Lyndon 相关的炫酷字符串科技
浅谈从 Lyndon Words 到 Three Squares Lemma
By zghtyarecrenj
本文包括:Lyndon Words & Significant Suffixes & Lyndon Array & Runs & Lyndon Tree & Three Squares Lemma。
禁止转载全文,转载部分需要注明出处。
前言
本文正在重写
如果你发现笔者有写错的地方,请联系笔者。(尽量不要用博客园评论,我不会经常看,建议用洛谷私信我或者加 QQ 3360155688)。
截至 2021-06-14 的 To-do List:
- [ ] 重写 Significant Suffixes
- [ ] 重写 Lyndon Factorization 的部分证明和题解
- [ ] ZJOI2020 字符串 (runs)
- [ ] CF594E (cfl)
- [ ] [JSOI2019]节日庆典 (significant suffixes)
- [ ] 简单字符串 (Lyndon array)
- [ ] Lyndon Tree 其实写的很草率(但是这部分应该没什么用吧)
- [ ] Periodicity 还有很多很有趣的内容
0 Preliminaries
关于字符串部分的基础详见 oi-wiki 字符串,这里略提。
我们定义两个字符串 \(a\) 和 \(b\),如果 \(a\) 的字典序 \(<b\),则我们称 \(a < b\)。
如果 \(a\) 是 \(b\) 的前缀且 \(a \ne b\),则我们称 \(a \sqsubset b\)。
如果 \(a\) 是 \(b\) 的前缀,则我们称 \(a \sqsubseteq b\)。
如果 \(a < b\) 且 \(a\) 不是 \(b\) 的前缀,则我们称 \(a \triangleleft b\)。即 \(a \triangleleft b \Longleftrightarrow (a < b) \wedge (a \not\sqsubseteq b)\)。Fact:如果 \(a \triangleleft b\),则 \({au} < {bv}\)。
\({abc}\) 表示拼接 \(a, b, c\) 三个字符串。
\(a^n\) 表示 \(n\) 个 \(a\) 拼接在一起。e.g. \({a^2b} = {aab}\)
\(\epsilon\) 表示空串。
我们定义字符集为 \(\Sigma\),组成的字符串为 \(\Sigma^*\),\(\Sigma^+ = \Sigma^* \setminus \{\epsilon\}\)
\(\operatorname{pref}(a)\) 表示所有 \(a\) 的前缀的集合,\(\operatorname{suf}(a)\) 表示所有 \(a\) 的后缀的集合(包含 \(a\) 和 \(\epsilon\))
\(\operatorname{pref}^+(a) = \operatorname{pref}(a) \setminus \{a,\epsilon\},\ \operatorname{suf}^+(a) = \operatorname{suf}(a) \setminus \{a, \epsilon\}\)
若无特殊定义,字符串 \(s\) 是从 \(0\) 开始。
\(|s|\) 表示 \(s\) 的长度,\(s[i..j]\) 表示 \(s\) 的一个子串,第一个字符的标号为 \(i\),最后一个字符的标号为 \(j\)。
$\hat{w}=w$ $,其中 $$ $ 是一个比字符集里面任何数小的字符。
1 Lyndon Words
这部分这位老哥写的可能比我的详细= = link
1.1 Definition
Lyndon Word:一个字符串是一个 Lyndon Word 当且仅当 \(\forall a\) 的后缀 \(b\),有 \(a < b\)。
还有一个定义:对于一个 \(n\) 的串有 \(n\) 个循环同构,则其中严格最小的那个是一个 Lyndon Word。
比如:\(\text{ab}\) 是一个 Lyndon Word,但是 \(\text{ba}\) 不是。
\(\mathcal L\) 表示所有 Lyndon Word 组成的集合。
1.2 Chan-Fox-Lyndon Factorization
又称 Lyndon Decomposition。
我们定义 \(\operatorname{CFL}(s)\) 是一个对于 \(s\) 串的划分,即划分成了 \({w_1w_2\cdots w_k} = s\),使得所有 \(w_i\) 是 Lyndon Word,并且 \(w_1 \ge w_2 \ge \cdots \ge w_n\)。
比如:串 \(\text{bbababaabaaabaaaab}\) 的 Lyndon 分解是 \(\text{b|b|ab|ab|aab|aaab|aaaab}\)。
Theorem 1.2.1 Lyndon Concatanation
这是一个很显然的结论。
如果 \(a, b \in \mathcal L\),且 \(a < b\),则 $ {ab} \in \mathcal L$。
由于 \(a < b\),我们有 \({ab} < b\)。接下来我们分两种情况讨论。
当 \(a \not \sqsubseteq b\) 时:根据 \(a < b\),我们有 \(a \triangleleft b\)。所以 \({ab} \triangleleft b \implies {ab} < b\)。
当 \(a \sqsubseteq b\) 时:令 \(b={ac}\),则 \({ab} = {a^2c}\)。因为 \(b \in \mathcal L\),所以 \({ab} < b \implies {a^2c} < {ac} \implies {ac} < c\),所以 \(b < c\)。
所以,\(\forall d \in \operatorname{suf}^+(b), \ {ab} < b < d \implies \forall c \in \operatorname{suf}^+(a),\ a \triangleleft e \implies {ab} \triangleleft {eb}\)。\(\blacksquare\)
Theorem 1.2.2 Existence of CFL
这个结论和 [Theorem 1.2.3] Uniqueness of CFL 是两个很有趣的结论。
对于任意的串 \(s\),\(\operatorname{CFL}(s)\) 一定存在。
构造法。我们考虑,单个的字母一定是 Lyndon Word。
根据 [Theorem 1.2.1 Lyndon Concatanation],我们可以把字典序小的两个 Lyndon Word 并起来,所以我们把所有的字典序单增的序列都并起来,剩下的就是一个合法的 CFL。\(\blacksquare\)
Theorem 1.2.3 Uniqueness of CFL
对于任意的串 \(s\),\(\operatorname{CFL}(s)\) 一定唯一。
反证法,假设有两种方案。我们考虑第一个不同的位置的情况,可以很容易地得到矛盾,和 CFL 的定义矛盾。\(\blacksquare\)
然后我们就得到了 CFL 存在且唯一。由此有两个推论:
Theorem 1.2.4 Lyndon Suffixes and Lyndon Prefixes
\(w_1\) 是最长的 Lyndon 前缀且 \(w_k\) 是最长的 Lyndon 后缀。
反证法。因为如果 \(w_1\) 不是最长,那么还能再拼,产生了两个合法的 CFL,和 [Theorem 1.2.3 Uniqueness of CFL] 矛盾。所以 \(w_1\) 是最长的 Lyndon 前缀。
\(w_k\) 同理。\(\blacksquare\)
Theorem 1.2.5 Theorem of Minsuf
一个字符串 \(s\) 的最小后缀是 \(w_k\)。
首先,我们有这样的一个 CFL:

首先,我们记 \(w_n\) 的起始位置为 \(pos\),则显然

如图,最小后缀的其实位置不可能 \(>pos\),因为根据 Lyndon Word 的定义,\(w_n\) 的每个后缀都大于他自身。
接下来我们考虑最小后缀在另一个位置的情况,即他在另一个 \(w_i\) 之中

根据 \(w_i \ge w_{i+1}\ge \cdots \ge w_n\),而 \(w_i\) 的一个后缀 \(> w_i\),所以这个后缀大于 \(w_n\)。
所以唯一可能的最小后缀就是 \(w_n\)。
简单来说,假设最小后缀是 \({xw_{i+1}w_{i+2}\cdots w_{k}}\) 而不是 \(w_k\) 且 \(|x| < |w_i|\)。我们有 \({x w_{i + 1} \dots w_k} \geq x > w_i \ge w_k\),矛盾。\(\blacksquare\)
1.3 Duval's Algorithm
就是求出 CFL 的算法啦~
我们有一个非常优美的算法
简要思想:
$ {uav} \in \mathcal{L}\(,\)u,v,h \in \Sigma^*\(,\)a<b\in\Sigma\(,\)k\ge1$
- \({(uav)^k ub} \in \mathcal{L}\)
- \(\operatorname{CFL}({(ubv)^k uah}) = {(ubv)^k} \operatorname{CFL}({uah})\)
- \(\operatorname{CFL}({(uv)^k u}) = {(uv)^k} \operatorname{CFL}(u)\)
换成代码实现就是:
我们需要维护两个部分:\(ubv\) 和 \(u\)。
- 如果可以拼到当前的串的末尾就拼上去。
- 否则就是一个新的 Lyndon Word。(如果碰到一个比当前的小的东西,则我们更新 \(ubv\),否则我们就更新 \(u\))。
- 如果不满足 Lyndon Word 字段序递减的条件,则根据 [Theorem 1.2.1 Lyndon Concatanation],我们可以将两个 Lyndon Word 合并。
如果还是不太懂可以移步 oi-wiki,那里写的比较详细。
模拟即可,显然空间复杂度 \(\mathcal O(1)\)。接下来证明一下时间复杂度。
接下来证明一下复杂度为什么是对的。
最优情况为一个分解走到底,\(\mathcal O(n)\)。
最坏情况为不停地在重新找,由于至多回退 \(n\) 次,每次回退的距离不超过前进的距离,所以是 \(\mathcal O(n)\)。
Template
CFL 板子,欢迎来蒯。char *s 从 \(0\) 开始编号,int *ans 返回 CFL 的右端点(注意从 \(0\) 开始),函数返回的 int 是 Lyndon 串的个数。
inline int CFL(char *s, int *ans) {
int res = 0, n = strlen(s), i = 0, j, k;
while (i < n) {
j = i, k = i + 1;
while (k < n && s[j] <= s[k]) j = s[j] == s[k++] ? j + 1 : i;
while (i <= j) ans[res++] = i + k - j - 1, i += k - j;
}
return res;
}
Exercises
Ex A Minsuf of Prefixes
给定串 \(S\),求前缀的最小后缀。要求 \(\mathcal O(n)\)。
这是很裸的 Lyndon 的题吧……
不用 Lyndon 的话传统做法是后缀树,维护一下最右边的路径即可。然而是带 \(\log\) 的。
根据 [Theorem 1.2.5 Theorem of Minsuf],\(w_n\) 就是最小后缀,所以我们可以记忆化一下 CFL 分解:
我们知道,Lyndon 分解的时候是一个 Lyndon 串不停地在重复,如果碰到冲突会重新跳,我们考虑把这个东西记忆化,记为 \(\operatorname{minsuf}(i)\)。
然后这个问题就迎刃而解了。
Ex B Maxsuf of Prefixes
求前缀的最大后缀。
你可能看到这个问题会觉得把字典序反一下就好了,那也太 naive 了,试试自己举一个反例。
揭晓答案:\(\color{white}\text{我们在最小后缀之中需要的是字典序最短的,但是最大后缀要字典序最长的}\)。(试试复制一下,你就能看了)
但是好消息是这个问题可以用另一种非常 naive 的方法解决,把 Lyndon 串在分解的时候直接记一下,输出当前的串就好了。(感性理解一下
Ex C Minimal Rotation
最小循环表示
对着 \({x}\) 求一遍 CFL,找到前半串开始的最长 Lyndon Word 就是了。时间复杂度 \(\mathcal O(n)\)。
FAQ:诶,这用最小表示不是更好做吗?A:但是你用 Lyndon 不就能少学一个算法吗= =
代码可以看 xht 的。
Ex D [Moscow 2012] Darkwing Duck
给你一个串 \(S\ (|S|\le 5\times 10^5)\)。给你 \(q\) 个询问,每次询问 \(\operatorname{maxsuf}(s[l..r])\) 的下标。
这个显然可以SA,但是这个问题其实是可以使用 Lyndon 的知识解决的。
首先我们以 \(r\) 为关键词离线所有的询问,所以现在这个东西变成这样了:
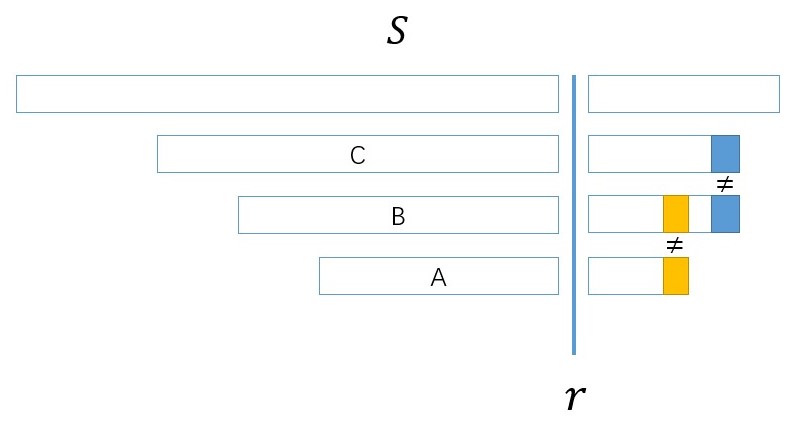
我们定义一个位置 \(i\) 是有用的当且仅当 \(f(i\cdots r)\) 是 Lyndon 的。
我们有一堆 \(i\),他们有这些特点:他们满足一种后缀关系(废话
我们可以维护一个类似栈的东西,把相邻的两个点 LCP 算出来,比如:
C 和 B 在某个位置不同,B 和 A 在某个位置不同。我们把小的删掉,一直删光。
如果我们要回答询问,我们可以 std::lower_bound 求出 \(l\) 右边的第一个。
如果你不想离线,我们把一个 \(r\) 对应的集合用主席树记下来,也可以做的。
时间复杂度 \(\mathcal O(n \log n)\)。
Ex E [Yandex.Algorithm 2015 Round 2.2] Lexicographically Smallest String
题意:给你一个字符串 \(S\),你可以选择任意一个区间进行翻转,使操作后的字符串字典序最小。\(|S| \le 10^7\)
来观察性质。
Lemma:如果我们在开头有一个不大于其他所有的字符的字符,则我们一定不动这个字符,否则一定会反转某一个前缀。
假设翻转一个前缀 \(s[1..t]\) 后的第一个字符比当前的小,则显然 \(s[t] < s[1]\),矛盾。
如果第一个字符不是最小,那么我们应该找到最小的字符 \(s[t]\) 并且翻转前缀 \(s[1..t]\),使得第一个字符成为最小。\(\blacksquare\)
既然我们要考虑一个翻转的区间,则我们不妨把原创翻转的结果记为 \(S^R\)。
我们考虑翻转过后的一个前缀是 \(S^R\) 中的一个后缀,而我们要求翻转之后的字典序最小,所以我们需要挑选 \(S^R\) 中的最小后缀(这里的最小后缀和一般说的有所不同,只要比其他不存在前缀关系都要小即可,所以可能不止一个)。
可以发现,所以符合条件的后缀都是最长的一个的前缀。
我们注意到,一个串 \(S'\) 是可以表示成若干的 \(w\) 的幂和一个 \(w\) 的前缀。
接下来我们考虑什么时候需要翻转。
如果 \(|A|=|B|\),则 \(A + A + C < A + C + B < C + B + B\) 或 \(A+A+C>A+C+B>C+B+B\) 或 \(A+A+C=A+C+B=C+B+B\)。
我们考虑 \(A=w, B=w^R,C=w'\) 的情况,发现满足条件的后缀之中只有最长的和最短的后缀可能对答案产生贡献。
接下来我们应该使用 Duval 算法来找到 \(\operatorname{CFL}(S^R)\) 来找到这些后缀。
时间复杂度 \(\mathcal O(n)\)。
Ex F Cutting the Line
题意:给你一个字符串 \(S\),你可以把他分成 \(k\) 段,并且翻转其中的若干段,使操作后的字符串字典序最小。\(1\le k\le |S| \le 5\times 10^6\)
留作习题。
2 Significant Suffixes
2.1 Definition
我们令 \(\operatorname{minsuf}(u)\) 为 \(u\) 的最小后缀,且 \(\operatorname{minsuf}(u, v) = \min _{w \in \operatorname{suf}(u)} wv\)。
Significant Suffixes:\(\Lambda(u) = \arg\min_{w\in \operatorname{suf}(u)} wv\)。
\(\operatorname{minsuf}(s)\) 表示 S 字典序最小的后缀,且
由 \(\operatorname{minsuf}\) 的性质可知,\(\operatorname{minsuf}(u, \epsilon) = \operatorname{minsuf}(u)\)。\(\implies \operatorname{minsuf}(u) \in \Lambda(u)\)。
所以,显然 \(\forall u \in \Lambda(u),\ \operatorname{minsuf}(u) \sqsubseteq u\)。
我们注意到一个 CFL 分解中的 Lyndon Words 是存在一定的循环的。因此,我们可以记一个 CFL 为次方的形式。
\]
我们记 \(s_i\) 为一个后缀,即 \(s_i = {{w_i}^{k_i}{w_{i+1}}^{k_{i+1}}\cdots{w_n}^{k_n}}\)。边界:\(s_{n+1} = \epsilon\)。
2.2 Significant Theorem
首先,我们需要一个引理。
Theorem 2.2.1 Infinite Theorem
在 [Theorem 2.2.2 Significant Suffixes Theorem] 里面会用到,建议先食用下一个 Theorem。
如果 \(u^\infty < v\),则 \(v > {uv} > {u^2v} > \cdots\)。
\(u^\infty < v \implies u^\infty < {uv}\)。
令 \(u = {xay}\),\(v = {(xay)^k xbh}\),其中 \(x,y,h\in\Sigma^*\),\(a,b\in\Sigma\),\(a<b\)。
我们有 \(v \succ uv \Longleftrightarrow (xay)^{k - 1} xbh \succ (xay)^k xbh \Longleftrightarrow xbh \succ (xay) xbh\)。
\(v>{uv} \implies {u^iv} > u^{i+1} \implies \blacksquare\)
同理如果 \(u^\infty > v\),则 \(v < {uv} < {u^2v} < \cdots\)。
Theorem 2.2.2 Significant Suffixes Theorem
\[\Lambda(u)\subseteq \{s_i | i \in [1,n]\}
\]
反证法:如果这个命题不成立,则我们分类讨论
i) 假设有一个串 \(v = {b{w_i}^ks_{i+1}} \in \Lambda(u)\),\(|b| < |w_i|,\ 0 \le k < k_i\)。
\(w_i \in \mathcal L \implies w_i \triangleleft b \implies s_i = {w_is_{i+1}} < {bs_{i+1}}\),矛盾。
ii) 假设有一个串 \(v = {{w_i}^ks_{i+1}} \in \Lambda(u)\),\(1 < k < k_i\)。
根据 [Theorem 2.2.1 Infinite Theorem],如果 \({w_i}^\infty < s_{i+1}\),则 \({{w_i}^{k_i}s_{i+1}} < {{w_i}^{k_i - 1}s_{i+1}}<\cdots<s_{i+1}\),否则 \({{w_i}^{k_i}s_{i+1}} > {{w_i}^{k_i-1}s_{i+1}} > \cdots > s_{i+1}\)。
我们令 \(\lambda = \min \{i : s_{i+1} \sqsubset s_i\}\)。\(\forall i \ge \lambda, \ w_i = {s_{i+1}y_i},\ x_i = {y_is_{i+1}}\)。\(\implies s_i = {{w_i}^{k_i}s_{i+1}}= {(s_{i+1}y_i)^{k_i}s_{i+1}} = {s_{i+1}{x_i}^{k_i}}\)。
根据 CFL 的性质,\(s_{\lambda} \triangleleft w_{\lambda - 1}\)。所以 \(\Lambda(u)\subseteq \{s_i | i \in [1,n]\}\)。\(\blacksquare\)
2.3
Theorem 2.3.1 Lambda Subset Theorem
如果有 \(2\) 个串 \(u\) 和 \(v\),满足 \(|u| \le |v|\),则我们有
\[\begin{aligned}\Lambda(uv) &\subseteq \Lambda(v) \cup \{\operatorname{maxsuf}^R(u, v)\} \\&= \Lambda(u) \cup{\max _{s \in \Lambda(u)}}^R \{sv\}\end{aligned}
\]
理由很简单,因为 \(\{\operatorname{maxsuf}^R(u, v)\}\) 也是一个 Significant Suffix,随意我们就可以把它展成第二行的式子的形式。\(\blacksquare\)
Theorem 2.3.2 Significant Suffixes Log Theorem
一个字符串 \(S\) 的 Significant Suffixes 至多有 \(\log n\) 个。
原命题可以很容易地转化为:
如果两个 Significant Suffixes \(u\),\(v\) 满足 \(|u| < |v|\),那么 \(2|u| < |v|\)。
反证法。设存在 \(|u| < |v| < 2|u|\)。因为 \(u, v \in \operatorname{suf}^+(u)\),所以 \(u \in \operatorname{suf}^+(v)\)。
所以我们可以非常容易地知道,\(u \triangleleft v\)。\(\implies v\) 有一个长度为 \(|v| - |u| < \frac {|v|} 2\) 的周期,记为 \(T\)。
所以,\(u = {Tw}, v = {T^2w}\)。
由于 \(u\) 是一个 Significant Suffix,因此存在串 \(t\),满足 \(vt>ut\),即 \({T^2wt} > {Twt} \implies {Twt} > {wt}\)。
而 \(w \in \operatorname{suf}^+(s)\),所以与 \(u\) 是 Significant Suffix 矛盾。\(\blacksquare\)
2.4 Facts
我们知道 \(\Lambda(S)\) 中有很多串,其中最短的是 \(\operatorname{minsuf}(S)\),而最长的是 \(\operatorname{maxsuf}^R(S)\)。这里的 \(^R\) 代表 reverse。
- \(\Lambda(u) = \{s_{\lambda}, \cdots, s_{n+1}\}\)
- \(\operatorname{minsuf}(u) = s_n\)
- \(\operatorname{maxsuf}^R(u) = s_\lambda\)
- \({x_\lambda}^\infty > \cdots > {x_m}^\infty\)
- 我们有一个串 \(v\),\({x_i}^\infty > v > {x_{i+1}}^\infty\)。则 \({s_\lambda v} > \cdots > {s_{i+1}v} < \cdots < {s_kv}\)。
- 对于两个串 \(u\) 和 \(v\),有 \(|u|<|v|\),\(\Lambda({uv}) \subseteq \{\operatorname{maxsuf}^R(u, v)\} \cup \Lambda(v) = \{\min_{w \in \Lambda(u)}{wv}\} \cup \Lambda(v)\)。
这里的 Proof 先咕着吧。贴个 Reference:
Tomohiro, I., Nakashima, Y., Inenaga, S., Bannai, H., & Takeda, M. (2016). Faster Lyndon factorization algorithms for SLP and LZ78 compressed text. Theor. Comput. Sci., 656, 215-224.
Kociumaka, T. (2016). Minimal Suffix and Rotation of a Substring in Optimal Time. ArXiv, abs/1601.08051
Exercises
Ex G [JSOI2019] 节日庆典
留作习题。
Ex H [ZJOI2017] 字符串
简要题意:维护动态字符串,值域 \(10^9\),区间加,求区间 \(\operatorname{minsuf}\) 的位置。\(|S| \le 2 \times 10 ^ 5,m \le 3 \times 10 ^ 4\)
前置芝士:Lyndon 分解,Significant Suffixes,线段树,字符串哈希,分块。
我们先考虑不带修的情况。
由 [Theorem 2.3.1 Lambda Subset Theorem],我们可以很容易地想到考虑建一棵线段树来维护 Significant Suffixes。
细节:如果线段树的 mid = l + r >> 1,则左边的区间比右边长一些。但是上面的这个结论对于 \(|u| \le |v|\) 有效,所以我们需要调整一下,使得左儿子比右儿子要长一些(即:mid = l + r + 1 >> 1,使得左儿子总不比右儿子短)
可以存一下当前代表的串的所有 Significant Suffixes,然后直接考虑合并(把右边的所有的直接加进来,左边的都循环一遍,字典序最长的加进去)得到父节点的 Significant Suffixes 即可。(看不懂的看代码)
由 [Theorem 2.3.2 Lambda Log Theorem] 可知,每一个集合都是 \(O(\log n)\) 大小的。这样的话,我们求出了每一个线段树上的区间的 Significant Suffixes。然后查询就在这 \(O(\log n)\) 个区间内求 Significant Suffixes 的并,暴力比较即可。所以我们需要一个 \(O(1)\) 比较两个串的方法(否则复杂度就挂了)。所以如果不带修的话我们可以考虑 SA。
接下来考虑带修的情况。
我们需要快速地求两个串的 LCP,又有一个线段树,所以可以很自然地想到一个线段树+字符串哈希+二分LCP的算法。复杂度 \(O(q \log^4 n)\),慢了点,我这种人傻常数大的就不用想了。
我们考虑分块维护一些哈希,分 \(\sqrt n\) 的块。我们维护一下每个点到块的末端的哈希值,然后维护一下每个块到串的末尾的哈希值。然后我们可以记一个块的全局的偏移量,就可以算了。每次查询的时候,我们只需要查 \(2\) 次即可,\(O(1)\) 查找。最终是 \(O(q \log ^3 n + q\sqrt n)\) 的复杂度。
Q: 道理我都懂,但是为什么我挂了? A: 你是用了自然溢出哈希吧,换个双哈希试试。
3 Lyndon Array
3.1 Definition
我们有一个字符串 \(s\),则
Lyndon Array:\(\mathcal L[i] = \max \{j : s_i \cdots s_{j-1} \in L\}\),其中 \(L\) 表示 Lyndon 串的集合。在 \(\prec_l\) 意义下的 \(\mathcal L\) 记为 \(\mathcal L_l\)。
这有啥子用?别急,先看性质。
3.2 Non Intersecting Substrings
Theorem 3.2.1 Non Intersecting Lyndon Substrings
最长的 Lyndon 子串是无交集的,即 \(i < j < \mathcal L[i]\),我们有 \(\mathcal L[j] \le \mathcal L[i]\)。
我们假设存在 \(i,j\) 使得 \(\mathcal L[i] < \mathcal L[j]\)。
我们假设 \(u = s_i \cdots s_{j-1}\),\(v = s_j \cdots s_{\mathcal L[i] - 1}\),\(w = s_{\mathcal L[i]} \cdots s_{\mathcal L[j] - 1}\),且 \(u,v,w\) 满足 \({uv}, {vw} \in L\)。
对于所有的 \(s \in \operatorname{suf}^+({uvw})\),且满足 \(|s| \le |v| + |w|\),有 \(s \triangleleft {vw} \sqsupseteq v \triangleleft {uv}\)。\(\implies {uvw} \triangleleft s\)。
对于所有的 \(s \in \operatorname{suf}^+({uvw})\),且满足 \(|s| > |v| + |w|\),有 \({svw} \sqsupseteq {sv} \triangleleft {uv}\)。\(\implies {uvw} \triangleleft {svw}\)。
所以 \({uvw} \in L\),矛盾。\(\blacksquare\)
3.3 Suffix & Lyndon Arrays
我们设 \(\operatorname{suf}(i) = s_i \cdots s_{n-1}\),即一个后缀。
而我们有 \(s_i \cdots s_{\mathcal L[i] - 1} \triangleleft s_j \cdots s_{\mathcal L[i] - 1}\)。
\(\implies \operatorname{suf}(i) \triangleleft \operatorname{suf}(j)\quad(i<j<\mathcal L[i])\)
于是我们设
\]
显然 \(\mathcal L[i] \le \operatorname {NSV}(i)\)。
我们还有 \(\neg(\operatorname{suf}(i) \triangleleft \operatorname{suf}(j)) \Longleftrightarrow \operatorname{suf}(j) \sqsubseteq \operatorname{suf}(i) \vee \operatorname{suf}(j) \triangleleft \operatorname{suf}(i) \Longleftrightarrow \operatorname{rank}(i) > \operatorname{rank}(j)\)。
Theorem 3.3.1 NSV Theorem
有了上述定义,证这个是不是非常简单呢 XD
\(\mathcal L[i] = \operatorname{NSV}(i)\)
原命题可以很方便地转化为 \(s_i \cdots s_{\operatorname{NSV}(i) - 1} \in L\)。
分类讨论:
如果 \(\operatorname{NSV}(i) = n\),\(s_i \cdots s_{\operatorname{NSV}(i) - 1} = \operatorname{suf}(i)\)
否则的话我们肯定有一些 \(j\) 使得 \(\operatorname{suf}(i) \triangleleft \operatorname{suf}(j)\)。
然后我们继续来讨论:
i) 如果 \(s_1 \cdot s_{\operatorname{NSV}(i) - 1} \triangleleft s_{j} \cdots s_{\operatorname{NSV}(i) - 1}\),易证。
ii) 反之,结合 \(\operatorname{suf}(i + (\operatorname{NSV}(i) - j) - 1) \triangleright \operatorname{suf}(i)>\operatorname{suf}(\operatorname{NSV}(i))\),易证矛盾。(你看不出来?明显与 \(\operatorname{suf}(i) \triangleright \operatorname{suf}(j)\) 矛盾)。\(\blacksquare\)
Exercises
Ex I 简单字符串
留作习题。
4 Runs
4.1 Definition
这个东西的英文名是 runs,他的中文名是顶天立地串……(好中二啊)
我们有一个串,runs 是他的一些子串,满足:
\(p = \operatorname{per}(s_i\cdots s_{j-1})\le \dfrac {j-i}2\),\(s_{i-1} \ne s_{i-1}+p\),\(s_{j-p}=s_{j}\)
更好理解的定义:
定义一个字符串 \(|S|\) 里的一个 run,指其内部一段两侧都不能扩展的周期子串,且周期至少完整出现两次。
严格地说,一个 run 是一个 三元组 \((i,j,p)\),满足 \(p\) 是 \(S[i..j]\) 的最小周期,\(j-i+1 \ge 2p\),且满足如下两个条件:
- 要么 \(i=1\),要么 \(S[i-1]\ne S[i-1+p]\);
- 要么 \(j=n\),要么 \(S[j+1] \ne S[j+1-p]\)。
例如:\(S = \text{aababaababb}\) 之中有 7 个 runs:\(S[1..2] = \text a^2\),\(S[1..10] = (\text{aabab})^2\),\(S[2..6] = (\text{ab})^{2.5}\),\(S[4..9] = (\text{aba})^2\),\(S[6..7] = \text a^2\),\(S[7..10] = (\text{ab})^2\),\(S[10..11] = \text b^2\)。
(实际上是 LOJ #173 的题面,题目是我造的,这一段是 EtoainWu 的文字)
定义 \(Runs(w)\) 表示字符串 \(w\) 的所有 runs 的集合。
\(\rho(n)\) 表示了在一个长为 \(n\) 的字符串之中至多有多少组 runs,而 \(\sigma(n)\) 表示了在一个长为 \(n\) 的字符串之中所有 runs 的幂之和的最大值。
Lyndon Root:令 \(r=(i,j,p)\) 是一个run,则他的 Lyndon Root 是一个 \(s[i..j]\) 的长度为 \(p\) 的 Lyndon 子串。
每一个 run 都有一个 Lyndon root。
4.2 Linear Runs
Theorem 4.2.1 Linear Runs Theorem
我们假设 \(\prec^0\) 表示 \(<\),而 \(\prec^1\) 表示 \(<^R\)。(此处的 \(^R\) 表示 reverse,给 \(\prec\) 标号是为了方便)
\(\prec^0\) 和 \(\prec^1\) 的对应的 Lyndon Array 是 \(\mathcal L^0\) 和 \(\mathcal L^1\).
\(\rho(n) \le 2n\)
原命题可以转化为
对于每个 runs,我们有存在 \(i\) 和 \(t\) 使得 \(s[i..\mathcal L^t[i] - 1]\) 是 Lyndon root。
我们令 \(w\) 是 Lyndon root,\(w=s[k..s-1]\)。
分类讨论:
如果 \(j=|S|\),
我们可以把 \(s[k .. |S| - 1]\) 表示成 \({w^pw'} \ (p \in N, w' \in \operatorname{pref}(w))\)。
因为 \(\operatorname{CFL}({w^pw'}) = {w^p\operatorname{CFL}(w')}\),所以 \(w\) 是从 \(k\) 开始的最长 Lyndon 前缀。
如果 \(j<|S|\),
我们可以把 \(w\) 表示成 \({uab}\),其中 \(a \ne b\)。
所以我们可以把 \(s_k \cdots s_{|S| - 1}\) 表示成为 \({(uav)^pub}\)。
我们不妨假设 \(b \prec^t a\)、
因为我们有 \(\operatorname{CFL}^t({(uav)^pubh}) = (uav)^p\operatorname{CFL}^t({ubh})\),所以 \({uav}\) 是 \(\prec^t\) 下的最长 Lyndon 前缀。\(\blacksquare\)
Theorem 4.2.2 The "Runs" Theorem
\(\rho(n)<n,\sigma(n)\leq3n-3\)
几乎从 WC2019 课件搬运的证明
定义 \(Beg(I)\) 表示 \(I\) 中所有区间的起始端点的集合。
Lemma A
对于一个串的 Lyndon Array \(\mathcal L^0[i]\) 和 \(\mathcal L^1[i]\),总有 \(\mathcal L^{l}[i] = [i..i], \mathcal L^{1-l}[i] = [i..j] (j\ne i)\),其中 \(l\in \{0,1\}\)。
令 \(k=\max\{k'\ |\hat{w}_{k'}\ne \hat{w}_i,k'>i\}\)。
由 [Theorem 1.2.1 Lyndon Concatanation] 可得:
- 若 \(\hat w_k < \hat w_i\),则 \(\mathcal L^0[i]=[i..i]\),且 \(\mathcal L^1[i]=[i..j]\ (j\geq k>i)\)。
- 若 \(\hat w_k > \hat w_i\),则 \(\mathcal L^1[i]=[i..i]\),且 \(\mathcal L^0[i]=[i..j]\ (j\geq k>i)\)。\(\blacksquare\)
Lemma B
若 \(r=(i,j,p)\) 为一个run,则对于 \(\hat{w}[j+1]\prec_l \hat{w}[j+1-p]\) 的 \(l\),\(\forall r\) 的 \(\prec_l\) 意义下的 Lyndon Root \(\hat w[i_{\lambda}..j_{\lambda}]\) 都与 \(\mathcal L^l(i_{\lambda})\)相等。
\(\because \hat{w}[j+1]\ne\hat{w}[j+1-p]\),令 \(l\in\{0,1\}\) 满足 \(\hat{w}[j+1]\prec_l\hat{w}[j+1-p]\)。
令 \(\lambda=[i_{\lambda}...j_{\lambda}]\) 为 \(r\) 的 \(\prec_l\) 意义下的一个 Lyndon Root,由 [Theorem 1.2.1 Lyndon Concatanation],\([i_{\lambda}...j_{\lambda}]=\mathcal L^l(i_{\lambda})\)。\(\blacksquare\)
对于一个run \(r=(i,j,p)\),令 \(B_r=\{\lambda=[i_{\lambda}...j_{\lambda}]|\lambda\) 为 \(r\) 的 \(\prec_l\) 意义下的一个 Lyndon Root 且 \(i_{\lambda}\ne i\}\)。即 \(B_r\) 表示所有 \(r\) 的关于 \(\prec_l\) 的 Lyndon Root 构成的集合,但要除去开头位置 \(i\) 处开始的 Lyndon Root。有 \(|Beg(B_r)|=|B_r|\geq \lfloor e_r-1\rfloor\geq 1\),其中 \(e_r\) 为 \(r\) 的指数。
Lemma C
两个不同的 run \(r,r'\),\(Beg(B_r)\cap Beg(B_{r'})\) 为空。
反证,假设存在 \(i\in Beg(B_r)\cap Beg(B_{r'})\),并且 \(\lambda=[i...j_{\lambda}]\in B_r\),\(\lambda'=[i...j_{\lambda'}]\in B_{r'}\)。
令 \(l\in\{0,1\}\) 满足 \(\lambda=\mathcal L^l[i]\),由于 \(\lambda\ne \lambda'\),有 \(\lambda'=\mathcal L^{1-l}[i]\)。
由 Lemma A,\(\lambda\) 和 \(\lambda'\) 中有且只有一个为 \([i..i]\)。
不妨设 \(\lambda=[i..i]\),那么 \(j_{\lambda'}>i\)。
由于 \(w[i...j_{\lambda'}]\) 为一个 Lyndon Word,有 \(w[i]\ne w[j_{\lambda'}]\)。
由 \(B_r\) 和 \(B_{r'}\) 的定义,\(r\) 和 \(r'\) 的开始位置均小于 \(i\),这意味着 \(w[i-1]=w[i]\)(由 \(r\) 的周期性),并且 \(w[i-1]=w[j_{\lambda'}]\)(由 \(r'\) 的周期性)。矛盾 \(\blacksquare\)
任意的一个 run \(r\) 可以被赋予一个两两不交的非空位置集合 \(Beg(B_r)\)。并且,由于 \(1\notin Beg(B_r)\) 对于任意的一个 \(r\) 均成立,有 \(\sum_{r\in Runs(w)}|B_r|=\sum_{r\in Runs(w)}|Beg(B_r)|\leq |w|-1\)。
考虑字符串 \(w\),由于对于任意 \(r\in Runs(w)\),有 \(|B_r|\geq1\),由 Lemma C,有 \(|Runs(w)|\leq\sum_{r\in Runs(w)}|B_r|\leq |w|-1\)。
考虑字符串 \(w\),令 \(e_r\) 表示 \(r\) 的指数。由于对于任意 \(r\in Runs(w)\),有 \(|B_r|\geq \lfloor e_r-1\rfloor>e_r-2\),由 Lemma C,有 \(\sum_{r\in Runs(w)}(e_r-2)<\sum_{r\in Runs(w)}\lfloor e_r-1\rfloor\leq\sum_{r\in Runs(w)}|B_r|\leq |w|-1\)。因为 \(|Runs(w)|\leq |w|-1\),可得 \(\sum_{r\in Runs(w)}e_r\leq3n-3\)。\(\blacksquare\)
4.3 Details about Implementation
在实现 Runs 之前,你需要会字符串哈希或者后缀数组或者其他后缀数据结构。
根据以上证明中的 Lemma B,每一个 runs 都会对应一个 Lyndon root,所以如果我们把 Lyndon Array 算出来了,就可以把每个 runs 对应的 Lyndon root 求出来。
那么我们怎么求 Lyndon Array \(\mathcal L^0\) 和 \(\mathcal L^1\)?
\]
而
\]
所以我们考虑对于字符串的每个后缀都维护他的 CFL,方法是在头上插入一个新字符,然后判断是否合法。根据 [Theorem 1.2.1 Lyndon Concatanation],如果遇到一个 Lyndon word 大于下一个的情况,合并即可。可以保证正确性。
这里有一个实现上的细节,可能会好写一点。根据 [Theorem 1.2.4 Lyndon Suffixes and Lyndon Prefixes],\(w_i\) 是 \(w_iw_{i+1}\cdots w_k\) 的最小前缀,所以比较两个 Lyndon word 的字典序相当于比较两个后缀的大小,而这个是比做一个 lcp 要简单多的。
所以至此 Lyndon Array 已经求完了,具体实现细节可以看代码。
接下来我们只要使用 Lyndon Array 扩展出 runs 就可以了,具体的做法是求出 lcp,即如果当前的 Lyndon Array \(\mathcal L[i] = (l..r)\),则我们 lcp 求出最长的 \(s[l..l+l_1-1]=s[r+1..r+l_1], s[l-l_2..l-1]=s[r-l_2..r-1]\)。
根据 runs 的定义,如果 \(l_1 + l_2 \ge 2(l - r + 1)\),那么我们就找到了一个 run \((l-l_2, r+l_1-1, r-l+1)\)。
如果我们使用 \(\mathcal O(n \log n)\) 的 SA 和 \(\mathcal O(n \log n)-\mathcal O(1)\) 的 rmq 算法,我们就可以在 \(\mathcal O(n \log n)\) 的时间复杂度之内求出所有的 runs。
如果我们使用 SAIS 和 \(\mathcal O(n) - \mathcal O(1)\) 的 rmq 算法,我们就可以 \(\mathcal O(n)\) 求出所有的 runs。
比较优秀的 \(\mathcal O(n) - \mathcal O(1)\) 的 rmq 方法:叉姐的 和 hqztrue的。
Template
是我出的啦owo
5 Lyndon Tree
5.1 Definition
标准划分:把一个 Lyndon Word 划分为他的字典序最小的后缀和其余的部分。两部分一定是 Lyndon Word。
Lyndon Tree:每一个节点都是一个 Lyndon Word,左儿子和右儿子对应一个标准划分。
\(\operatorname {Ltree}(S)\) 表示一个根节点为 \(S\) 的 Lyndon Tree。
如图是一个串 \(\text{aababbaababa}\) 的 Lyndon Tree:(论文图真香)

我们先来观察性质,他是一棵笛卡尔树,所以如果你不嫌麻烦的话可以用 Lyndon Tree 实现线性 runs。
性质:如果我们的 Lyndon Tree 有一个 Lyndon word,记为 \(s[i..j]\),那么从 \(i\) 到 \(j\) 所有叶节点的 LCA 是 \([i..k]\),其中 \(i \le j \le k\)。如果这个 Lyndon Word 是从 \(i\) 开始的最长 Lyndon 串,则 LCA 一定是一个右子节点。如果 \(i=1\),则 LCA 为根节点。
5.2 Weak Periodicity Lemma
Theorem 5.2.1 Weak Periodicity Lemma
我们有一个串 \(S\) 有 \(p,q\) 两个周期,满足 \(p<q\) 且 \(p + q \le |S|\),则 \(\gcd(p,q)\) 也是 \(S\) 的周期。
这个应该很显然把……
显然,\(S_i = S_{i+q} = S_{i-p+q} = S_{i-p} = S_{i-p+q}\)。所以 \(q-p\) 也是 \(S\) 的周期。
然后辗转相除法可以证得 \(\gcd(p,q)\) 也是 \(S\) 的周期。\(\blacksquare\)
Fact 5.2.2 Periodicity Lemma
事实上有一个更强的结论。
我们有一个串 \(S\) 有 \(p,q\) 两个周期,满足 \(p<q\) 且 \(p + q - \gcd(p,q) \le |S|\),则 \(\gcd(p,q)\) 也是 \(S\) 的周期。
5.3 2-Period Queries
经典问题,可能是 Lyndon tree 的唯一应用= =
\(S\) 是一个串,询问 \(S\) 的某个子串有没有不超过长度一半的周期,如果有就求出最小周期。
我们定义一个 run 是一个 \(\operatorname{exrun}(i,j)\) 当且仅当他是 \((i', j', p)\) 满足 \(i' \le i, j' \ge j, p \le (j-i+1)/2\)。
根据 [Theorem 5.2.1 Weak Periodicity Lemma],exrun 唯一。如果我们找出了 \(\operatorname{exrun}(i,j)\),则我们就可以回答询问。
我们先构造出两棵 Lyndon Tree \(\operatorname {Ltree}^0(S)\) 和 \(\operatorname {Ltree}^1(S)\)。
然后我们在两棵 Lyndon Tree 上面分别寻找从 \(i\) 到 \((i+j)/2\) 的 LCA,判断其右子节点的 runs 是否符合 exrun。
证明留作习题。
听说可以搬到树上什么的……还是不要出这种东西吧……
6 Three Squares Lemma
6.1 Definition
Squares: 能表示成 \(x^2\) 的串。
Primitive Squares: 不能再拆的 Squares,即最小周期为自身长度的一半的字符串。如 \(x^2+x\) 一定是一个 Primitive Square。
6.2 Three Squares Lemma
Theorem 6.2.1 Three Squares Lemma
我们有 3 个 Primitive Squares,为 \(u^2\),\(v^2\) 和 \(w^2\),满足 \(|u|<|v|<|w|\)。
则我们有 \(|u| + |v| \le |w|\)。
反证法,假设 \(|u|+|v| > |w|\) 成立,则 \(|w|-|v|\) 为 \(u\) 和 \(v\) 的周期。
如果 \(2|u| \le |v|\),则 \(|w|-|v| < |u|\) 是 \(u^2\) 的周期,故 \(u^2\) 不是一个 Primitive Square,矛盾。
否则,\(|u|\) 和 \(|w|-|v|\) 都是 \(v\) 的周期,而 \(u^2\) 是一个 Primitive Square,所以 \(u\) 不是一个周期串,则 \(|u|+|w|>2|v|\)。
我们令 \(w=vs_1\),\(u=s_1s_3\),\(v=ws_2=s_1s_3s_2\)。显然,\(|s_2| < |s_1|\)。
考虑串 \(s_3 s_2\),它有周期 \(|s_2|\)。由于 \(|s_1|\) 是 \(u\) 的周期,可得 \(s_3s_2\) 是 \(u\) 的前缀,所以 \(|s_3|\) 也是它的周期。
根据 [Theorem 5.2.1 Weak Periodicity Lemma],\(r=\gcd(|s_2|,|s_3|)\) 是它的周期。而 \(|s_2|\) 本身同时是 \(u\) 的周期,因此可得 \(r\) 是 \(u\) 的周期。
接着考虑串 \(u=s_1s_3\)。它的周期有 \(|s_1|\) 和 \(r\),而 \(r\le|s_3|\),根据 [Theorem 5.2.1 Weak Periodicity Lemma],\(r'=\gcd(r,|s_1|)\) 也是 \(u\) 的周期。然而 \(|s_1|\) 和 \(|s_3|\) 都是 \(r'\) 的倍数,这表示 \(u^2\) 也有周期 \(r'\),矛盾。\(\blacksquare\)
由此我们有 2 个显然的结论:
Theorem 6.2.2 Number of Primitive Squares
Primitive Squares 的数量级为 \(\mathcal O(n\log n)\)。
显然。
Theorem 6.2.3 Different Primitive Squares
本质不同的 Primitive Squares 不超过 \(2n\) 个。
每个位置最多出现 2 个以这个位置为结尾的 Primitive Squares。\(\blacksquare\)
6.3 Implementation
首先我们可以想到一种十分显然的方法,因为数量级为 \(\mathcal O(n \log n)\),而 primitive squares 一定是 runs 的一部分,所以所以我们可以在每一个 runs 上面暴力求是否有 runs。时间复杂度 \(\mathcal O(n \log n)\)。
方法二,枚举平方串的长度,lcp。
7 扯淡
我在出 LOJ #173 的时候,发现有一个非常强的暴力,就是暴力地去做 lcp 和 lcs。
后来我经过不懈努力使用 aaaaa...ab 这个串卡掉了他,但是其实考场上如果时间不够的话写这个暴力其实是非常优秀的,毕竟我见过的两个 runs 题都没有卡这个暴力。
Exercises
Ex J [集训队作业2018] 串串划分
给你个串 \(S\ (|S| \le 10^5)\),切成若干段,其中每一段是 primitive 的,且相邻两个串是不相等的。求方案数模 \(998244353\)。
首先考虑 dp。\(f_i\) 表示 \(\operatorname{suf}(i)\) 的划分方案数。可以得到这么一个柿子:(当然,如果考虑划分前缀也是可以的
\]
其中,\(\sigma(s)\) 是这样定义的:对于字符串 \(s\),他的最小循环节的循环的长度为 \(\sigma(s)\)。
比如,对于串 \(\color{blue}\text{abcabcabc}\color{red}\text{defg}\),他的 \(\sigma = 3\),因为 \(\color{blue}\text{abc}\) 为最小循环节,循环了 \(3\) 次。
这个复杂度是 \(\mathcal O(n^2)\),无法接受。
考虑优化:把循环串分成一个初始的循环串和一些循环,分开计算贡献。
我们认为一个循环串初始的时候的最小周期一定是大于等于长度的一半的(否则会重复的)。
\]
然于是我们把 Primitive squares 和 runs 求出来转移就好了。时间复杂度为 \(\mathcal O(n \log n)\)。
Ex K [ZJOI2020] 字符串
留作习题。
Reference
- Roger Conant Lyndon. On Burnside’s problem. Transactions of the American Mathematical Society, 77(2):202–215, 1954.
- Jean-Pierre Duval. Factorizing words over an ordered alphabet. Journal of Algorithms, 4(4):363–381, 1983.
- https://www.luogu.com.cn/blog/xht37/solution-p1368
- https://oi-wiki.org/string/lyndon/
- https://codeforces.ml/blog/entry/18538?locale=en
- Babenko, M.A., Gawrychowski, P., Kociumaka, T., Kolesnichenko, I.I., & Starikovskaya, T. (2016). Computing minimal and maximal suffixes of a substring. Theor. Comput. Sci., 638, 112-121.
- Tomohiro, I., Nakashima, Y., Inenaga, S., Bannai, H., & Takeda, M. (2016). Faster Lyndon factorization algorithms for SLP and LZ78 compressed text. Theor. Comput. Sci., 656, 215-224.
- Kociumaka, T. (2016). Minimal Suffix and Rotation of a Substring in Optimal Time. ArXiv, abs/1601.08051
- WC2019 营员交流
- https://zhuanlan.zhihu.com/p/85169630
- https://yhx-12243.github.io/OI-transit/records/lydsy4877%3Blg5211%3Buoj296%3Bloj2572.html
Lyndon 相关的炫酷字符串科技的更多相关文章
- :after和:before炫酷用法总结
引入 提到伪类,在我的印象中最常用的不过是:hover.:active.:link.:visited,还有css3里的常用伪类选择器:last-child.:first-child.nth-child ...
- 25 个 Linux 下最炫酷又强大的命令行神器,你用过其中哪几个呢?
本文首发于:微信公众号「运维之美」,公众号 ID:Hi-Linux. 「运维之美」是一个有情怀.有态度,专注于 Linux 运维相关技术文章分享的公众号.公众号致力于为广大运维工作者分享各类技术文章和 ...
- 初级开发者也能码出专业炫酷的3D地图吗?
好看的3D地图搭建出来,一定是要能为开发者所用与业务系统开发中才能真正地体现价值.基因于此,CityBuilder建立了与ThingJS的通道——直转ThingJS代码,支持将配置完成的3D地图一键转 ...
- HTML5打造的炫酷本地音乐播放器-喵喵Player
将之前捣腾的音乐频谱效果加上一个播放列表就成了现在的喵喵播放器(Meow meow Player,额知道这名字很二很装萌~),全HTML5打造的网页程序,可本地运行也可以挂服务器上用. 在线Demo及 ...
- 炫酷实用的jQuery插件 涵盖菜单、按钮、图片
新的一周开始了,今天我们要为大家分享一些全新的jQuery插件和HTML5/CSS3应用,这些jQuery插件不仅非常炫酷,而且还挺实用,这次的分享包含jQuery菜单.CSS3按钮已经多种图片特效, ...
- iOS动画开发之五——炫酷的粒子效果
在上几篇博客中,我们对UIView层的动画以及iOS的核心动画做了介绍,基本已经可以满足iOS应用项目中所有的动画需求,如果你觉得那些都还不够炫酷,亦或是你灵光一现,想用UIKit框架写出一款炫酷的休 ...
- Android 教你打造炫酷的ViewPagerIndicator 不仅仅是高仿MIUI
1.概述 哈,今天给大家带来一个ViewPagerIndicator的制作,相信大家在做tabIndicator的时候,大多数人都用过 TabPageIndicator,并且很多知名APP都使用过这个 ...
- 视频编辑SDK---我们只提供API,任你自由设计炫酷的功能
面对相对复杂的视频编辑处理技术,你是否束手无策? 在短视频应用中,有一定技术难度的视频编辑技术中,我们提出了一种全新的解决方法:画板和画笔.短视频处理,用画板和画笔,就够了! 我们设计了极其简单易懂的 ...
- 炫酷:一句代码实现标题栏、导航栏滑动隐藏。ByeBurger库的使用和实现
本文已授权微信公众号:鸿洋(hongyangAndroid)原创首发. 其实上周五的时候已经发过一篇文章.基本实现了底部导航栏隐藏的效果.但是使用起来可能不是很实用.因为之前我实现的方式是继承了系统的 ...
随机推荐
- HTML5-CSS(一)
一.创建 CSS 样式表有三种方式 1. 元素内嵌样式<p style="color:red;font-size:50px;">这是一段文本</p>解释:即 ...
- 在deeping上安装mariadb
1,安装的官网参考:有安装的命令和指导https://downloads.mariadb.org/mariadb/repositories/#distro=Debian&distro_rele ...
- Linux中tomcat随服务器自启动的设置方法
1. cd到rc.local文件所在目录,一般在 /etc/rc.d/目录. 2. 将rc.local下载到本地windows系统中. 3. 编辑rc.local,将要启动的tomcat /bin/ ...
- 如何反编译Python写的exe到py
参考链接: https://blog.csdn.net/qq_44198436/article/details/97314626?depth_1-utm_source=distribute.pc_re ...
- MP4命令行处理
MP4Box可用于生成符合MPEG-DASH规范的内容,也就是ISO / IEC 23009-1在ISO公共可用标准中可用的内容. dash切片命令: mp4box -dash 5000 -frag ...
- 大数据学习(21)—— ZooKeeper原理
这一篇我们对zookeeper的主要原理做一个简单介绍.zookeeper的核心原理是zookeeper atomic broadcast(ZAB协议),它来源于paxos协议.这里用通俗易懂的话,介 ...
- WordPress如何配置邮件发送?
WordPress配置了邮件发送最直接的用处就是可以通过邮件找回密码,当然还有其他的用处,比如Wordpress有新用户注册,订单状态.评论等发生变化时给管理员发送邮件提醒等. 经过大量用户实践反馈, ...
- ubuntu安装qemu
ubuntu安装qemu ubtuntu编译安装qemu 5.2.0,apt-get安装的版本过于老旧. 环境:ubuntu 18.04. wget https://download.qemu.org ...
- Java Fork/Join
Fork/Join框架 Fork/Join 以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果. 这个过程其实就是分治算法的并行版本,图解如下: 如何使用 我们要使 ...
- 【Android面试揭秘】面试官说“回去等通知”,我到底会不会等来通知?
前言 大部分情况下,面试结束后,面试官都会跟你说:我们会在1-2个工作日内通知你面试结果. 许多人认为:所谓「等通知」其实是面试官委婉地给你「发拒信」.但是,这不是「等通知」的全部真相. 这篇文章,我 ...