使用Loadrunner进行性能测试
一、确定性能测试的范围、要求、配置、工具等
- 明确测试的系统:
本文档主要指的是web应用。
- 明确测试要求:
用户提出性能测试,例如,网站首页页面响应时间在3S之内,主要的业务操作时间小于10s,支持300用户在线操作等相关语言描述。主要指标涉及到到并发量,响应时间,TPS,服务器CPU、内存使用占比等
- 明确服务器配置:
web服务器,数据库服务器,包括内存、CPU等,同时对于数据库版本、中间件版本都需要明确好
- 明确测试工具和环境:
确定压力测试工具,服务器的监控工具等(本次使用的是loadrunner作为负载软件,nmon作为服务器监控工具)
二、确定测试的方式,业务占比
根据系统的实际业务场景,来测定测试的方式,可以多选。
- 压力测试
选择场景做一次性并发,观察那个时间点的连接处和TPS结合来判断系统所能承受的最大压力场景。
- 容量测试
采用阶梯式加压的形式来判断系统所能承受的性能节点,一般在场景设置中配置,举例:每2分钟增加20个虚拟用户,每次持续2分钟,还是结合TPS,每秒事务总数,每秒连接数来辅助判断系统拐点(指标出现明显的下降等)。
- 稳定性测试
容量测试可以得到系统的最高承受力或这是性能最优点,可以用容量测试的结果或者*80%来做稳定性测试,设定时间为8小时或者是24等。
三、测试计划,(规范性比较强的会做要求,例如银行)
野路子的我是不需要计划的【哈哈哈】,不过有时候公司会让提供,此处列一个基本的目录供参考(一般像银行也会让你提供一份)。

四、搭建测试环境
测试系统环境:windows7
测试工具:LoadRunner11
测试浏览器:火狐浏览器24
【这块没啥说的,网上教程很多,目前破解的只有LoadRunner11,而11只能在window7-旗舰版上使用,而且支持录制的,只有IE8和火狐24】
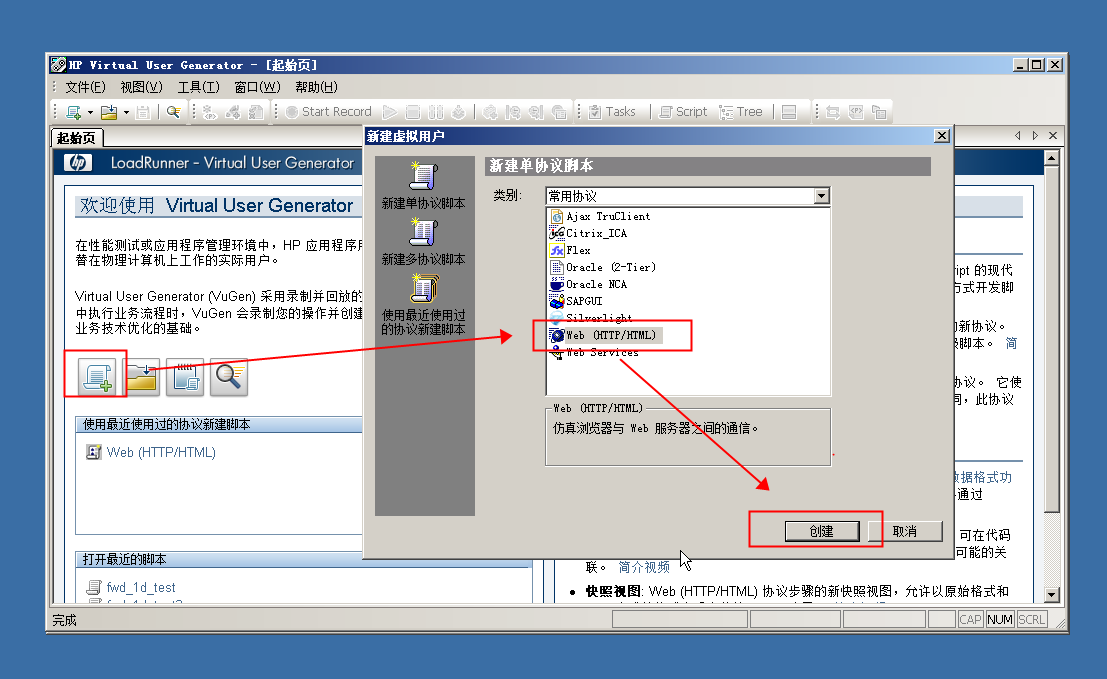
四、录制脚本
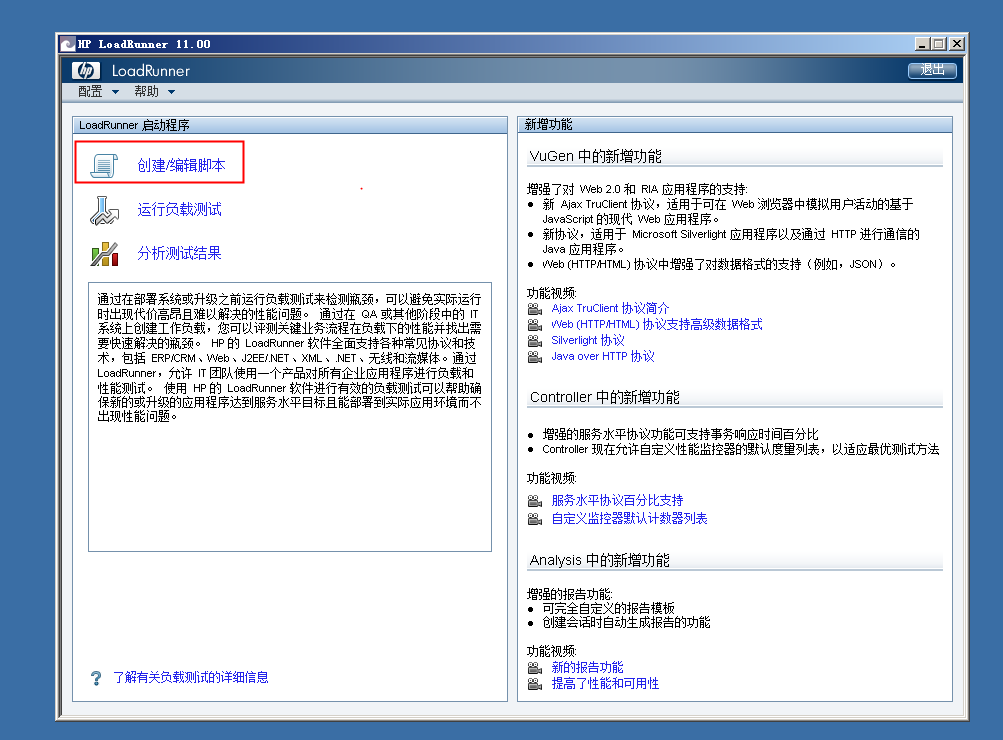
第一步点击创建/编辑脚本【注意启动都是用管理员启动】
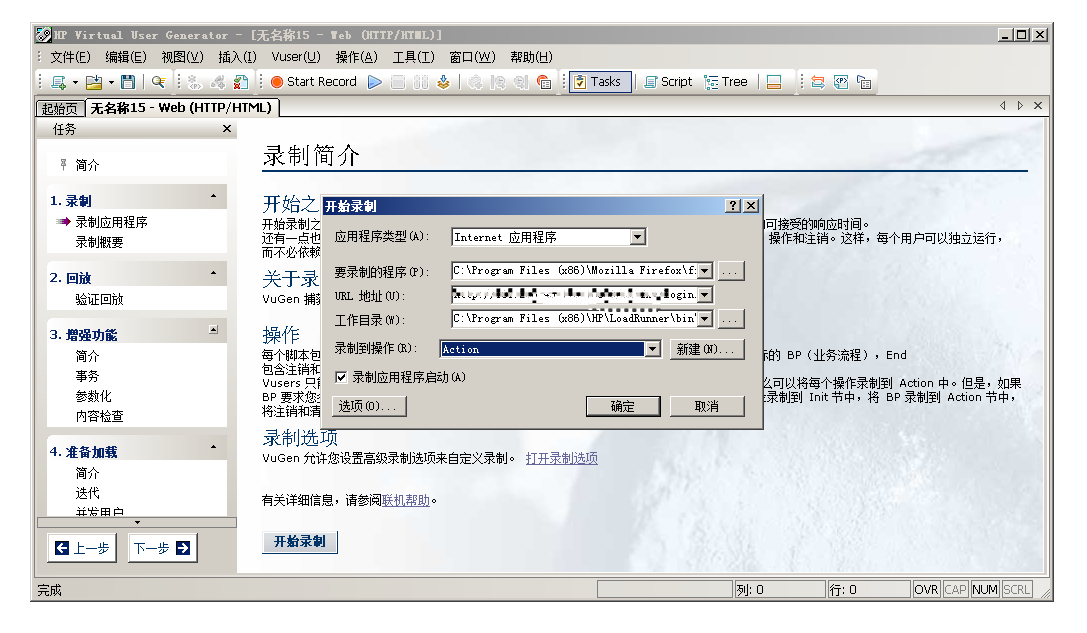
这里的参数需要说明一下:
应用程序类型:分为Internet 应用程序,w32应用程序,web测试默认Internet 应用程序就可以了。
要录制的程序:此为浏览器的应用程序地址,这里使用的火狐24
url地址:要测试的服务地址
工作目录:lordrunner的bin目录
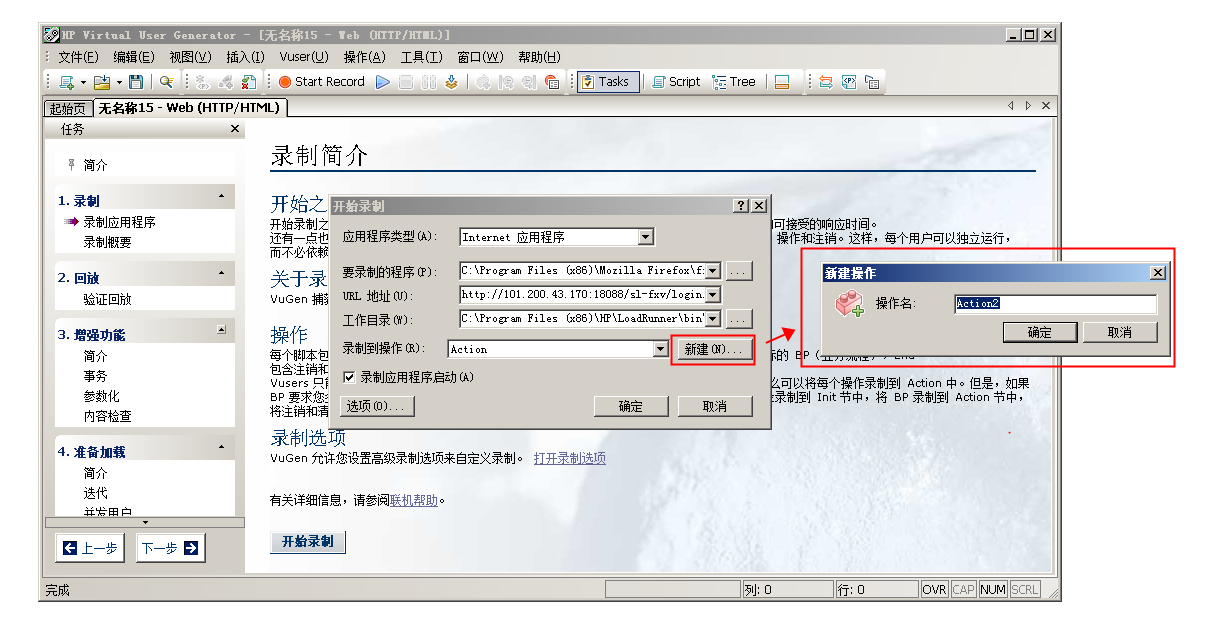
注意:此处可以分离对应的操作,比如说初始是登录,则简历对应登录操作存放登录相关事件脚本
录制脚本过程相对简单,傻瓜式,这里就不描述了,主要是录制的脚本需要调整,主要通过Script进行调整,录制后的脚本查看请求响应情况可以通过Tree进行查看,类似页面F12的效果。
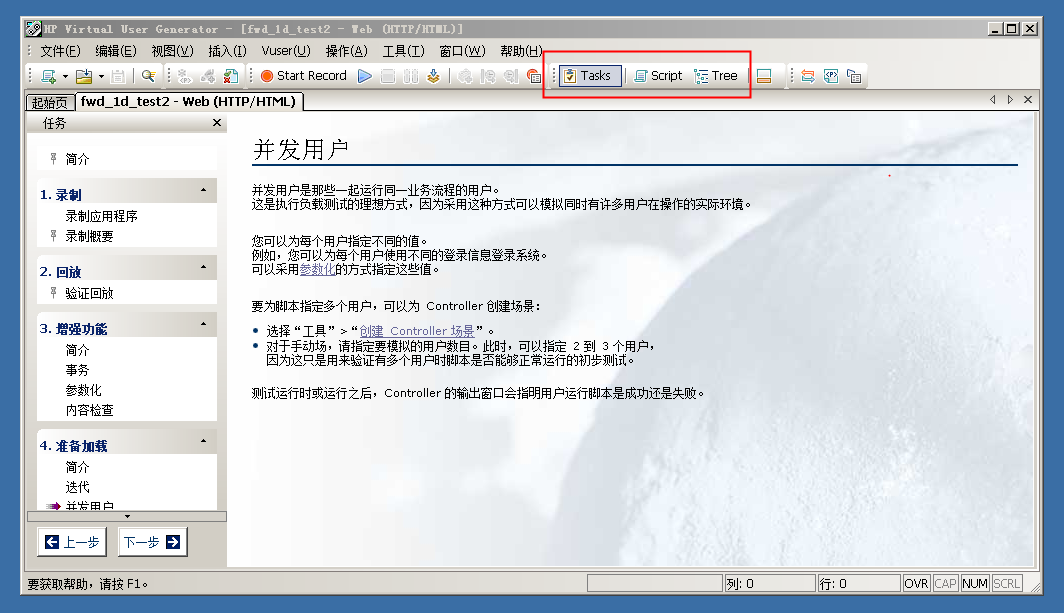
五、脚本增强
1、事务
模拟用户的一个相对完整的、有意义的业务操作过程,例如登录、查询、交易、转账,这些都可以作为事务,而一般不会把每次HTTP请求作为一个事务。对于业务逻辑性比较强的系统来说,一个事务可能是一系列请求的合集,比如说一个保存事务,一直到保存这一步,可能包括了,获取新增界面信息、获取客户信息、获取清算信息、计算、然后才是保存。
这一块就要具体业务具体分析了,要注意,集合点中不要设置集合点,思考时间,不然会影响实际的结果。
至于事务的设置,可以使用右键新增,要注意这是一个前后呼应的函数,开始和结尾必须都存在,事务名称一致。
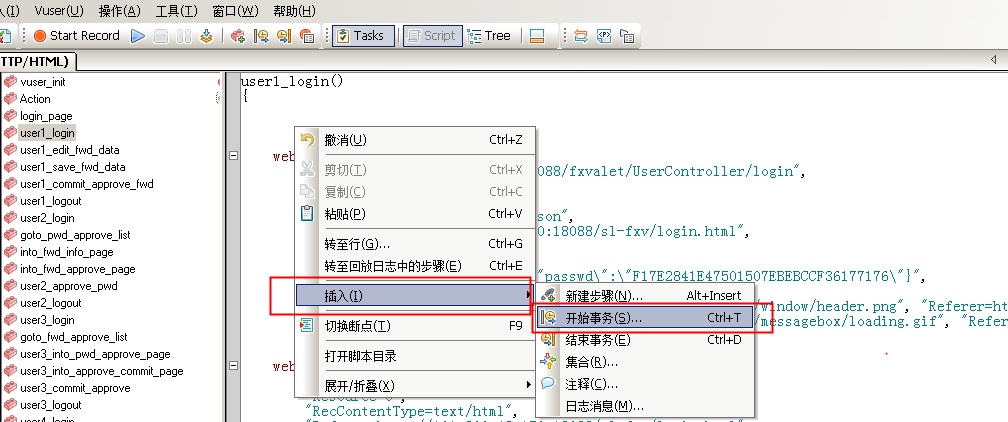
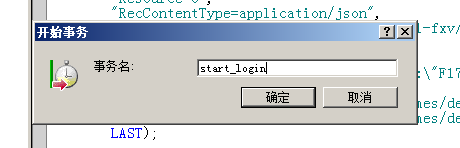
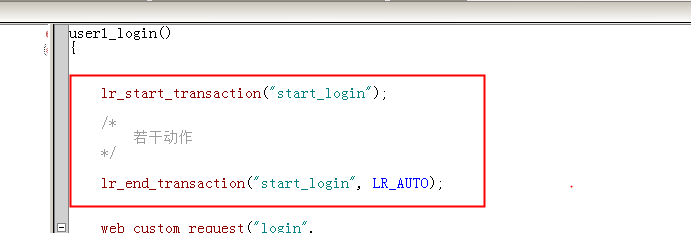
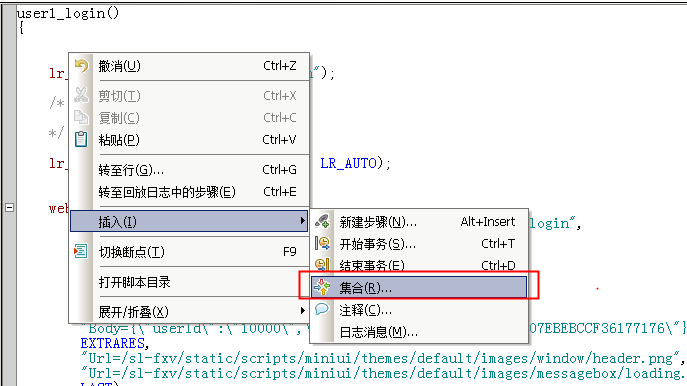
2、集合点
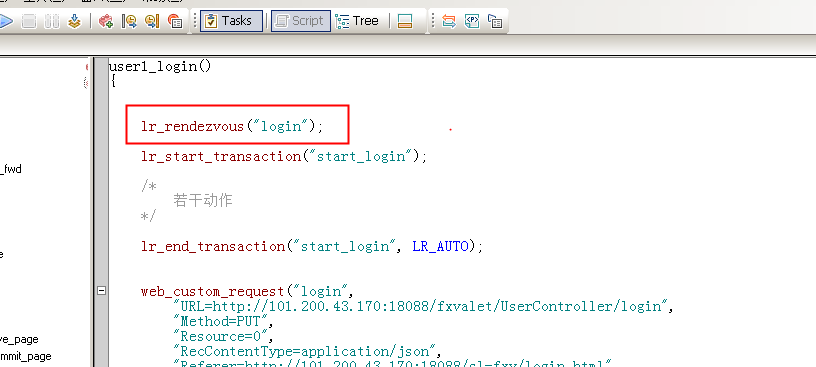
集合点,顾名思义,就是虚拟用户的集合点,相当于大量的用户集合某一个点,并等待其他用户集合,达到释放的标准后,同一时间对服务器访问形成并发,来对服务器形成更大的压力。
操作方式如下:
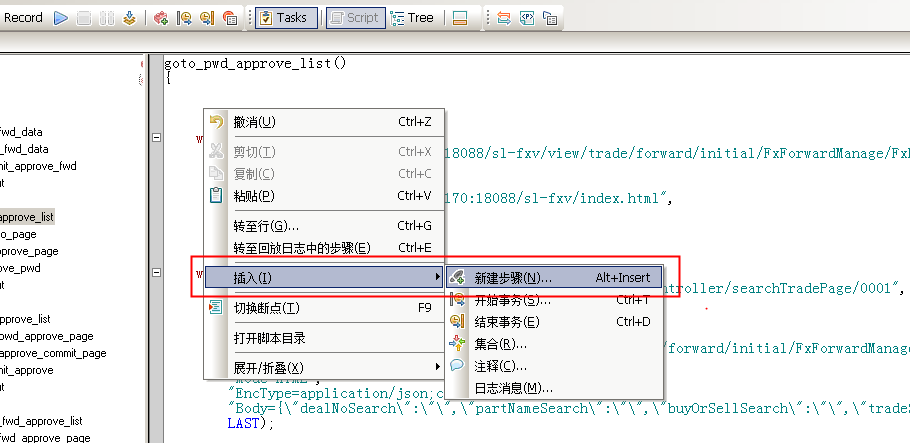
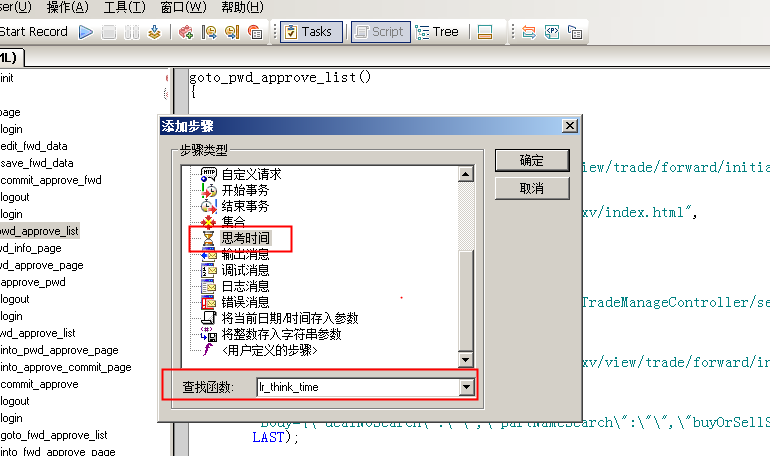
3、思考时间
用户访问某个网站或软件,一般不会不停地做个各种操作,例如填写表单,用户需要时间输入信息,并检查等等,也就是说用户在做某些操作时,是会有停留时间的,我们在做性能测试时,为了更真实的模拟用户的操作,需要给代码加入思考时间。
使用方式如下:

4、参数化
为了更真实的模拟现实环境,我们进行性能测试的时候登录用户也不能是同一样,此时可能需要预设成千上百的用户,又或者一些系统本身就是单点登录的系统,一个用户在使用时,其他人无法使用。针对这些场景,参数化就派上用场了。
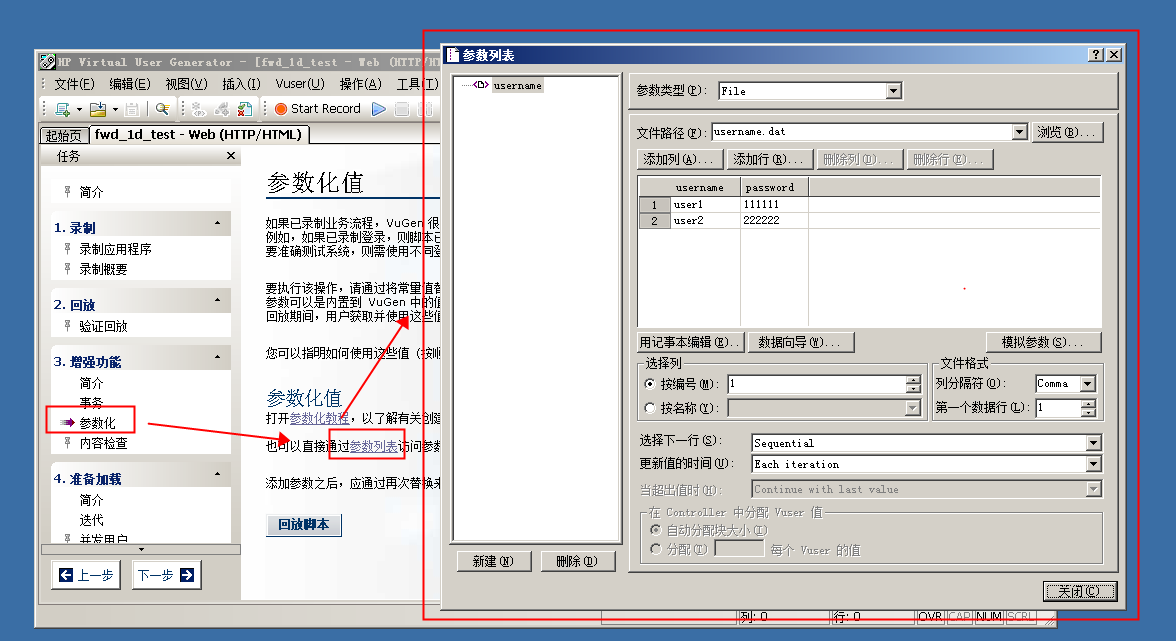
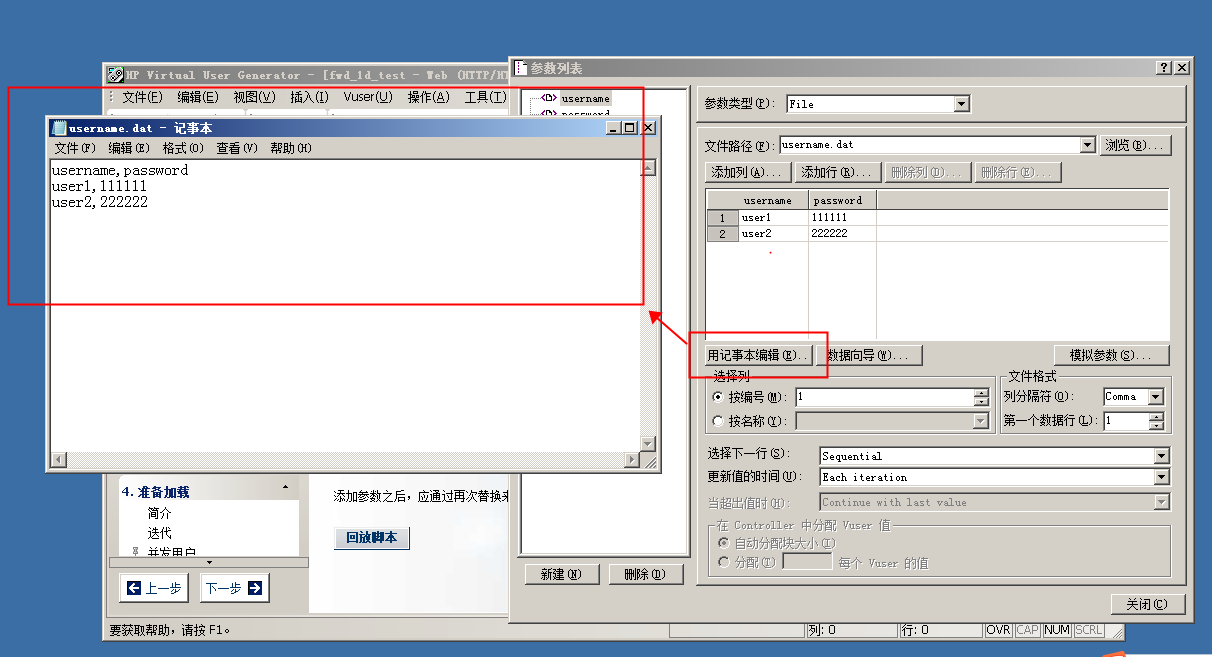
以用户名、密码为例,点击记事本编辑,出现以下格式文件编辑界面,如果量比较大,可以使用excel编辑好,复制进来,用户名我们一般按照列名来取,
而用户名的选取方式
选择下一行的时间:
Sequential :顺序的,按照参数化的数据顺序,从上往下一个一个的来取;
Random: 随机取,参数化中的数据,每次随机的从中抽取数据;
Unique :唯一,唯一的向下取值,只能被用一次;
Same line as *:和*列取同一行的值,(行相同)步调一致;
更新值得时间:
Each iteration :每次迭代时取值;
Each occurrence :每次遇到该参数时取值;
Once :取值仅一次,脚本运行过程中只取值一次值的是:一次选择,一直不变;
我一般采用Sequential + Each iteration的模式,具体要结合实际的业务场景来选择。
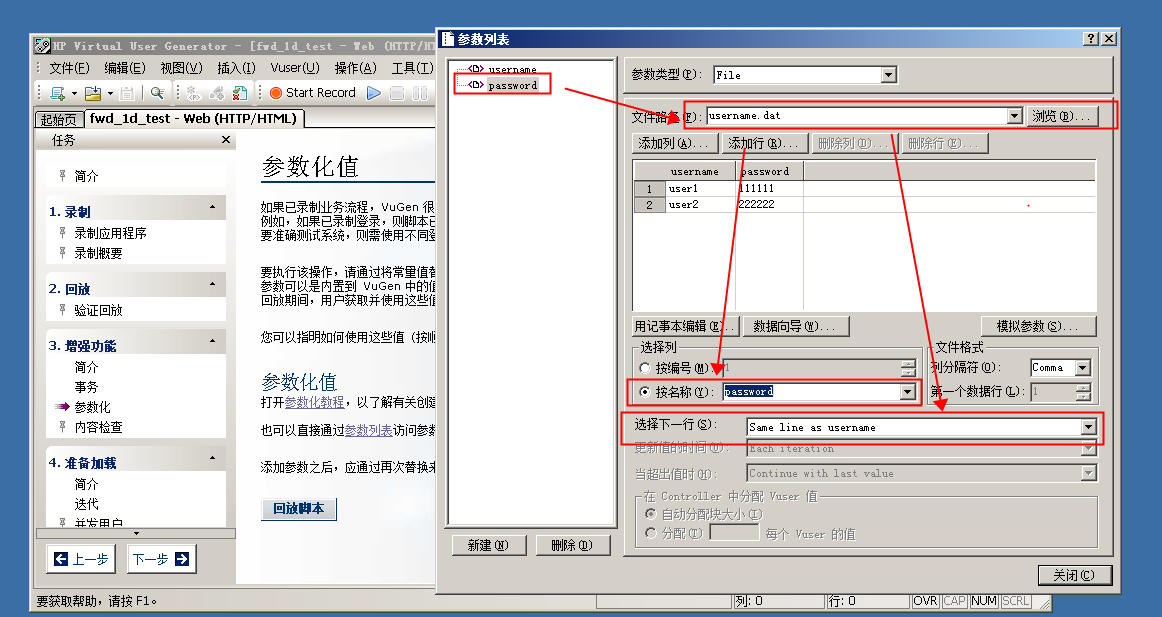
而密码需要和用户名对应,所以选取方式使用用户名同一行的数据。
5、补充
5.1 附件需要存在对应脚本根目录才可以上传
六、设置
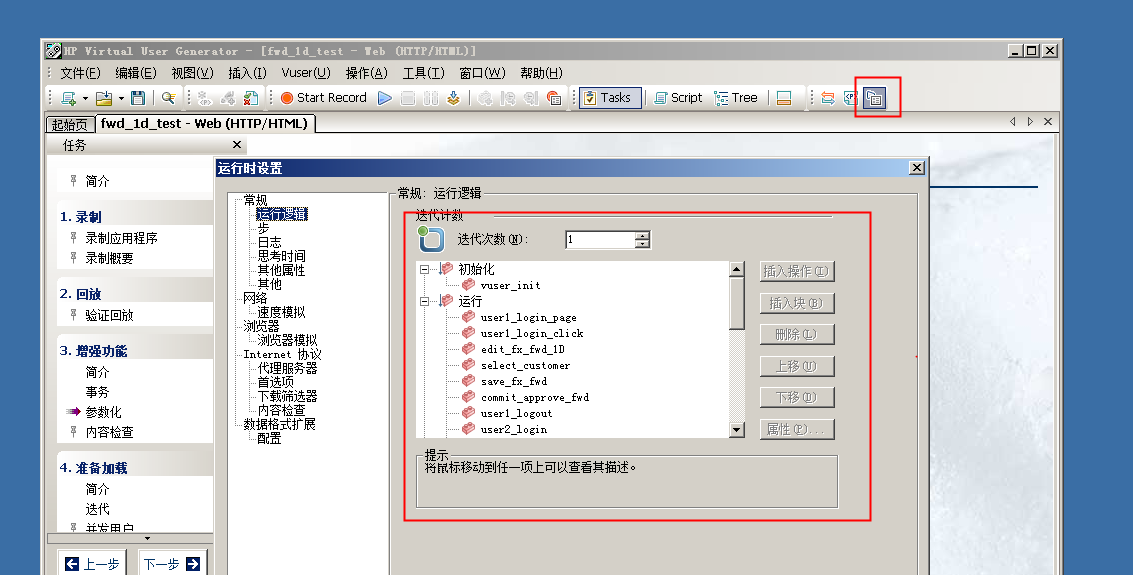
运行时设置十分重要,一定要记得设置,性能测试的原理是使用若干得虚拟用户来同时执行一个脚本,而运行的一些方式则由此设置决定。
打开按钮如下图,这里可以设置运行的逻辑,包括迭代次数等,执行顺序等,最常用的就是登陆完成后,循环做业务操作,来做性能测试。
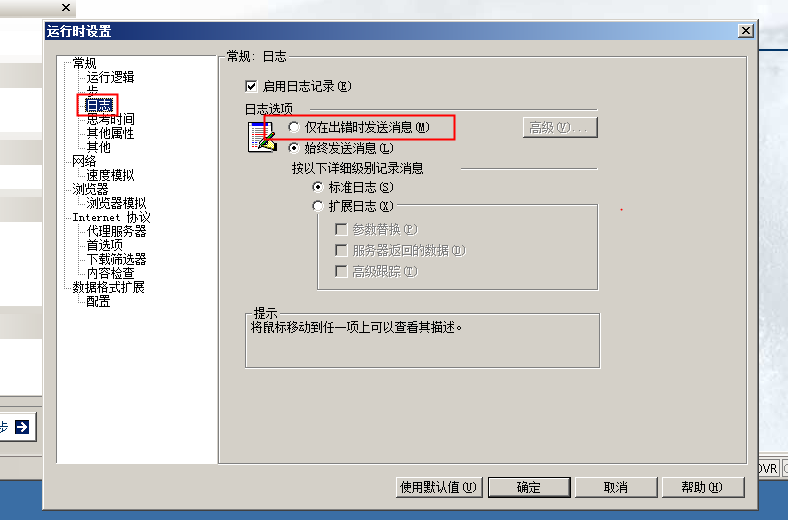
日志设置,执行脚本阶段,应该选择仅在出错时发送消息,因为并发时候日志量级太大,根本看不出来,只需要关注错误信息即可。
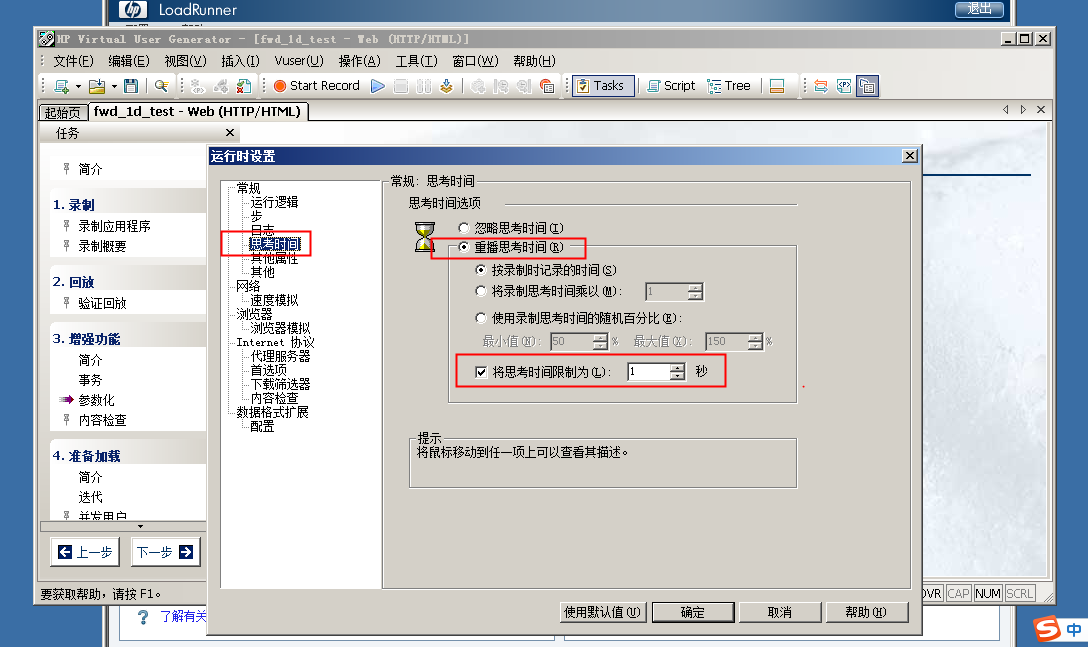
设置中默认是忽略思考时间的,为了更好的模拟实际情况,应该启用思考时间,但是脚本多了,而且是录制的,可能有些思考时间太长,影响到测试的效率, 需要针对实际情况进行限制,比如说下图就是限制了不超过1s。
另外的设置我关注比较少,后面如有需要我再继续补充。
七、场景设置及监控指标
脚本设置完毕后,点击打开场景设置,这里设置的主要是测试的策略,包括用户启动的速度,执行时间,集合策略等等。
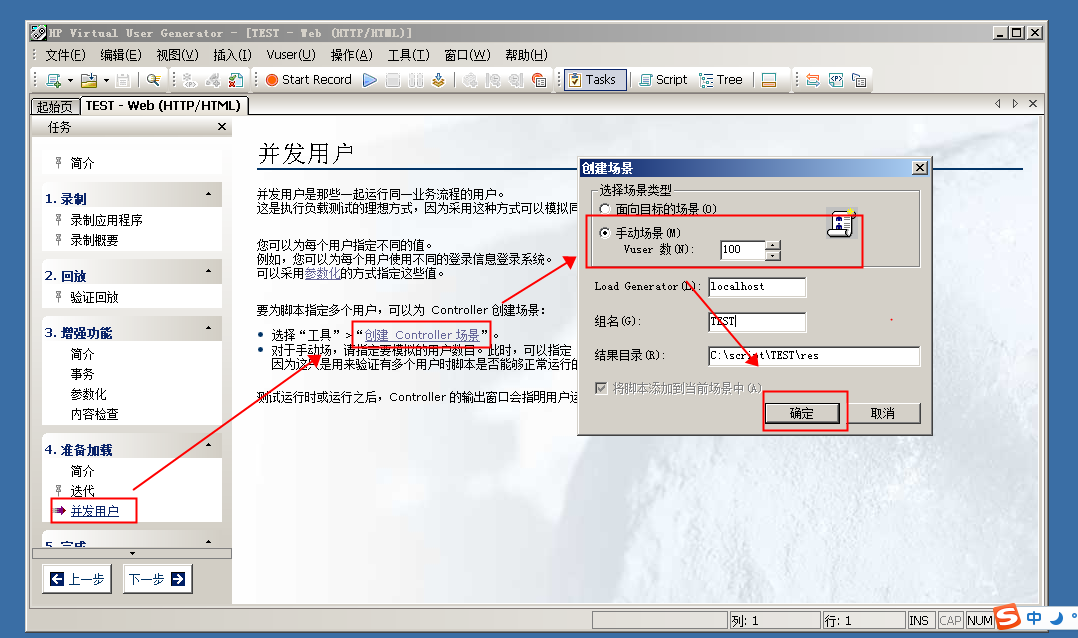
这里主要说明以上几点:
设置vuser数量和增长频率
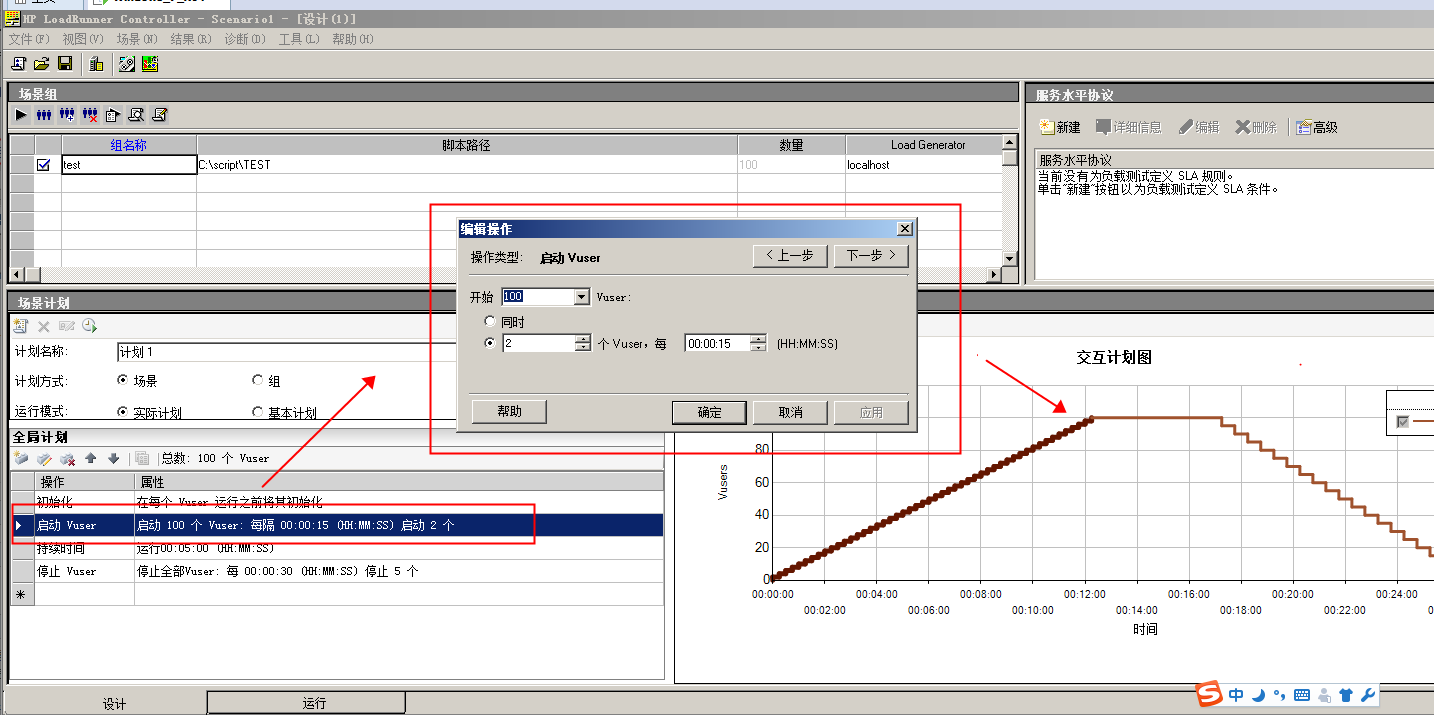
设置执行时间

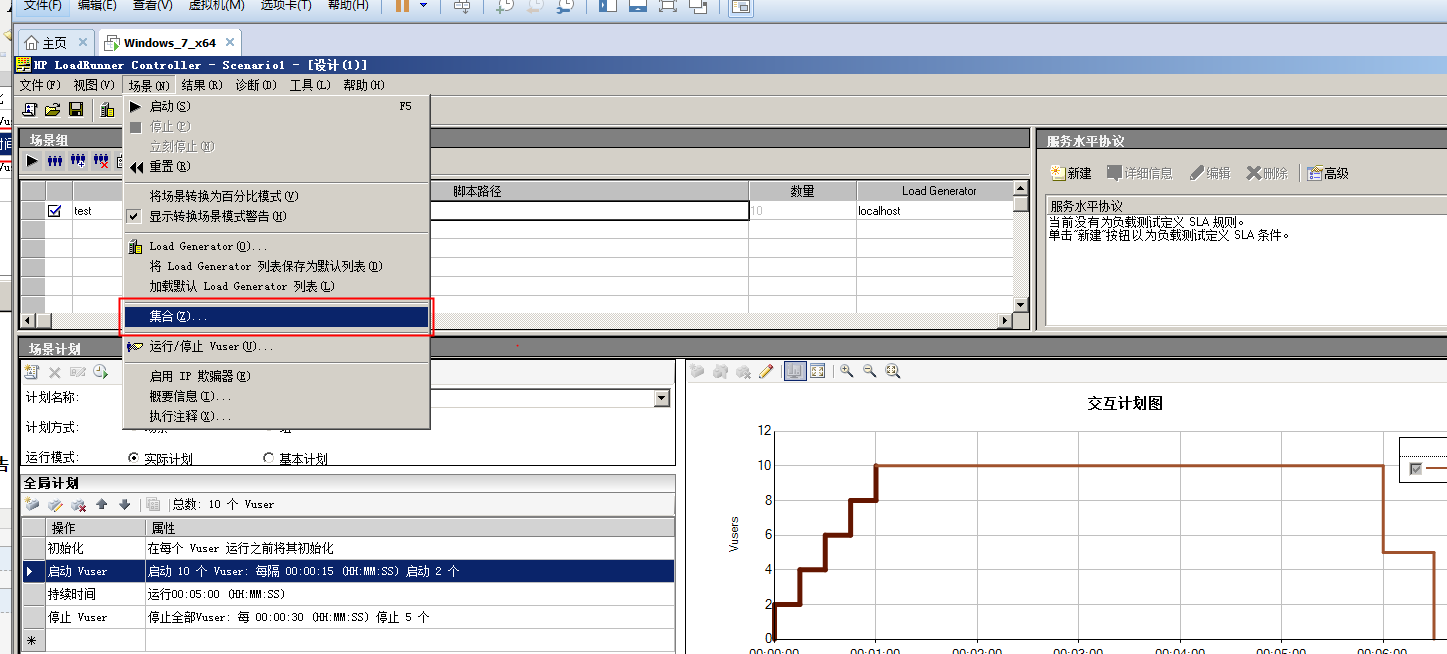
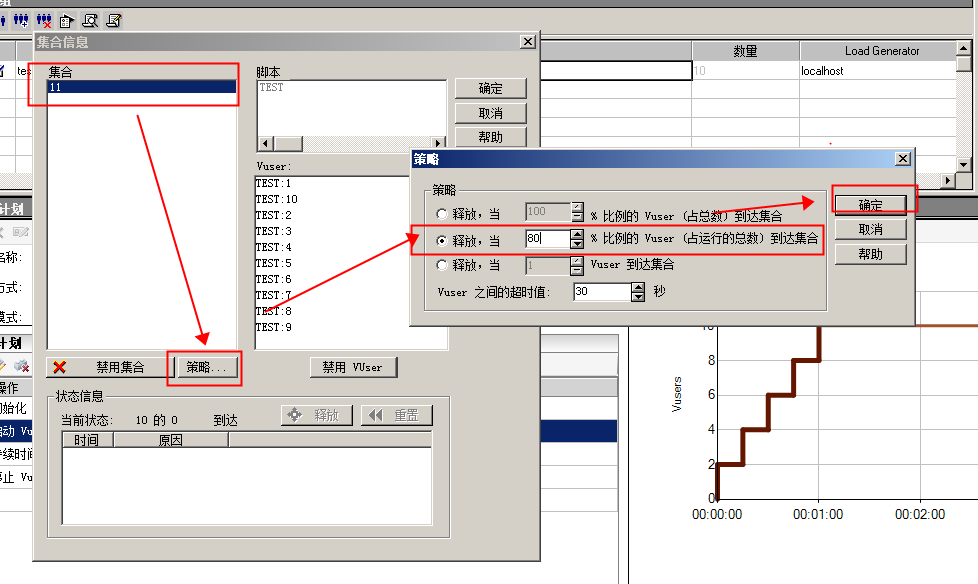
设置集合策略
切换到运行tab页,可以选择监控的相关指标,包括 vuser数量、响应时间、每秒通过事务数、系统吞吐量等。
八、编写报告
报告这块,还是给大家一个目录作为参考,只要把结果描述清楚,是否满足最开始的指标需求(这个过程中如果不满足,就需要根据实际情况进行调优了,测试人员可以给开发人员建议,此块可以参考另外一篇博客(基于web网站项目的性能测试结果分析)

使用Loadrunner进行性能测试的更多相关文章
- Loadrunner进行性能测试的步骤
Loadrunner 11是一款免费的性能测试工具,他包含三个大模块 •使用VuGen:创建脚本•运用Controller:设置方案•查看Analysis:分析测试结果 结合软件测试的流程可以知道使用 ...
- Loadrunner做性能测试的主要步骤
Loadrunner做性能测试的主要步骤: Loadrunner将性能测试过程分为计划测试.测试设计.创建VU脚本.创建测试场景.运行测试场景和分析结果6个步骤. 1) 计划测试:主要进行测试需求的收 ...
- [转][LoadRunner]LR性能测试结果样例分析
LR性能测试结果样例分析 测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要.并发数.平均事务响应时间.每秒点击数.业务成功率.系统资源.网页细分图.Web服务器资源 ...
- LoadRunner做性能测试 从设计到分析执行
项目简介:像百度知道系统类似的系统性能测试,是公司的自己产品. 对最近这个系统的性能测试进行总结下: 系统功能介绍: 前台用户可以根据自己的需要对不同的区域提问,提问包括匿名和登陆用户提问 后台不同区 ...
- [LoadRunner]LR性能测试结果样例分析
R性能测试结果样例分析 测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要.并发数.平均事务响应时间.每秒点击数.业务成功率.系统资源.网页细分图.Web服务器资源. ...
- 【Loadrunner】性能测试:通过服务器日志获取性能需求
性能测试:通过服务器日志获取性能需求 接触过性能测试的童鞋都知道,想要做好一个项目的性能测试,性能需求的获取至关重要~!如果公司有做过性能测试还好,大家可以拿之前的性能测试数据作为参 ...
- LoadRunner性能测试执行过程的问题
LoadRunner做性能测试 从设计到分析执行 执行测试并分析调优: 测试中报错的信息解决: 1. Failed to connect to server "域名:80": [1 ...
- 《软件性能测试与LoadRunner实战教程》新书上市
作者前三本书<软件性能测试与LoadRunner实战>.<精通软件性能测试与LoadRunner实战>和<精通软件性能测试与LoadRunner最佳实战>面市后,受 ...
- 性能测试从零开始-LoadRunner入门
写在前面 又到了公司每月的读书会,经过上个月的试运行后,公司把读书会纳入每月的绩效考核中,听到这个消息,当时我的内心是崩溃的,不过从另一方面来讲,对于我来说也一件好事儿,这样可以督促自己养成读书的习惯 ...
随机推荐
- python 爬虫刷访问量
import urllib.requestimport time # 使用build_opener()是为了让python程序模仿浏览器进行访问opener = urllib.request.buil ...
- 8 Java 条件逻辑语句
生活中,我们经常需要先做判断,然后才决定是否要做某件事情.例如,在上学的时候,如果期末考试成绩在全校能拿到前100名,则奖励一个 iPhone 11 .对于这种“需要先判断条件,条件满足后才执行的情况 ...
- ASP.NET Core3.x 基础(1)
ASP.NET Core与2.x相比发生的一些变化: 项目结构 Blazor SignalR gRPC 关于Program类:Main方法,在系统执行时就会找到这个Main方法,实际上是配置了ASP. ...
- c++之广度优先搜索
广度优先搜索BFS(Breadth First Search)也称为宽度优先搜索,它是一种先生成的结点先扩展的策略. 在广度优先搜索算法中,解答树上结点的扩展是按它们在树中的层次进行的.首先生成第一层 ...
- Markdown基本语法及生成目录结构的方法
Markdown是一种纯文本格式的标记语言.通过简单的标记语法,它可以使普通文本内容具有一定的格式. 一.标题 在想要设置为标题的文字前面加#来表示一个#是一级标题,二个#是二级标题,以此类推.支持六 ...
- 2020-06-19:多线程消费kafka的时候,开发、测试环境都能每秒10w+,但是正式环境只能1w/s,正式环境不能重启,看怎么调试?
福哥答案2020-06-19: 答案来自群成员:基准测试. 观察 网络和磁盘的读写,实时与历史曲线,观察文件句柄/内存的使用情况.观察系统patch 基础库/运行时状态.
- C#LeetCode刷题之#219-存在重复元素 II(Contains Duplicate II)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3704 访问. 给定一个整数数组和一个整数 k,判断数组中是否存在 ...
- geth常用命令
转载地址 https://blog.csdn.net/qq_36124194/article/details/83686823 geth常用命令 初始化私链 geth --datadir /path/ ...
- 详解POW工作量证明原理
原文地址 来自 微信公众号 区块链大师 POW工作量证明(英文全称为Proof of Work)早在比特币出现之前就已经有人探索,常见的是利用HASH运算的复杂度进行CPU运算实现工作量确定,当然你 ...
- [算法入门]——深度优先搜索(DFS)
深度优先搜索(DFS) 深度优先搜索叫DFS(Depth First Search).OK,那么什么是深度优先搜索呢?_? 样例: 举个例子,你在一个方格网络中,可以简单理解为我们的地图,要从A点到B ...