【论文笔记】Recommendations as Treatments: Debiasing Learning and Evaluation
Recommendations as Treatments: Debiasing Learning and Evaluation
Authors: Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, Thorsten Joachims
ICML’16 Cornell University
0. 总结
本文提出了基于IPS的评测指标和模型训练方法,并提出了两种倾向性评分的估计方法。收集并公开了Coat数据集,在半合成数据集和无偏数据集上,验证了评测指标对Propensity score估计的鲁棒性和IPS-MF的性能优越性。
1.研究目标
去除选择偏差(selection-bias)对模型性能评测(evaluation)和模型训练(training)带来的不利影响。
2.问题背景
推荐系统中的选择偏差(selection bias)可能有两个来源:首先,用户更可能跟自己感兴趣的物品发生交互,不感兴趣的物品更可能没有交互记录;第二,推荐系统在给出推荐列表时也会倾向于给用户推荐符合用户兴趣的产品。
3. IPS评价指标
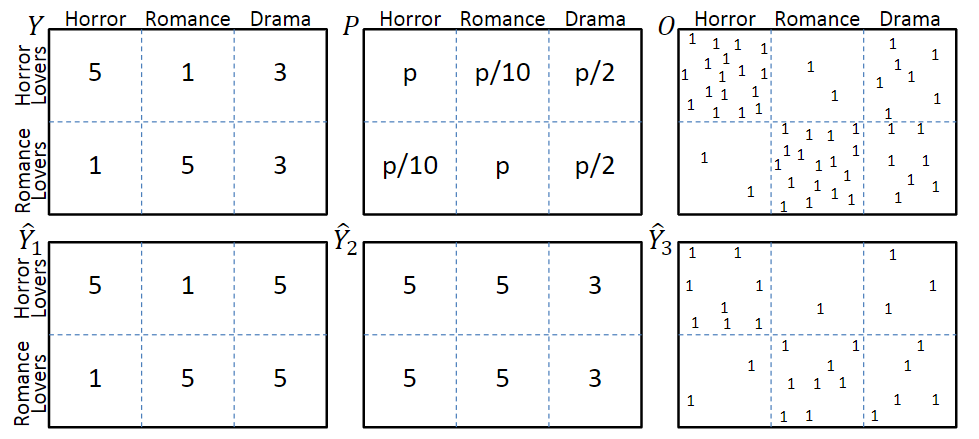
图一
考虑图一中的模型,图中第一行分别表示真实评分Y、曝光概率P和曝光分布O,其中评分越低的交互,观测到的概率也就越低。第二行\(\hat{Y}_1\)和\(\hat{Y}_2\)分别表示两种不同的预测结果,\(\hat{Y}_3\)表示是否发生了交互。
3.1 任务1:评分预测准确率评价
在理想情况下,即所有评分都被观测到时,评价指标为
\]
但在存在selection bias的场景下,评价指标会变为
\]
从喜恶判断的角度,\(\hat{Y}_1\)明显优于\(\hat{Y}_2\);但是从评价指标上看,由于\(\hat{Y}_2\)中预测错误的那些交互很少被观测到,因此,\(\hat{Y}_2\)会优于\(\hat{Y}_1\)。
3.2 推荐质量评价
评价推荐结果的质量,也就是在回答一个反事实问题:如果用户与推荐列表中的物品发生交互,而不是实际上的交互历史,用户的体验会得到多大程度的提升?
评价指标可以是DCG等。由于观测数据是有偏的,与3.1中的描述相似,最终的评价指标也是有偏的。
3.3 基于倾向分数的性能评估
解决selection bias的关键在于理解观测数据的生成机制(Assignment Mechanism),包含系统生成(Experimental Setting)和用户选择(Observational Setting)两种因素。
为了解决评测指标的偏差问题,作者提出使用逆倾向分数对观察数据加权,构建一个对理想评测指标的无偏估计器——IPS Estimator:
\mathbb{E}_{O}\left[\hat{R}_{I P S}(\hat{Y} | P)\right] =\frac{1}{U \cdot I} \sum_{u} \sum_{i} \mathbb{E}_{O_{u, i}}\left[\frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} O_{u, i}\right] \\
=\frac{1}{U \cdot I} \sum_{u} \sum_{i} \delta_{u, i}(Y, \hat{Y})=R(\hat{Y})
\]
其中\(O_{u,i} ~ Bernoulli(P_{u,i})\),\(P_{u,i}\)为propensity score。
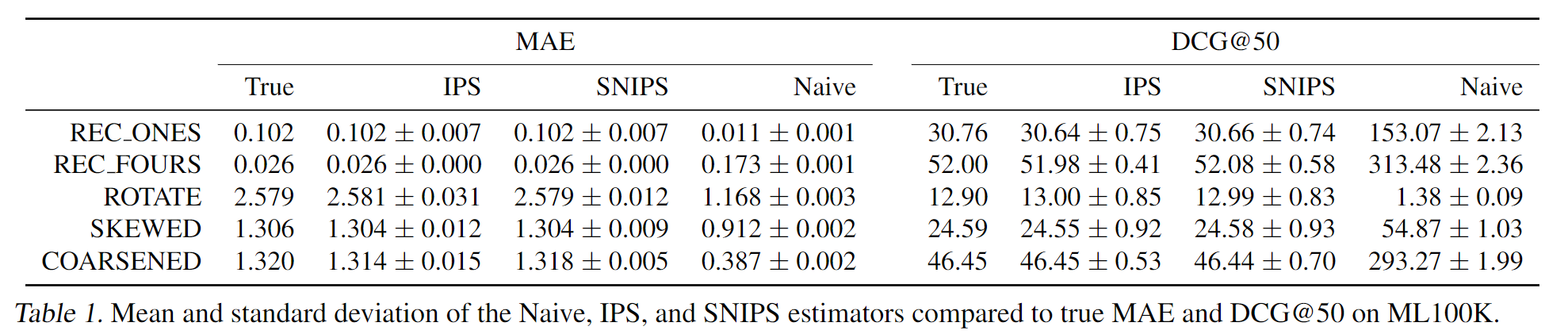
3.4 实验验证
利用MF生成的全曝光模拟数据集,作者设计了几种评分策略,每种策略都有不同的评分错误。基于真实数据集中的曝光情况,计算曝光交互的评价指标,证明了IPS评价指标能有效抵消selection bias带来的评价误差。
4. IPS推荐系统
基于IPS的推荐系统,训练目标为:
\]
其中\(P_{u,i}\)是倾向性评分,相当于在对应的loss项上加了权重。
5. 倾向性评分的估计
作者提出了两种估计方法
朴素贝叶斯估计
这个方法似乎是对评分相同的u-i交互给出了相同的评分?
\[P\left(O_{u, i}=1 \mid Y_{u, i}=r\right)=\frac{P(Y=r \mid O=1) P(O=1)}{P(Y=r)}
\]逻辑斯特回归
将所有关于u-i对的信息都作为特征,来学习一个线性模型
\[P_{u, i}=\sigma\left(w^{T} X_{u, i}+\beta_{i}+\gamma_{u}\right)
\]
6. 实验
6.1 实验设置
训练集是有偏(MNAR)数据,使用k-折交叉验证来调参,使用无偏数据或者合成的全曝光数据作为测试集。
6.2 采样偏差对评测指标的影响
构建全曝光的合成数据集:在ML 100K数据集上,使用MF 填充所有空缺的评分,并对填充之后的评分分布进行调整,以降低高评分的比例。
实验结果见3.4
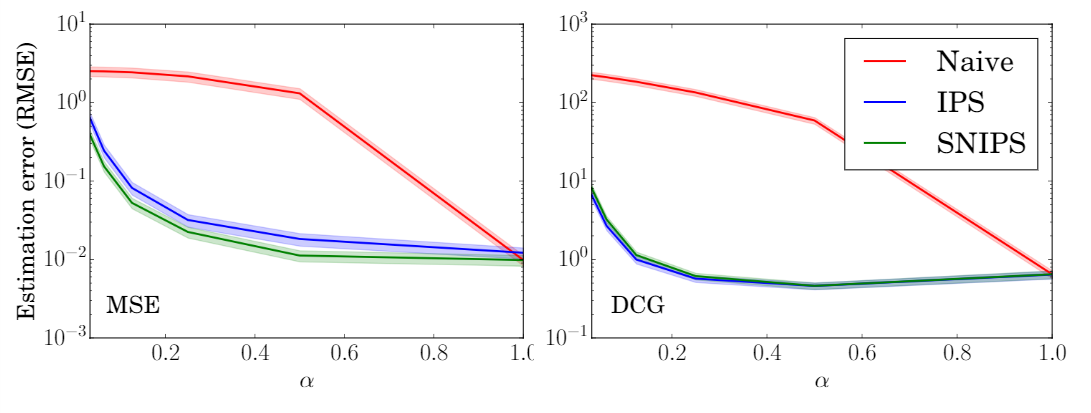
6.3 采样偏差对模型训练的影响
对于不同程度的选择偏差(\(\alpha\)越小,选择偏差越大),实验结果如下图。
可见,IPS-MF和SNIPS-MF的性能要明显优于naive-MF。
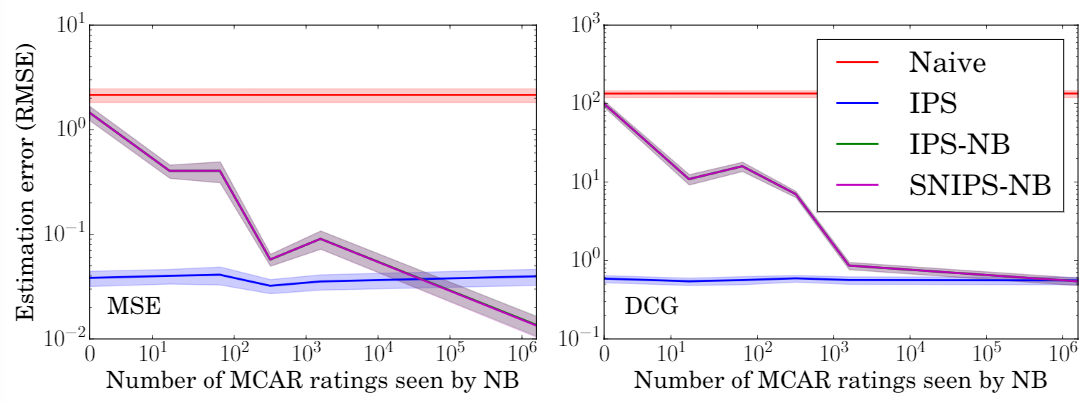
6.4 倾向性评分估计准确度的影响
使用不同比例的数据来估计倾向性评分,可以看出,在所有条件下,IPS和SNIPS都优于MF,验证了模型对倾向性评分的鲁棒性。
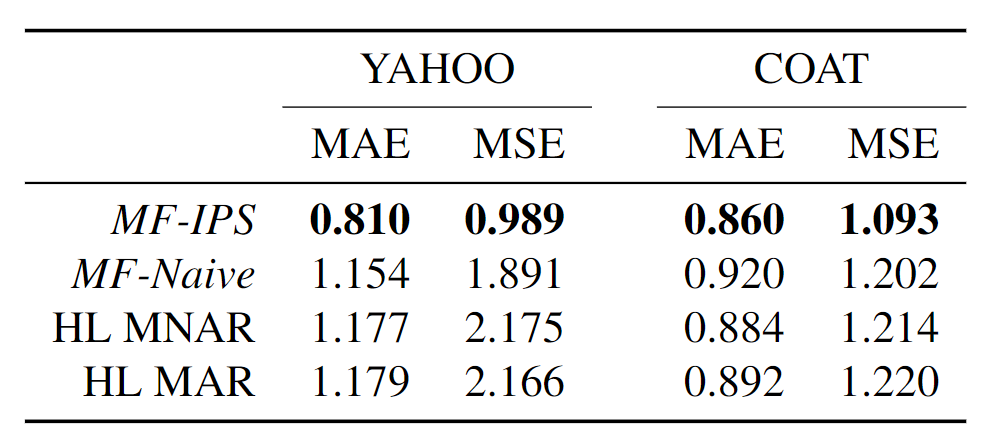
6.5 真实数据集上的性能
Yahoo! R3:使用5%的无偏数据来估计倾向性评分,95%的无偏数据作为测试集。
Coat:本文收集了一个新的无偏数据集Coat(很大的贡献),包含290个user和300个item,每个user自主选择24个商品给出评分,并对16个随机商品给出评分(1-5分)。
实验结果表明,在两个数据集上都优于最好的baseline。
【论文笔记】Recommendations as Treatments: Debiasing Learning and Evaluation的更多相关文章
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 【论文笔记】DeepOrigin: End-to-End Deep Learning for Detection of New Malware Families
DeepOrigin: End-to-End Deep Learning for Detection of New Malware Families 标签(空格分隔): 论文 论文基本信息 会议: I ...
- 论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference
这位更是重量级.这篇论文对于概率论学的一塌糊涂的我简直是灾难. 由于 prompt 的分布与预训练的分布不匹配(预训练的语料是自然语言,而 prompt 是由人为挑选的几个样本拼接而成,是不自然的自然 ...
- 论文笔记之: Deep Metric Learning via Lifted Structured Feature Embedding
Deep Metric Learning via Lifted Structured Feature Embedding CVPR 2016 摘要:本文提出一种距离度量的方法,充分的发挥 traini ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- [loj6278]数列分块入门2
做法1 以$K$为块大小分块,并对每一个块再维护一个排序后的结果,预处理复杂度为$o(n\log K )$ 区间修改时将整块打上标记,散块暴力修改并归并排序,单次复杂度为$o(\frac{n}{K}+ ...
- [atAGC047F]Rooks
如果将$x$和$y$都离散,那么删除的点的$x_{i}$和$y_{i}$必然都组成了一个完整的区间(包括过程中) 将所有点按$x$排序,再令$f[i][j][0/1]$表示当删除完区间$[i,j]$且 ...
- Golang - 关于 proto 文件的一点小思考
目录 前言 helloworld.proto 小思考 小结 推荐阅读 前言 ProtoBuf 是什么? ProtoBuf 是一套接口描述语言(IDL),通俗的讲是一种数据表达方式,也可以称为数据交换格 ...
- GraalVM最佳实践,使用Java开发CLI、Desktop(JavaFX)、Web(SpringBoot)项目,并使用native-image技术把Java代码静态编译为独立可执行文件(本机映像)
原创文章,转载请注明出处! 源码地址: Gitee Gtihub 介绍 GraalVM最佳实践,使用Java开发CLI.Desktop(JavaFX).Web(SpringBoot)项目,并使用nat ...
- Unique Path AGC 038 D
Unique Path AGC 038 D 考虑如果两个点之间只能有一个边它们就把它们缩起来,那么最后缩起来的每一块都只能是一棵树. 如果两个点之间必须不止一个边,并且在一个连通块,显然无解. 首先把 ...
- Codeforces 582D - Number of Binominal Coefficients(Kummer 定理+数位 dp)
Codeforces 题目传送门 & 洛谷题目传送门 一道数论与数位 dp 结合的神题 %%% 首先在做这道题之前你需要知道一个定理:对于质数 \(p\) 及 \(n,k\),最大的满足 \( ...
- 洛谷 P3270 - [JLOI2016]成绩比较(容斥原理+组合数学+拉格朗日插值)
题面传送门 考虑容斥.我们记 \(a_i\) 为钦定 \(i\) 个人被 B 神碾压的方案数,如果我们已经求出了 \(a_i\) 那么一遍二项式反演即可求出答案,即 \(ans=\sum\limits ...
- vector.erase();vector.clear();map.erase();
vector::erase()返回下一个iter: STL中的源码: //清除[first, last)中的所有元素 iterator erase(iterator first, iterator l ...
- sigma网格中水平压力梯度误差及其修正
1.水平梯度误差产生 sigma坐标系下,笛卡尔坐标内水平梯度项对应形式为 \[\begin{equation} \left. \frac{\partial }{\partial x} \right| ...
- 【豆科基因组】鹰嘴豆Chickpea (Cicer arietinum L.)429个自然群体重测序2019NG
目录 一.来源 二.结果 材料测序.变异检测.群体结构和LD衰减 驯化后经历选择的候选基因组区域 起源中心.迁移路线和多样性 GWAS 一.来源 Resequencing of 429 chickpe ...