基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践
- 实时数据落地需求演进
- 基于Spark+Hudi的实时数据落地应用实践
- 基于Flink自定义实时数据落地实践
- 基于Flink+Hudi的应用实践
- 后续应用规划及展望

1. 实时数据落地需求演进
实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时指标到oracle库中供展示查询。
随着实时平台的稳定及推广开放,各种使用人员有了更广发的需求:
- 对实时开发来说,需要将实时sql数据落地做一些etl调试,数据取样等过程检查;
- 数据分析、业务等希望能结合数仓已有数据体系,对实时数据进行分析和洞察,比如用户行为实时埋点数据结合数仓已有一些模型进行分析,而不是仅仅看一些高度聚合化的报表;
- 业务希望将实时数据作为业务过程的一环进行业务驱动,实现业务闭环;
- 针对部分需求,需要将实时数据落地后,结合其他数仓数据,T - 1离线跑批出报表;
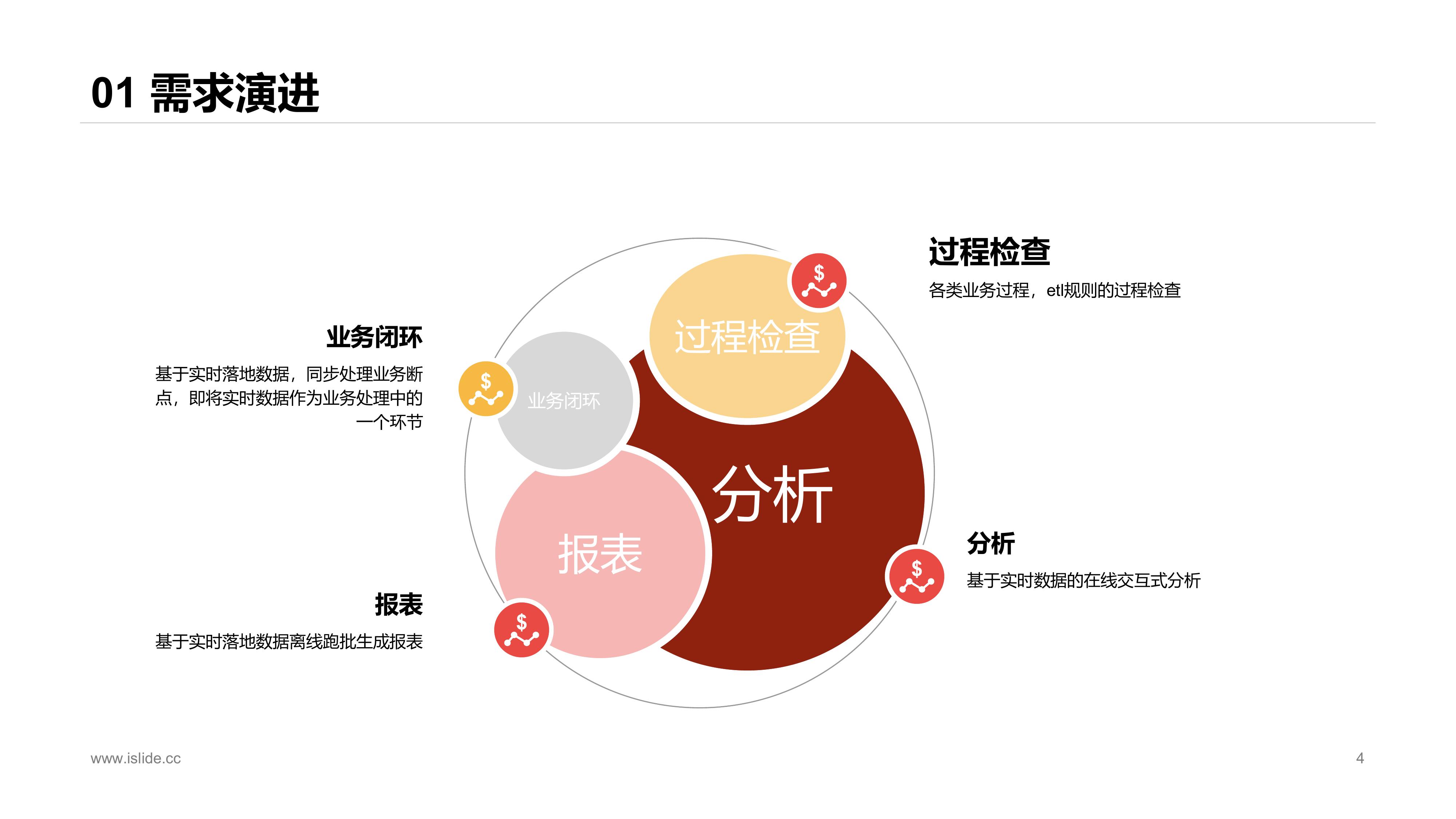
除了上述列举的主要的需求,还有一些零碎的需求。
总的来说,实时平台输出高度聚合后的数据给用户,已经满足不了需求,用户渴求更细致,更原始,更自主,更多可能的数据
而这需要平台能将实时数据落地至离线数仓体系中,因此,基于这些需求演进,实时平台开始了实时数据落地的探索实践
2. 基于Spark+Hudi的实时数据落地应用实践
最早开始选型的是比较流行的Spark + Hudi体系,整体落地架构如下:
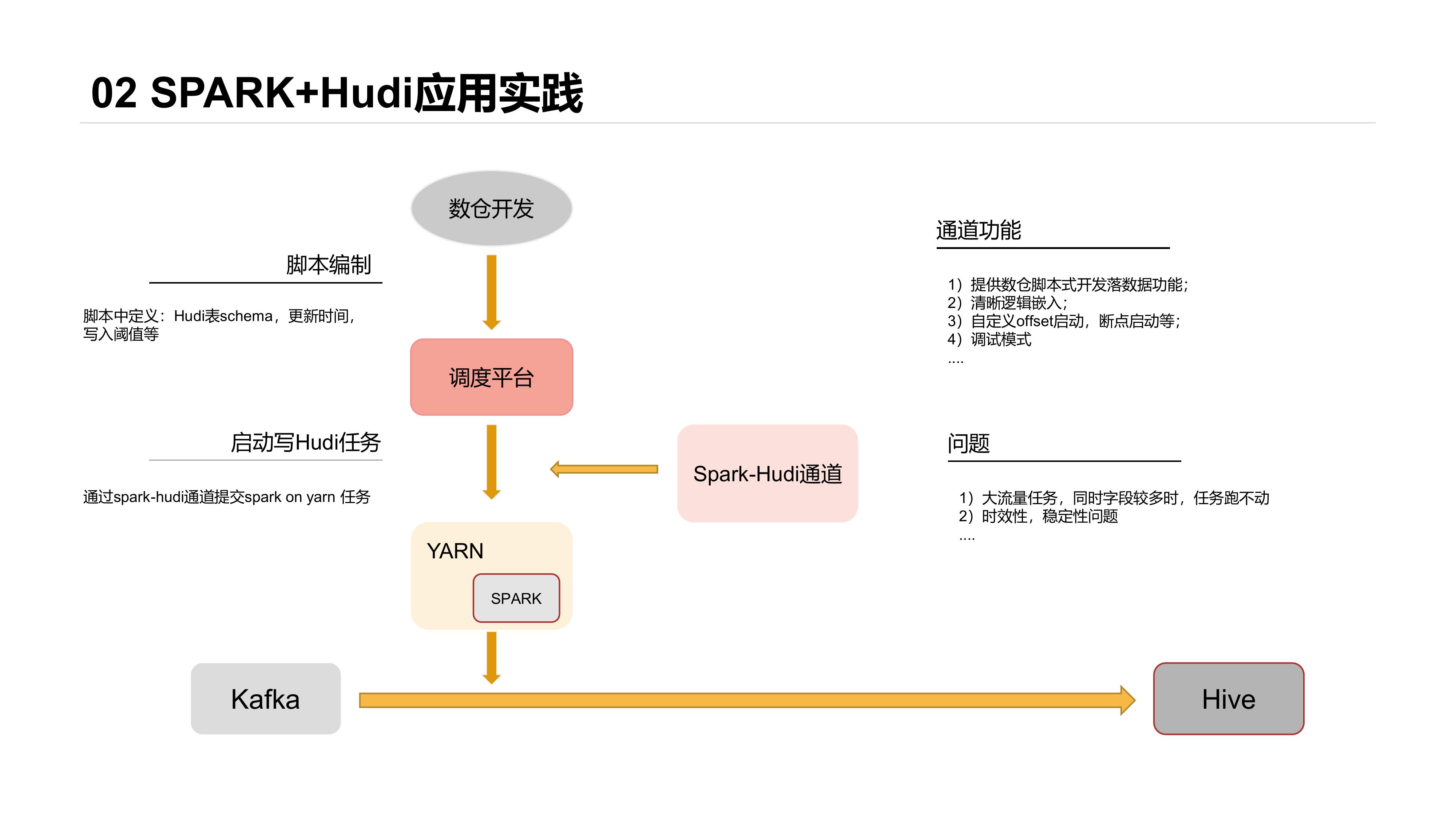
这套主要基于以下考虑:
- 数仓开发不需写Scala/Java打Jar包做任务开发
- ETL逻辑能够嵌入落数据任务中
- 开发入口统一
我们当时做了通用的落数据通道,通道由Spark任务Jar包和Shell脚本组成,数仓开发入口为统一调度平台,将落数据的需求转化为对应的Shell参数,启动脚本后完成数据的落地。
3. 基于Flink自定义实时数据落地实践
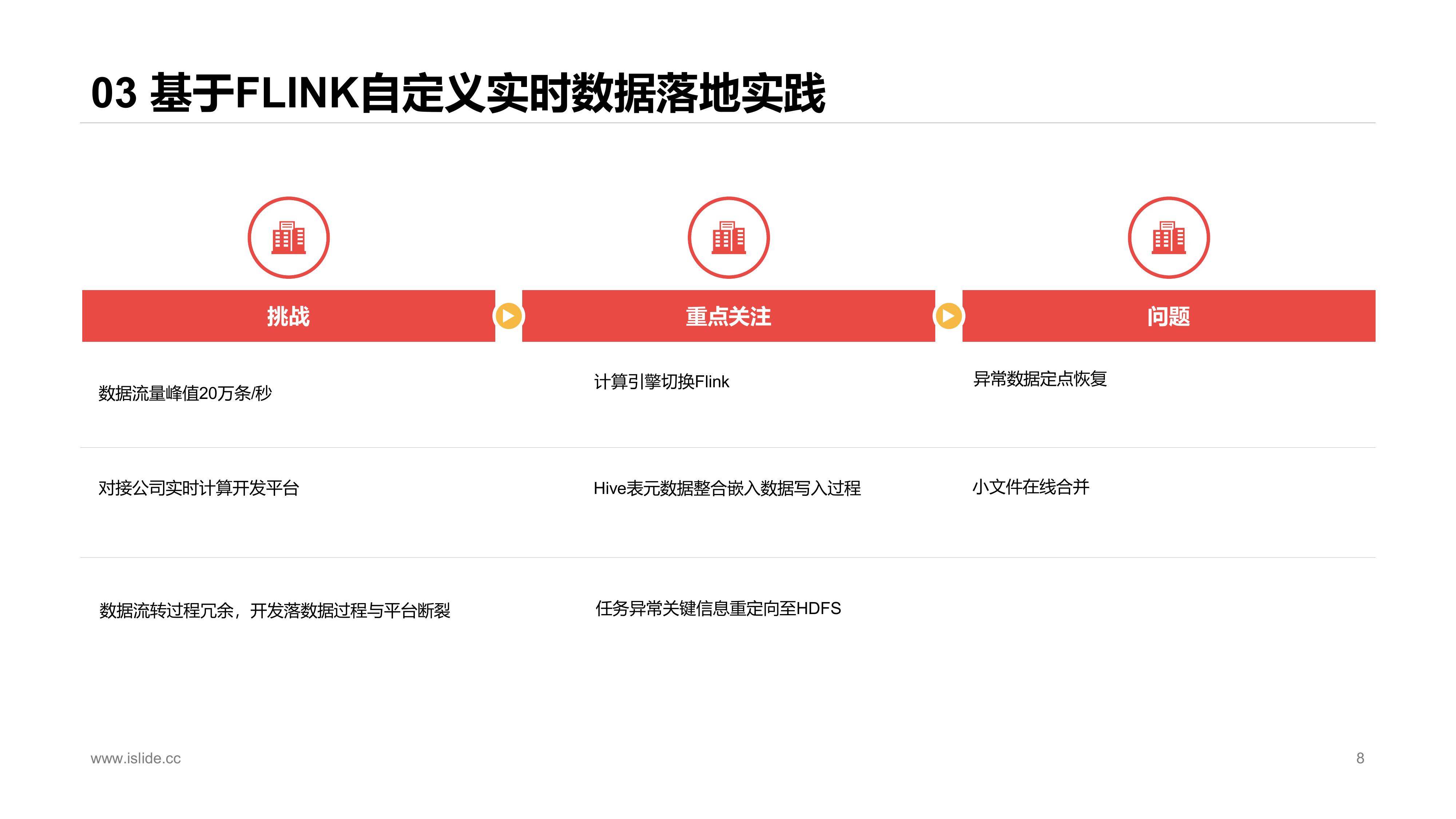
由于我们当时实时平台是基于Flink,同时Spark+Hudi对于大流量任务的支持有一些问题,比如落埋点数据时,延迟升高,任务经常OOM等,因此决定探索Flink落数据的路径。
当时Flink+Hudi社区还没有实现,我们参考Flink+ORC的落数据的过程,做了实时数据落地的实现,主要是做了落数据Schema的参数化定义,使数据开发同事能shell化实现数据落地。
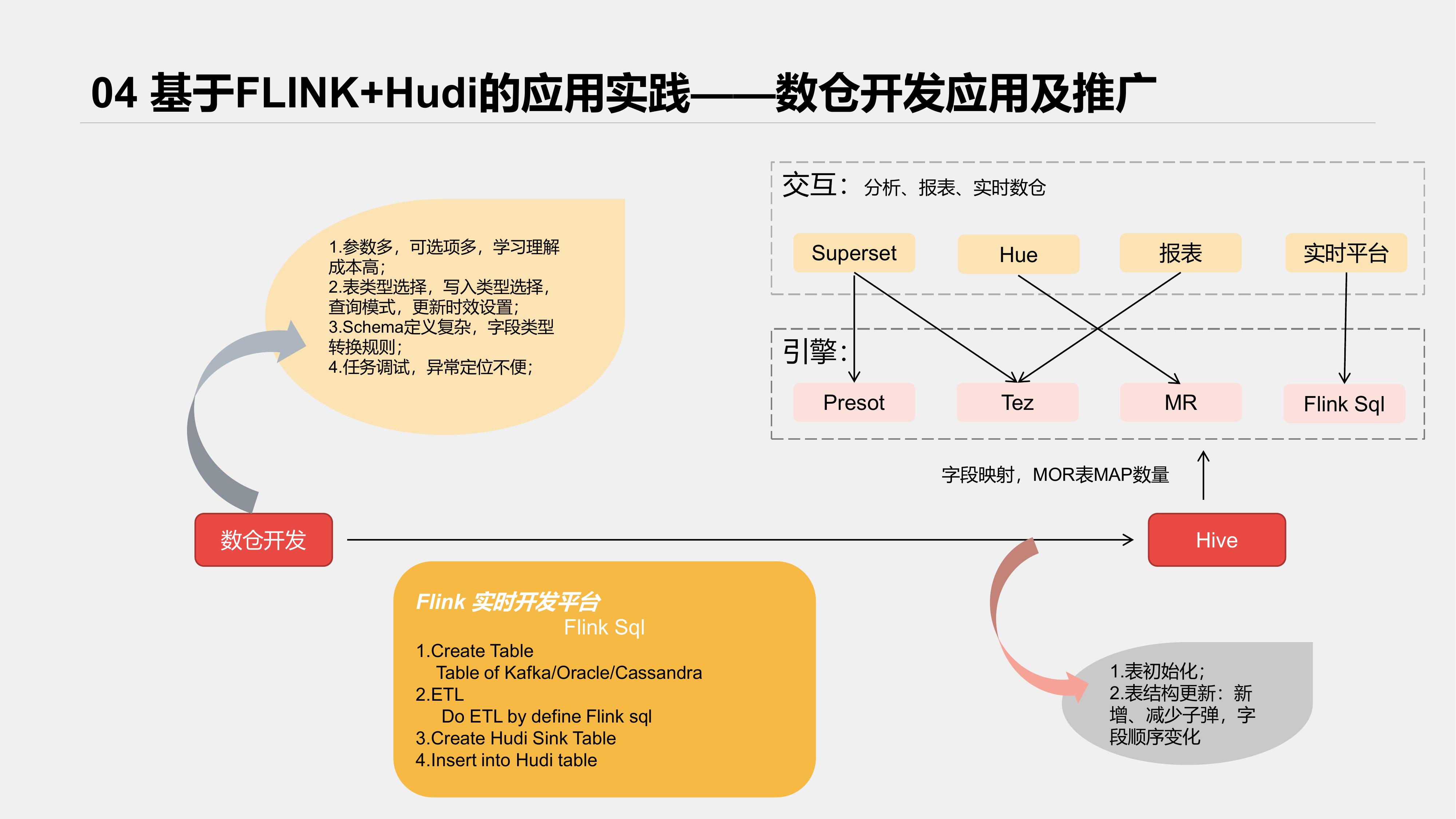
4. 基于Flink + Hudi的落地数据实践
Hudi整合Flink版本出来后,实时平台就着手准备做兼容,把Hudi纳入了实时平台开发内容。
先看下接入后整体架构
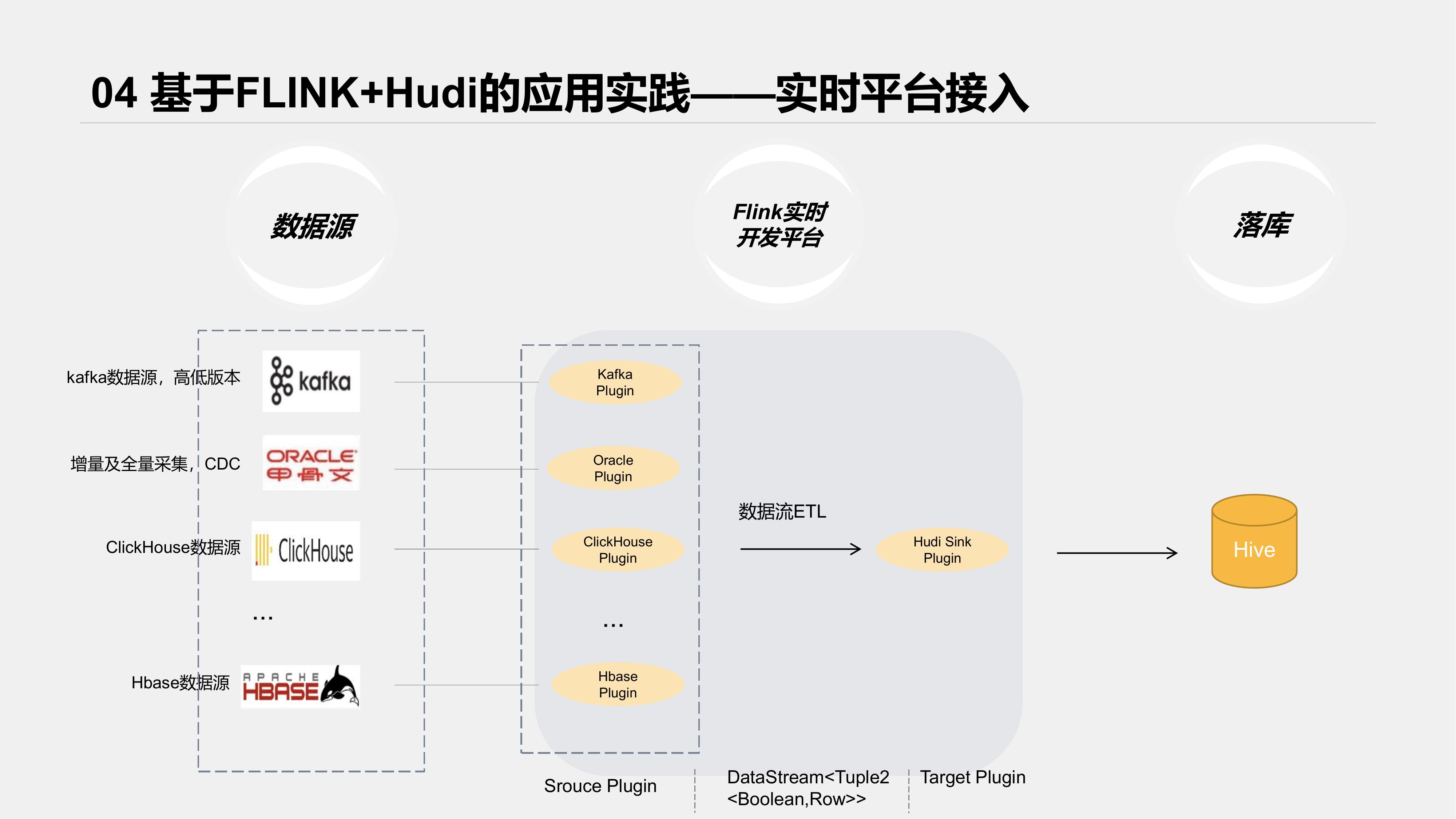
实时平台对各类数据源及Sink端都以各类插件接入,我们参考了HudiFlinkTable的Sink流程,将Hudi接入了我们的实时开发平台。
为了提高可用性,我们主要做了以下辅助功能;
- Hive表元数据自动同步、更新;
- Hudi schema自动拼接;
- 任务监控、Metrics数据接入等
实际使用过程如下
整套体系上线后,各业务线报表开发,实时在线分析等方面都有使用,比较好的赋能了业务,上线链路共26条,单日数据落入约3亿条左右
5. 后续应用规划及展望
后续主要围绕如下几个方面做探索
5.1 取代离线报表,提高报表实时性及稳定性
离线报表特点是 T - 1,凌晨跑数,以及报表整体依赖链路长。两个特点导致时效性不高是一个方面,另一个方面是,数据依赖链路长的情况下,中间数据出问题容易导致后续整体依赖延时,而很多异常需要等到报表任务实际跑的时候,才能暴露出来。并且跑批问题凌晨暴露,解决的时效与资源协调都是要降低一个等级的,这对稳定性准时性要求的报表是不可接受的,特别是金融公司来说,通过把报表迁移至实时平台,不仅仅是提升了报表的时效性,由于抽数及报表etl是一直再实时跑的,报表数据给出的稳定性能有一个较大的提升。这是我们Hudi实时落数据要应用的规划之一
5.2 完善监控体系,提升落数据任务稳定性
目前仅仅做到落数据任务的监控,即任务是否正常运行,有没有抛异常等等。但实际使用者更关心数据由上游到Hive整条链路的监控情况。比如数据是否有延迟,是否有背压,数据源消费情况,落数据是否有丢失,各个task是否有瓶颈等情况,总的来说,用户希望能更全面细致的了解到任务的运行情况,这也是后面的监控需要完善的目标
5.3 落数据中间过程可视化探索
这个是和上面的监控有类似的地方,用户希望确定,一条数据从数据源接进来,经过各个算子的处理,它的一些详细情况。比如这个数据是否应该被过滤,处于哪个窗口,各个算子的处理时间等等,否则对于用户,整个数据SQL处理流程是一个黑盒。
基于Apache Hudi + Flink的亿级数据入湖实践的更多相关文章
- 挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 精彩回顾 近期,初灵科技的大数据开发工程师钟霈合在社区活动的线 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
随机推荐
- python爬虫期末复习
python期末复习 选择题 以下选项中合法的是(A). A 爬取百度的搜索结果 B 爬取淘宝的商品数据 C 出售同学的个人信息 D 为高利贷提供技术服务 网站的根目录下有一个文件告诉爬虫哪些内容可以 ...
- 【划重点】Python xlrd简介
一.用xlrd获取对应数据,并获取所有sheet的名字 import xlrd data=xlrd.open_workbook(r'C:\Users\ASUS\Desktop\重新开始\Python获 ...
- MySQL 面试题汇总(持续更新中)
COUNT COUNT(*) 和 COUNT(1) 根据 MySQL 官方文档的描述: InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) opera ...
- CF60A Where Are My Flakes? 题解
Content 有人发现他的麦片不见了,原来是室友把它藏在了 \(n\) 个盒子中的一个,另外还有 \(m\) 个提示,有两种: \(\texttt{To the left of }x\):麦片在第 ...
- java 编程基础 反射方式获取泛型的类型Fileld.getGenericType() 或Method.getGenericParameterTypes(); (ParameterizedType) ;getActualTypeArguments()
引言 自从JDK5以后,Java Class类增加了泛型功能,从而允许使用泛型来限制Class类,例如,String.class的类型实际上是 Class 如果 Class 对应的类暂时未知,则使 C ...
- STL源码剖析-waked_ptr
目录一.提问二. 代码实现2.1 mweak_ptr的具体实现2.2 测试用例一.提问weak_ptr为什么会存在?shared_ptr不是已经有了引用计数吗?具体原因详见模拟实现boost库中的sh ...
- SpringBoot内嵌ftp服务
引入依赖 <!-- https://mvnrepository.com/artifact/org.apache.ftpserver/ftpserver-core --> <depen ...
- Guava Retryer实现接口重试
前言 小黑在开发中遇到个问题,我负责的模块需要调用某个三方服务接口查询信息,查询结果直接影响后续业务逻辑的处理: 这个接口偶尔会因网络问题出现超时,导致我的业务逻辑无法继续处理: 这个问题该如何解决呢 ...
- 【九度OJ】题目1138:进制转换 解题报告
[九度OJ]题目1138:进制转换 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1138 题目描述: 将一个长度最多为30 ...
- HDU 4355:Party All the Time(三分模板)
Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission(s) ...