centos 6.4-linux环境配置,安装hadoop-1.1.2(hadoop伪分布环境配置)
1 Hadoop环境搭建
hadoop 的6个核心配置文件的作用:
- core-site.xml:核心配置文件,主要定义了我们文件访问的格式hdfs://。
- hadoop-env.sh:主要配置我们的java路径。
- hdfs-site.xml:主要定义配置我们的hdfs的相关配置。
- mapred-site.xml:主要定义我们的mapreduce相关的一些配置。
- slaves:控制我们的从节点在哪里,datanode nodemanager在哪些机器上。
- yarn-site.xml:配置我们的resourcemanager资源调度。
2 Hadoop部署方式:本地模式、伪分布模式、集群模式
- 安装前准备工作:virtualbox、jdk、hadoop-1.1.2.tar.gz
- 本文主要是通过伪分布模式进行安装,伪分布模式安装步骤:关闭防火墙、修改ip、修改hostname、设置SSH自动登录、安装jdk、安装hadoop
2.1 Hadoop伪分布具体安装步骤
——前提条件:【使用root用户登录】
A.设置静态ip
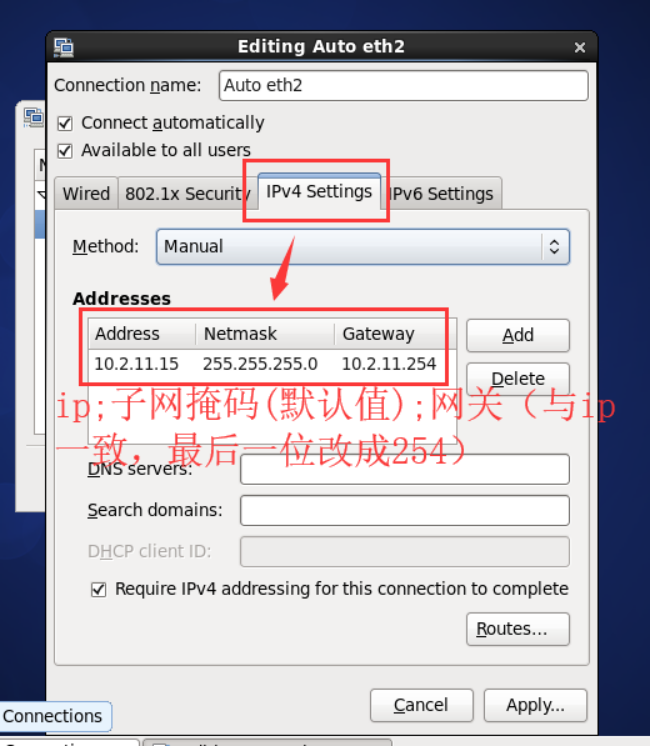
在centos桌面右上角的图标上,右键修改,或者执行命令 vi /etc/sysconfig/network-scripts/ifcfg-eth2
重启网卡 执行命令service network restart
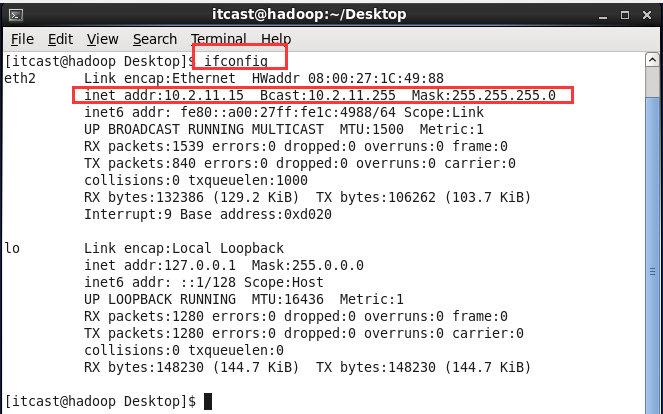
验证:执行命令ifconfig
B.修改主机名
步骤(1)和(2)最好操作步骤二
(1)修改当前会话中的主机名,执行命令 vi /etc/sysconfig/network
(2) 修改配置文件中的主机名,执行命令vi /etc/hosts
验证:重启机器 reboot -h now

C.把hostname和ip绑定
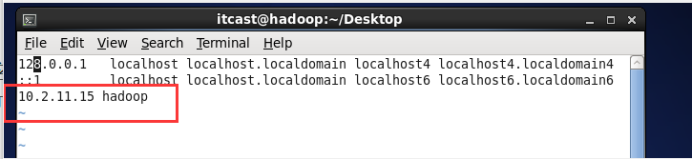
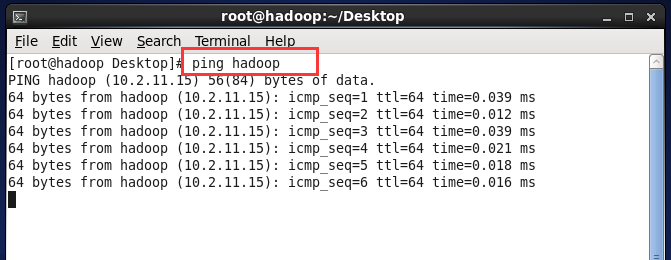
执行命令vi /etc/hosts,增加一行内容,如下:10.2.11.15 hadoop 保持退出
验证ping hadoop

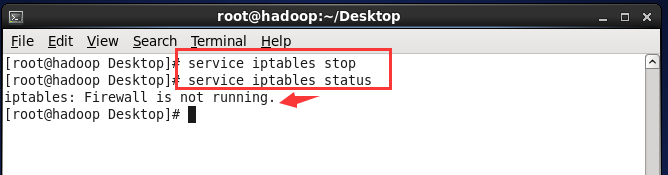
D.关闭防火墙
执行命令 service iptables stop
验证:service iptables status
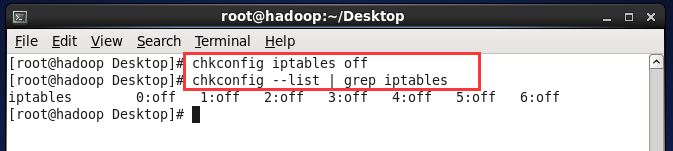
E.关闭防火墙的自动运行
执行命令 chkconfig iptables off
验证:chkconfig --list | grep iptables
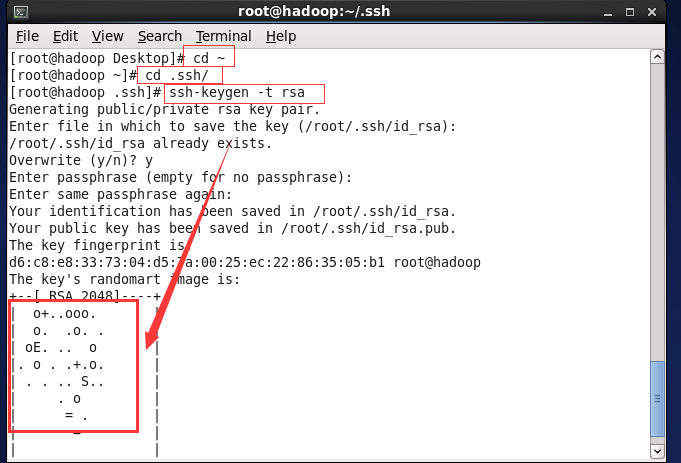
F.SSH(secure shell)的免密登录
存放在cd下的ssh目录下(cd ~ cd .ssh/)
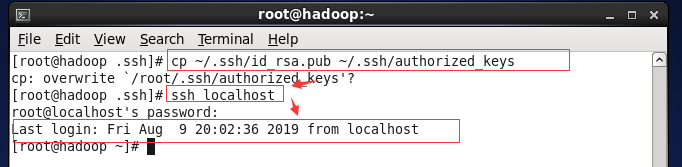
(1) 执行命令 ssh-keygen -t rsa 产生秘钥,位于~/ .ssh 文件夹
(2) 执行命令 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
验证:ssh localhost
G.安装jdk
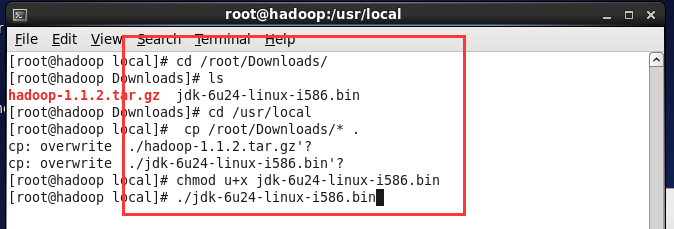
(1) 执行命令rm -rf /usr/local/* 删除所有内容

(2)使用winscp把jdk、hadoop文件从windows复制到/usr/downloads目录下

(3)执行命令 chmod u+x jdk-6u24-linux-i586.bin 赋予执行
(4)执行命令./jdk-6u24-linux-i586.bin 解压缩
(5)执行命令mv jdk1.6.0_24 jdk 重命名

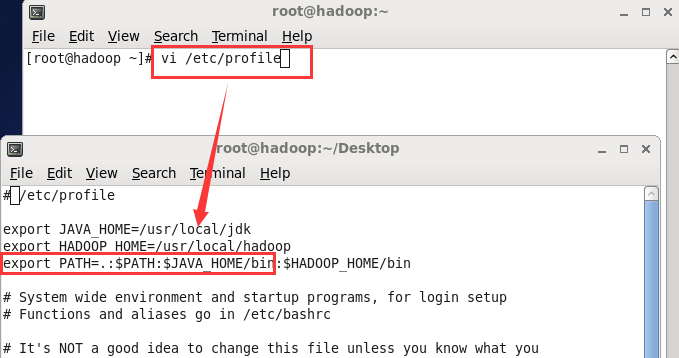
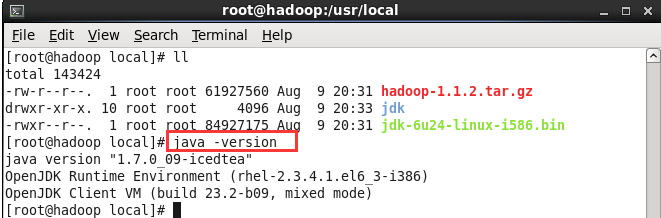
(6)执行命令vi /etc/profile 设置环境变量,增加2行内容
Export JAVA_HOME=/usr/local/jdk
Export PATH=.:$PATH:JAVA_HOME/bin
保持退出
执行命令立即生效 source /etc/profile

H.安装hadoop
(1) 执行命令 tar -zxvf hadoop-1.1.2.tar
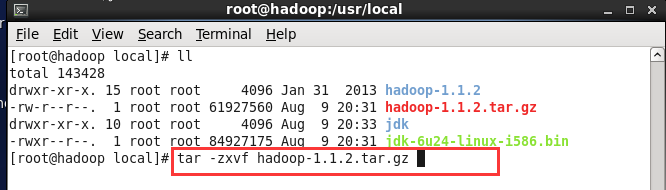
(2) 执行命令 mv hadoop-1.1.2 hadoop重命名
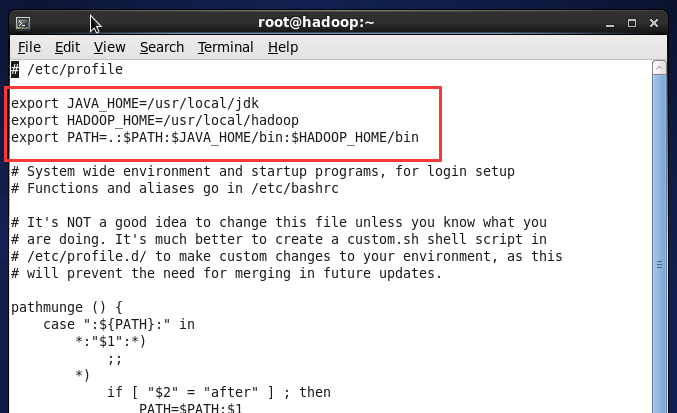
(3) 执行命令 vi /etc/profile 设置环境变量,增加了一行内:
export HADOOP_HOME=/usr/local/hadoop
修改一行内容:
Export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
保持退出
执行命令 source /etc/profile 让该设置立即生效

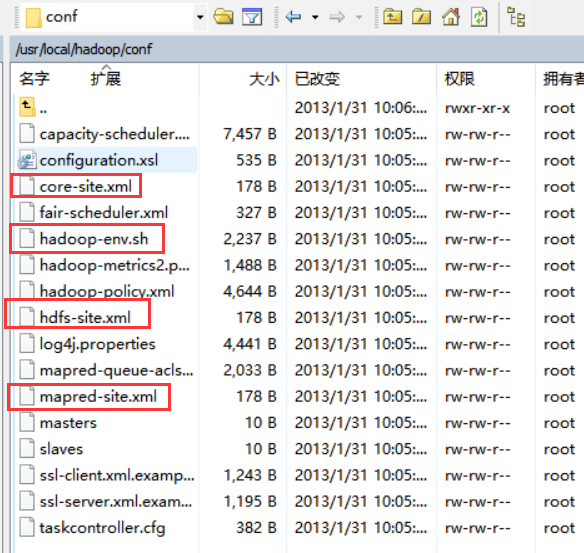
(4) 执行hadoop的配置文件,位于$HADOOP_HOME/conf目录下,修改配置文件hadoop-env.sh,core-site.xml,hdfs-site.xml、mapred-site.xml.
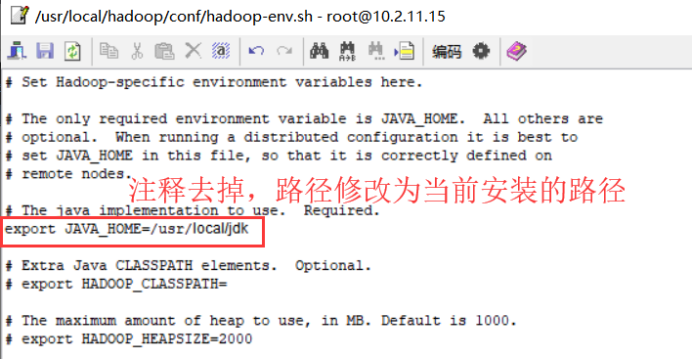
export JAVA_HOME=/usr/local/jdk
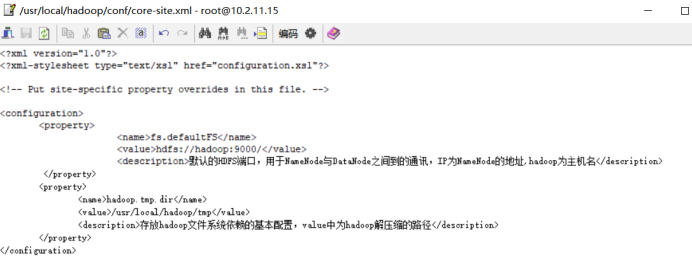
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000/</value>
<description>默认的HDFS端口,用于NameNode与DataNode之间到的通讯,IP为NameNode的地址,hadoop为主机名</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>存放hadoop文件系统依赖的基本配置,value中为hadoop解压缩的路径</description>
</property>
</configuration>
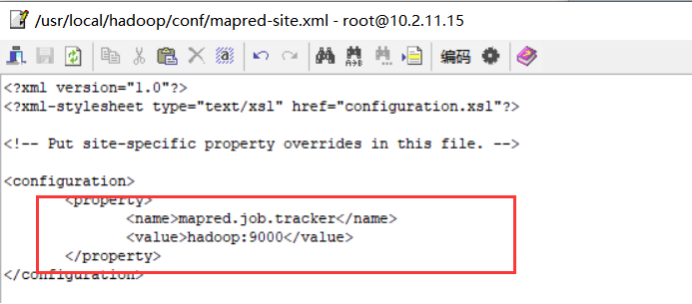
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9000</value>
</property>
</configuration>
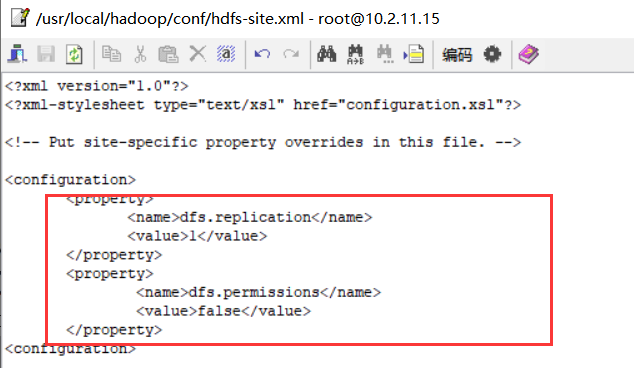
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<configuration>
(5) 执行命令 hadoop namenode -format 对hadoop进行格式化
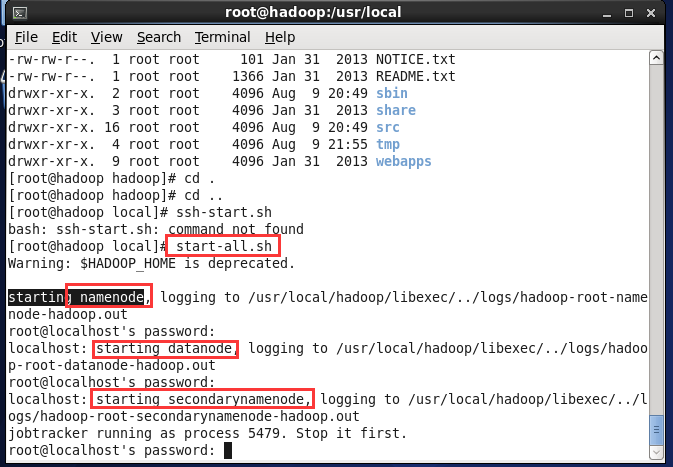
(6) 执行命令 start-all.sh 启动
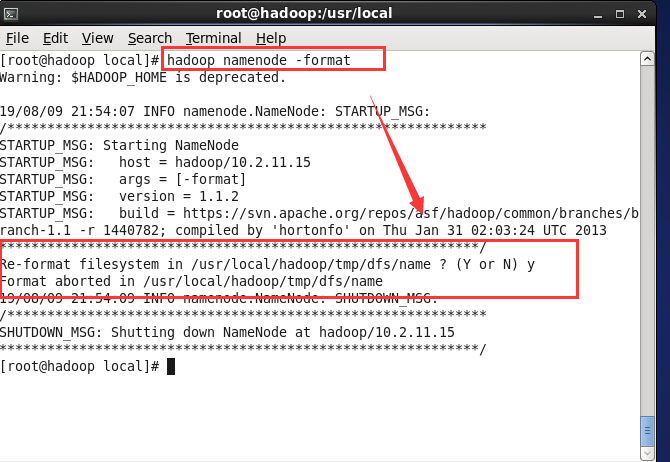
验证:
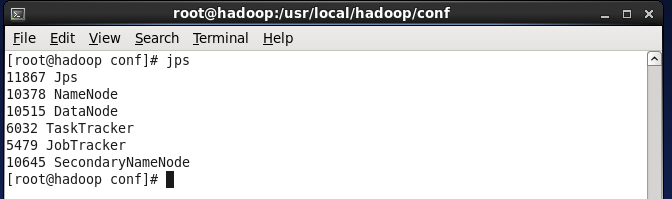
(1) 执行命令jps,发现5个java进程,分别是NameNode , DataNode , SecondaryNameNode, JobTracker, TaskTracker。
(2) 通过浏览器执行
NameNode:http://hadoop:50030
jobtracker:http://hadoop:50070
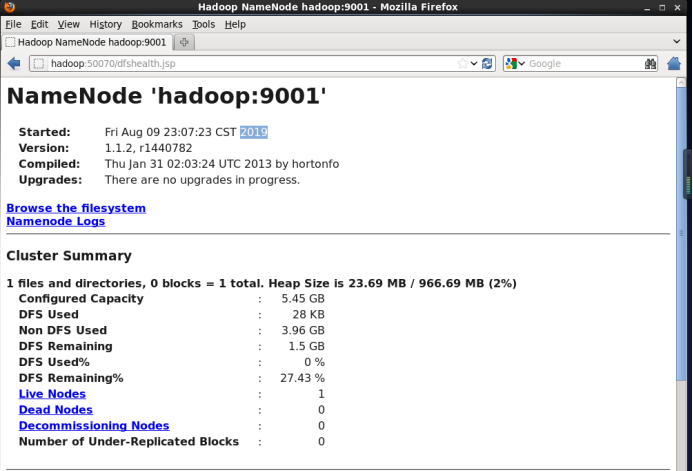
PS:9000和9001 不知道为什么,配置文件的时候这么修改,就能正常配置hadoop
疑问
1、为什么要配置静态IP?
在实际应用中,默认我们使用的是DHCP(动态主机分配协议)来分配地址的,那么ip地址有可能是会变动的。
而我们用Linux来搭建集群学习Hadoop的话,是希望IP固定不变的, 那么这个时候就需要我们配置静态IP。
2、配置ip,可以参考如下博文
https://baijiahao.baidu.com/s?id=1618628054855105015&wfr=spider&for=pc
3.修改root密码,可以参考如下博文
https://www.cnblogs.com/wenrulaogou/p/9409251.html
执行命令:passwd root 修改完成后ctrl+d 进行重启
4.网络采用桥接方式(桥接的网络选择对应实际网络)

centos 6.4-linux环境配置,安装hadoop-1.1.2(hadoop伪分布环境配置)的更多相关文章
- Hadoop之伪分布环境搭建
搭建伪分布环境 上传hadoop2.7.0编译后的包并解压到/zzy目录下 mkdir /zzy 解压 tar -zxvf hadoop.2.7.0.tar.gz -C /zzy 配置hado ...
- (一)Hadoop1.2.1安装——单节点方式和单机伪分布方式
Hadoop1.2.1安装——单节点方式和单机伪分布方式 一. 需求部分 在Linux上安装Hadoop之前,需要先安装两个程序: 1)JDK 1.6(或更高版本).Hadoop是用Java编写的 ...
- 在CentOS/RHEL/Scientific Linux 6下安装 LAMP
LAMP 是服务器系统中开源软件的一个完美组合.它是 Linux .Apache HTTP 服务器.MySQL 数据库.PHP(或者 Perl.Python)的第一个字母的缩写代码.对于很多系统管理员 ...
- CentOS 6.4 linux下编译安装MySQL5.6.14
CentOS 6.4下通过yum安装的MySQL是5.1版的,比较老,所以就想通过源代码安装高版本的5.6.14. 正文: 一:卸载旧版本 使用下面的命令检查是否安装有MySQL Server rpm ...
- Hadoop.2.x_伪分布环境搭建
一. 基本环境搭建 1. 设置主机名.静态IP/DNS.主机映射.windows主机映射(方便ssh访问与IP修改)等 设置主机名: vi /etc/sysconfig/network # 重启系统生 ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- hadoop: hbase1.0.1.1 伪分布安装
环境:hadoop 2.6.0 + hbase 1.0.1.1 + mac OS X yosemite 10.10.3 安装步骤: 一.下载解压 到官网 http://hbase.apache.org ...
- hadoop伪分布环境快速搭建
1.首先下载一个完成已经进行简单配置好的镜像文件(hadoop,HBASE,eclipse,jdk环境已经搭建好,tomcat为7.0版本,建议更改为tomcat8.5版本,运行比较稳定). 2安装V ...
- 启动原生Hadoop集群或伪分布环境
一:启动Hadoop 集群或伪分布安装成功之后,通过执行./sbin/start-all.sh启动Hadoop环境 通过jps命令查看当前启动进程是否正确~ [root@neusoft-master ...
随机推荐
- scjp卡壳题
1. void looper() { int x = 0; one: while (x < 10) { two: System.out.println(++x); if (x > 3) { ...
- tcp/udp注意事项
- TCP/IP模型简介和/etc/hosts文件说明
软件=协议的实现. IP决定了主机的位置.端口号决定了进程的位置. 两台主机上的通讯实际是两台主机上两个具体进程的通讯. TCP/IP模型分四层: TCP/IP模型:应用层---传输层----网络层- ...
- SpringBoot第十一集:整合Swagger3.0与RESTful接口整合返回值(2020最新最易懂)
SpringBoot第十一集:整合Swagger3.0与RESTful接口整合返回值(2020最新最易懂) 一,整合Swagger3.0 随着Spring Boot.Spring Cloud等微服务的 ...
- 预估ceph的迁移数据量
引言 我们在进行 ceph 的 osd 的增加和减少的维护的时候,会碰到迁移数据,但是我们平时会怎么去回答关于迁移数据量的问题,一般来说,都是说很多,或者说根据环境来看,有没有精确的一个说法,到底要迁 ...
- docker搭建渗透环境并进行渗透测试
目录 docker简介 docker的安装 docker.centos7.windows10(博主宿主机系统)之间相互通信 -docker容器中下载weblogic12c(可以略过不看) docker ...
- 这次齐了!Java面向对象、类的定义、对象的使用,全部帮你搞定
概述 Java语言是一种面向对象的程序设计语言,而面向对象思想是一种程序设计思想,我们在面向对象思想的指引下, 使用Java语言去设计.开发计算机程序. 这里的对象泛指现实中一切事物,每种事物都具备自 ...
- HBase高级特性、rowkey设计以及热点问题处理
在阐述HBase高级特性和热点问题处理前,首先回顾一下HBase的特点:分布式.列存储.支持实时读写.存储的数据类型都是字节数组byte[],主要用来处理结构化和半结构化数据,底层数据存储基于hdfs ...
- java工作两年了,连myBatis中的插件机制都玩不懂,那你工作危险了!
插件的配置与使用 在mybatis-config.xml配置文件中配置plugin结点,比如配置一个自定义的日志插件LogInterceptor和一个开源的分页插件PageInterceptor: & ...
- Linux root目录空间过小,加大空间
1. 查看还有多少空间可以使用: df -h 这里可以看出来home的空间还很大,可以分配给root 2. 扩容根目录的思路如下: 将/home文件夹备份,删除/home文件系统所在的逻辑卷,增大/文 ...