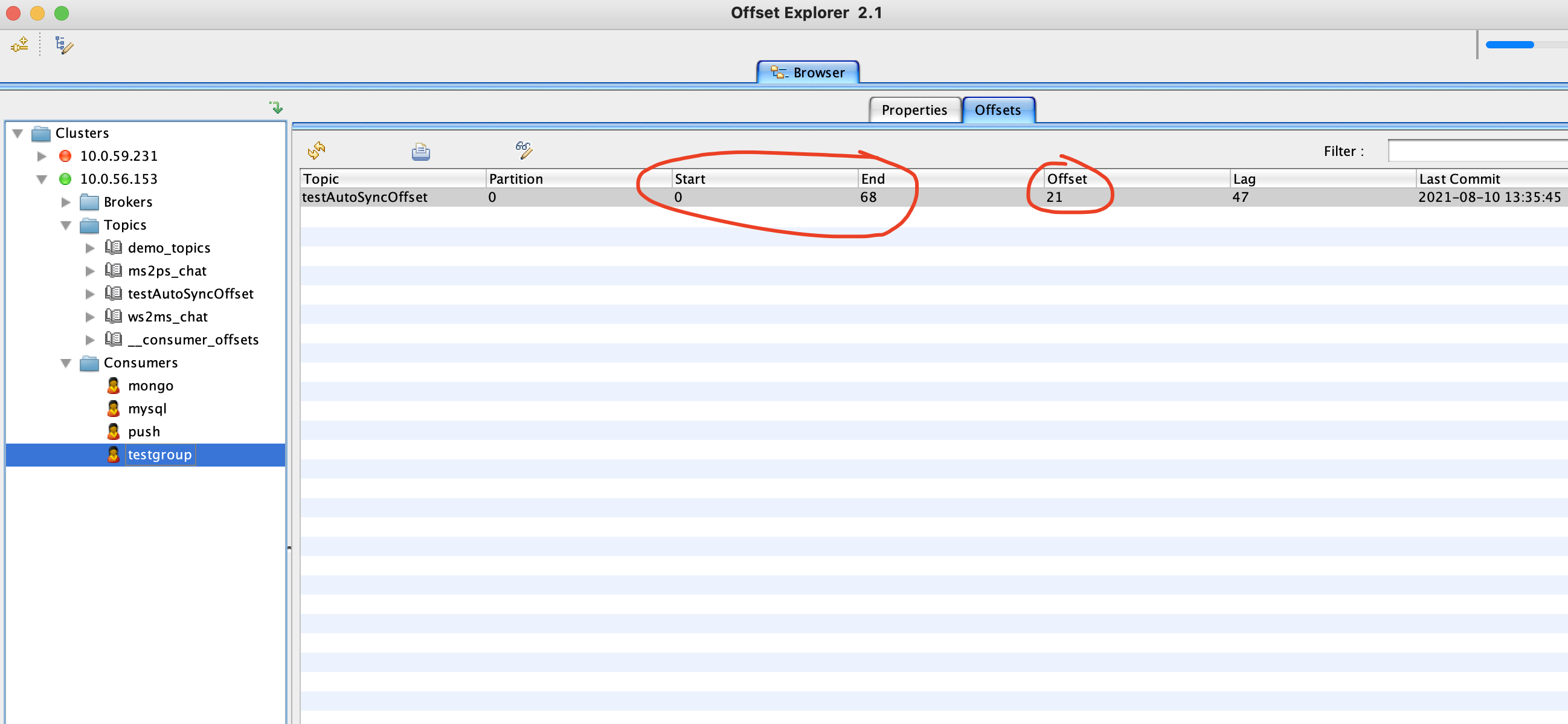
}如果不调用sess.MarkMessage(msg, “"),即使启用了自动提交也没有效果,下次启动消费者会从上一次的Offset重新消费,我们不妨注释掉sess.MarkMessage(msg, “"),然后打开Offset Explorer查看:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 插入mysql
insertToMysql(msg)
// 正确:插入mysql成功后程序崩溃,下一次顶多重复消费一次,而不是因为Offset超前,导致应用层消息丢失了
sess.MarkMessage(msg, “")
}
return nil
}
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 错误1:不能先标记,再插入mysql,可能标记的时候刚好自动提交Offset,但mysql插入失败了,导致下一次这个消息不会被消费,造成丢失
// 错误2:干脆忘记调用sess.MarkMessage(msg, “"),导致重复消费
sess.MarkMessage(msg, “")
// 插入mysql
insertToMysql(msg)
}
return nil
}sarama手动提交模式
consumerConfig := sarama.NewConfig()
consumerConfig.Version = sarama.V2_8_0_0
consumerConfig.Consumer.Return.Errors = false
consumerConfig.Consumer.Offsets.AutoCommit.Enable = false // 禁用自动提交,改为手动
consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 插入mysql
insertToMysql(msg)
// 手动提交模式下,也需要先进行标记
sess.MarkMessage(msg, "")
consumerCount++
if consumerCount%3 == 0 {
// 手动提交,不能频繁调用,耗时9ms左右,macOS i7 16GB
t1 := time.Now().Nanosecond()
sess.Commit()
t2 := time.Now().Nanosecond()
fmt.Println("commit cost:", (t2-t1)/(1000*1000), "ms")
}
}
return nil
}
五、Kafka消息顺序问题
msg := &sarama.ProducerMessage{
Topic: “msgc2s",
Value: sarama.StringEncoder(“hello”),
Partition: toUserId % 10,
}
partition, offset, err := producer.SendMessage(msg)
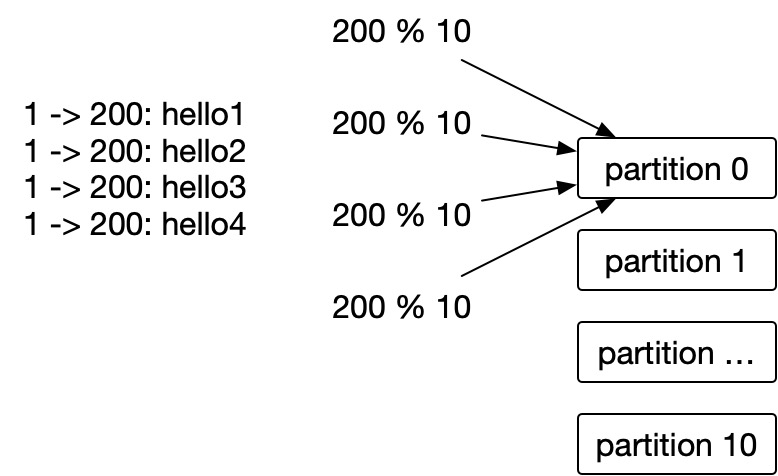
生产消息的时候,除了Topic和Value,我们可以通过手动指定partition,比如总共有10个分区,我们根据用户ID取余,这样发给同一个用户的消息,每次都到1个partition里面去了,消费者写入mysql中的时候,自然也是有序的。
p.config.Producer.Partitioner = sarama.NewHashPartitioner
然后,在生成消息之前,设置消息的Key值:
msg := &sarama.ProducerMessage{
Topic: "testAutoSyncOffset",
Value: sarama.StringEncoder("hello"),
Key: sarama.StringEncoder(strconv.Itoa(RecvID)),
}
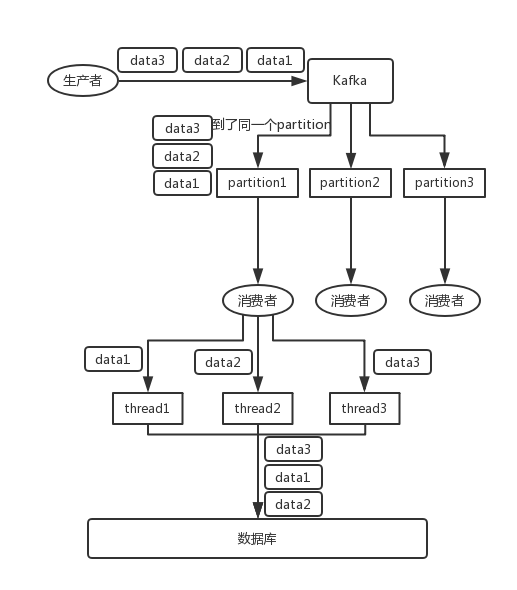
4.扩展知识:多线程情况下一个partition的乱序处理
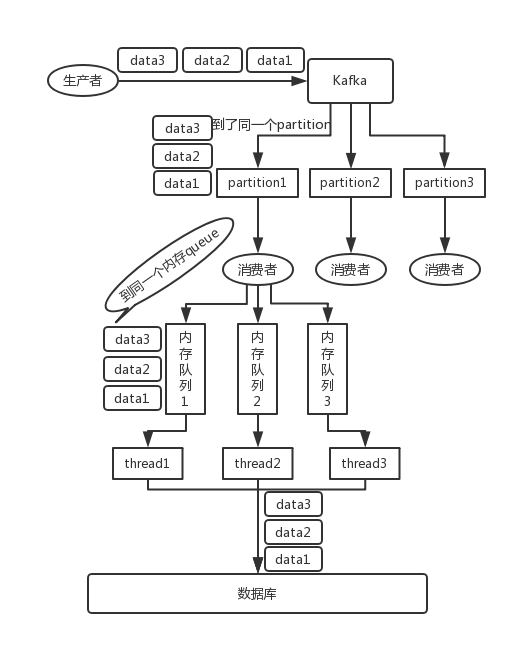
六、重复消费和消息幂等
- 如果是存在redis中不需要持久化的数据,比如string类型,set具有天然的幂等性,无需处理。
- 插入mysql之前,进行一次query操作,针对每个客户端发的消息,我们为它生成一个唯一的ID(比如GUID),或者直接把消息的ID设置为唯一索引。
七、完整代码实例
type msgConsumerGroup struct{}
func (msgConsumerGroup) Setup(_ sarama.ConsumerGroupSession) error { return nil }
func (msgConsumerGroup) Cleanup(_ sarama.ConsumerGroupSession) error { return nil }
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 查mysql去重
if check(msg) {
// 插入mysql
insertToMysql()
}
// 标记,sarama会自动进行提交,默认间隔1秒
sess.MarkMessage(msg, "")
}
return nil
}
func main(){
consumerConfig := sarama.NewConfig()
consumerConfig.Version = sarama.V2_8_0_0 // specify appropriate version
consumerConfig.Consumer.Return.Errors = false
//consumerConfig.Consumer.Offsets.AutoCommit.Enable = true // 禁用自动提交,改为手动
//consumerConfig.Consumer.Offsets.AutoCommit.Interval = time.Second * 1 // 测试3秒自动提交
consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest
cGroup, err := sarama.NewConsumerGroup([]string{"10.0.56.153:9092", "10.0.56.153:9093", "10.0.56.153:9094"},"testgroup", consumerConfig)
if err != nil {
panic(err)
}
for {
err := cGroup.Consume(context.Background(), []string{"testAutoSyncOffset"}, consumerGroup)
if err != nil {
fmt.Println(err.Error())
break
}
}
_ = cGroup.Close()
}
func main(){
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 等待所有follower都回复ack,确保Kafka不会丢消息
config.Producer.Return.Successes = true
config.Producer.Partitioner = sarama.NewHashPartitioner // 对Key进行Hash,同样的Key每次都落到一个分区,这样消息是有序的
// 使用同步producer,异步模式下有更高的性能,但是处理更复杂,这里建议先从简单的入手
producer, err := sarama.NewSyncProducer([]string{"10.0.56.153:9092"}, config)
defer func() {
_ = producer.Close()
}()
if err != nil {
panic(err.Error())
}
msgCount := 4
// 模拟4个消息
for i := 0; i < msgCount; i++ {
rand.Seed(int64(time.Now().Nanosecond()))
msg := &sarama.ProducerMessage{
Topic: "testAutoSyncOffset",
Value: sarama.StringEncoder("hello+" + strconv.Itoa(rand.Int())),
Key: sarama.StringEncoder("BBB”),
}
t1 := time.Now().Nanosecond()
partition, offset, err := producer.SendMessage(msg)
t2 := time.Now().Nanosecond()
if err == nil {
fmt.Println("produce success, partition:", partition, ",offset:", offset, ",cost:", (t2-t1)/(1000*1000), " ms")
} else {
fmt.Println(err.Error())
}
}
}
八、参考
- Kafka 的数据丢失和重复消费 https://zhuanlan.zhihu.com/p/54287819
- kafka什么时候会丢消息
- CAP 定理的含义 https://www.ruanyifeng.com/blog/2018/07/cap.html
- Kafka入门(3):Sarama生产者是如何工作的 https://www.cnblogs.com/hongjijun/p/13584373.html
- 超好用的 Kafka 客户端管理工具 Offset Explorer http://www.ibloger.net/article/3497.html
- 查看集群中kafka的Version(版本) https://blog.csdn.net/Damonhaus/article/details/54310868
- Kafka如何保证消息的顺序性 https://blog.csdn.net/qianshangding0708/article/details/103360193
Golang中如何正确的使用sarama包操作Kafka?的更多相关文章
- 在Golang中如何正确地使用database/sql包访问数据库
本文记录了我在实际工作中关于数据库操作上一些小经验,也是新手入门golang时我认为一定会碰到问题,没有什么高大上的东西,所以希望能抛砖引玉,也算是对这个问题的一次总结. 其实我也是一个新手,机缘巧合 ...
- golang中文件以及文件夹路径相关操作
获取目录中所有文件使用包: io/ioutil 使用方法: ioutil.ReadDir 读取目录 dirmane 中的所有目录和文件(不包括子目录) 返回读取到的文件的信息列表和读取过程中遇到的任何 ...
- android中正确导入第三方jar包
android中正确导入第三方jar包 andriod中如果引入jar包的方式不对就会出现一些奇怪的错误. 工作的时候恰好有一个jar包需要调用,结果用了很长时间才解决出现的bug. 刚开始是这样引用 ...
- golang中的reflect包用法
最近在写一个自动生成api文档的功能,用到了reflect包来给结构体赋值,给空数组新增一个元素,这样只要定义一个input结构体和一个output的结构体,并填写一些相关tag信息,就能使用程序来生 ...
- golang 中 sync包的 WaitGroup
golang 中的 sync 包有一个很有用的功能,就是 WaitGroup 先说说 WaitGroup 的用途:它能够一直等到所有的 goroutine 执行完成,并且阻塞主线程的执行,直到所有的 ...
- 『Golang』MongoDB在Golang中的使用(mgo包)
有关在Golang中使用mho进行MongoDB操作的最简单的例子.
- golang中Context的使用场景
golang中Context的使用场景 context在Go1.7之后就进入标准库中了.它主要的用处如果用一句话来说,是在于控制goroutine的生命周期.当一个计算任务被goroutine承接了之 ...
- java项目中可能会使用到的jar包解释
一.Struts2 用的版本是struts2.3.1.1 一个简单的Struts项目所需的jar包有如下8个 1. struts2-core-2.3.1.1.jar: Struts2的核心类库. 2. ...
- 正确的 Composer 扩展包安装方法
问题说明 我们经常要往现有的项目中添加扩展包,有时候因为文档的错误引导,如下图来自 这个文档 的: composer update 这个命令在我们现在的逻辑中,可能会对项目造成巨大伤害. 因为 com ...
随机推荐
- kubernetes关闭基于角色的访问控制-匿名访问
1.关闭基于角色的访问控制 如果正在使用一个带有RBAC机制的Kubernetes集群,服务账户可能不会被授权访问API服务器(或只有部分授权).目前最简单的方式就是运行下面的命令查询API服务器,从 ...
- 9、zabbix监控
9.1.监控: 1.初级(凡人): (1)识别监控的对象: (2)理解监控的对象: (3)细分监控对象的指标: (4)确定告警的基准线: 2.预中级(飞仙): (1)工具化和监控分离: (2)监控对象 ...
- SpringBoot 优雅整合Swagger Api 自动生成文档
前言 一个好的可持续交付的项目,项目说明,和接口文档是必不可少的,swagger api 就可以帮我们很容易自动生成api 文档,不需要单独额外的去写,无侵入式,方便快捷大大减少前后端的沟通方便查找和 ...
- CentOS-Docker搭建Nextcloud
下载镜像 $ docker pull nextcloud 运行镜像 $ docker run -d --restart=unless-stopped --name nextcloud -v /home ...
- consul 多节点/单节点集群搭建
三节点配置 下载安装包 mkdir /data/consul mkdir /data/consul/data curl -SLO https://github.com/consul/1.9.5/con ...
- 所有的Java虚拟机必须实现在每个类或接口被Java程序 “ 首次主动使用 ” 时才初始化他们
原文:https://www.cnblogs.com/fanjie/p/6916784.html Java程序对类的使用方式可分为两种– 主动使用– 被动使用 被动使用以后再讲,这里说说什么是主动使用 ...
- 谈谈Java事务
事务具基本特征(ACID) ① Atomi(原子性):事务中包含的操作被看做一个整,要么完全部成功,要么全部失败. ② Consistency(一致性):事务在完成时,必须是所有的数据都保持一致状态, ...
- C:汉字存储
问题 C语言中汉字如何存储?梳理思路! 答案 在计算机中,一个英文字符占1个字节,汉字占两个字节,如果用char字符数组存储字符时,需要在最后面自动加上一个字节的结束符"\0" 汉 ...
- HTML5-CSS(三)
一.CSS 盒模型 1.元素尺寸:CSS 盒模型中最基础的就是设置一个元素的尺寸大小.有三组样式来配置一个元素的尺寸大小,样式表如下 //设置元素尺寸 div { width: 200px;heig ...
- MapReduce学习总结之java版wordcount实现
一.代码实现: package rdb.com.hadoop01.mapreduce; import java.io.IOException; import org.apache.hadoop.con ...