Salesforce Integration 概览(四) Batch Data Synchronization(批量数据的同步)
本篇参考:https://resources.docs.salesforce.com/sfdc/pdf/integration_patterns_and_practices.pdf
前两篇博客讲了一下远程进程调用的场景。今天我们描述一下 批量数据同步的模式。
一. 上下文
公司曾经使用其他的CRM平台,然后和其他的上下游系统进行数据的交互以及集成来保证多方数据的一致性。公司现在正在将CRM实施从原有系统转移到Salesforce,并希望有以下的操作:
•从当前CRM系统中提取和转换 Account / Contact / Opportunity等,并将数据加载到Salesforce(初始数据导入)。
•每周从远程系统提取、转换客户Billing数据,并将其加载到Salesforce中(正在进行)。
•每周从Salesforce提取客户Activity信息并将其导入内部数据仓库(正在进行)。
•需要考虑salesforce作为主数据变化,其他系统接收。其他系统作为主数据变化,salesforce同样数据一致性(数据复制)
二. 问题和考虑因素
问题: 如何将数据导入到Salesforce以及将数据从Salesforce导出到其他系统,同时考虑到这些导入和导出可能会在工作时间干扰最终用户的操作,并涉及大量数据?
考虑因素: 当基于这种模式应用解决方案时,需要考虑各种各样的因素:
•大量的数据是否应存储在Salesforce中?
•如果数据应存储在Salesforce中,是否应刷新数据以响应远程系统中的事件?(外部数据是否为主还是salesforce为主?)
•是否应定期刷新数据?
•数据是否支持主要业务流程?
•Salesforce中是否存在受此数据可用性影响的分析(报告)需求?
三. 解决方案
针对解决方案的选择,我们首先需要知道谁作为主数据,salesforce作为主数据,同步给外部系统以及 外部系统作为主数据,同步给salesforce针对大数据量有不同的解决方案,详情如下表格
|
解决方案 |
适配程度 |
谁作为主数据 |
comments |
|
Salesforce Change Data Capture |
Best |
Salesforce |
Salesforce更改数据会发送更改数据的事件,这些事件表示对Salesforce记录的更改操作。订阅端捕获的事件包括创建新记录、更新现有记录、删除记录和取消删除记录。 通过CDC,下游系统可以接收Salesforce记录的近实时更改,并在外部数据存储中同步相应的记录。CDC负责复制的连续同步部分。它发布Salesforce新记录和更改记录的数据增量。更改数据捕获需要一个集成应用程序来接收事件并在外部系统中执行更新。详情可以查看此博客: salesforce零基础学习(一百零五)Change Data Capture |
|
通过第三方ETL工具进行复制 |
Best |
外部系统 |
利用第三方ETL工具,该工具允许您针对源数据运行变更数据捕获。该工具对源数据集中的更改做出反应,转换数据,然后调用Salesforce Bulk API来发出DML语句。这也可以使用salesforcesoapi实现。当然大数据量,我们倾向于用 bulk API来实现(dataloader也基于bulk api) |
|
通过第三方ETL工具进行复制 |
Good |
Salesforce |
利用第三方ETL工具,允许您针对ERP和Salesforce数据集运行变更数据捕获。在这个解决方案中,Salesforce是数据源,您可以使用各行的时间/状态信息来查询数据并过滤目标结果集。这可以通过将SOQL与SOAP API和query()方法一起使用,或者通过使用SOAP API和getUpdated()方法来实现。 |
|
Remote call-in |
Suboptimal |
外部系统 |
远程系统可以使用其中一个api调用Salesforce,并在数据发生时执行更新。但是,这会导致两个系统之间的通信量相当大。应该更加强调错误处理和锁定。这种模式有可能导致持续更新,从而影响最终用户的性能。 |
|
Remote process invocation |
Suboptimal |
Salesforce |
Salesforce可以调用远程系统,并在数据发生时执行更新。但是,这会导致两个系统之间的通信量相当大。应该更加强调错误处理和锁定。这种模式有可能导致持续更新,从而影响最终用户的性能。 |
这里做一个引申。我们除了遵循是否 best practice以外,还需要进行多方面的考虑,比如项目所能负担的成本以及是否有可使用的resource等等。比如针对Change Data Capture,官方只是几个表免费,如果超过了指定的数量,需要有额外的开支。这些在我们选择方案的时候都需要进行考虑的。
四. 流程草图
1.针对外部系统作为主数据,官方的一个集成方案的草图,通过ETL来实现
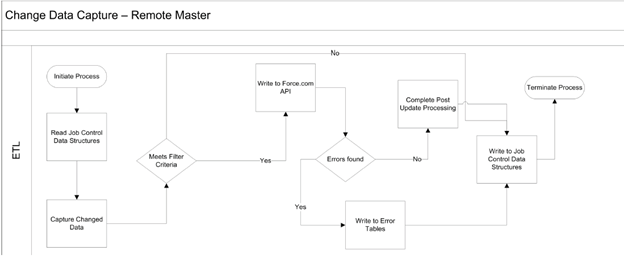
2. 针对salesforce作为主数据,官方的一个集成方案的草图,通过CDC来实现

五. 其他关键点
我们可以在以下情况下将外部来源的数据与Salesforce集成:
•外部系统是数据主系统,Salesforce是单源系统或多个系统提供的数据的使用者。在这种情况下,通常会有一个数据仓库,在将数据导入Salesforce之前对数据进行聚合。
•Salesforce是数据主系统,Salesforce是特定表(实体)的SOR(system of record)
在典型的Salesforce集成场景中,实施团队执行以下操作之一:
•对源数据集实施CDC。
•在中间的、内部数据库中实现一组支持的数据库结构,称为控制表。然后使用ETL工具创建程序,这些程序将进行以下的步骤:
1.读取控制表以确定作业的上次运行时间,并提取所需的任何其他控制值。
2.使用上述控制值作为过滤器并查询源数据集。
3.应用预定义的处理规则,包括验证、改进等。
4.使用ETL工具的可用连接器/转换功能创建目标数据集。
5.将数据集写入Salesforce对象。
6.如果处理成功,则更新控制表中的控制值。
7.如果处理失败,请使用允许重新启动和退出的值更新控制表。
注意:我们建议您在ETL工具可以访问的环境中创建控制表和关联的数据结构,即使Salesforce的访问权限不可用。这提供了足够的弹性。对于ETL工具从数据同步能力获得最大效益,请考虑以下内容:
•对ETL作业进行链接和排序,以提供一个连贯的过程。
•使用两个系统的主键匹配传入数据(unique key)。
•使用特定的API方法仅提取更新的数据。
•如果导入主详细信息或查找关系中的子记录,请在源位置使用其父项对导入的数据进行分组,以避免锁定。
•任何导入后处理,如trigger,只能选择性地处理数据。
总结:篇中主要介绍了批量数据同步的模式,我们在使用这个模式之前,需要先确保数据是否要落入到数据库以及谁是 MDM,以谁为主,数据从哪来到哪去,不同的点需要不同的设计方式。当然,除了best practice以外,effort以及resource等都是项目中必须要考量的。综合考虑才是特定项目的最优解。篇中有错误的地方欢迎指出,有不懂欢迎留言。
Salesforce Integration 概览(四) Batch Data Synchronization(批量数据的同步)的更多相关文章
- salesforce Integration 概览(一) 杂篇
本篇参考:https://resources.docs.salesforce.com/sfdc/pdf/integration_patterns_and_practices.pdf 我们在做sales ...
- Salesforce Integration 概览(七) Data Virtualization数据可视化
本篇参考:https://resources.docs.salesforce.com/sfdc/pdf/integration_patterns_and_practices.pdf Salesforc ...
- Salesforce Integration 概览(五) Remote Call-In(远程操作 外部->salesforce)
本篇参考:https://resources.docs.salesforce.com/sfdc/pdf/integration_patterns_and_practices.pdf 本篇博客介绍 Re ...
- Salesforce Integration 概览(六) UI Update Based on Data Changes(UI自动更新基于数据变更)
Salesforce用户界面必须由于Salesforce数据的更改而自动更新.这个场景其实在我所经历的项目中用到的不是特别多,因为客户可能直接点击刷新按钮就直接看到了最新的数据,而不是那种一直不刷新然 ...
- Salesforce Integration 概览(二) Remote Process Invocation—Request and Reply(远程进程调用--请求和响应)
本篇参考:https://resources.docs.salesforce.com/sfdc/pdf/integration_patterns_and_practices.pdf 我们在项目中,经常 ...
- Salesforce Integration 概览(三) Remote Process Invocation—Fire and Forget(远程进程调用-发后即弃)
本篇参考:https://resources.docs.salesforce.com/sfdc/pdf/integration_patterns_and_practices.pdf 我们在上一篇讲了远 ...
- 在Salesforce中通过dataloadercliq调用data loader来批量处理数据
上一篇文章讲到,通过data loader去批量处理数据,那么这篇文章将主要讲解在Salesforce中通过dataloadercliq调用data loader来批量处理数据. 1): CLIq文件 ...
- c#之mysql四种带事务批量插入
前言 对于像我这样的业务程序员开发一些表单内容是家常便饭的事情,说道表单 我们都避免不了多行内容的提交,多行内容保存,自然要用到数据库,如果循环打扰我数据库,数据库也会觉得很累,从而增加数据库服务器压 ...
- Bootstrap入门(二十四)data属性
Bootstrap入门(二十四)data属性 你可以仅仅通过 data 属性 API 就能使用所有的 Bootstrap 插件,无需写一行 JavaScript 代码.这是 Bootstrap 中的一 ...
随机推荐
- Java并发之ReentrantLock源码解析(三)
ReentrantLock和BlockingQueue 首先,看到这个标题,不要怀疑自己进错文章,也不要怀疑笔者写错,哈哈.本章笔者会从BlockingQueue(阻塞队列)的角度,看看juc包下的阻 ...
- Place the Robots 需要较强的建图能力
Place the Robots 思路:在任意一个点格子放机器人,那么它所在的行和列被控制了.我们对每一行或每一列连续的空地(草地忽视)称之为块,给每一行和每一列的块标号, 每一行的快与每一列的快相交 ...
- Gerrit GitLab GitHub的几点不同
代码评审的方式不一样 GitHub是基于Pull Request 进行代码评审; GitLab是基于Merge Request 进行代码评审; Gerrit是基于Change Request 进行代码 ...
- Linux:linux下解压*压缩tar.xz、tar、tar.gz、tar.bz2、tar.Z、rar、zip、war等文件方法
tar -c: 建立压缩档案-x:解压-t:查看内容-r:向压缩归档文件末尾追加文件-u:更新原压缩包中的文件 ------------------------------------------ 这 ...
- 了解Javascript中函数作为对象的魅力
前言 Javascript赋予了函数非常多的特性,其中最重要的特性之一就是将函数作为第一型的对象.那就意味着在javascript中函数可以有属性,可以有方法, 可以享有所有对象所拥有的特性.并且最重 ...
- bugku--cookie欺骗
打开题目一看,是一串的东西,再看了一下filename发现不对劲了,明显是base64编码,拿去解码一下, 发现是这个,说明是filename,是需要解析的哪个文件名,把index.php编码一下,试 ...
- XCTF command_execution
讲道理这题算是我的思路盲区,先试着ping下本地的地址,127.0.0.1 看了大佬的wp时,我突然意识到,这是放在服务器上执行的,而且服务器一般都是linux系统的,所以linux命令是必需的, 思 ...
- buu crypto 变异凯撒
一.由题目就可知是凯撒加密,但是是变异,说明有改动,但是凯撒的本质移位是不变的,将密文afZ_r9VYfScOeO_UL^RWUc,和flag进行比较,字符表查一下,发现 a:97 f:102 f:1 ...
- 官宣.NET 6 预览版4
我们很高兴发布 .NET 6 Preview 4.我们现在大约完成了 .NET 6 发布的一半.现在是一个很好的时机,可以再次查看.NET6的完整范围.许多功能都接近最终形式,而其他功能将很快推出,因 ...
- 【源码篇】Flutter GetX深度剖析 | 我们终将走出自己的路(万字图文)
前言 人心中的成见是一座大山,任你怎么努力都休想搬动. 这是电影<哪吒>里申公豹说的一句话,也是贯彻整部电影的一个主题:或许这句话引起了太多人的共鸣:35岁职场危机,大厂卡本科学历,无房无 ...