HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点)
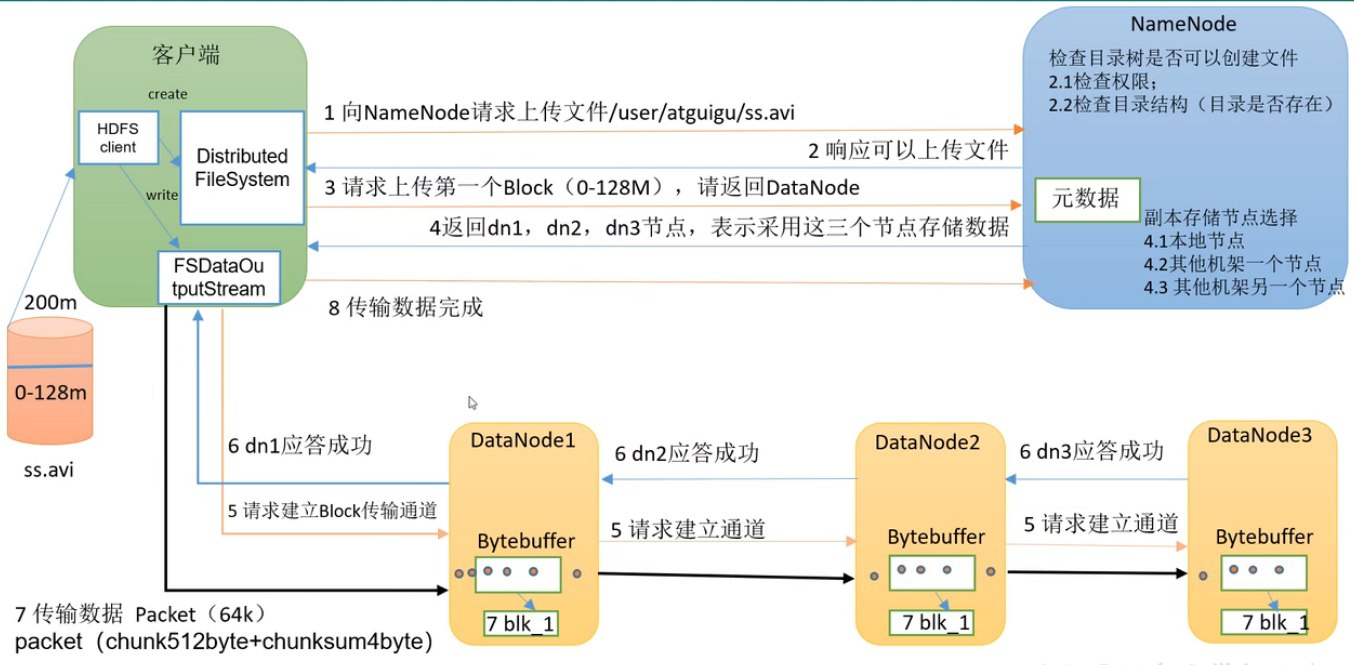
HDFS写数据流程
客服端把D://ss.avi文件传送到集群
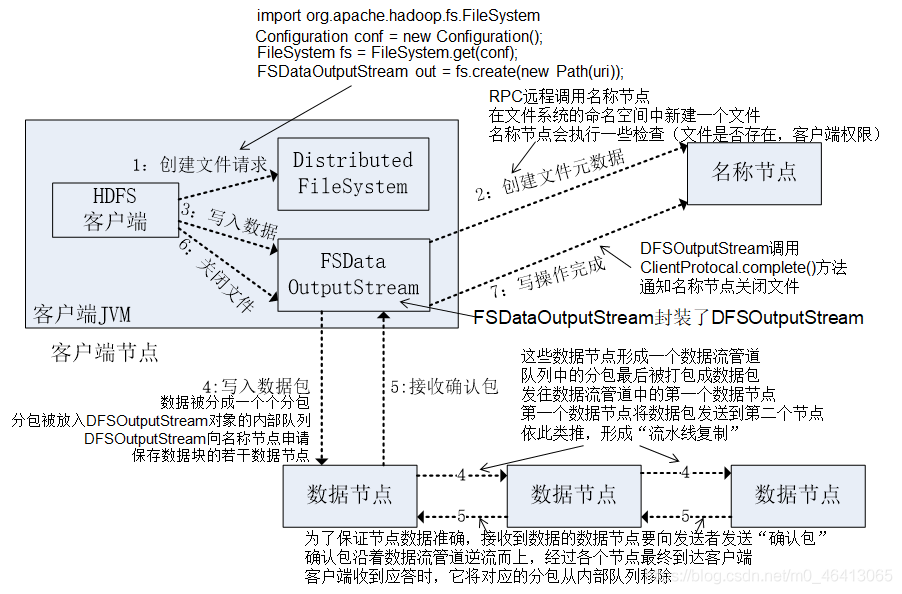
1.首先需要创建一个Distributed FileSystem(分布式文件系统)客服端。向NameNode请求上传文件。上传到/user/atguigu/ss.avi路径。
2.NameNode 检查用户是否有权限,检查目标路径/user/atguigu是否可行,检测目标文件ss.avi是否存在。检查完毕后返回结果,是否可以上传文件。
3.客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
4.NameNode根据选择策略返回 DataNode 节点。
5.客户端创建FSDataOutPutStream,请求 dn1建立Block传输通道,dn1 收到请求会继续传给dn2,然后 dn2 传给 dn3,将这个通信管道建立完成。
6.dn3、dn2、dn1应答客户端。
7.dn1在磁盘中写的过程中,同时把数据传给dn2。以Packet(64k)为单位,dn1收到一个 Packet就会传给dn2,dn2 传给 dn3。每个dn都有ACK队列,应答成功后,缓存的数据才会清空,如果失败,缓存数据用于重发。
(8)当一个 Block 传输完成之后, 客户端再次请求 NameNode 上传第二个 Block。(重复执行 3-7 步)
补充:选择策略
节点距离最近与负载均衡
4.1优先本地节点
4.2其他机架A一个节点
4.3其他机架A另一个节点
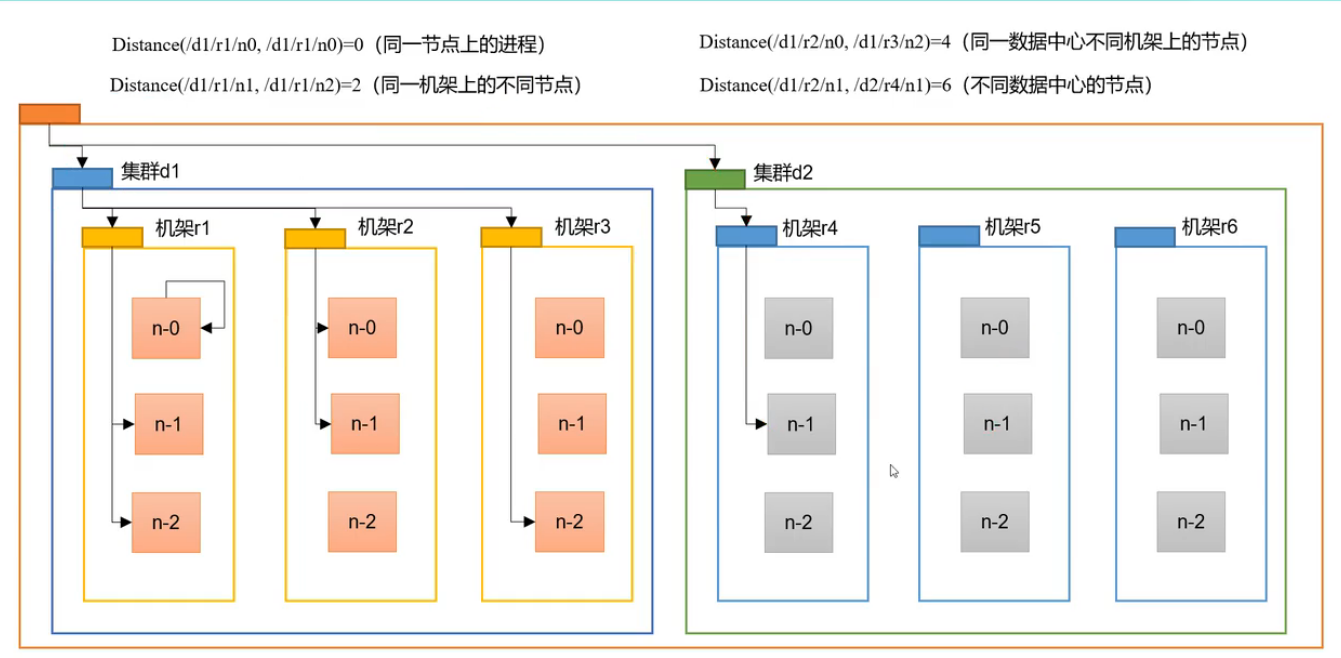
网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距 离待传上传数据最近距离 的DataNode接收。那么这个最近距离怎么计算?
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。以下给出了四种类型距离描述。
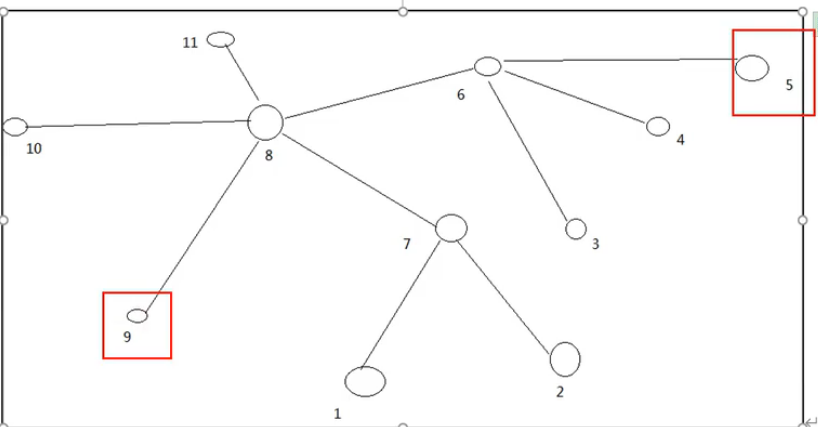
案例
计算节点5与节点9之间的节点距离是多少 -3
计算节点2与节点10之间的节点距离是多少 -3
机架感知(副本存储节点的选择)
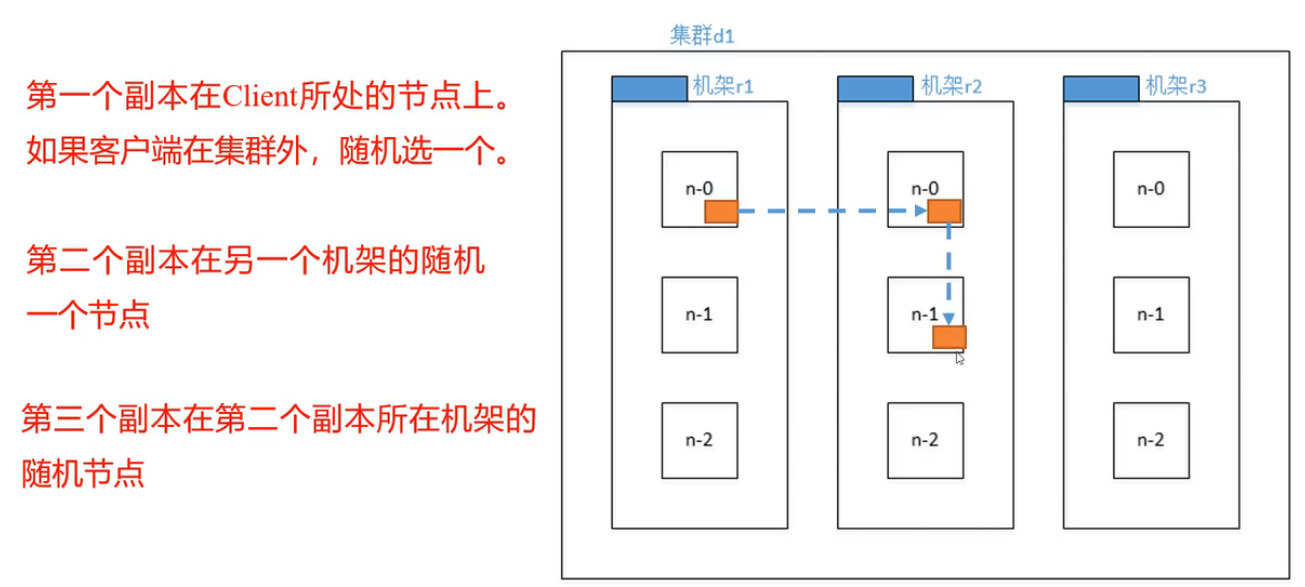
第一个副本考虑的是节点距离最近,上传速度最快。
第二个副本保证数据可靠性。
第三个副本兼顾效率与速度。
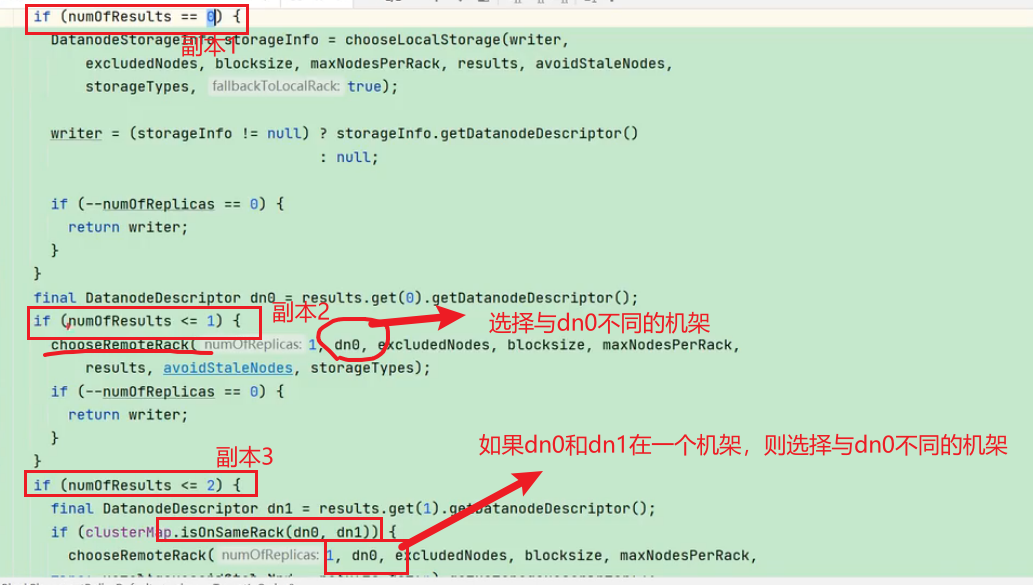
查看源码
Crtl + n 查找 BlockPlacementPolicyDefault类,在该类中查找 chooseTargetInOrder 方法。

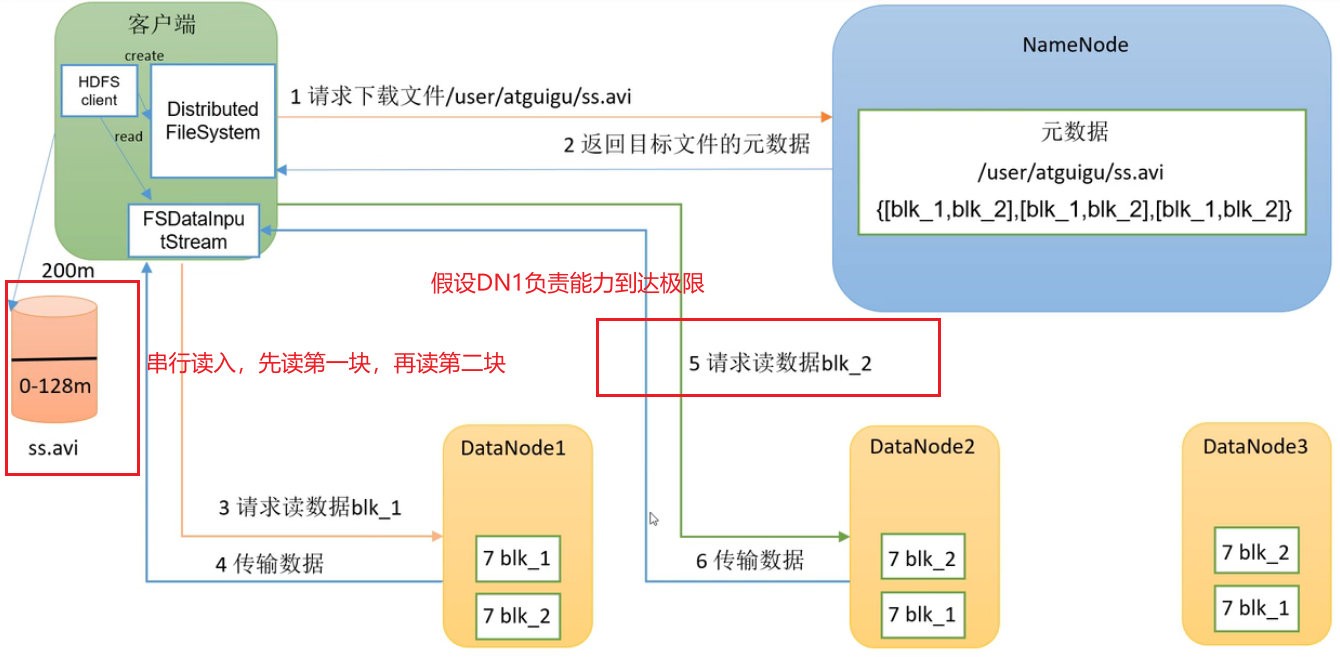
HDFS的读数据流程
把HDFS的数据读到本地
1.客户端通过 DistributedFileSystem 向 NameNode 请求下载文件。
2.NameNode先判断权限再通过查询元数据,找到文件块所在的 DataNode 地址,返回目标文件的元数据。
3.客户端创建FSDataInputStream流对象,挑选一台 DataNode服务器(就近原则与负载能力),请求读取数据。 假设DN1负载能力到了极限,串行读,先读第一块,再读第二块
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
HDFS04 HDFS的读写流程的更多相关文章
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS的读写流程
1.2. 客户端向NameNode发起创建文件的请求,在NameNode上创建一个文件名,并且返回一个输出流 3.客户端向输出流发起写入数据的请求 4.输出流向NameNode请求写数据,NameNo ...
- Hadoop---HDFS读写流程
Hadoop---HDFS HDFS 性能详解 HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案. HDFS 将将要存储的大文件进行分割,分割到既定的存储 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
随机推荐
- 身份证归属地查询免费api接口
描写叙述 :依据身份证编号 查询归属地信息. 调用地址: http://api.k780.com:88/? app=idcard.get&idcard=510103195309280011&a ...
- undefined reference to `recvIpcMsg(int, ipc_msg*)'——#ifdef __cplusplus extern "C" { #endif
最近在弄一个进程间通信,原始测试demon用c语言写的,经过测试ok,然后把接口封装起来了一个send,一个recv. 使用的时候send端是在一个c语言写的http服务端使用,编译ok没有报错,但是 ...
- linux下软链接文件的拷贝
最近在编译libnl库准备拷贝到其他机器中使用的时候出现无法拷贝问题,原因是sd卡是fat32文件系统格式,这种文件系统不支持linux下的ln软链接文件, void@void-ThinkPad-E4 ...
- cf2A Winner(implementation)
题意: N个回合. 每个回合:name score[名为name的这个人得了score分(可负可正)]. 问最后谁的累积分数是最高的.设为M.如果有好几个都得了M,找出这几个人中哪个最早回合累积分数超 ...
- hdu 1160 FatMouse's Speed(最长不下降子序列+输出路径)
题意: FatMouse believes that the fatter a mouse is, the faster it runs. To disprove this, you want to ...
- Ubuntu安装数据库
1.通过命令行安装:sudo apt-get install mysql-client mysql-server 2.安装过程中输入数据库密码("123456",root) 3.使 ...
- 盘点 GitHub 年度盛会|附视频
「Universe 2021」是 GitHub 于今年举办的开发者盛会,本次 Universe 2021 大会采用线上直播模式,为期两天已于上周落下帷幕. 这是 GitHub 举办的一年一度开发者盛会 ...
- 【编译原理】LL1文法语法分析器
上篇文章[编译原理]语法分析--自上向下分析 分析了LL1语法,文章最后说给出栗子,现在补上去. 说明: 这个语法分析器是利用LL1分析方法实现的. 预测分析表和终结符以及非终结符都是针对一个特定文法 ...
- css书写规范 & 页面布局规范 &常用案例经验总结
CSS 属性书写顺序(重点) 建议遵循以下顺序: 布局定位属性:display / position / float / clear / visibility / overflow(建议 displa ...
- storm在windows下本地调试报错java.lang.UnsatisfiedLinkError cannot find rocksdbjnixxxxxxxxxx.dll
storm启动本地集群调试时,有时会找不到rocksdbjni.dll,storm加载该库的时候会先从jkd的bin下找rocksdbjni.dll,如果找不到就从pom文件的依赖包里找,再找不到就会 ...