日志收集系统系列(四)之LogAgent优化
实现功能
logagent根据etcd的配置创建多个tailtasklogagent实现watch新配置logagent实现新增收集任务logagent删除新配置中没有的那个任务logagent根据IP拉取自己的配置
代码实现
config/config.ini[kafka]
address=127.0.0.1:9092
chan_max_size=100000
[etcd]
address=127.0.0.1:2379
timeout=5
collect_log_key=/logagent/%s/collect_configconfig/config.gopackage conf
type Config struct {
Kafka Kafka `ini:"kafka"`
Etcd Etcd `ini:"etcd"`
}
type Kafka struct {
Address string `ini:"address"`
ChanMaxSize int `ini:"chan_max_zise"`
}
type Etcd struct {
Address string `ini:"address"`
Key string `ini:"collect_log_key"`
Timeout int `ini:"timeout"`
}main.gopackage main
import (
"fmt"
"gopkg.in/ini.v1"
"logagent/conf"
"logagent/etcd"
"logagent/kafka"
"logagent/taillog"
"logagent/tools"
"strings"
"sync"
"time"
)
var config = new(conf.Config)
// logAgent 入口程序
func main() {
// 0. 加载配置文件
err := ini.MapTo(config, "./conf/config.ini")
if err != nil {
fmt.Printf("Fail to read file: %v", err)
return
}
// 1. 初始化kafka连接
err = kafka.Init(strings.Split(config.Kafka.Address, ";"), config.Kafka.ChanMaxSize)
if err != nil {
fmt.Println("init kafka failed, err:%v\n", err)
return
}
fmt.Println("init kafka success.")
// 2. 初始化etcd
err = etcd.Init(config.Etcd.Address, time.Duration(config.Etcd.Timeout) * time.Second)
if err != nil {
fmt.Printf("init etcd failed,err:%v\n", err)
return
}
fmt.Println("init etcd success.")
// 实现每个logagent都拉取自己独有的配置,所以要以自己的IP地址实现热加载
ip, err := tools.GetOurboundIP()
if err != nil {
panic(err)
}
etcdConfKey := fmt.Sprintf(config.Etcd.Key, ip)
// 2.1 从etcd中获取日志收集项的配置信息
logEntryConf, err := etcd.GetConf(etcdConfKey)
if err != nil {
fmt.Printf("etcd.GetConf failed, err:%v\n", err)
return
}
fmt.Printf("get conf from etcd success, %v\n", logEntryConf)
// 2.2 派一个哨兵 一直监视着 zhangyafei这个key的变化(新增 删除 修改))
for index, value := range logEntryConf{
fmt.Printf("index:%v value:%v\n", index, value)
}
// 3. 收集日志发往kafka
taillog.Init(logEntryConf)
var wg sync.WaitGroup
wg.Add(1)
go etcd.WatchConf(etcdConfKey, taillog.NewConfChan()) // 哨兵发现最新的配置信息会通知上面的通道
wg.Wait()
}kafka/kafka.gopackage kafka
import (
"fmt"
"github.com/Shopify/sarama"
)
// 专门往kafka写日志的模块
type LogData struct {
topic string
data string
}
var (
client sarama.SyncProducer // 声明一个全局的连接kafka的生产者client
logDataChan chan *LogData
)
// init初始化client
func Init(addrs []string, chanMaxSize int) (err error) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出⼀个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 连接kafka
client, err = sarama.NewSyncProducer(addrs, config)
if err != nil {
fmt.Println("producer closed, err:", err)
return
}
// 初始化logDataChan
logDataChan = make(chan *LogData, chanMaxSize)
// 开启后台的goroutine,从通道中取数据发往kafka
go SendToKafka()
return
}
// 给外部暴露的一个函数,噶函数只把日志数据发送到一个内部的channel中
func SendToChan(topic, data string) {
msg := &LogData{
topic: topic,
data: data,
}
logDataChan <- msg
}
// 真正往kafka发送日志的函数
func SendToKafka() {
for {
select {
case log_data := <- logDataChan:
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = log_data.topic
msg.Value = sarama.StringEncoder(log_data.data)
// 发送到kafka
pid, offset, err := client.SendMessage(msg)
if err != nil{
fmt.Println("sned msg failed, err:", err)
}
fmt.Printf("send msg success, pid:%v offset:%v\n", pid, offset)
//fmt.Println("发送成功")
}
}
}etcd/etcd.gopackage etcd
import (
"context"
"encoding/json"
"fmt"
"go.etcd.io/etcd/clientv3"
"strings"
"time"
)
var (
cli *clientv3.Client
)
type LogEntry struct {
Path string `json:"path"` // 日志存放的路径
Topic string `json:"topic"` // 日志发往kafka中的哪个Topic
}
// 初始化etcd的函数
func Init(addr string, timeout time.Duration) (err error) {
cli, err = clientv3.New(clientv3.Config{
Endpoints: strings.Split(addr, ";"),
DialTimeout: timeout,
})
return
}
// 从etcd中获取日志收集项的配置信息
func GetConf(key string) (logEntryConf []*LogEntry, err error) {
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
resp, err := cli.Get(ctx, key)
cancel()
if err != nil {
fmt.Printf("get from etcd failed, err:%v\n", err)
return
}
for _, ev := range resp.Kvs {
//fmt.Printf("%s:%s\n", ev.Key, ev.Value)
err = json.Unmarshal(ev.Value, &logEntryConf)
if err != nil {
fmt.Printf("unmarshal etcd value failed,err:%v\n", err)
return
}
}
return
}
// etcd watch
func WatchConf(key string, newConfChan chan<- []*LogEntry) {
rch := cli.Watch(context.Background(), key) // <-chan WatchResponse
// 从通道尝试取值(监视的信息)
for wresp := range rch {
for _, ev := range wresp.Events {
fmt.Printf("Type: %s Key:%s Value:%s\n", ev.Type, ev.Kv.Key, ev.Kv.Value)
// 通知taillog.taskMgr
var newConf []*LogEntry
//1. 先判断操作的类型
if ev.Type != clientv3.EventTypeDelete {
// 如果不是是删除操作
err := json.Unmarshal(ev.Kv.Value, &newConf)
if err != nil {
fmt.Printf("unmarshal failed, err:%v\n", err)
continue
}
}
fmt.Printf("get new conf: %v\n", newConf)
newConfChan <- newConf
}
}
}taillog/taillog.gopackage taillog
import (
"context"
"fmt"
"github.com/hpcloud/tail"
"logagent/kafka"
)
// 专门收集日志的模块
type TailTask struct {
path string
topic string
instance *tail.Tail
// 为了能实现退出r,run()
ctx context.Context
cancelFunc context.CancelFunc
}
func NewTailTask(path, topic string) (t *TailTask) {
ctx, cancel := context.WithCancel(context.Background())
t = &TailTask{
path: path,
topic: topic,
ctx: ctx,
cancelFunc: cancel,
}
err := t.Init()
if err != nil {
fmt.Println("tail file failed, err:", err)
}
return
}
func (t TailTask) Init() (err error) {
config := tail.Config{
ReOpen: true, // 充新打开
Follow: true, // 是否跟随
Location: &tail.SeekInfo{Offset: 0, Whence: 2}, // 从文件哪个地方开始读
MustExist: false, // 文件不存在不报错
Poll: true}
t.instance, err = tail.TailFile(t.path, config)
// 当goroutine执行的函数退出的时候,goriutine就退出了
go t.run() // 直接去采集日志发送到kafka
return
}
func (t *TailTask) run() {
for {
select {
case <- t.ctx.Done():
fmt.Printf("tail task:%s_%s 结束了...\n", t.path, t.topic)
return
case line :=<- t.instance.Lines: // 从TailTask的通道中一行一行的读取日志
// 3.2 发往kafka
fmt.Printf("get log data from %s success, log:%v\n", t.path, line.Text)
kafka.SendToChan(t.topic, line.Text)
}
}
}taillog/taillog_mgrpackage taillog
import (
"fmt"
"logagent/etcd"
"time"
)
var taskMrg *TailLogMgr
type TailLogMgr struct {
logEntry []*etcd.LogEntry
taskMap map[string]*TailTask
newConfChan chan []*etcd.LogEntry
}
func Init(logEntryConf []*etcd.LogEntry) {
taskMrg = &TailLogMgr{
logEntry: logEntryConf,
taskMap: make(map[string]*TailTask, 16),
newConfChan: make(chan []*etcd.LogEntry), // 无缓冲区的通道
}
for _, logEntry := range logEntryConf{
// 3.1 循环每一个日志收集项,创建TailObj
// logEntry.Path 要收集的全日志文件的路径
// 初始化的时候齐了多少个tailTask 都要记下来,为了后续判断方便
tailObj := NewTailTask(logEntry.Path, logEntry.Topic)
mk := fmt.Sprintf("%s_%s", logEntry.Path, logEntry.Topic)
taskMrg.taskMap[mk] = tailObj
}
go taskMrg.run()
}
// 监听自己的newConfChan,有了新的配合过来之后就做对应的处理
func (t *TailLogMgr) run() {
for {
select {
case newConf := <- t.newConfChan:
// 1. 配置新增
for _, conf := range newConf {
mk := fmt.Sprintf("%s_%s", conf.Path, conf.Topic)
_, ok := t.taskMap[mk]
if ok {
// 原来就有,不需要操作
continue
}else {
// 新增的
tailObj := NewTailTask(conf.Path, conf.Topic)
t.taskMap[mk] = tailObj
}
}
// 找出原来t.logEntry有,但是newConf中没有的,删掉
for _, c1 := range t.logEntry{ // 循环原来的配置
isDelete := true
for _, c2 := range newConf{ // 取出新的配置
if c2.Path == c1.Path && c2.Topic == c1.Topic {
isDelete = false
continue
}
}
if isDelete {
// 把c1对应的这个tailObj给停掉
mk := fmt.Sprintf("%s_%s", c1.Path, c1.Topic)
// t.taskNap[mk] ==> tailObj
t.taskMap[mk].cancelFunc()
}
}
// 2. 配置删除
// 3. 配置变更
fmt.Println("新的配置来了!", newConf)
default:
time.Sleep(time.Second)
}
}
}
// 一个函数,向外暴露taskMgr的newConfChan
func NewConfChan() chan <-[]*etcd.LogEntry {
return taskMrg.newConfChan
}tools/get_ippackage tools
import (
"net"
"strings"
)
// 获取本地对外IP
func GetOurboundIP() (ip string, err error) {
conn, err := net.Dial("udp", "8.8.8.8:80")
if err != nil {
return
}
defer conn.Close()
localAddr := conn.LocalAddr().(*net.UDPAddr)
//fmt.Println(localAddr.String())
ip = strings.Split(localAddr.IP.String(), ":")[0]
return
}
三. 连接kafka进行消费
将收集项配置放入etcd
package main
import (
"context"
"fmt"
"net"
"strings"
"time"
"go.etcd.io/etcd/clientv3"
)
// 获取本地对外IP
func GetOurboundIP() (ip string, err error) {
conn, err := net.Dial("udp", "8.8.8.8:80")
if err != nil {
return
}
defer conn.Close()
localAddr := conn.LocalAddr().(*net.UDPAddr)
fmt.Println(localAddr.String())
ip = strings.Split(localAddr.IP.String(), ":")[0]
return
}
func main() {
// etcd client put/get demo
// use etcd/clientv3
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"127.0.0.1:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
// handle error!
fmt.Printf("connect to etcd failed, err:%v\n", err)
return
}
fmt.Println("connect to etcd success")
defer cli.Close()
// put
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
value := `[{"path":"f:/tmp/nginx.log","topic":"web_log"},{"path":"f:/tmp/redis.log","topic":"redis_log"},{"path":"f:/tmp/mysql.log","topic":"mysql_log"}]`
//value := `[{"path":"f:/tmp/nginx.log","topic":"web_log"},{"path":"f:/tmp/redis.log","topic":"redis_log"}]`
//_, err = cli.Put(ctx, "zhangyafei", "dsb")
//初始化key
ip, err := GetOurboundIP()
if err != nil {
panic(err)
}
log_conf_key := fmt.Sprintf("/logagent/%s/collect_config", ip)
_, err = cli.Put(ctx, log_conf_key, value)
//_, err = cli.Put(ctx, "/logagent/collect_config", value)
cancel()
if err != nil {
fmt.Printf("put to etcd failed, err:%v\n", err)
return
}
// get
ctx, cancel = context.WithTimeout(context.Background(), time.Second)
resp, err := cli.Get(ctx, log_conf_key)
//resp, err := cli.Get(ctx, "/logagent/collect_config")
cancel()
if err != nil {
fmt.Printf("get from etcd failed, err:%v\n", err)
return
}
for _, ev := range resp.Kvs {
fmt.Printf("%s:%s\n", ev.Key, ev.Value)
}
}消费者代码
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
// kafka consumer
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions("web_log") // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println("分区: ", partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
go func(sarama.PartitionConsumer) {
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%s Value:%s\n", msg.Partition, msg.Offset, msg.Key, msg.Value)
}
}(pc)
}
select {}
}运行步骤
开启zookeeper
开启kafka
开启etcd
设置收集项配置到etcd
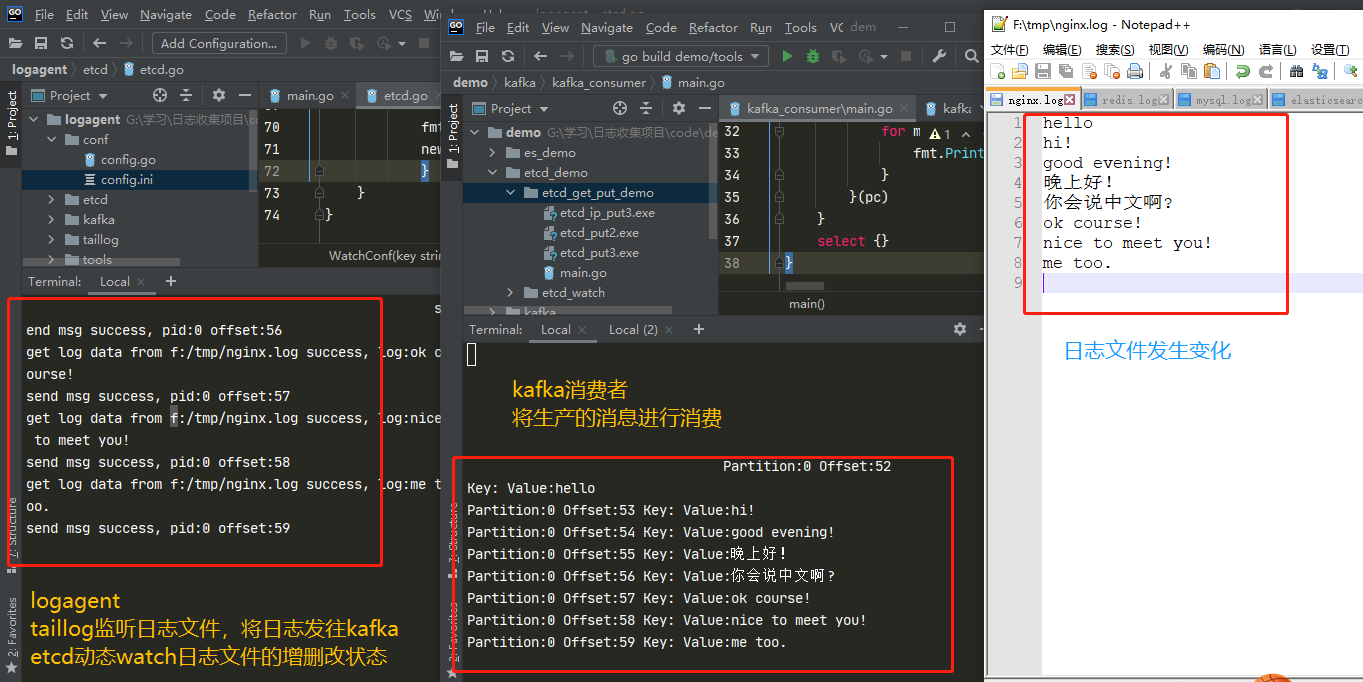
运行logagent从etcd加载收集项配置,使用taillog监听日志文件内容,将新增的日志内容发往kafka
连接kafka进行消费
添加日志内容,观察logagent生产和kafka消费状态
项目地址:https://gitee.com/zhangyafeii/go-log-collect
日志收集系统系列(四)之LogAgent优化的更多相关文章
- 日志收集系统系列(三)之LogAgent
一.什么是LogAhent 类似于在linux下通过tail的方法读日志文件,将读取的内容发给kafka,这里的tailf是可以动态变化的,当配置文件发生变化时,可以通知我们程序自动增加需要增加的配置 ...
- 日志收集系统系列(五)之LogTransfer
从kafka里面把日志取出来,写入ES,使用Kibana做可视化展示 1. ElasticSearch 1.1 介绍 Elasticsearch(ES)是一个基于Lucene构建的开源.分布式.RES ...
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
- 基于Flume的美团日志收集系统 架构和设计 改进和优化
3种解决办法 https://tech.meituan.com/mt-log-system-arch.html 基于Flume的美团日志收集系统(一)架构和设计 - https://tech.meit ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- GO学习-(33) Go实现日志收集系统2
Go实现日志收集系统2 一篇文章主要是关于整体架构以及用到的软件的一些介绍,这一篇文章是对各个软件的使用介绍,当然这里主要是关于架构中我们agent的实现用到的内容 关于zookeeper+kaf ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- 【C/C++】字符数组:char,char*,char a[], char *a[], char **s 的区别与联系/const char*和char*的区别
一.char,char*,char a[], char *a[], char **s 的区别与联系 C语言中的字符串是字符数组,可以像处理普通数组一样处理字符串. 可以理解为在内存中连续存储的字符. ...
- 利用代码覆盖率提高嵌入式软件的可靠性 - VectorCAST
简介 代码覆盖率是衡量软件测试完成情况的指标,通常基于测试过程中已检查的程序源代码比例 计算得出.代码覆盖率可以有效避免包含未测试代码的程序被发布. 代码覆盖率能不能提高软件的可靠性?答案是肯定的,代 ...
- Game On Serverless:SAE 助力广州小迈提升微服务研发效能
作者:洛浩 小迈于 2015 年 1 月成立,是一家致力以数字化领先为优势,实现业务高质量自增长的移动互联网科技公司.始终坚持以用户价值为中心,以数据为驱动,为用户开发丰富的工具应用.休闲游戏.益智. ...
- GDAL重投影重采样像元配准对齐
研究通常会涉及到多源数据,需要进行基于像元的运算,在此之前需要对数据进行地理配准.空间配准.重采样等操作.那么当不同来源,不同分辨率的数据重采样为同一空间分辨率之后,各个像元不一一对应,有偏移该怎么办 ...
- RabbitMQ 消息队列 实现RPC 远程过程调用交互
#!/usr/bin/env python # Author:Zhangmingda import pika,time import uuid class FibonacciRpcClient(obj ...
- Linux三剑客综合练习
1.找出/proc/meminfo文件中以s开头的行,至少用三种方式忽略大小写 [root@localhost ~]# grep -E '^[sS]' /proc/meminfo [root@loca ...
- c(++)变长参数之整形(非字符串类型类似)
0.序言 变长参数,接触的第一个可变长参数函数是 printf , 然后是 scanf .他们的原型如下: printf: _Check_return_opt_ _CRT_STDIO_INLI ...
- CMake判断操作系统和编译器
判断操作系统 IF (CMAKE_SYSTEM_NAME MATCHES "Linux") ELSEIF (CMAKE_SYSTEM_NAME MATCHES "Wind ...
- LeetCode Top 100 Liked 点赞最高的 100 道算法题
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 公众号:负雪明烛 本文关键词:刷题顺序,刷题路径,好题,top100,怎么刷题,Leet ...
- 【九度OJ】题目1170:找最小数 解题报告
[九度OJ]题目1170:找最小数 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1170 题目描述: 第一行输入一个数n,1 < ...