Java 树结构实际应用 二(哈夫曼树和哈夫曼编码)
package huffmanTree; import java.util.ArrayList;
import java.util.Collections; public class HuffmanTree { public static void main(String[] args) {
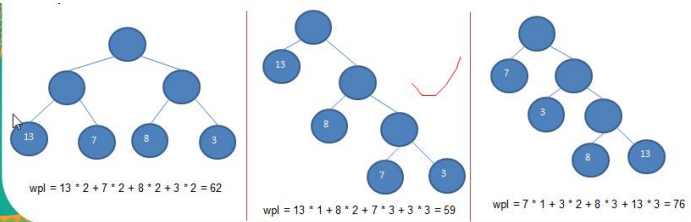
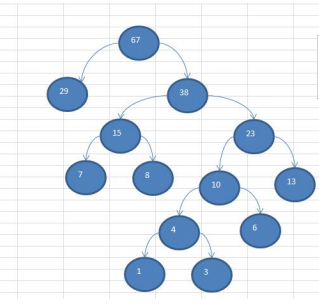
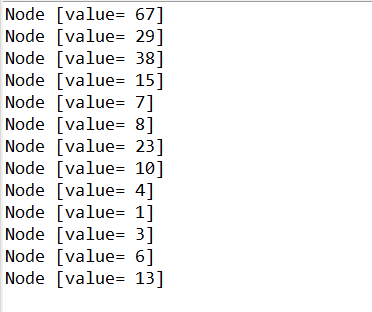
int[] arr = {13, 7, 8, 3, 29, 6, 1}; Node createHuffmanTree = createHuffmanTree(arr); preOrder(createHuffmanTree); } // 前序遍历方法
public static void preOrder(Node root) {
if(root != null) {
root.preOrder();
} else {
System.out.println("空树!");
}
} // 创建哈夫曼树
public static Node createHuffmanTree(int[] arr) {
// 1 遍历arr数组
// 2 将arr的每个元素构成一个Node
// 3 将Node放入ArrayList
ArrayList<Node> nodes = new ArrayList<Node>();
for (int value: arr) {
nodes.add(new Node(value));
} while(nodes.size() > 1) {
Collections.sort(nodes); // System.out.println(nodes.toString()); // 取出根节点权值最小的两个二叉树
Node leftNode = nodes.get(0);
Node rightNode = nodes.get(1); // 构建新二叉树
Node parent = new Node(leftNode.value + rightNode.value);
parent.left = leftNode;
parent.right = rightNode;
// 删除处理过的节点
nodes.remove(leftNode);
nodes.remove(rightNode);
// parent加入List
nodes.add(parent); // Collections.sort(nodes);
// System.out.println(nodes.toString());
}
// 返回root
return nodes.get(0);
}
} // 创建节点
class Node implements Comparable<Node>{
int value;
Node left;
Node right; public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
} public Node(int value) {
this.value = value;
} @Override
public String toString() {
return "Node [value= " + value + "]";
} @Override
public int compareTo(Node o) {
return this.value - o.value;
}
}


package com.lin.HuffmanCode_0314; import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
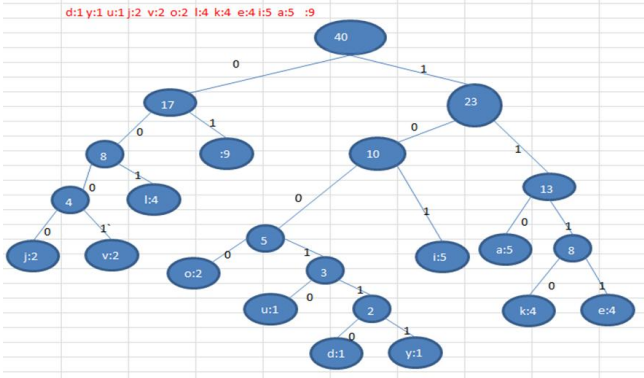
import java.util.Map; public class HuffmanCode { public static void main(String[] args) { String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println(contentBytes.length); // 40 List<Node> nodes = getNodes(contentBytes);
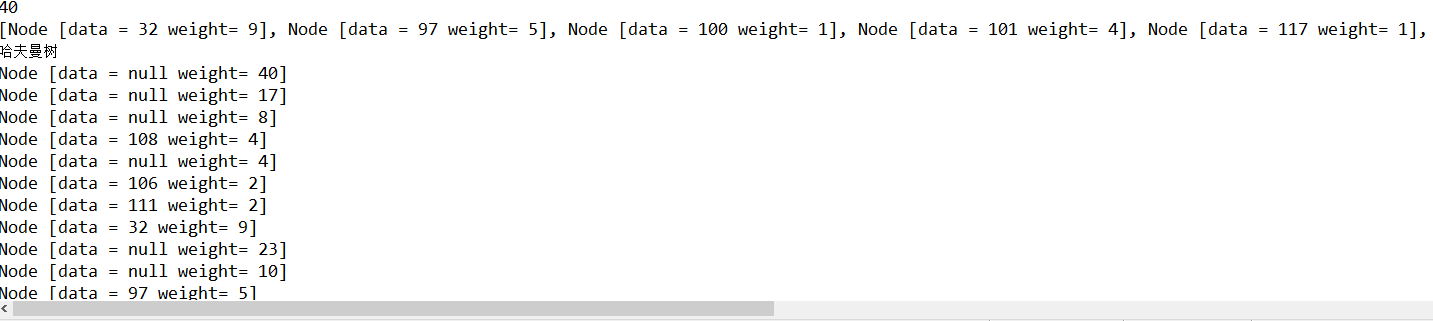
System.out.println(nodes); // 创建哈夫曼树
System.out.println("哈夫曼树");
Node createHuffmanTree = createHuffmanTree(nodes); preOrder(createHuffmanTree); } /**
*
* @Description:生成赫夫曼树对应的赫夫曼编码<br>
* 思路:将赫夫曼编码存放在Map<
* @author LinZM
* @date 2021-3-14 21:09:30
* @version V1.8
*/ // 前序遍历
private static void preOrder(Node root){
if(root != null) {
root.preOrder();
} else {
System.out.println("空树!");
}
}
/**
*
* @Description:
* @author LinZM
* @date 2021-3-14 20:45:23
* @version V1.8
* @param bytes接收字节数组
* @param
*/
private static List<Node> getNodes(byte[] bytes){
// 1 创建一个ArrayList
ArrayList<Node> nodes= new ArrayList<Node>(); // 遍历bytes,统计每一个byte出现的次数->map[key, value]
Map<Byte, Integer> counts = new HashMap();
for(byte b: bytes) {
Integer count = counts.get(b); //
if(count == null) { // Map中还没有这个字符数据, 第一次
counts.put(b, 1);
} else {
counts.put(b, count + 1);
}
}
// 把每个键值对转成一个Node对象, 并加入到nodes集合
for(Map.Entry<Byte, Integer> entry: counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
} // 通过List创建赫夫曼树
private static Node createHuffmanTree(List<Node> nodes) {
while(nodes.size() > 1) {
Collections.sort(nodes); Node leftNode = nodes.get(0);
Node rightNode = nodes.get(1); Node parent = new Node(null, leftNode.weight + rightNode.weight); parent.left = leftNode;
parent.right = rightNode; nodes.remove(leftNode);
nodes.remove(rightNode); nodes.add(parent);
}
return nodes.get(0);
} } class Node implements Comparable<Node>{
Byte data;// 存放数据本身
int weight; // 权值,字符出现的次数
Node left;
Node right; public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
} @Override
public int compareTo(Node o) {
// TODO Auto-generated method stub
return this.weight - o.weight;
} @Override
public String toString() {
return "Node [data = " + data + " weight= " + weight + "]";
} // 前序遍历
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
}
仅供参考,有错误还请指出!
有什么想法,评论区留言,互相指教指教。
觉得不错的可以点一下右边的推荐哟
Java 树结构实际应用 二(哈夫曼树和哈夫曼编码)的更多相关文章
- Java数据结构(十二)—— 霍夫曼树及霍夫曼编码
霍夫曼树 基本介绍和创建 基本介绍 又称哈夫曼树,赫夫曼树 给定n个权值作为n个叶子节点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称为最优二叉树 霍夫曼树是带权路径长度最短的树,权值较 ...
- 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- java实现哈弗曼树和哈夫曼树压缩
本篇博文将介绍什么是哈夫曼树,并且如何在java语言中构建一棵哈夫曼树,怎么利用哈夫曼树实现对文件的压缩和解压.首先,先来了解下什么哈夫曼树. 一.哈夫曼树 哈夫曼树属于二叉树,即树的结点最多拥有2个 ...
- 10: java数据结构和算法: 构建哈夫曼树, 获取哈夫曼编码, 使用哈夫曼编码原理对文件压缩和解压
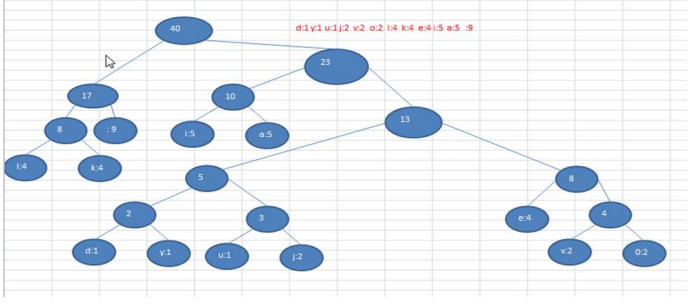
最终结果哈夫曼树,如图所示: 直接上代码: public class HuffmanCode { public static void main(String[] args) { //获取哈夫曼树并显 ...
- C语言数据结构之哈夫曼树及哈夫曼编码的实现
代码清单如下: #pragma once #include<stdio.h> #include"stdlib.h" #include <string.h> ...
- 04-树6. Huffman Codes--优先队列(堆)在哈夫曼树与哈夫曼编码上的应用
题目来源:http://www.patest.cn/contests/mooc-ds/04-%E6%A0%916 In 1953, David A. Huffman published his pap ...
- c++实现哈夫曼树,哈夫曼编码,哈夫曼解码(字符串去重,并统计频率)
#include <iostream> #include <iomanip> #include <string> #include <cstdlib> ...
- Java 树结构实际应用 四(平衡二叉树/AVL树)
平衡二叉树(AVL 树) 1 看一个案例(说明二叉排序树可能的问题) 给你一个数列{1,2,3,4,5,6},要求创建一颗二叉排序树(BST), 并分析问题所在. 左边 BST 存在的问题分析: ...
- (哈夫曼树)HuffmanTree的java实现
参考自:http://blog.csdn.net/jdhanhua/article/details/6621026 哈夫曼树 哈夫曼树(霍夫曼树)又称为最优树. 1.路径和路径长度在一棵树中,从一个结 ...
随机推荐
- 3.使用nginx-ingress
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-06-25 13:54:15 星期二 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- git hooks All In One
git hooks All In One $ xgqfrms git:(main) cd .git/ $ .git git:(main) ls COMMIT_EDITMSG HEAD branches ...
- window.navigator All In One
window.navigator All In One navigator "use strict"; /** * * @author xgqfrms * @license MIT ...
- 2020 front-end interview
2020 front-end interview https://juejin.im/post/5e083e17f265da33997a4561 xgqfrms 2012-2020 www.cnblo ...
- taro ref & wx.createSeletorQuery
taro ref & wx.createSeletorQuery https://developers.weixin.qq.com/miniprogram/dev/api/wxml/wx.cr ...
- taro & querySelector & refs
taro & querySelector & refs delayQuerySelector https://github.com/NervJS/taro-ui/blob/dev/sr ...
- NGK公链全面服务旅游经济
有数据显示,2019 年全球旅游总收入已达 6.5万亿美元, 占全球 GDP 的 7.3%,旅游业发展所创造的收益,于全球经济的重要性,不言而喻. 在旅游产业蓬勃发展的同时,中心化运营模式下却仍存在痛 ...
- git相关问题
1.git查看远程分支更新到本地 git clone 项目地址,示例如下: git clone https://github.com/zhongyushi-git/vue-test.git 在拉取时, ...
- setScaledContents
ui->catchPhotoLabel_607->setPixmap(QPixmap::fromImage(*m_imageCatchtDefaultPhoto_607).scaled(Q ...
- SpringBoot启动报错 Disconnected from the target VM, address: '127.0.0.1:2227', transport: 'socket'
今天搭建了一个SpringBoot项目,刚启动就报错 Disconnected from the target VM, address: '127.0.0.1:2227', transport: 's ...