MySQL实战45讲(10--15)-笔记
11 | 怎么给字符串字段加索引?
维护一个支持邮箱登录的系统,用户表是这么定义的:
mysql> create table SUser(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
登录操作,有类似这样的语句
mysql> select f1, f2 from SUser where email='xxx';
如果 email 这个字段上没有索引,那么这个语句就只能做全表扫描。
同时,MySQL 是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
创建前缀索引
比如,这两个在 email 字段上创建索引的语句:
mysql> alter table SUser add index index1(email);
或
mysql> alter table SUser add index index2(email(6));
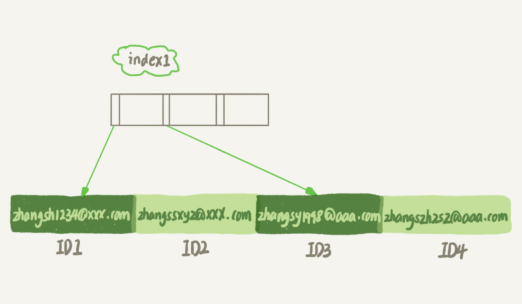
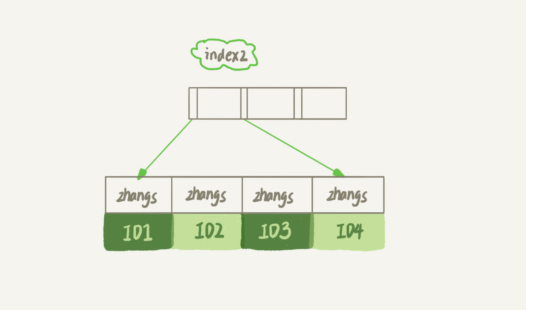
前缀索引占用的空间会更小,这同时带来的损失是,可能会增加额外的记录扫描次数。
分析语句的执行流程:
select id,name,email from SUser where email='zhangssxyz@xxx.com';
如果使用的是 index1(即 email 整个字符串的索引结构),这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
如果使用的是 index2(即 email(6) 索引结构),可能要扫描多行。
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
更好的索引长度
语句:
mysql> select count(distinct email) as L from SUser;
可以一同使用 DISTINCT 和 COUNT 关键词,来计算非重复结果的数目。
mysql> select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例。
前缀索引对覆盖索引的影响
语句:
select id,email from SUser where email='zhangssxyz@xxx.com';
select id,name,email from SUser where email='zhangssxyz@xxx.com';
如果使用 index1(即 email 整个字符串的索引结构)的话,可以利用覆盖索引,从index1 查到结果后直接就返回了,不需要回到 ID 索引再去查一次。
而如果使用 index2(即email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
其他方式
第一种方式是使用倒序存储。
如果你存储身份证号的时候把它倒过来存,每次查询的时候,你可以这么写:
mysql> select field_list from t where id_card = reverse('input_id_card_string');
第二种方式是使用 hash 字段。
你可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
使用倒序存储和使用 hash 字段这两种方法的异同点:
- 从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,
而 hash字段方法需要增加一个字段。
当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
- 在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,
而hash 字段的方式需要额外调用一次 crc32() 函数。
如果只从这两个函数的计算复杂度来看的话,reverse 函数额外消耗的 CPU 资源会更小些。
- 从查询效率上看,使用 hash 字段方式的查询性能相对更稳定一些。
因为 crc32 算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近 1。
而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
小结
- 直接创建完整索引,这样可能比较占用空间;
- 创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引;
- 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题;
- 创建 hash 字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不
支持范围扫描。
12 | 为什么我的MySQL会“抖”一下?
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。
内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
MySQL 偶尔“抖”一下的那个瞬间,可能就是在刷脏页(flush)。
例如这几种场景:
- 对应的就是 InnoDB 的 redo log 写满了。这时候系统会停止所有更新操作,把checkpoint 往前推进,redo log 留出空间可以继续写。
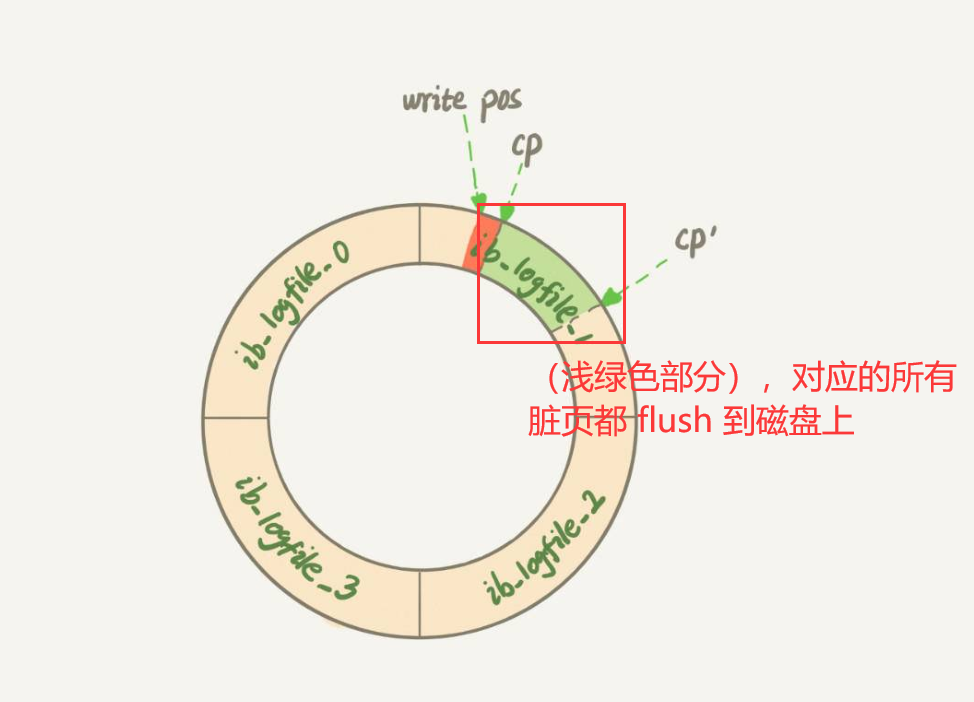
系统内存不足。当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。如果淘汰的是“脏页”,就要先将脏页写到磁盘。
MySQL 认为系统“空闲”的时候,也要见缝插针地找时间,只要有机会就刷一点“脏页”。
MySQL 正常关闭的情况。这时候,MySQL 会把内存的脏页都 flush到磁盘上,这样下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快。
其中第三第四种情况不需要多考虑,
第一种是“redo log 写满了,要 flush 脏页”,这种情况是 InnoDB 要尽量避免的。
因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住。如果你从监控上看,这时候更新数会跌为 0。
第二种是“内存不够用了,要先将脏页写到磁盘”,这种情况其实是常态。
InnoDB 用缓冲池(buffer pool)管理内存,缓冲池中的内存页有三种状态:
- 还没有使用的;
- 使用了并且是干净页;
- 使用了并且是脏页。
InnoDB 的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少。
所以,刷脏页虽然是常态,但是出现以下这两种情况,都是会明显影响性能的:
- 一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长;
- 日志写满,更新全部堵住,写性能跌为 0,这种情况对敏感业务来说,是不能接受的。
InnoDB 刷脏页的控制策略
要知道 InnoDB 所在主机的 IO 能力,这样 InnoDB 才能知道需要全力刷脏页可以刷多快。
这就要用到 innodb_io_capacity 这个参数了,它会告诉 InnoDB 你的磁盘能力。
这个值我建议你设置成磁盘的 IOPS。磁盘的 IOPS 可以通过 fio 这个工具来测试。
InnoDB 的刷盘速度就是要参考这两个因素:
- 一个是脏页比例
- 一个是 redo log 写盘速度。
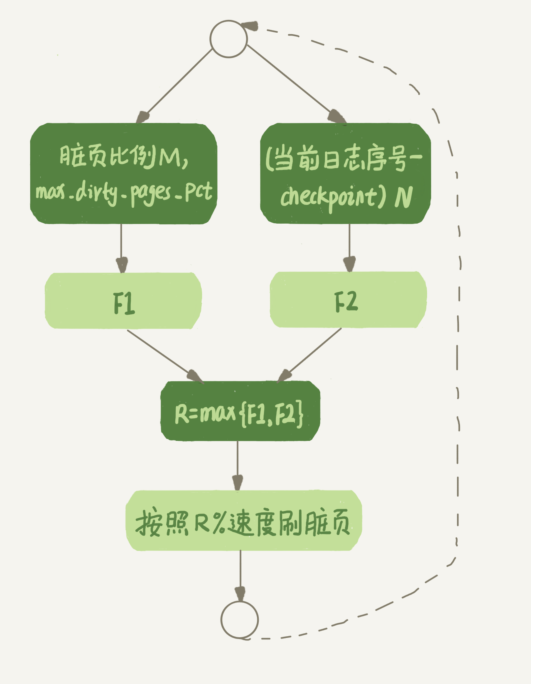
现在你知道了,InnoDB 会在后台刷脏页,而刷脏页的过程是要将内存页写入磁盘。
所以,无论是你的查询语句在需要内存的时候可能要求淘汰一个脏页,还是由于刷脏页的逻辑会占用 IO 资源并可能影响到了你的更新语句,都可能是造成你从业务端感知到 MySQL“抖”了一下的原因。
要尽量避免这种情况,你就要合理地设置 innodb_io_capacity 的值,并且平时要多关注脏页比例,不要让它经常接近 75%。
其中,脏页比例是通过 Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total
得到的。
接下来,我们再看一个有趣的策略。
一旦一个查询请求需要在执行过程中先 flush 掉一个脏页时,这个查询就可能要比平时慢了。而
MySQL 中的一个机制,可能让你的查询会更慢:在准备刷一个脏页的时候,如果这个数据页旁
边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉;而且这个把“邻居”拖下水的逻
辑还可以继续蔓延,也就是对于每个邻居数据页,如果跟它相邻的数据页也还是脏页的话,也会
被放到一起刷。
在 InnoDB 中,innodb_flush_neighbors 参数就是用来控制这个行为的,值为 1 的时候会有上
述的“连坐”机制,值为 0 时表示不找邻居,自己刷自己的。
找“邻居”这个优化在机械硬盘时代是很有意义的,可以减少很多随机 IO。机械硬盘的随机
IOPS 一般只有几百,相同的逻辑操作减少随机 IO 就意味着系统性能的大幅度提升。
而如果使用的是 SSD 这类 IOPS 比较高的设备的话,我就建议你把 innodb_flush_neighbors
的值设置成 0。因为这时候 IOPS 往往不是瓶颈,而“只刷自己”,就能更快地执行完必要的刷
脏页操作,减少 SQL 语句响应时间。
在 MySQL 8.0 中,innodb_flush_neighbors 参数的默认值已经是 0 了。
13 | 为什么表数据删掉一半,表文件大小不变?
一个 InnoDB 表包含两部分,即:表结构定义和数据。
在 MySQL 8.0 版本以前,表结构是存在以.frm 为后缀的文件里。而 MySQL 8.0 版本,则已经允许把表结构定义放在系统数据表中了。因为表结构定义占用的空间很小,所以我们今天主要讨论的是表数据。
参数 innodb_file_per_table
表数据既可以存在共享表空间里,也可以是单独的文件。
这个行为是由参数 innodb_file_per_table 控制的:
这个参数设置为 OFF 表示的是,表的数据放在系统共享表空间,也就是跟数据字典放在一起;
这个参数设置为 ON 表示的是,每个 InnoDB 表数据存储在一个以 .ibd 为后缀的文件中。
从 MySQL 5.6.6 版本开始,它的默认值就是 ON 了。
我建议你不论使用 MySQL 的哪个版本,都将这个值设置为 ON。
因为,一个表单独存储为一个文件更容易管理,而且在你不需要这个表的时候,通过 drop table 命令,系统就会直接删除这个文件。
而如果是放在共享表空间中,即使表删掉了,空间也是不会回收的。
数据删除流程
在B+树的结构中就算是删除了,它还是没有释放这个空间,而是可能会复用这个位置,所以磁盘的文件大小不会缩小。
(就算是一页的数据给删除了,那也只是说明,这一页可以片被复用了)
但是,数据页的复用跟记录的复用是不同的。
delete 命令其实只是把记录的位置,或者数据页标记为了“可复用”,但磁盘文件的大小是不会变的。
也就是说,通过 delete 命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是“空洞”。
实际上,不止是删除数据会造成空洞,插入数据也会。
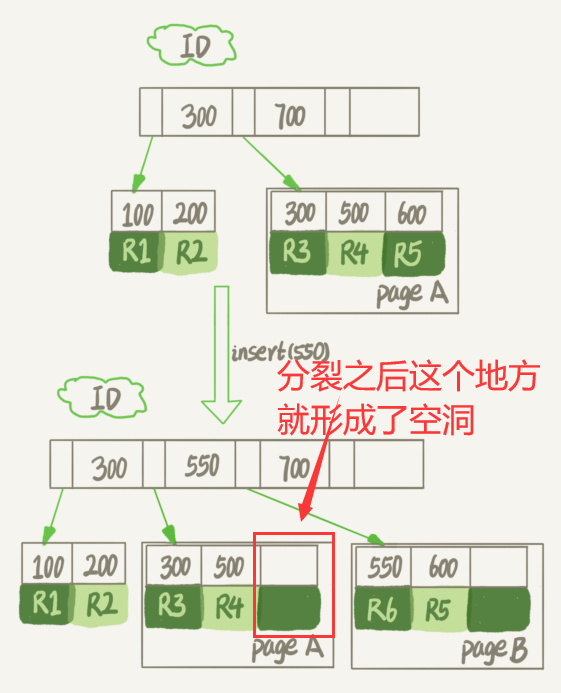
重建表
alter table A engine=InnoDB 命令来重建表,重建之后更紧凑,数据页的利用率也更高。
在 MySQL 5.5 版本之前,这个命令的执行流程跟我们前面描述的差不多,区别只是这个临时表 B 不需要你自己创建,
MySQL 会自动完成转存数据、交换表名、删除旧表的操作。
但是这个 DDL 不是 Online 的。
而在MySQL 5.6 版本开始引入的 Online DDL,对这个操作流程做了优化。
1. 建立一个临时文件,扫描表 A 主键的所有数据页;
2. 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;
3. 生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中
4. 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件
5. 用临时文件替换表 A 的数据文件。
简单来说就是:+ row log,把DDL过程中的操作弄进去了。
14 | count(*)这么慢,我该怎么办?
count(*) 的实现方式
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count() 的时候会直接返回这个数,效率很高;
- 而 InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
这里需要注意的是,我们在这篇文章里讨论的是没有过滤条件的 count(*),
如果加了 where 条件的话,MyISAM 表也是不能返回得这么快的。
那为什么 InnoDB 不跟 MyISAM 一样,也把数字存起来呢?
这是因为即使是在同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,
InnoDB表“应该返回多少行”也是不确定的。
count(*) 操作的时候还是做了优化的:
在保证逻辑正确的前提下,尽量减少扫描的数据量,是数据库系统设计的通用法则之一。
- MyISAM 表虽然 count() 很快,但是不支持事务;
- show table status 命令虽然返回很快,但是不准确;(官方文档说误差可能达到 40% 到 50%)
- InnoDB 表直接 count() 会遍历全表,虽然结果准确,但会导致性能问题。
用缓存系统保存计数
你可以用一个 Redis 服务来保存这个表的总行数。这个表每被插入一行 Redis 计数就加 1,每被删除一行 Redis 计数就减 1。
问题:可能会丢失更新。
还有:将计数保存在缓存系统中的方式,还不只是丢失更新的问题。即使 Redis 正常工作,这个值还是逻辑上不精确的。
在数据库保存计数
如果我们把这个计数直接放到数据库里单独的一张计数表 C 中,又会怎么样呢?
- 首先,这解决了崩溃丢失的问题,InnoDB 是支持崩溃恢复不丢数据的。
- 利用“事务”这个特性,解决计数不准确的问题。
不同的 count 用法
count() 的语义:
count() 是一个聚合函数,对于返回的结果集,一行行判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加。最后返回累计值。
分析性能差别的时候,你可以记住这么几个原则:
1. server 层要什么就给什么;
2. InnoDB 只给必要的值;
3. 现在的优化器只优化了 count(*) 的语义为“取行数”,其他“显而易见”的优化并没有做。
对于 count(主键 id) 来说,
InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
对于 count(1) 来说,
InnoDB 引擎遍历整张表,但不取值server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
对于 count(字段) 来说:
如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
但是 count() 是例外,
并不会把全部字段取出来,而是专门做了优化,不取值。count() 肯定不是 null,按行累加。
小结
把计数放在 Redis 里面,不能够保证计数和 MySQL 表里的数据精确一致的原因,
是这两个不同的存储构成的系统,不支持分布式事务,无法拿到精确一致的视图。
而把计数值也放在MySQL 中,就解决了一致性视图的问题。
InnoDB 引擎支持事务,我们利用好事务的原子性和隔离性,就可以简化在业务开发时的逻辑。这也是 InnoDB 引擎备受青睐的原因之一。
15 | 答疑文章(一):日志和索引相关问题
这一章没有我记载,因为自己还有些不明白,抱歉。
MySQL实战45讲(10--15)-笔记的更多相关文章
- 《MySQL实战45讲》(1-7)笔记
<MySQL实战45讲>笔记 目录 <MySQL实战45讲>笔记 第一节: 基础架构:一条SQL查询语句是如何执行的? 连接器 查询缓存 分析器 优化器 执行器 第二节:日志系 ...
- 《MySQL实战45讲》(8-15)笔记
MySQL实战45讲 目录 MySQL实战45讲 第八节: 事务到底是隔离的还是不隔离的? 在MySQL里,有两个"视图"的概念: "快照"在MVCC里是怎么工 ...
- 《MySQL实战45讲》个人笔记-基础篇
拜读了林晓斌大佬的<MySQL实战45讲>,特意做个知识点总结,以便后期回忆. 01.基础架构:一条SQL查询语句是如何执行的? Server 层包括连接器.查询缓存.分析器.优化器.执行 ...
- 《MySQL实战45讲》学习笔记1——MySQL的基础架构
在<极客时间>订阅了<MySQL实战45讲>专栏,总觉得看完和没看一样
- 《MySQL实战45讲》学习笔记4——MySQL中InnoDB的索引
索引是在存储引擎层实现的,且在 MySQL 不同存储引擎中的实现也不同,本篇文章介绍的是 MySQL 的 InnoDB 的索引. 下文将以这张表为例开展. # 创建一个主键为 id 的表,表中有字段 ...
- 《MySQL实战45讲》学习笔记2——MySQL的日志系统
一.日志类型 逻辑日志:存储了逻辑SQL修改语句 物理日志:存储了数据被修改的值 二.binlog 1.定义 binlog 是 MySQL 的逻辑日志,也叫二进制日志.归档日志,由 MySQL Ser ...
- 《MySQL实战45讲》学习笔记3——InnoDB为什么采用B+树结构实现索引
索引的作用是提高查询效率,其实现方式有很多种,常见的索引模型有哈希表.有序列表.搜索树等. 哈希表 一种以key-value键值对的方式存储数据的结构,通过指定的key可以找到对应的value. 哈希 ...
- 深挖计算机基础:MySQL实战45讲学习笔记
参考极客时间专栏<MySQL实战45讲>学习笔记 一.基础篇(8讲) MySQL实战45讲学习笔记:第一讲 MySQL实战45讲学习笔记:第二讲 MySQL实战45讲学习笔记:第三讲 My ...
- Mysql实战45讲 04讲深入浅出索引(上)读书笔记 极客时间
极客时间 Mysql实战45讲 04讲深入浅出索引 极客时间(上)读书笔记 笔记体悟 1.索引的作用:提高数据查询效率2.常见索引模型:哈希表.有序数组.搜索树3.哈希表:键 - 值(key - v ...
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
随机推荐
- 深入刨析tomcat 之---第1篇,解决第1,2章bug 页面不显示内容Hello. Roses are red.
writedby 张艳涛, 第一个问题是不显示index.html网页 19年才开始学java的第二个月,就开始第一遍看这本书,我估计当初,做第一章的一个案例,自己写代码,和验证就得一天吧,当初就发现 ...
- DC-4 靶机渗透测试
DC-4 渗透测试 冲冲冲,努力学习 .掌握 hydra ,nc反弹shell 记住你要干嘛, 找地方上传shell(大多以后台登录为切入点,再反弹shell),shell提权到root 操作机:ka ...
- synchronized优化手段:锁膨胀、锁消除、锁粗化和自适应自旋锁...
synchronized 在 JDK 1.5 时性能是比较低的,然而在后续的版本中经过各种优化迭代,它的性能也得到了前所未有的提升,上一篇中我们谈到了锁膨胀对 synchronized 性能的提升,然 ...
- RHCSA_DAY07
echo $PATH 用户账号管理 用户账号的作用:用户账号可用来登录系统,可以实现访问控制 用户模板目录:/etc/skel/ [root@localhost ~]# ls -a /etc/skel ...
- Recuva ——天下第一的删除恢复应用
天下第一的删除恢复应用 下载地址 http://www.onlinedown.net/soft/66224.htm 实名diss那个垃圾 易得恢复 98一年,真是趁火打劫(跟个老鼠一样, ...
- sqli-labs lesson 26-27a
less 26: 因为本关在windows上运行可能会出现字符转义(apacche下空格无法转义)错误,所以在docker上搭建好sqli-labs 在win2003上远程登录sqli-labs 先执 ...
- swagger菜单分级
效果 实现 SwaggerAutoConfiguration里新增配置: package com.fxkj.common.config; import com.google.common.base.P ...
- 手把手教你AspNetCore WebApi:Swagger(Api文档)
前言 小明已经实现"待办事项"的增删改查,并美滋滋向负责前端的小红介绍Api接口,小红很忙,暂时没有时间听小明介绍,希望小明能给个Api文档.对于码农小明来说能不写文档就尽量不要写 ...
- ASP.NET Core教程:ASP.NET Core中使用Redis缓存
参考网址:https://www.cnblogs.com/dotnet261010/p/12033624.html 一.前言 我们这里以StackExchange.Redis为例,讲解如何在ASP.N ...
- C#多线程---Mutex类实现线程同步
一.例子 1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 ...