结合k8s和pipeline的流水线,并通过k8s接口完成镜像升级
现在这家单位的CICD比较的混乱,然后突发奇想,想改造下,于是就用pipeline做了一个简单的流水线,下面是关于它的一些介绍
写一个简单的流水线

大概就是这么个流程简单来说就是:拉代码---》编译---》打镜像---》推镜像---》部署到k8s中,下面的pipeline就是在这条主线上进行,根据情况进行增加
pipeline {
agent { label 'pdc&&jdk8' }
environment {
git_addr = "代码仓库地址"
git_auth = "拉代码时的认证ID"
pom_dir = "pom文件的目录位置(相对路径)"
server_name = "服务名"
namespace_name = "服务所在的命名空间"
img_domain = "镜像地址"
img_addr = "${img_domain}/cloudt-safe/${server_name}"
// cluster_name = "集群名"
}
stages {
stage('Clear dir') {
steps {
deleteDir()
}
}
stage('Pull server code and ops code') {
parallel {
stage('Pull server code') {
steps {
script {
checkout(
[
$class: 'GitSCM',
branches: [[name: '${Branch}']],
userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_addr}"]]
]
)
}
}
}
stage('Pull ops code') {
steps {
script {
checkout(
[
$class: 'GitSCM',
branches: [[name: 'pipeline-0.0.1']], //拉取的构建脚本的分支
doGenerateSubmoduleConfigurations: false,
extensions: [[$class: 'RelativeTargetDirectory', relativeTargetDir: 'DEPLOYJAVA']], //DEPLOYJAVA: 把代码存放到此目录中
userRemoteConfigs: [[credentialsId: 'chenf-o', url: '构建脚本的仓库地址']]
]
)
}
}
}
}
}
stage('Set Env') {
steps {
script {
date_time = sh(script: "date +%Y%m%d%H%M", returnStdout: true).trim()
git_cm_id = sh(script: "git rev-parse --short HEAD", returnStdout: true).trim()
whole_img_addr = "${img_addr}:${date_time}_${git_cm_id}"
}
}
}
stage('Complie Code') {
steps {
script {
withMaven(maven: 'maven_latest_linux') {
sh "mvn -U package -am -amd -P${env_name} -pl ${pom_dir}"
}
}
}
}
stage('Build image') {
steps {
script {
dir("${env.WORKSPACE}/${pom_dir}") {
sh """
echo 'FROM 基础镜像地址' > Dockerfile //由于我这里进行了镜像的优化,只指定一个基础镜像地址即可,后面会详细的说明
"""
withCredentials([usernamePassword(credentialsId: 'faabc5e8-9587-4679-8c7e-54713ab5cd51', passwordVariable: 'img_pwd', usernameVariable: 'img_user')]) {
sh """
docker login -u ${img_user} -p ${img_pwd} ${img_domain}
docker build -t ${img_addr}:${date_time}_${git_cm_id} .
docker push ${whole_img_addr}
"""
}
}
}
}
}
stage('Deploy img to K8S') {
steps {
script {
dir('DEPLOYJAVA/deploy') {
//执行构建脚本
sh """
/usr/local/python3/bin/python3 deploy.py -n ${server_name} -s ${namespace_name} -i ${whole_img_addr} -c ${cluster_name}
"""
}
}
}
// 做了下判断如果上面脚本执行失败,会把上面阶段打的镜像删除掉
post {
failure {
sh "docker rmi -f ${whole_img_addr}"
}
}
}
stage('Clear somethings') {
steps {
script {
// 删除打的镜像
sh "docker rmi -f ${whole_img_addr}"
}
}
post {
success {
// 如果上面阶段执行成功,将把当前目录删掉
deleteDir()
}
}
}
}
}
优化构建镜像
上面的pipeline中有一条命令是生成Dockerfile的,在这里做了很多优化,虽然我的Dockerfile就写了一个FROM,但是在这之后又会执行一系列的操作,下面我们对比下没有做优化的Dockerfile
未优化
FROM 基础镜像地址
RUN mkdir xxxxx
COPY *.jar /usr/app/app.jar
ENTRYPOINT java -jar app.jar
优化后的
FROM 基础镜像地址
优化后的Dockerfile就这一行就完了。。。。。 下面简单介绍下这个ONBUILD
ONBUILD可以这样理解,就比如我们这里使用的镜像,是基于java语言做的一个镜像,这个镜像有两部分,一个是包含JDK的基础镜像A,另一个是包含jar包的镜像B,关系是先有A再有B,也就是说B依赖于A。
假设一个完整的基于Java的CICD场景,我们需要拉代码,编译,打镜像,推镜像,更新pod这一系列的步骤,而在打镜像这个过程中,我们需要把编译后的产物jar包COPY到基础镜像中,这就造成了,我们还得写一个Dockerfile,用来COPY jar包,就像下面这个样子:
FROM jdk基础镜像
COPY xxx.jar /usr/bin/app.jar
ENTRYPOINT java -jar app.jar
这样看起来也还好,基本上三行就解决了,但是能用一行就解决为什么要用三行呢?
FROM jdk基础镜像
ONBUILD COPY target/*.jar /usr/bin/app.jar
CMD ["/start.sh"]
打成一个镜像,比如镜像名是:java-service:jdk1.8,在打镜像的时候,ONBUILD后面的在本地打镜像的过程中不会执行,而是在下次引用时执行的
FROM java-service:jdk1.8
只需要这一行就可以了,并且这样看起来更加简洁,pipeline看起来也很规范,这样的话,我们每一个java的服务都可以使用这一行Dockerfile了。
使用凭据
有时候使用docker进行push镜像时需要进行认证,如果我们直接在pipeline里写的话不太安全,所以得进行脱敏,这样的话我们就需要用到凭据了,添加凭据也是非常简单,由于我们只是保存我们的用户名和密码,所以用Username with password类型的凭据就可以了,如下所示
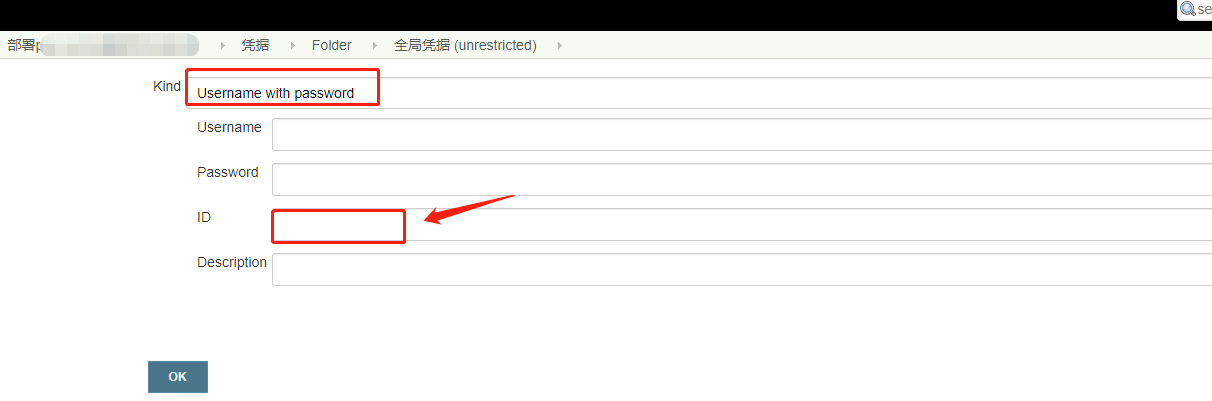
比如说:拉取git仓库的代码需要用到,然后这里就添加一个凭据,对应与pipeline里的下面这段内容:
stage('Pull server code') {
steps {
script {
checkout(
[
$class: 'GitSCM',
branches: [[name: '${Branch}']],
userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_addr}"]]
]
)
}
}
}
这里的变量${git_auth}就是添加凭据时设置的ID,如果不设置ID会随机生成一个ID
然后docker push时会需要进行认证,也需要添加凭据,添加方式和上面是一样的,不过我们可以用pipeline的语法来生成一个,方式如下:
点击Pipeline Syntax

选择withCredentials: Bind credentials to variables

然后和之前添加的凭据进行绑定,这里选择类型为:Username and password (separated)

设置用户名和密码的变量名,然后选择刚才添加好的凭据

点击生成即可,就是上面pipeline里的下面这段:
withCredentials([usernamePassword(credentialsId: 'faabc5e8-9587-4679-8c7e-54713ab5cd51', passwordVariable: 'img_pwd', usernameVariable: 'img_user')]) {
sh """
docker login -u ${img_user} -p ${img_pwd} ${img_domain}
docker build -t ${img_addr}:${date_time}_${git_cm_id} .
docker push ${whole_img_addr}
"""
}
credentialsId: 这个ID就是随机生成的ID
执行脚本进行更新镜像
这里是使用python写了一个小脚本,来调用kubernetes的接口做了一个patch的操作完成的。先来看下此脚本的目录结构

核心代码:deploy.py
核心文件:config.yaml 存放的是kubeconfig文件,用于和kubernetes的认证
下面贴一下deploy.py的脚本内容,可以参考下:
import os
import argparse
from kubernetes import client, config
class deployServer:
def __init__(self, kubeconfig):
self.kubeconfig = kubeconfig
config.kube_config.load_kube_config(config_file=self.kubeconfig)
self._AppsV1Api = client.AppsV1Api()
self._CoreV1Api = client.CoreV1Api()
self._ExtensionsV1beta1Api = client.ExtensionsV1beta1Api()
def deploy_deploy(self, deploy_namespace, deploy_name, deploy_img=None, deploy_which=1):
try:
old_deploy = self._AppsV1Api.read_namespaced_deployment(
name=deploy_name,
namespace=deploy_namespace,
)
old_deploy_container = old_deploy.spec.template.spec.containers
pod_num = len(old_deploy_container)
if deploy_which == 1:
pod_name = old_deploy_container[0].name
old_img = old_deploy_container[0].image
print("获取上一个版本的信息\n")
print("当前Deployment有 {} 个pod, 为: {}\n".format(pod_num, pod_name))
print("上一个版本的镜像地址为: {}\n".format(old_img))
print("此次构建的镜像地址为: {}\n".format(deploy_img))
print("正在替换当前服务的镜像地址....\n")
old_deploy_container[deploy_which - 1].image = deploy_img
else:
print("只支持替换一个镜像地址")
exit(-1)
new_deploy = self._AppsV1Api.patch_namespaced_deployment(
name=deploy_name,
namespace=deploy_namespace,
body=old_deploy
)
print("镜像地址已经替换完成\n")
return new_deploy
except Exception as e:
print(e)
def run():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--name', help="构建的服务名")
parser.add_argument('-s', '--namespace', help="要构建的服务所处在的命名空间")
parser.add_argument('-i', '--img', help="此次构建的镜像地址")
parser.add_argument('-c', '--cluster',
help="rancher中当前服务所处的集群名称")
args = parser.parse_args()
if not os.path.exists('../config/' + args.cluster):
print("当前集群名未设置或名称不正确: {}".format(args.cluster), 'red')
exit(-1)
else:
kubeconfig_file = '../config/' + args.cluster + '/' + 'config.yaml'
if os.path.exists(kubeconfig_file):
cli = deployServer(kubeconfig_file)
cli.deploy_deploy(
deploy_namespace=args.namespace,
deploy_name=args.name,
deploy_img=args.img
)
else:
print("当前集群的kubeconfig不存在,请进行配置,位置为{}下的config.yaml.(注意: config.yaml名称写死,不需要改到)".format(args.cluster),
'red')
exit(-1)
if __name__ == '__main__':
run()
写的比较简单,没有难懂的地方,关键的地方是:
new_deploy = self._AppsV1Api.patch_namespaced_deployment(
name=deploy_name,
namespace=deploy_namespace,
body=old_deploy
)
这一句是执行的patch操作,把替换好新的镜像地址的内容进行patch。
然后就是执行就可以了。
其他
这里有一个需要注意的地方是pipeline里加了一个异常捕获,如下所示:
post {
success {
// 如果上面阶段执行成功,将把当前目录删掉
deleteDir()
}
}
生命式的pipeline和脚本式的pipeline的异常捕获的写法是有区别的,声明式写法是用的post来进行判断,比较简单,可以参考下官方文档
另外还有一个地方使用了并行执行,同时拉了服务的代码,和构建脚本的代码,这样可以提高执行整个流水线的速度,如下所示:
parallel {
stage('Pull server code') {
steps {
script {
checkout(
[
$class: 'GitSCM',
branches: [[name: '${Branch}']],
userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_addr}"]]
]
)
}
}
}
stage('Pull ops code') {
steps {
script {
checkout(
[
$class: 'GitSCM',
branches: [[name: 'pipeline-0.0.1']], //拉取的构建脚本的分支
doGenerateSubmoduleConfigurations: false,
extensions: [[$class: 'RelativeTargetDirectory', relativeTargetDir: 'DEPLOYJAVA']], //DEPLOYJAVA: 把代码存放到此目录中
userRemoteConfigs: [[credentialsId: 'chenf-o', url: '构建脚本的仓库地址']]
]
)
}
}
}
}
嗯,情况就是这么个情况,一个简简单单的流水线就完成了,如果想快速使用流水线完成CICD,可以参考下这篇文章。
欢迎各位朋友关注我的公众号,来一起学习进步哦

结合k8s和pipeline的流水线,并通过k8s接口完成镜像升级的更多相关文章
- Jenkins + Pipeline 构建流水线发布
Jenkins + Pipeline 构建流水线发布 利用Jenkins的Pipeline配置发布流水线 参考: https://jenkins.io/doc/pipeline/tour/depl ...
- Beam概念学习系列之Pipeline 数据处理流水线
不多说,直接上干货! Pipeline 数据处理流水线 Pipeline将Source PCollection ParDo.Sink组织在一起形成了一个完整的数据处理的过程. Beam概念学习系列之P ...
- 【K8S学习笔记】Part2:获取K8S集群中运行的所有容器镜像
本文将介绍如何使用kubectl列举K8S集群中运行的Pod内的容器镜像. 注意:本文针对K8S的版本号为v1.9,其他版本可能会有少许不同. 0x00 准备工作 需要有一个K8S集群,并且配置好了k ...
- 【K8S】基于单Master节点安装K8S集群
写在前面 最近在研究K8S,今天就输出部分研究成果吧,后续也会持续更新. 集群规划 IP 主机名 节点 操作系统版本 192.168.175.101 binghe101 Master CentOS 8 ...
- Blazor+Dapr+K8s微服务之基于WSL安装K8s集群并部署微服务
前面文章已经演示过,将我们的示例微服务程序DaprTest1部署到k8s上并运行.当时用的k8s是Docker for desktop 自带的k8s,只要在Docker for deskto ...
- K8S 使用Kubeadm搭建高可用Kubernetes(K8S)集群 - 证书有效期100年
1.概述 Kubenetes集群的控制平面节点(即Master节点)由数据库服务(Etcd)+其他组件服务(Apiserver.Controller-manager.Scheduler...)组成. ...
- jenkins的Pipeline代码流水线管理
1.新建一个pipline任务 2.自写一个简单的pipline脚本 a.Pipeline的脚本语法在Pipeline Syntax中,片段生成器,示例步骤中选择builf:Build a job b ...
- jenkisn Pipeline的流水线发布,自动化部署
创建一个流水线job,这只是个简单的流水线发布教程,写的不好~
- [k8s]kubeadm k8s免费实验平台labs.play-with-k8s.com,k8s在线测试
k8s实验 labs.play-with-k8s.com特色 这玩意允许你用github或dockerhub去登录 这玩意登录后倒计时,给你4h实践 这玩意用kubeadm来部署(让你用weave网络 ...
随机推荐
- Word带数学公式发布博客
Word公式编辑器无法直接上传博客,一个一个的转换LaTeX还要加$,十分麻烦. 下面是我昨天摸索出来的办法.作为博客新人,这个问题困扰我一晚上,能解决我也是非常高兴的. 如果各位前辈有好方法的话,请 ...
- DHCP (Dynamic Host Configuration Protocol )协议的探讨与分析
DHCP (Dynamic Host Configuration Protocol )协议的探讨与分析 问题背景 最近在工作中遇到了连接外网的交换机在IPv6地址条件下从运营商自动获取的DNS地址与本 ...
- SpringBoot 整合 hibernate 连接 Mysql 数据库
前一篇搭建了一个简易的 SpringBoot Web 项目,最重要的一步连接数据库执行增删改查命令! 经过了一天的摸爬滚打,终于成功返回数据! 因为原来项目使用的 SpringMVC + Hibern ...
- Traefik-v2.x快速入门
一.概述 traefik 与 nginx 一样,是一款优秀的反向代理工具,或者叫 Edge Router.至于使用它的原因则基于以下几点 无须重启即可更新配置 自动的服务发现与负载均衡 与 docke ...
- 翻译:《实用的Python编程》03_02_More_functions
目录 | 上一节 (3.1 脚本) | 下一节 (3.3 错误检查) 3.2 深入函数 尽管函数在早先时候介绍了,但有关函数在更深层次上是如何工作的细节却很少提供.本节旨在填补这些空白,并讨论函数调用 ...
- C# 应用 - 使用 HttpListener 接受 Http 请求
1. 库类: \Reference Assemblies\Microsoft\Framework\.NETFramework\v4.6\System.dll System.Net.HttpListen ...
- WPF 实战 - 翻页控件
1. 先上效果 <StackPanel Orientation="Horizontal" HorizontalAlignment="Center"> ...
- Everything about WSL 1 you want to know
关于 WSL 1 入门,你应该知道这些 如有错误,欢迎指出 参考: WSL 文档 VMware Workstation Pro 文档 概述 通过 WSL 2 来认识 WSL 1 什么是 WSL 2? ...
- IntelliJ IDEA热部署配置总结
Intellij IDEA 4种配置热部署的方法: 热部署可以使的修改代码后,无须重启服务器,就可以加载更改的代码. 第1种:修改服务器配置,使得IDEA窗口失去焦点时,更新类和资源 菜单Run -& ...
- 正则表达式-Python实现
1.概述: Regular Expression.缩写regex,regexp,R等: 正则表达式是文本处理极为重要的工具.用它可以对字符串按照某种规则进行检索,替换. Shell编程和高级编程语言中 ...