第10讲:Flink Side OutPut 分流
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
关注公众号:
大数据技术派,回复资料,领取1024G资料。
这一课时将介绍 Flink 中提供的一个很重要的功能:旁路分流器。
分流场景
我们在生产实践中经常会遇到这样的场景,需把输入源按照需要进行拆分,比如我期望把订单流按照金额大小进行拆分,或者把用户访问日志按照访问者的地理位置进行拆分等。面对这样的需求该如何操作呢?
分流的方法
通常来说针对不同的场景,有以下三种办法进行流的拆分。
Filter 分流
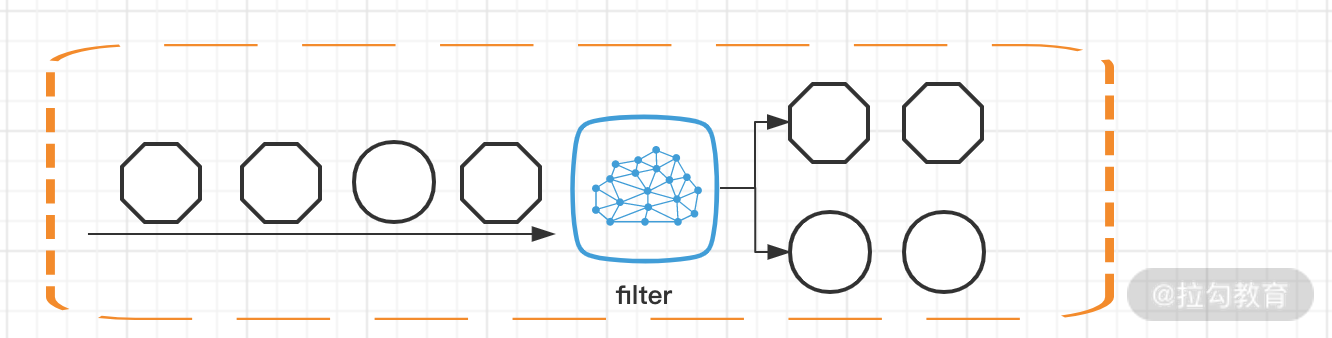
Filter 方法我们在第 04 课时中(Flink 常用的 DataSet 和 DataStream API)讲过,这个算子用来根据用户输入的条件进行过滤,每个元素都会被 filter() 函数处理,如果 filter() 函数返回 true 则保留,否则丢弃。那么用在分流的场景,我们可以做多次 filter,把我们需要的不同数据生成不同的流。
来看下面的例子:
复制代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> zeroStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == 0);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> oneStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == 1);
zeroStream.print();
oneStream.printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
在上面的例子中我们使用 filter 算子将原始流进行了拆分,输入数据第一个元素为 0 的数据和第一个元素为 1 的数据分别被写入到了 zeroStream 和 oneStream 中,然后把两个流进行了打印。
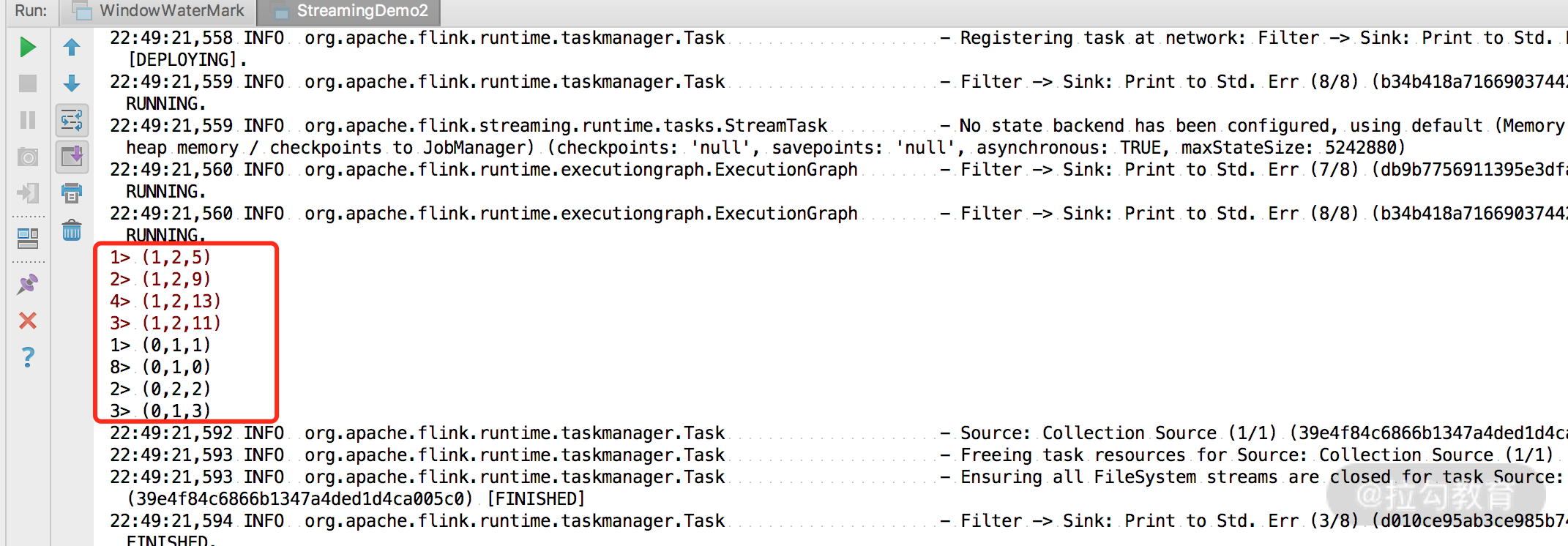
可以看到 zeroStream 和 oneStream 分别被打印出来。
Filter 的弊端是显而易见的,为了得到我们需要的流数据,需要多次遍历原始流,这样无形中浪费了我们集群的资源。
Split 分流
Split 也是 Flink 提供给我们将流进行切分的方法,需要在 split 算子中定义 OutputSelector,然后重写其中的 select 方法,将不同类型的数据进行标记,最后对返回的 SplitStream 使用 select 方法将对应的数据选择出来。
我们来看下面的例子:
复制代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SplitStream<Tuple3<Integer, Integer, Integer>> splitStream = items.split(new OutputSelector<Tuple3<Integer, Integer, Integer>>() {
@Override
public Iterable<String> select(Tuple3<Integer, Integer, Integer> value) {
List<String> tags = new ArrayList<>();
if (value.f0 == 0) {
tags.add("zeroStream");
} else if (value.f0 == 1) {
tags.add("oneStream");
}
return tags;
}
});
splitStream.select("zeroStream").print();
splitStream.select("oneStream").printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
同样,我们把来源的数据使用 split 算子进行了切分,并且打印出结果。

但是要注意,使用 split 算子切分过的流,是不能进行二次切分的,假如把上述切分出来的 zeroStream 和 oneStream 流再次调用 split 切分,控制台会抛出以下异常。
复制代码
Exception in thread "main" java.lang.IllegalStateException: Consecutive multiple splits are not supported. Splits are deprecated. Please use side-outputs.
这是什么原因呢?我们在源码中可以看到注释,该方式已经废弃并且建议使用最新的 SideOutPut 进行分流操作。
SideOutPut 分流
SideOutPut 是 Flink 框架为我们提供的最新的也是最为推荐的分流方法,在使用 SideOutPut 时,需要按照以下步骤进行:
- 定义 OutputTag
- 调用特定函数进行数据拆分
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
在这里我们使用 ProcessFunction 来讲解如何使用 SideOutPut:
复制代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
OutputTag<Tuple3<Integer,Integer,Integer>> zeroStream = new OutputTag<Tuple3<Integer,Integer,Integer>>("zeroStream") {};
OutputTag<Tuple3<Integer,Integer,Integer>> oneStream = new OutputTag<Tuple3<Integer,Integer,Integer>>("oneStream") {};
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> processStream= items.process(new ProcessFunction<Tuple3<Integer, Integer, Integer>, Tuple3<Integer, Integer, Integer>>() {
@Override
public void processElement(Tuple3<Integer, Integer, Integer> value, Context ctx, Collector<Tuple3<Integer, Integer, Integer>> out) throws Exception {
if (value.f0 == 0) {
ctx.output(zeroStream, value);
} else if (value.f0 == 1) {
ctx.output(oneStream, value);
}
}
});
DataStream<Tuple3<Integer, Integer, Integer>> zeroSideOutput = processStream.getSideOutput(zeroStream);
DataStream<Tuple3<Integer, Integer, Integer>> oneSideOutput = processStream.getSideOutput(oneStream);
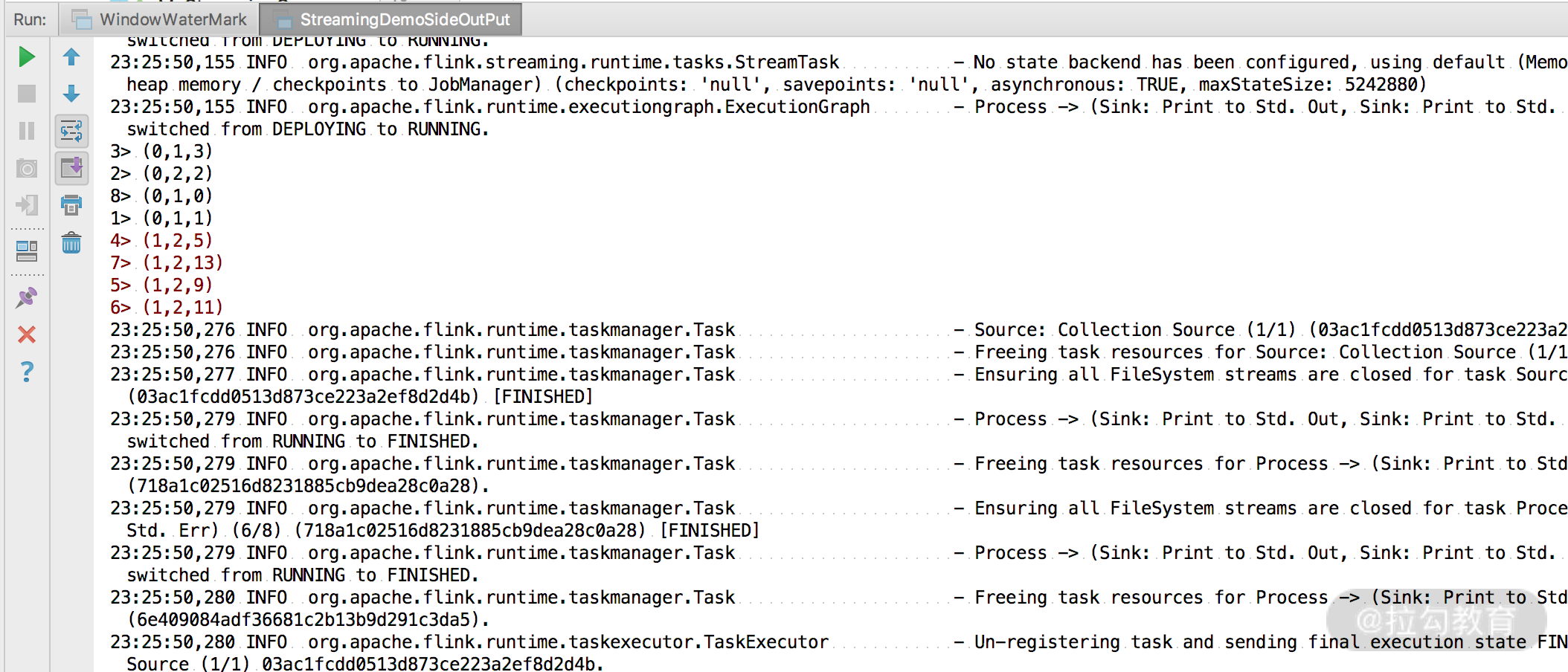
zeroSideOutput.print();
oneSideOutput.printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
可以看到,我们将流进行了拆分,并且成功打印出了结果。这里要注意,Flink 最新提供的 SideOutPut 方式拆分流是可以多次进行拆分的,无需担心会爆出异常。
总结
这一课时我们讲解了 Flink 的一个小的知识点,是我们生产实践中经常遇到的场景,Flink 在最新的版本中也推荐我们使用 SideOutPut 进行流的拆分。
关注公众号:
大数据技术派,回复资料,领取1024G资料。
第10讲:Flink Side OutPut 分流的更多相关文章
- [ionic开源项目教程] - 第10讲 新闻详情页的用户体验优化
目录 [ionic开源项目教程] 第1讲 前言,技术储备,环境搭建,常用命令 [ionic开源项目教程] 第2讲 新建项目,架构页面,配置app.js和controllers.js [ionic开源项 ...
- 第10讲- UI线程阻塞及其优化
第10讲UI线程阻塞及其优化 .UI 阻塞demo (首先在activity_main.xml中放置两个button,分别命名为button1,button2) //首先设置一个button1用来进行 ...
- JVM基础系列第10讲:垃圾回收的几种类型
我们经常会听到许多垃圾回收的术语,例如:Minor GC.Major GC.Young GC.Old GC.Full GC.Stop-The-World 等.但这些 GC 术语到底指的是什么,它们之间 ...
- 第10讲-Java集合框架
第10讲 Java集合框架 1.知识点 1.1.课程回顾 1.2.本章重点 1.2.1 List 1.2.2 Set 1.2.3 Map 2.具体内容 2.1.Java集合框架 2.1.1 为什么需要 ...
- [VirtualBox] Install Ubuntu 14.10 error 5 Input/output error
After you download the VirtualBox install package and install it (just defualt setting). Then you sh ...
- PHP学习之[第10讲]PHP 的 Mysql 数据库函数 (微型博客系统)II
mysql结构如下: -- phpMyAdmin SQL Dump -- version 4.4.1.1 -- http://www.phpmyadmin.net -- -- Host: localh ...
- 《Tsinghua oc mooc》第8~10讲 虚拟内存管理
资源 OS2018Spring课程资料首页 uCore OS在线实验指导书 ucore实验基准源代码 MOOC OS习题集 OS课堂练习 Piazza问答平台 暂时无法注册 第八讲 虚拟内存概念 为什 ...
- flink系列-10、flink保证数据的一致性
本文摘自书籍<Flink基础教程> 一.一致性的三种级别 当在分布式系统中引入状态时,自然也引入了一致性问题.一致性实际上是“正确性级别”的另一种说法,即在成功处理故障并恢复之后得到的结果 ...
- 第10讲:利用SQL语言实现关系代数操作
一.实现并.交.差运算 1. 基本语法形式:子查询 [union [all] | intersect [all] | except [all] 子查询] ①意义:将关系代数中的∪.∩.- 分别用uni ...
随机推荐
- Hadoop开启Kerberos安全模式
Hadoop开启Kerberos安全模式, 基于已经安装好的Hadoop的2.7.1环境, 在此基础上开启Kerberos安全模式. 1.安装规划 已经安装好Hadoop的环境 10.43.159.7 ...
- Swoole 协程使用示例及协程优先级
示例一: Co::set(['hook_flags'=> SWOOLE_HOOK_ALL]); Co\run(function () { go(function() { var_dump(fil ...
- Oracle打怪升级之路二【视图、序列、游标、索引、存储过程、触发器】
前言 在之前 <Oracle打怪升级之路一>中我们主要介绍了Oracle的基础和Oracle常用查询及函数,这篇文章作为补充,主要介绍Oracle的对象,视图.序列.同义词.索引等,以及P ...
- APP自动化测试之手机滑屏
相信大家在安装一个APP之后,进入之前会有几个页面组成的滑屏欢迎页面,要对这个APP进行自动化测试之前,就需要实现自动滑屏,怎么实现呢?请继续往下看 滑屏分 左滑和右滑,上滑.下滑 实现的原理(左滑) ...
- python 单下划线与双下划线的区别
来自为知笔记(Wiz)
- Python 元类实现ORM
ORM概念 ORM(Object Ralational Mapping,对象关系映射)用来把对象模型表示的对象映射到基于 SQL 的关系模型数据库结构中去.这样,我们在具体的操作实体对象的时候,就不 ...
- WebLogic任意文件上传漏洞(CVE-2019-2725)
一,漏洞介绍 1.1漏洞简介 Oracle weblogic反序列化远程命令执行漏洞,是根据weblogic的xmldecoder反序列化漏洞,只是通过构造巧妙的利用链可以对Oracle官方历年来针对 ...
- Flowable实战(六)集成JPA
上文提到,Flowable所有的表单数据都保存在一张表(act_hi_varinst)中,随着时间的推移,表中数据越来越多,再加上数据没有结构优化,查询使用效率会越来越低. 在Flowable ...
- MicroPython 8266 配置
MicroPython 8266 配置 刷固件 下载固件 MicroPython - Python for microcontrollers 从以上网址下载固件,本文下载的是esp8266-20210 ...
- IPOPT安装
1.安装工具coinbrew 打开网页,找到以下网址 将网站中的内容全部复制到自己创建的coinbrew文件中,并且赋予权限 chmod u+x coinbrew 或者执行 git clone htt ...