x86-TSO : 适用于x86体系架构并发编程的内存模型
Abstract :
如今大数据,云计算,分布式系统等对算力要求高的方向如火如荼。提升计算机算力的一个低成本方法是增加CPU核心,而不是提高单个硬件工作效率。
这就要求软件开发者们能准确,熟悉地运用高级语言编写出能够充分利用多核心CPU的软件,同时程序在高并发环境下要准确无误地工作,尤其是在商用环境下。
但是做为软件工程师,实际上不太可能花大量的时间精力去研究CPU硬件上的同步工作机制。
退而求其次的方法是总结出一套比较通用的内存模型,并且运用到并发编程中去。
本文结合对CPU的黑盒测试,介绍一个能够通用于 x86 系列CPU的并发编程的内存模型。
此内存模型 被测试在 AMD 与 x86 系列CPU上具有可行性,正确性。
本文章节:
1.关于各型号CPU的说明书规定或模型规定
2.官方发布的黑盒测试及它们可复现/不可复现的CPU型号
3.指令重排的发生
4.根据黑盒测试定义抽象内存模型 x86-TSO
5.A Rigorous and Usable Programmer’s Model for x86 Multiprocessors 的发布团队在AMD/Intel系列CPU上进行的一系列黑盒测试及它们与x86-TSO模型结构的关系
6.扩展
6.1 通过Hotspot源码分析 java volatile 关键字的语意及其与x86-TSO/普通TSO内存模型的关系
6.2 Linux内存屏障宏定义 与 x86-TSO 模型的关系
7.总结
8.参考文献
1.各个型号CPU的规定
CPU相关的模型或规定:
x86-CC 模型(出自 The semantics of x86-CC multiprocessor machine code. In Proc. POPL 2009, Jan. 2009)
IWP (Intel White Paper,英特尔在2007年8月发布的一篇CPU模型准则,内容给出了P1~P8共8条规则,并且用10个在CPU上的黑盒测试
来支持这8条规则)
Intel SDM (继承IWP的Intel 模型)
AMD3.14 说明手册对CPU的规定
2.官方黑盒测试
下面的可在...观察到,不可在...观察到,都是针对 最后的 State 而言,亦即 Proc 0: EAX = 0 ^ ... 语句表示的最终状态
其中倒着的V是且的意思
以下提到的StoreBuffer即CPU核心暂时缓存写入操作的物理部件,StoreBuffer中的写入操作会在任意时刻被刷入共享存储(主存/缓存),前提是总线没被锁/缓存行没被锁
以下提到的Store Fowarding 指的是CPU核心在读取内存单元时 会去 StoreBuffer中寻找该变量,如果找到了就读取,以便得到该内存单元在本核心上最新的版本
1.测试SB : 可在现代Intel CPU 和 AMD x86 中观察到
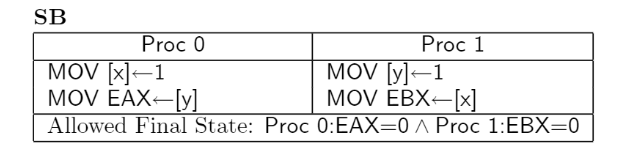
核心0 和 核心1 各有自己的Store Buffer,会造成上述情况。
核心0将 x = 1 缓存在自己的StoreBuffer里,并且从共享内存中获取 y = 0,之所以见不到 y = 1 是因为 核心1 将 y = 1 的操作缓存在自己的StoreBuffer里
核心1将 y = 1 缓存在自己的StoreBuffer里,并且从共享内存中获取 x = 0,无法见到 x = 1 与上述同理
2.测试IRIW : 实际上不允许在任何CPU上观察到,但是有的CPU模型的描述可能让该测试发生
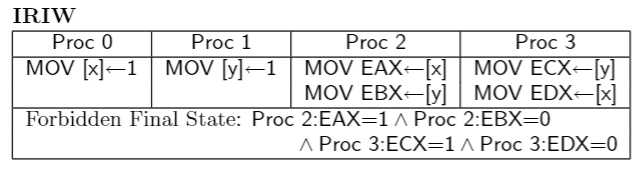
如果 核心0 和 核心2 共享 StoreBuffer,因为读取时会先去 StoreBuffer 读取修改,所以 核心0 执行的 x = 1 会被 CPU2 读取,故 EAX = 1 , 因为核心1 和 核心2 不共享StoreBuffer,核心1 的 y = 1 操作缓存在自己和核心3的共享StoreBuffer中
所以 EBX = 0 , CPU3的寄存器状态同理
3.测试n6 : 在 Intel Core 2 上可以观察到,但却是被X86-CC模型和IWP说明禁止的

核心0 和 核心1 有各自的Store Buffer
核心0将 x = 1 缓存在自己的Store Buffer 中,并且根据 Store Forwarding 原则 , 核心0 读取 x 到 EAX 的时候
会读取自己的Store Buffer,读取x 的值是 1,故EAX = x = 1
同理,核心1也会缓存自己的写操作, 即缓存 y = 2 和 x = 2 到自己的 StoreBuffer,因此 y = 2 这个操作不会被
核心0 观察到,核心0 从主内存中加载 y 。故 EBX = y = 0
4.测试n5 / n4b :实际上不能在任何CPU上观察到
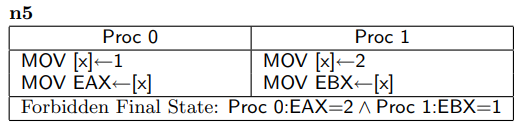
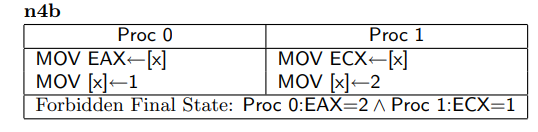
n5和n4b是同样类型的测试,假如 核心0和 核心1都有自己的StoreBuffer
对于n5,核心0的EAX如果等于2,那么说明 核心1的StoreBuffer刷入到 共享的主存中, 那么 EAX = x 必然=执行于 x = 2
之后,一位 x = 1 对 EAX = x 来说是有影响的,EAX = x 和 x = 1 禁止重排,那么 x = 1 必然不能出现在 x = 2 之前,
更不可能出现在 ECX = x 之前 (x = 2 对 ECX = x 也是有影响的,语义上严禁重排)
对于n4b,如果EAX = 2 ,说明 核心1的 x = 2 操作已经刷入主存被 核心0 观察到,那么对于 核心0来说 x = 2 先于 EAX = x 执行
同上理,ECX = x 和 x = 2 也是严禁重排的,故 ECX = x 要先于 EAX = x 执行,更先于 x = 1 执行
n5 和 n4b 测试在AMD3.14 和Intel SDM 中好像是可以被允许的,也就是上面的 Forbidden Final State 被许可,但实际上不能
A Rigorous and Usable Programmer’s Model for x86 Multiprocessors 中作者原话 : However, the principles stated in revisions 29–34 of the Intel SDM appear, presumably unintentionally, to allow them. The AMD3.14 Vol. 2, §7.2 text taken alone would allow them, but the implied coherence from elsewhere in the AMD manual would forbid them
实际上是概念模型如果从局部描述,没有办法说确切,但是从整体上看,整个模型的说明很多地方都禁止了n5和n4b的发生,可见想描述一个松散执行顺序的CPU模型是多么难的一件事。软件开发者也没办法花大量的时间精力去钻研硬件的结构组成和工作原理,只能依靠硬件厂商提供的概念模型去理解硬件的行为
在AMD3.15的模型说明中,语言清晰地禁止了IRIW,而不是模棱两可的否定。
以下表格总结了上述的黑盒测试在不同CPU模型中的观察结果(3.14 3.15是AMD不同版本的模型,29~34是Intel SDM在这个版本范围的模型)

3.指令重排的发生
上述的黑盒测试的解释中,提到了重排的概念,让我们看一下从软件层面的指令到硬件上,哪些地方可能出现 重排序:
CPU接收二进制指令流,流水线设计的CPU会依照流水线的方式串行地执行每条指令的各个阶段
举例描述:一个餐厅里 每个人的就餐需要三个阶段:盛饭,打汤,拿餐具。有三个员工,每人各负责一个阶段,显然每个员工只能同时处理一个客人,也就是同一时刻,同一阶段只能有一个客人,也就是任何时刻不可能出现两位客人同时打汤的情况,当然也不可能出现两个员工同时服务一个客人。能形成一条有条不紊的进餐流水线,不用等一个客人一口气完成3个阶段其他客人才能开始盛饭。
对于CPU也是,指令的执行分为 取指,译码,取操作数,写回内存 等阶段,每个阶段只能有一条指令在执行。
CPU应当有 取值工作模块,译码工作模块,等等模块来执行指令。每种模块同一时刻只能服务一条指令,对于CPU来说,流水线式地执行指令,是串行的,没有CPU聪明到给指令重排序一说,如果指令在CPU内部的执行顺序和高级语言的语义顺序不一样,那么很可能是编译器优化重排,导致CPU接受到的指令
本来就是编译器重排过的。
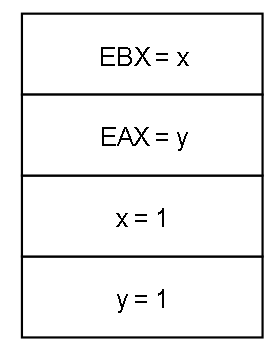
真正的指令重排出现在StoreBuffer的不可见上,缓存一致性已经保证了CPU间的缓存一致性。具体重拍的例子就是第一个黑盒测试SB:
初值:x = 0, y = 0

在我们常规的并发编程思维中,会为这4条语句排列组合(按我们的认知,1一定在2之前,3一定在4之前),并且认为无论线程怎么切换,这四条语句的排列组合(1在2前,3在4前的组合)一定有一条符合最后的实际运行结果。假如按照 1 3 2 4 这样的组合来执行,那么最后 EAX = 1 , EBX = 1,或者 1 2 3 4 这样的顺序来执行,最后 EAX = 0 且 EBX = 1,怎么都不可能 EAX = 0, EBX = 0
但实际上SB测试可以在Intel系列上观察到,从软件开发者的角度上看,就好像 按照 2 4 1 3 的顺序执行了一样,如同 2 被排在1 之前,3 被排在4 之前,是所谓 指令重排 的一种情况
实际上,是因为StoreBuffer的存在,才导致了上述的指令重排。
试想一下,CPU0将 x = 1 指令的执行缓存在了自己的StoreBuffer里,CPU1也把 y = 1 的执行缓存在自己的StoreBuffer里,这样的话当两者执行各自的读取操作的时候,亦即CPU0执行 EAX = y
CPU1执行 EBX = x , 都会直接去缓存或主存中读取,而缓存又MESI协议保证一致,但是不保证StoreBuffer一致,所以两者无法互相见到对方的StoreBuffer中对变量的修改,于是读到x, y都是初值 0
4.根据黑盒测试定义抽象内存模型 x86-TSO
从以上的试验无法总结出一套通用的内存模型,因为每个CPU的实现不同,但是我们可以总结出一个合理的关于x86的内存模型
并且这个模型适合软件开发者参考,并且符合CPU厂商的意图
首先是关于StoreBuffer的设计:
1.在Intel SDM 和 AMD3.15模型中,IRIW黑盒测试是明文禁止的,而IRIW测试意味着某些CPU可以共享StoreBuffer所以我们想创造的合理内存模型不能让CPU共享StoreBuffer
2.但是在上述黑盒测试中,比如n6和SB,都证明了,StoreBuffer确实存在
总结:StoreBuffer存在且每个CPU独占自己的StoreBuffer
上述的黑盒测试表明,除了StoreBuffer造成的CPU写不能马上被其他CPU观察到,各个CPU对主存的观察应该都是一致的,可以忽略掉缓存行,因为MESI协议会保证各个CPU的缓存行之间的一致性,但是无法保证StoreBuffer中的内容的一致性,因为MESI是缓存一致性协议,每个字母对应缓存(cache)的一种状态,保证的只是缓存行的一致性。
总结一下:我们想构造的x86模型的特点:
1. 在硬件上必然是有StoreBuffer存在的,设计时需要考虑进去
2. 缓存方面因为MESI协议,各个CPU的缓存之间不存在不一致问题,所以缓存和主存可以抽象为一个共享的内存
3. 额外的一个特点是 总线锁,x86提供了 lock 前缀 ,lock前缀可以修饰一些指令来达到 read-modify-write 原子性的效果,比如最常见的 read-modify-write 指令 ADD,CPU需要从内存中取出变量,
加一后再写回内存,lock前缀可以让当前CPU锁住总线,让其他CPU无法访问内存,从而保证要修改的变量不会在修改中途被其他CPU访问,从而达到原子性 ADD 的效果。在x86中还有其他的指令自带
lock 前缀的效果,比如XCHG指令。带锁缓存行的指令在锁释放的时候会把StoreBuffer刷入共享存储
最后可以得到如下模型:
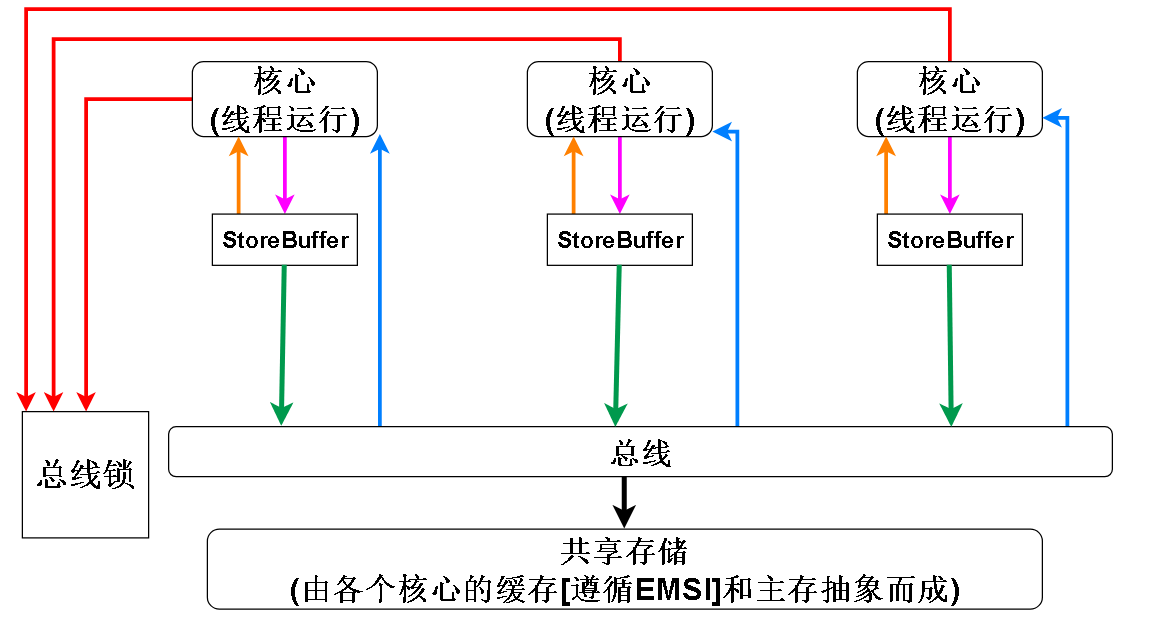
其中各颜色线段的含义:
红色:CPU的各个核心可以争夺总线锁,占有总线锁的CPU可以将自己的storeBuffer刷入到共享存储中(其实总线锁不是真的一定要锁总线,也可以锁缓存行,如果要锁的目标不只一个缓存行,则锁总线),占有期间其他CPU无法将自己的storeBuffer刷入共享存储
橙色:根据StoreFowarding原则,CPU核心读取内存单元时,首先去StoreBuffer读取最近的修改,并且x86的StoreBuffer是遵循FIFO的队列,x86不允许CPU直接修改缓存行,所以StoreStore内存屏障在x86上是空操作,因为对于一个核心来说,写操作都是FIFO的,写操作不会重排序。x86不允许直接修改缓存行也是缓存和主存能抽象成一体的原因。
紫色: 核心向StoreBuffer写入数据,在一些英文文献中会表示为:Buffered writes to 变量名,也就是对变量的写会被缓存在StoreBuffer,暂时不会被其他CPU观察到
绿色: CPU核心将缓存的写操作刷入共享存储,除了有其他核心占有锁的情况 (因为其他核心占有锁的话,锁住了缓存行或总线,则当前核心不能修改这个缓存行或访问共享存储),任何情况下,StoreBuffer都可以被刷入共享存储
蓝色:如果要读取的变量不在StoreBuffer中,则去共享存储读取(缓存或主存)
5.A Rigorous and Usable Programmer’s Model for x86 Multiprocessors 的发布团队在AMD/Intel系列CPU上进行的一系列黑盒测试及它们与x86-TSO模型结构的关系
在A Rigorous and Usable Programmer’s Model for x86 Multiprocessors 一文中,作者为了验证x86-TSO模型的正确性,在普遍流行的 AMD和 Intel 处理器上使用嵌入汇编的C程序进行测试。
并且使用memevents工具监视内存并且查看最终结果,并且用HOL4监控指令执行前后寄存器和内存的状态,最后进行验证,共进行了4600次试验。
结果如下:
1.写操作不允许重排序,无论是对其他核心来说还是自己来说

解释:
从核心1 的角度看 核心0,x 和 y 的写入顺序不能颠倒
从x86-TSO模型的物理构件角度解释就是,写操作会按照 FIFO 的规则 进入 StoreBuffer,并且按照FIFO的顺序刷入共享存储,所以 写操作无法重排序。
所以 x = 1 写操作先入StoreBuffer队列,接着 y = 1 入,刷入共享存储的时候, x = 1 先刷入,y = 1 再刷入, 所以如果 y 读到 1 的话,x 一定不能是 0
2.读操作不能延迟 :对于其他核心来说,对于自己来说如果不是同一个内存单元,是否重排无关紧要,(因为读不能通知写,只有写改变了某些状态才能通知读去做些什么, 比如 x = 1; if (x == 1); )

解释:
从核心1的角度观察,如果EBX = 1 , 那么说明 核心0的 y = 1 操作已经从 StoreBuffer中刷入到共享存储,之前说过,CPU流水线执行指令在物理上是不能对指令流进行重排的,所以 EAX = x 的操作 在 y = 1 之前执行
同理,EBX = y 这个读操作也不能延后到 x = 1 之后执行,所以 EAX = x 先于 y = 1 ,y = 1 先于 EBX = y , EBX = y 先于 x = 1 , 所以 EAX 不可能接受到 x = 1 的结果
3.读操作可以提前:上述2是读操作不能延后,但是可以提前,并且是从其他核心的角度观察到的
例子是 上面的 SB测试,
如果忽视StoreBuffer,从核心1的角度看,EBX = 0,说明 x = 1 未执行,那么 EBX = x 应该在 x = 1 之前执行,又因为 y = 1 在 EBX = x 之前,那么 y = 1 应该在 x = 1 之前,EAX = y 在 x = 1 之后,理应在 y = 1 之后
那么EAX 理应 = 1。

但是最后状态可以两者均为0.。就好像 读取的指令被重新排到前面(下面是一种重排情况)
在x86-TSO模型中,写操作是允许被提前的,从物理硬件的角度解释如下:
假设核心0是左边的核心,核心1是右边的核心,如果两者都把 写操作缓存在 StoreBuffer中,并且读操作执行之前,StoreBuffer没有同步回共享存储,那么两者读到的 x 和 y 都来自共享存储,并且都是 0。

4.对于单个核心来说,因为Store Forwarding 原则,同一个内存单元 之前的写操作必对之后的读操作可见
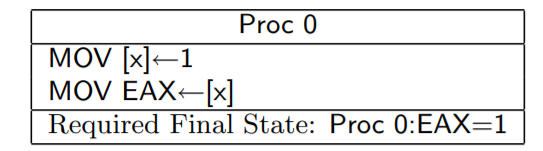
解释:对一个核心而言,自己的写入是能马上为自己所见的
5.写操作的可见性是传递的,这一点与 happens-before 原则的传递性类似,如果 A 能 看到 B 的动作,B能看到 C 的动作,那么 A一定能看到C 的动作

解释: 对于核心1,如果EAX = 1 ,那么说明核心1已经见到了 核心0的动作,对于核心2,EBX = 1,说明核心2已经见到了 核心1的动作,又根据之前的 读操作不能延后,EAX = x 不能延迟到 y = 1 之后,
所以 核心2 必能见到 核心0 的动作,所以 ECX = x 不能为 0
6.共享存储的状态对所有核心来说都是一致的
上面的IRIW测试就是违反共享内存一致性的例子:
核心2 和 核心3 观察到 核心0 和 核心1 的行为,那么他们的行为应该都是一样的,因为都刷入到共享存储中了
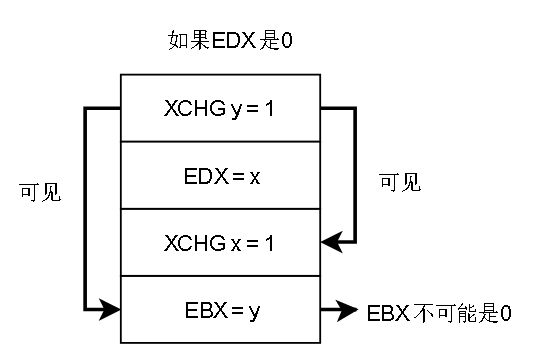
7.带lock前缀的指令或者 XCHG指令,会清空StoreBuffer,使得之前的写操作马上被其他核心观察到
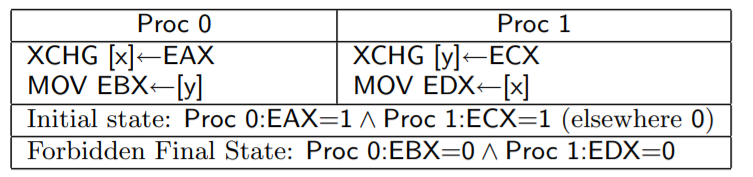
解释:EAX一开始是1,将EAX的值写入 x ,核心0 的 XCHD会把StoreBuffer清空,亦即将 x = EAX (1) 刷入共享存储,核心1如果看到 x = 0 (EDX = 0 ),说明 x = EAX 在后面才执行。推得y = ECX 在 x = EAX 之前执行
y = ECX 也会马上刷入共享存储,必然对 核心 0 可见,所以 最后不可能 x = 0, y = 0
MFENCE指令在x86-TSO模型上也能达到刷StoreBuffer的效果。
总结:在x86-TSO模型上,唯一可能重排序的清空是 读被提前了(从多个CPU的视角看),实际上是 StoreBuffer缓存了写操作,导致写操作没写出来。
6.扩展:
6.1 通过Hotspot源码分析 java volatile 关键字的语意及其与x86-TSO/普通TSO内存模型的关系
Java 的 volatile语意:Hotspot实现
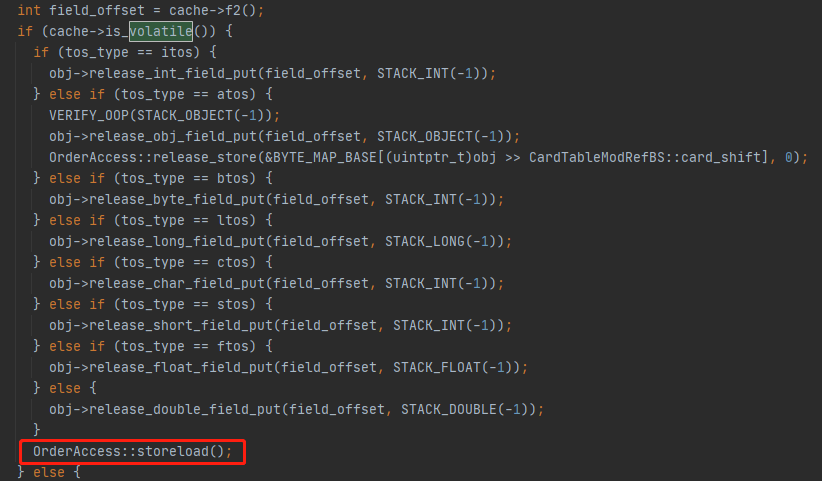
在JVM的字节码解释器中,如果putstatic字节码或putfield字节码的变量是java层面的volatile关键字修饰的,就会在指令执行的最后插入一道 storeLoad 屏障,前文已经说过,在x86中
唯一可能重排的是 读操作提前到 写操作之前,这里的storeLoad操作做的就是阻止重排

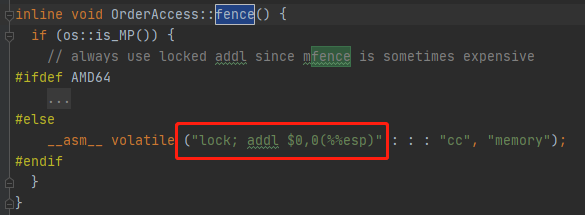
在os_cpu/linux_x86下的实现如下:
其实只是执行了一条带lock前缀的空操作嵌入汇编指令(栈顶指针+0是空操作),实现的效果就是把StoreBuffer中的内容刷入到 共享存储中
其实还有一层加强, __ asm __ 后面的volatile关键字 会阻止编译器对本条指令前后的指令重排序优化,这保证了CPU得到的指令流是符合我们程序的语意的
在模板解释器中:
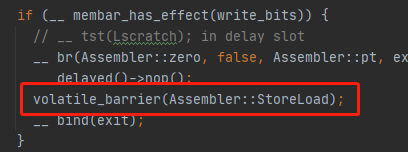

一开始我惊讶于此,这句话没有为不同平台实现选择不同的实现方法,而是简单检查如果不是需要 storeLoad 屏障就跳过。

其实作者注解已经说的很明白,现在大部分RISC的SPARC架构的CPU的实现都满足TSO模型,所以只需要StoreLoad屏障而已
我在新南威尔斯大学的网站上找到了关于TSO的比较正宗的解释:

下面的讨论中,是否需要重排序是根据CPU最后的行为是否符合我们高级语言程序的语意顺序决定的,如果相同则不需要,不相同则需要。
也就是单个核心中,写操作之间是顺序的,会按二进制指令流的写入顺序刷到共享存储,不需要考虑重排的情况,所以不需要StoreStore屏障
遵循Store Forwarding,所以对于本核心,本核心的写操作对后续的读操作可见。这三点已经十分符合本文的x86-TSO模型。
有一点没有呈现,就是单个CPU核心中,是否禁止读延迟,也就是写操作不能跨越到读操作之前,根据上面的 只有StoreLoad 屏障有操作,其他屏障,包括LoadStore屏障无操作可以推断
普通的TSO模型也是遵循禁止读延迟原则的
6.2 Linux内存屏障宏定义 与 x86-TSO 模型的关系
Linux 的内存屏障宏定义
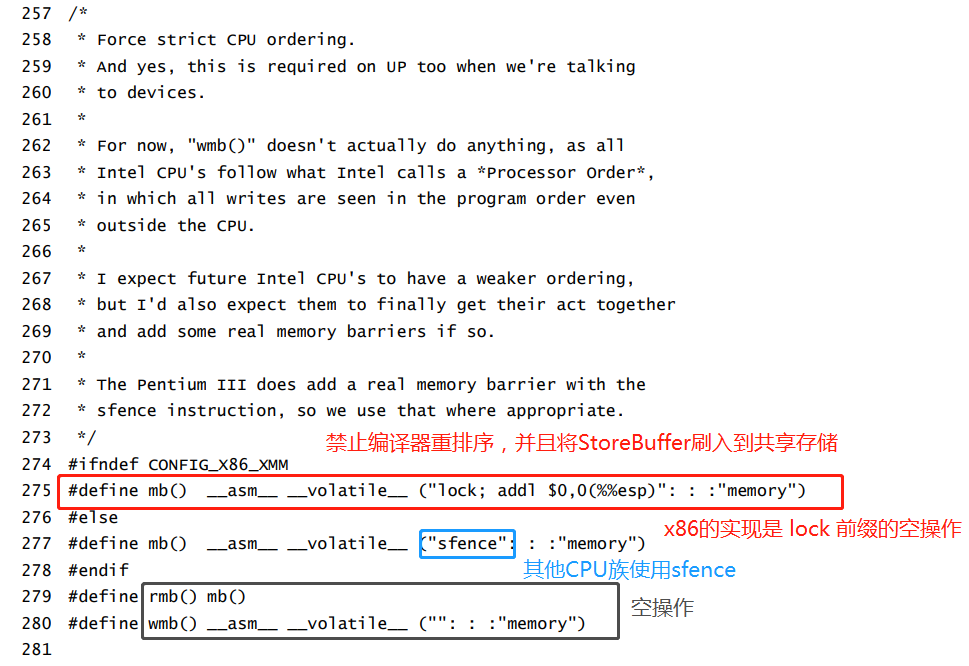
在Linux下定义的具有全功能的内存屏障,是有实际操作的,和JVM的storeLoad如出一辙
读屏障是空操作,写屏障只是简单的禁止编译器重排序,防止CPU接收的指令流被编译器重排序。
只要编译器能编译出符合我们高级语言程序语意顺序的二进制流给CPU,根据TSO模型的,CPU执行这些指令流的中的写操作对外部呈现出来的(刷入共享存储被所有CPU观察到)就是FIFO顺序
读操作不涉及任何状态变更,所以不需要内存屏障(也许只有在x86上才不需要,在其他有Invaild Queue的CPU结构中或许需要)
7.总结
本文总结:
x86-TSO模型的特点总结:
因为缓存有MESI协议保证一致性,所以缓存可以和主存合并抽象成共享存储
x86-TSO的写操作严格遵循FIFO
CPU流水线式地执行指令会使得CPU对接受到的指令流顺序执行
x86-TSO中唯一重排的地方在于StoreBuffer,因为StoreBuffer的存在,核心的写入操作被缓存,无法马上刷新到共享存储中被其他核心观察到,所以就有了 “ 写 ” 比 “读” 晚执行的直观感受,也可以说是读操作提前了,排到了写操作前
阻止这种重排的方法是 使用带 lock 前缀的指令或者XCHG指令,或MFENCE指令,将StoreBuffer中的内容刷入到共享存储,以便被其他核心观察到
8.本文参考文献
参考文献:
《Linux内核源代码情景分析》:毛德操
x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors
Memory Barriers: a Hardware View for Software Hackers
x86-TSO : 适用于x86体系架构并发编程的内存模型的更多相关文章
- Java并发编程-Java内存模型
JVM内存结构与Java内存模型经常会混淆在一起,本文将对Java内存模型进行详细说明,并解释Java内存模型在线程通信方面起到的作用. 我们常说的JVM内存模式指的是JVM的内存分区:而Java内存 ...
- 并发编程-Java内存模型
将之前看过的关于并发编程的东西总结记录一下,本文简单记录Java内存模型的相关知识. 1. 并发编程两个关键问题 并发编程中,需要处理两个关键问题:线程之间如何通信及线程之间如何同步. (1)在命令式 ...
- Java并发编程、内存模型与Volatile
http://www.importnew.com/24082.html volatile关键字 http://www.importnew.com/16142.html ConcurrentHash ...
- 【并发编程】- 内存模型(针对JSR-133内存模型)篇
并发编程模型 1.两个关键问题 1)线程之间如何通信 共享内存 程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信 消息传递 程之间没有公共状态,线程之间必须通过发送消息来显式进行通信 ...
- 并发编程 —— Java 内存模型总结图
关于 Java 内存模型的类似思维导图. 如有错误,还请指正.
- InnoDB体系架构(二)内存
InnoDB体系架构(二)内存 上篇文章 InnoDB体系架构(一)后台线程 介绍了MySQL InnoDB存储引擎后台线程:Master Thread.IO Thread.Purge Thread. ...
- 高效并发一 Java内存模型与Java线程(绝对干货)
高效并发一 Java内存模型与Java线程 本篇文章,首先了解虚拟机Java 内存模型的结构及操作,然后讲解原子性,可见性,有序性在 Java 内存模型中的体现,最后介绍先行发生原则的规则和使用. 在 ...
- 高并发第二弹:并发概念及内存模型(JMM)
高并发第二弹:并发概念及内存模型(JMM) 感谢 : 深入Java内存模型 http://www.importnew.com/10589.html, cpu缓存一致性 https://www.cnbl ...
- 【死磕Java并发】-----Java内存模型之重排序
在执行程序时,为了提供性能,处理器和编译器常常会对指令进行重排序,但是不能随意重排序,不是你想怎么排序就怎么排序,它需要满足以下两个条件: 在单线程环境下不能改变程序运行的结果: 存在数据依赖关系的不 ...
随机推荐
- unity探索者之微信分享回调
版权声明:本文为原创文章,转载请声明http://www.cnblogs.com/unityExplorer/p/7574561.html 上一遍讲了微信分享的一些坑,然后就忘了回调这事儿了,今天补上 ...
- web主题适配方案指北
前置知识 在这里了解实现网页主题切换的相关知识. CSS 变量 要实现主题切换需要了解一点 css 自定义属性.当然,本文还提供了其他实现方式,为了不给您接下来的阅读带来阻碍,先了解它. 变量的声明 ...
- WordCount of Software Engineering
1.Github项目地址:https://github.com/BayardM/WordCount 2.PSP表格(before): PSP2.1 Personal Software Process ...
- 可爱的python
可爱的python 作者: 哲思社区出版社: 电子工业出版社 优点 1. 案列讲解很详细,前几章的内容恰好是我想要了解的,例如利用python os模块读取磁盘的文件,或者获得文字的编码方式.这些内 ...
- muduo源码解析11-logger类
logger: class logger { }; 在说这个logger类之前,先看1个关键的内部类 Impl private: //logger内部数据实现类Impl,内部含有以下成员变量 //时间 ...
- 真是没想到 Springboot + Flowable 工作流开发会这么简单
本文收录在个人博客:www.chengxy-nds.top,技术资料共享,同进步 程序员是块砖,哪里需要哪里搬 公司内部的OA系统最近要升级改造,由于人手不够就把我借调过去了,但说真的我还没做过这方面 ...
- PyQt5+Caffe+Opencv搭建人脸识别登录界面
PyQt5+Caffe+Opencv搭建人脸识别登录界面(转载) 最近开始学习Qt,结合之前学习过的caffe一起搭建了一个人脸识别登录系统的程序,新手可能有理解不到位的情况,还请大家多多指教. 我的 ...
- 基于postman的api自动化测试实践
测试的好处 每个人都同意测试很重要,但并不是所有人都会去做.每当你添加新的代码,测试可以保证你的api按照预期运行.通过postman,你可以为所有api编写和运行测试脚本. postman中的测试 ...
- 【亲测】手把手教你如何破解pycharm(附安装包和破解文件)
此教程支持最新的2019.3版本的Pycharm,并兼容之前的版本. 一.准备工作: 1.下载Pycharm 有条件的可以自行去官网下载,这里我提供了我下载的版本,已上传到百度网盘,链接在下方. 2. ...
- Python超级码力在线编程大赛初赛题解
P1 三角魔法 描述小栖必须在一个三角形中才能施展魔法,现在他知道自己的坐标和三个点的坐标,他想知道他能否施展魔法 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后, ...