论文翻译:2020_Generative Adversarial Network based Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-5.pdf
基于GAN的回声消除
摘要
生成对抗网络(GANs)已成为语音增强(如噪声抑制)中的热门研究主题。通过在对抗性场景中训练噪声抑制算法,基于GAN的解决方案通常会产生良好的性能。在本文中,提出了卷积循环GAN架构(CRGAN-EC),以解决线性和非线性回声情况。所提出的体系结构在频域中进行了训练,并预测了目标语音的时频(TF)掩码。部署了几种度量损失函数,并研究了它们对回声消除性能的影响。实验结果表明,所提出的方法在回声回声损耗增强(ERLE)和语音质量感知评估(PESQ)方面优于看不见的说话者。此外,多个度量损失函数提供了实现特定目标的更大自由度,例如,更多的回声抑制或更少的失真。
关键字:非线性回声消除,深度学习,生成对抗网络,卷积循环网络
1 引言
声音回声产生于本地音频回路,当(近端)麦克风从扬声器接收音频信号,并将其发送回(远端)参与者时发生。回声会极大地干扰谈话,让通话变得非常不愉快和分散注意力。回声消除(AEC)或回声抑制(AES)的目的是抑制麦克风信号的回声,同时使近端通话者的语音失真最小。传统的回声消除算法在假设远端信号与回声呈线性关系的情况下,利用自适应滤波器[1]来估计回声路径。在实践中,这种线性假设并不总是成立的,因此经常使用[2][3]后置滤波器来抑制残差回声。然而,当引入非线性时,这种AEC算法的性能会显著下降。虽然提出了一些非线性自适应滤波器,如Volterra滤波器[4],但它们太昂贵而难以实现。
随着深度学习技术的发展,利用深度神经网络完成了语音识别[5]、噪声抑制[6][7]、语音分离[8][9]等语音处理任务。提出了几种消除回声的方法。Lee等人[10]使用三层受限玻尔兹曼机(RBM)深度神经网络来预测残差回声抑制的增益。Muller等人[11]建议在双讲过程中使用近端非活跃频率来适应声传递函数,使用两个全连接层网络来检测近端信号的活动。Zhang和Wang[12]提出了一种双向长短时记忆(BLSTM)算法,该算法从麦克风信号中预测出理想的比例掩码,然后利用该掩码重新合成近端语音。这种解决方案不需要双讲检测而传统方法做。Carbajal等[13]构建了两层网络来预测残差回声抑制的相敏滤波器。Zhang等人[14]利用卷积循环网络和长短期记忆将近端语音从麦克风录音中分离出来。Fazel等人[15]提出了带多任务学习的深度递推神经网络来学习估计回声的辅助任务,以改进估计近端语音的主要任务。
近年来,生成对抗网络在语音增强中的应用得到了研究。许多基于GAN的语音增强算法已经被提出。一些是端到端解决方案,直接映射噪音语音到增强信号[16][17]。其他GANs在T-F域[18][19]工作,预测掩码,然后在时域重新合成目标语音。
在本文中,我们提出了一种基于GAN的回声消除算法,适用于线性和非线性回声场景。在发生器网络中,将传声器信号和参考信号的对数幅值谱作为输入,预测谱的T-F掩模作为输出。编码器由卷积层组成,解码器相应由反卷积层组成。它们之间是一个两层的BLSTM。利用卷积层提取麦克风信号和参考信号之间的局部相关性,以及它们之间的映射关系。BLSTM层位于G网络的中心,可以捕获长期的时间信息。鉴别器D网络有卷积层和全连接层。鉴别器的输入为一对ground-truth 信号和增强信号,输出为[0,1]缩放分数,而不是真/假。
本文的其余部分组织如下。第2节介绍背景知识。在第3节中,我们介绍了基于GAN的算法,然后在第4节给出了实验设置和结果。最后的结论在第五部分给出。
2 背景知识
2.1 回声消除
声波回声是由麦克风和扬声器耦合而产生的,如图1所示。远端信号(或参考信号)\(x(t)\)从扬声器通过各种反射路径\(h(t)\)传播,与近端信号\(s(t)\)在麦克风\(d(t)\)混合。声学回声是\(x(t)\)的修改版本,包括回声路径\(h(t)\)和扬声器失真。
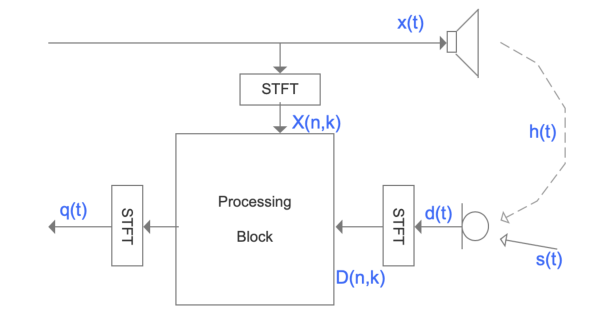
图1 回声生成和声学回声消除的示例
传统的AEC算法利用自适应滤波器估计回声路径\(h(t)\),并从麦克风信号\(d(t)\)中减去估计回声\(y(t)=\hat{h}(t) * x(t)\)。在双讲期间需要一个单独的双讲检测来冻结滤波器自适应。该线性回声消除器是在参考信号与声波回声呈线性关系的假设下实现的。然而,由于扬声器等硬件限制,通常会引入非线性。因此,需要一个后置滤波器来进一步抑制残留回声。传统AEC算法框图如图2中上图所示。
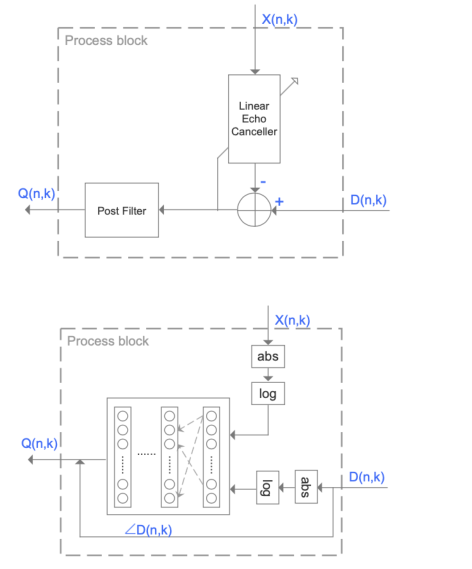
图2 传统AEC的示例(顶部)和基于神经网络的AEC(底部)
近年来,基于深度学习的AEC算法显示出了巨大的潜力。在有足够的训练数据的情况下,无论是在匹配的还是不匹配的测试用例中,基于神经网络的解决方案都比传统的解决方案具有更好的性能。图2底部是基于DNN算法的一个例子。模型输入由参考信号和传声器信号的对数幅度谱组成。该模型旨在估计增强的幅度谱(类似于LEC和后置滤波器组合)。最后,麦克风信号相位用于在时域中重新合成增强信号。
评价AEC性能的一般指标包括ERLE和PESQ,这两个指标也被用于本实验。
ERLE常用于测量系统在近端通话不活跃的情况下实现的回声减少。ERLE的定义是
\]
其中,E{}表示统计期望。
PESQ评估双讲期间增强的近端语音的感知质量。PESQ评分通过对比增强信号与ground-truth信号计算,评分范围为(-0.5,4.5),评分越高质量越好。
2.2 生成对抗网络
GAN由两个网络组成:一个生成网络G和一个辨别器网络D。这形成了一个极大极小博弈方案(minimax game scenario),G试图生成假数据来愚弄D,而D正在学习辨别真数据和假数据,重要的是,G并不记忆输入输出对,而是学习将数据分布特征映射到先验Z中定义的流形。D通常是一个二元分类器,其输入要么是来自G模仿数据集的真实样本,要么是由G组成的假样本。如[20]所述,传统GAN中D和G的损失函数可以表述为
\min _{G} \max _{D} V(D, G)=& \mathbb{E}_{y \sim}[\log D(y)] \\
&+\mathbb{E}_{z \sim z}[\log (1-D(G(z)))]
\end{aligned} (2)
\]
式中,\(\mathbb{E}_{y \sim Y}\)表示Y来自分布T的期望。
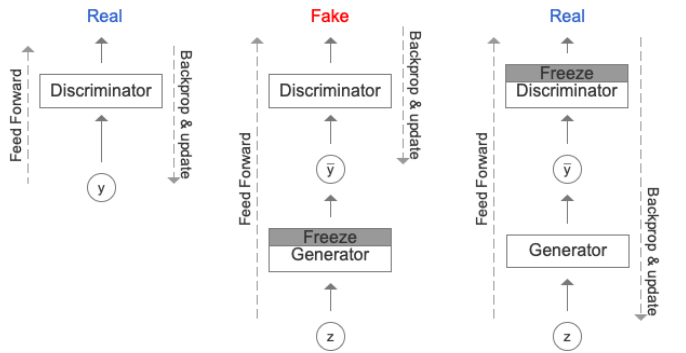
图3 GAN训练过程
图3显示了GAN训练过程。G调整它的参数,使D将G的输出分类为实数。在反向传播过程中,D在输入中输入真实特征方面得到改进,反过来,G纠正其参数向前移动。
3 提出方法
定义回声消除问题是为了让我们有一个输入回声已损坏的信号\(d(t)\),并想要清除它以获得增强信号\(q(t)\)。我们建议用GAN模型来完成这项工作。在该方法中,G网络进行增强。它的输入分别是麦克风信号\(d(t)\)和参考信号\(x(t)\)的对数幅度谱\(D(n,k)\)和\(X(n,k)\)以及潜在表示z,它的输出是用于重新合成增强版本\(Q(n,k)=M(n,k)*D(n,k)\)的T-F掩模\(Mask(n,k)=G\{D(n, k), X(n, k)\}\)。G网络具有类似于自动编码器的形状,如图4所示。在编码阶段,有三个二维卷积层,然后是一个reshape layer。卷积使网络专注于输入信号中的时间密切相关性,并且显示出在GAN训练[21]时更加稳定。相应的,解码阶段是编码的相反版本,它由三个反卷积层组成。编码器和解码器之间有两个双向LSTM层来捕获额外的时间信息。批处理归一化(BN)[22]应用于除输出层外的每个卷积层之后。除输出层使用sigmoid激活函数预测T-F掩模外,其他层均使用指数线性单元(ELU)[23]作为激活函数。
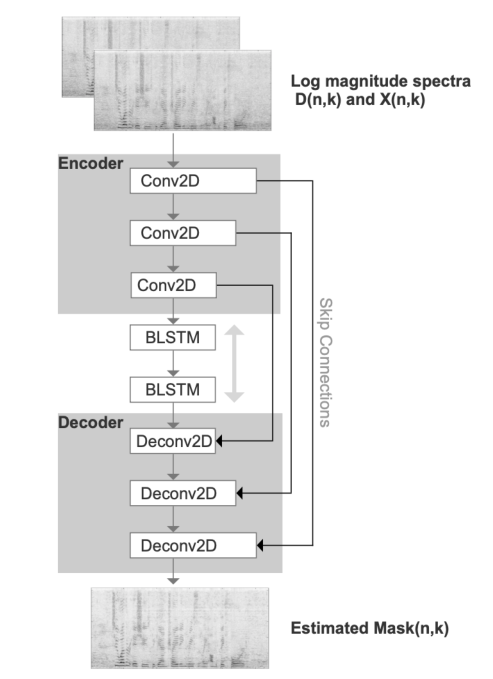
图4 G网络的编解码器架构
G网络还具有跳跃连接的特点,将每个编码层连接到其对应的解码层,并将输入谱的细粒度信息传递给解码器。此外,它们提供了更好的训练行为,因为梯度可以在整个[24]结构中流动得更深。
另一方面,D负责向G传递真实和虚假的信息,G可以根据真实的分布对输出进行轻微的修正,去掉被认为是假的回声分量。D可以表示为学习某种损失,使G的输出看起来真实。D的结构与G中的编码器相似,有三个卷积层,一个平坦层,然后是三个完全连接的层。
向更高的客观度量分数更新权重已经被证明是有效的[19]
\min _{D} V(D) &=\mathbb{E}_{(z, y) \sim(z, \Upsilon)}\left[(D(y, y)-Q(y, y))^{2}\right] \\
&+\mathbb{E}_{(z, y) \sim(z, \Upsilon)}\left[(D(G(z), y)-Q(G(z), y))^{2}\right] \\
\min _{G} V(G) &=\mathbb{E}_{z, y \sim(z, Y)}\left[(D(G(z), y)-1)^{2}\right] (3)
\end{aligned}
\]
其中Q表示标准化的评估指标,其输出范围为0,1,因此Q(y,y)=1。此外,我们发现通过在V(G)中添加L2范数可以得到更好的结果:
\min _{G} V(G) &=\mathbb{E}_{z, y \sim(z, \Upsilon)}\left[(D(G(z), y)-1)^{2}\right] \\
&+\lambda\|G(z)-Y\|^{2} (4)
\end{aligned}
\]
该算法采用对数幅度谱作为输入特征。我们应用的FFT大小为512,窗口长度为25毫秒,步长为10毫秒。较高的客观指标为PESQ和ERLE, \(\lambda=10\)。
在G的编码器中,卷积层的特征映射数量被设置为:16,32和64。第一层的内核大小为(1,3),其余层为(2,3),步长设置为(1,2)。BLSTM层共包含256个神经元,每个方向128个,时间步长为100。G的解码器部分遵循与编码器相反的参数设置。
在D中设置卷积层的特征映射个数为:10,20,20,完全连接层的神经元个数为:30,10,1。所有模型都使用Adam优化器[25]进行60个epoch的训练,学习率为0.002,批处理规模为1。时间步长随每句话的帧数而变化。D的输入是一对ground-truth信号和增强信号,输出是[0,1]的缩放分数,而不是真/假。对于PESQ 损失函数, ground-truth信号是干净的近端语音,对于ERLE损失函数, ground-truth信号是噪声信号(或麦克风信号)。PESQ和ERLE的度量损失都是基于话语水平的(utterance level)。
4 实验评价
4.1 实验设置
TIMIT数据集[26]用于评估回声消除性能。我们建立了类似于[14] [15]中报告的数据集:从TIMIT的630位说话人中,我们随机选择100对说话人(40位男女,30位男女,30位女性-女性)作为远端说话人。末端和近端扬声器。随机选择同一远端扬声器的三种发音,并将其串联起来以生成远端信号。然后,通过后端的零填充将近端扬声器的每个发声扩展到与远端信号相同的大小。近端扬声器的七种发音用于生成3500种训练混合信号,其中每个近端信号都与五个不同的远端信号混合。从剩余的430个扬声器中,随机选择另外100对扬声器作为远端和近端扬声器。我们按照与上述相同的步骤进行操作,但是这次仅使用了三种话音的近端扬声器来生成300种测试混合音,其中每个近端信号都与一个远端信号进行了混合。因此,测试混合物来自未经训练的说话人。
对远端信号采用以下过程来模拟[27]中的非线性声路径。对于声路径的非线性模型,我们首先使用硬裁剪来模拟扬声器饱和度(Thr =输入信号最大音量的80%):
\]
然后,我们应用下面的sigmoid函数来模拟扬声器失真:
\]
其中\(b(t)=1.5 x_{\text {clip }}(t)-0.3 x_{\text {clip }}(t)^{2}\), 且若 \(b(t)>0\),则\(a=4\),否则\(a=4\)。最后,将sigmoid函数的输出与随机选择的房间脉冲响应(RIR)进行卷积,得到麦克风采集到的声回声。
使用图像方法[28]生成RIRs进行训练。RIRs的长度设置为512,模拟室大小为\(4 m \times 5 m \times 3 m\),麦克风放置在[2,2,1.5]m处。扬声器随机放置在五个距离麦克风1.5米的位置。混响时间(\(RT_{60}\))在0.2 到0.5秒之间。
测试中使用RWCP数据库[29]中的5个真实环境记录的RIRs生成声回声。表1显示了五种RIRs的信息。
表1 来自RWCP数据库的RIR

本次测试同时考虑了线性和非线性回声场景。在训练步骤中,在信号回声比(SER) {- 6,- 3,0,3,6} dB处随机产生麦克风信号,其中SER定义为
\]
在测试阶段,麦克风信号在SER级别{0,3.5,7}dB产生,与训练的SERs稍有不同,以评估不匹配的训练-测试用例。
4.2 实验结果
在本实验中,采用两种最先进的神经网络算法,CRNN[14]和多任务GRU[15]作为基准。研究表明,基于神经网络的方法优于[15]中传统的“AES+RES”方法,因此我们跳过这里的“AES+RES”比较。我们没有在[14]中原始实现,而是直接使用本文方法中的G作为CRNN结构,参数在第3节给出。多任务GRU是按照[15]中的指令实现的。
我们首先在线性声路径场景下评估我们提出的方法。表2显示了未处理、CRNN、多任务GRU以及本文提出的方法的平均PESQ和ERLE得分。“CRGAN-EC-P ”表示使用PESQ作为度量损耗的GAN,“RGAN-EC-E”相应表示ERLE损耗的GAN。结果表明,在所有方法中,CRGAN-EC-P的PESQ得分最高,ERLE得分与CRNN和多任务GRU相当。CRGAN-EC-P性能优越的原因如下。卷积层有助于提供麦克风信号和参考信号之间的局部关联和映射,而BLSTM层有助于捕获长期时间信息。传统的均方误差(MSE)损失函数以均匀权值度量增强信号与ground-truth信号之间的谱距离,而PESQ则是根据心理声学原理,在不同权值的子带上累积的分数。因此,最小化MSE分数的模型不能保证产生良好的PESQ分数。
表2 线性声学路径场景下的PESQ和ERLE得分
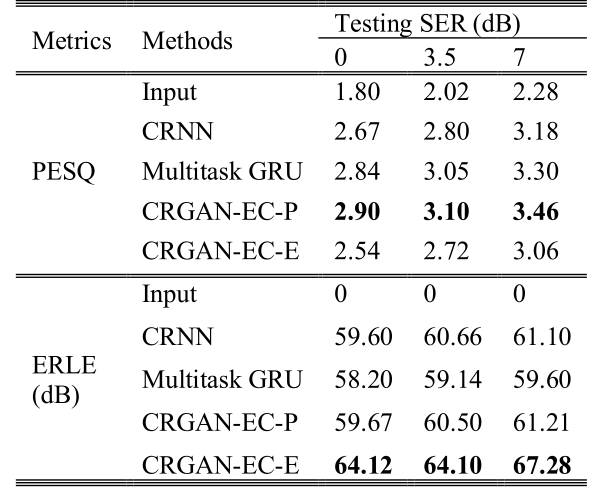
与CRNN和多任务GRU相比,CRGAN-EC-E的PESQ得分较低,但ERLE得分最高。由于本实验不考虑噪声,且SER也不低,因此高ERLE分数并没有多大意义。然而,不同的度量损失为系统实现特定目标提供了额外的自由。而结合PESQ和ERLE的度量损耗可以进一步在回声消除和目标语音失真之间实现适当的折衷。由于篇幅有限,这里只显示单独的PESQ和ERLE结果。
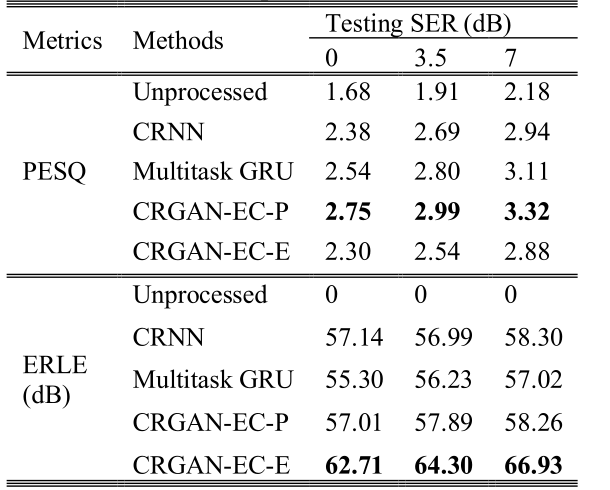
我们进一步研究了非线性声路径对我们方法的影响。在本次测试中,我们将\(x_{N L}\)与RIRs卷积产生声回声,因此既包含了功率放大器的削波,也包含了扬声器的失真。我们再次比较了我们的方法与CRNN和多任务GRU的结果。表3显示了PESQ和ERLE的平均得分。同样,本文提出的CRGAN-EC-P在所有方法中获得了最好的PESQ分数,ERLE分数也接近于最好的。提出的CRGAN-EC-E获得最好的ERLE分数。
表3 非线性声学路径场景下的PESQ和ERLE评分
5 结论
在这项研究中,我们提出了一种新的使用卷积循环GAN的声学回声消除算法,该算法在线性和非线性声路径场景下都能很好地工作。卷积层提取麦克风信号和参考信号之间的局部相关性,以及它们之间的映射关系。BLSTM层捕获长期时间信息。该体系结构在频域进行训练,预测目标语音的时频掩码。我们部署了各种度量损失函数,并证明了模型对回声抑制和目标语音失真之间的权衡的鲁棒性。在未来的工作中,我们打算在更严重的情况下,特别是无延迟的情况下,扩大对回声消除的研究。
6 参考文献
[1] E. Hansler and G. Schmidt, Acoustic Echo and Noise Control: A Practical Approach, Adaptive and learning systems for signal processing, communications, and control, Hoboken, NJ: Wiley-Interscience, 2004.
[2] S. Gustafsson, R. Martin and P. Vary, "Combined acoustic echo control and noise reudction for hands-free telephony," Signal Processing, vol. 64, no. 1, pp. 21-32, 1998.
[3] V. Turbin, A. Gilloire and P. Scalart, "Comparison of three postfiltering algorithms for residual acoustic echo reduction," in Proc. IEEE International Conf. on Acoustic, Speech, and Signal Processing, 1997.
[4] A. Stenger, L. Trautmann and R. Rabenstein, "Nonlinear acoustic echo cancellation with 2nd order adaptive Volterra filters," in Proc. IEEE International Conf. on Acoustics, Speech, and Signal Processing, 1999.
[5] G. Hinton, L. Deng, G. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath and B. Kingsbury, "Deep neural networks for acoustic modeling in speech recognition," IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82-97, 2012.
[6] X. Lu, Y. Tsao, S. Matsuda and C. Hori, "Speech enhancement based on deep denoising autoencoder," in Proc. Conf. of International Speech Communication Association, 2013.
[7] Y. Xu, J. Du, L. Dai and C. Lee, "An experimental study on speech enhancement based on deep neural networks," IEEE Signal Processing Letters, vol. 21, no. 1, pp. 65-68, 2014.
[8] Y. Wang, A. Narayanan and D. Wang, "On training targets for supervised speech separation," IEEE/ACM Trans. on Audio, Speech, and Language Processing, vol. 22, no. 12, pp. 1849-1858, 2014.
[9] F. Weninger, J. Hershey, J. Roux and B. Schuller, "Discriminatively trained recurrent neural networks for single-channel speech separation," in Global Conf. on Signal and Information Processing, 2014.
[10] C. Lee, J. Shin and N. Kim, "DNN-based residual echo suppression," in Proc. Conf. of International Speech Communication Association, 2015.
[11] M. Muller, J. Jansky, M. Bohac and Z. Koldovsky, "Linear acoustic echo cancellation using deep neural networks and convex reconstruction of incomplete transfer function," in IEEE International Workshop of Electronics, Control, Measurement, Signals and their Application to Mechatronics, 2017.
[12] H. Zhang and D. Wang, "Deep learning for acoustic echo cancellation in noisy and double-talk scenarios," in Proc. Conf. of International Speech Communication Association, 2018.
[13] G. Carbajal, R. Serizel, E. Vincent and E. Humbert, "Multiple-input neural network-based residual echo suppression," in IEEE International Conf. on Acoustic, Speech and Signal Processing, 2018.
[14] H. Zhang, K. Tan and D. Wang, "Deep learning for joint acoustic echo and noise cancellation with nonlinear distortions," in Proc. Conf. International Speech Communication Association, 2019.
[15] A. Fazel, M. El-Khamy and J. Lee, "Deep multitask acoustic echo cancellation," in Proc. Conf. International Speech Communication Association, 2019.
[16] S. Pascual, A. Bonafonte and J. Serra, "Segan: Speech enhancement generative adversarial network," in arXiv preprint, 2017.
[17] D. Baby and S. Verhulst, "Sergan: Speech enhancement using relativistic generative adversarial networks with gradient penalty," in Proc. International Conf. on Acoustic, Speech and Signal Processing, 2019.
[18] M. Soni, N. Shah and H. Patil, "Time-frequency masking-based speech enhancement using generative adversarial network," in Proc. International Conf. on Acoustic, Speech and Signal Processing, 2018.
[19] S. Fu, C. Liao, Y. Tsao and S. Lin, "Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement," in arXiv preprint, 2019.
[20] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville and Y. Bengio, "Generative adversarial nets," in Conf. on Neural Information Processing Systems, 2014.
[21] A. Radford, L. Metz and S. Chintala, "Unsupervised representation learning with depp convolutional generative adversarial networks," in arXiv preprint, 2015.
[22] S. Ioffe and C. Szegedy, "Batch normalization: Accelerating deep network training by reducing internal covariate shift," in arXiv preprint, 2015.
[23] D. Clevert, T. Unterthiner and S. Hochreiter, "Fast and accurate deep network learning by exponential linear units (elus)," in arXiv preprint, 2015.
[24] K. He, X. Zhang, S. Ren and J. Sun, "Deep residual learning for image recognition," in IEEE Conf. on Computer Vision and Pattern, 2016.
[25] D. Kingma and J. Ba, "Adam: A method for stochastic optimization," in arXiv preprint, 2014.
[26] F. Lamel, R. Kassel and S. Seneff, "Speech database development: Design and analysis of the acousticphonetic corpus," in Speech Input/Output Assessment and Speech Databases, 1989.
[27] S. Malik and G. Enzner, "State-space frequency-domain adaptive filtering for nonlinear acoustic echo cancellation," IEEE Trans. on Audio, Speech, and Language Processing, vol. 20, no. 7, pp. 2065-2079, 2012.
[28] J. Allen and D. Berkley, "Image method for efficiently simulating small-room acoustics," The Jounal of Acoustic Society of America, vol. 65, no. 4, pp. 943-950, 1979.
[29] S. Nakamura, K. Hiyane, F. Asano, T. Nishiura and T.
Yamada, "Acoustical sound database in real environments for sound scene understanding and handsfree speech recognition," in Proc. International Conf. on Language Resources and Evaluation, 2000.
论文翻译:2020_Generative Adversarial Network based Acoustic Echo Cancellation的更多相关文章
- 论文翻译:2018_Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios
论文地址:深度学习用于噪音和双语场景下的回声消除 博客地址:https://www.cnblogs.com/LXP-Never/p/14210359.html 摘要 传统的声学回声消除(AEC)通过使 ...
- 论文翻译:2020_Attention Wave-U-Net for Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-10.pdf Attention Wave-U-Net 的回声消除 摘要 提出了 ...
- 论文翻译:2021_Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation
论文地址:https://arxiv.53yu.com/abs/2104.04325 联合在线多通道声学回声消除.语音去混响和声源分离 摘要: 本文提出了一种联合声源分离算法,可同时减少声学回声.混响 ...
- 论文翻译:2021_论文翻译:2018_F-T-LSTM based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement
论文地址:https://arxiv.53yu.com/abs/2106.07577 基于 F-T-LSTM 复杂网络的联合声学回声消除和语音增强 摘要 随着对音频通信和在线会议的需求日益增加,在包括 ...
- 论文翻译:2020_A Robust and Cascaded Acoustic Echo Cancellation Based on Deep Learning
论文地址:https://indico2.conference4me.psnc.pl/event/35/contributions/3364/attachments/777/815/Thu-1-10- ...
- 论文翻译:2021_Semi-Blind Source Separation for Nonlinear Acoustic Echo Cancellation
论文地址:https://ieeexplore.ieee.org/abstract/document/9357975/ 基于半盲源分离的非线性回声消除 摘要: 当使用非线性自适应滤波器时,数值模型与实 ...
- 论文翻译:2021_ICASSP 2021 ACOUSTIC ECHO CANCELLATION CHALLENGE: INTEGRATED ADAPTIVE ECHO CANCELLATION WITH TIME ALIGNMENT AND DEEP LEARNING-BASED RESIDUAL ECHO PLUS NOISE SUPPRESSION
论文地址:https://ieeexplore.ieee.org/abstract/document/9414462 ICASSP 2021声学回声消除挑战:结合时间对准的自适应回声消除和基于深度学习 ...
- 论文翻译:2021_AEC IN A NETSHELL: ON TARGET AND TOPOLOGY CHOICES FOR FCRN ACOUSTIC ECHO CANCELLATION
论文地址:https://ieeexploreieee.53yu.com/abstract/document/9414715 Netshell 中的 AEC:关于 FCRN 声学回声消除的目标和拓扑选 ...
- BSS Audio® Introduces Full-Bandwidth Acoustic Echo Cancellation Algorithm for Soundweb London Conferencing Processors
BSS Audio® Introduces Full-Bandwidth Acoustic Echo Cancellation Algorithm for Soundweb London Confer ...
随机推荐
- 100个Shell脚本——【脚本2】截取字符串
[脚本2]截取字符串 一.脚本 现有一个字符串如下: http://www.aaa.com/root/123.htm 请根据以下要求截取出字符串中的字符: 1.取出www.aaa.com/root/1 ...
- 为什么要重写hashcode和equals方法
我在面试 Java初级开发的时候,经常会问:你有没有重写过hashcode方法?不少候选人直接说没写过.我就想,或许真的没写过,于是就再通过一个问题确认:你在用HashMap的时候,键(Key)部分, ...
- Linux基础命令---apachectl
apachectl apachectl指令是apache http服务器的前端控制程序,可以协助控制apache服务的守护进程httpd. 此命令的适用范围:RedHat.RHEL.Ubuntu.Ce ...
- AJAX - Http 中 post 和 get 的区别
HTTP: post 和 get 是 HTTP 协议中的两种方法.浏览器和服务器的交互是通过 HTTP 协议执行的,他的全称为Hyper Text Transfer Protocol(超文本传输协议) ...
- Spring Boot对静态资源的映射规则
规则一:所有 " /webjars/** " 请求都去classpath:/META-INF/resources/webjars/找资源 webjars:以jar包的方式引入静态资 ...
- 论文翻译:2021_Low-Delay Speech Enhancement Using Perceptually Motivated Target and Loss
论文地址:使用感知动机目标和损失的低延迟语音增强 引用格式:Zhang X, Ren X, Zheng X, et al. Low-Delay Speech Enhancement Using Per ...
- centos部署配置gogs代码仓库
目录 一.简介 二.部署 三.网页配置 一.简介 Gogs的目标是打造一个最简单.最快速和最轻松的方式搭建自助Git服务.使用Go语言开发使得Gogs能够通过独立的二进制分发,并且支持Go语言支持的 ...
- 预算(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 预算是件重要的事,不然银几一花没边了,那结果可是要牺牺的(以下省略具体描述9^323字) 在Project里做预算,步骤不 ...
- CF208A Dubstep 题解
Content 有一个字符串被变换了.其中在这个字符串的前面加了 \(\geqslant 0\) 个 WUB,每个单词(由空格间隔)之间加了 \(\geqslant 1\) 个 WUB,在这个字符串的 ...
- java 8 启动脚本优化 2
#!/bin/bash #链接文件 source /etc/profile #java虚拟机启动参数 #通过http://xxfox.perfma.com/jvm/check来检查参数的合理性 JAV ...