论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)
基于Attention的知识图谱关系预测
Abstract
关于知识库完成的研究(也称为关系预测)的任务越来越受关注。多项最新研究表明,基于卷积神经网络(CNN)的模型会生成更丰富,更具表达力的特征嵌入,因此在关系预测上也能很好地发挥作用。但是这些知识图谱的嵌入独立地处理三元组,因此无法覆盖和收集到三元组周围邻居隐含着的复杂隐藏信息。为此,作者提出了一种新颖的基于注意力的特征嵌入方法,该方法可以捕获任何给定实体的邻居中的实体和关系特征。
Introduction
最新的关系预测方法主要是基于知识嵌入的模型,它们大致分为转化模型和卷积神经网络。转化模型使用简单的操作和有限的参数来学习嵌入,产生了低质量的嵌入。基于CNN的模型由于其大量的参数和复杂关系的考虑而学习了更好的表达性嵌入。但是,基于转化和基于CNN的模型都独立地处理每个三元组,因此无法封装KG中给定实体附近固有存在的丰富的潜在结构信息。
Contributions
- 第一个使用图注意力机制学习针对知识图谱关系预测的嵌入表示。
- 扩展了图注意机制以捕获给定实体的多跳邻域中的实体和关系特征。
- 针对各种数据集中极具挑战性的关系预测任务评估了我们的模型。
Related Work
最近,已经提出了知识图谱嵌入的几种变体用于关系预测。 这些方法可大致分为:
(i)组合模型(ii)翻译模型(iii)基于CNN的模型和(iv)基于图的模型。
Approach
BackGround
知识图谱可以表示为 G=(ϵ, R),其中 ϵ 和 R 分别表示实体(结点)集合和关系(边)集合。对于三元组\((e_i, r, e_j )\)可以表示两个实体节点之间存在边 r。
嵌入模型学习的目标是:实体、关系的有效表示以及打分函数,当给定一个三元组 t 作为输入时,得分函数 f(t) 可以给出 t 是真实三元组的概率。
Graph Attention Networks (GATs)
图卷积网络 (GCNs) (Kipf and Welling, 2017) 将所有邻居实体的信息赋予同样权重来从邻居实体收集信息。
为了解决GCN的缺点,(Velicˇkovic等人,2018) 引入了图注意力网络(GAT), 根据邻居节点不同程度的重要性分配不同权重。GAT每一层的输入为\(x\) = {\(\vec{x_1},\vec{x_2},...,\vec{x_N}\)}, 输出为\(x^{'}\) = {\(\vec{x_1^{'}},\vec{x_2^{'}},...,\vec{x_N^{'}}\)},其中 \(\vec{x_i}\) 和 \(\vec{x_i^{'}}\) 分别代表实体 \(e_i\) 的输入和输出嵌入,N是实体(节点)数量。如果把每一层的结构当作一个黑盒,GCN层和GAT层在这里的表现都是一样的:输入为知识图谱中所有节点的嵌入,输出的是通过聚集邻域节点的信息进行更新后的新嵌入。其不同的仅是层内聚集信息和更新的方法。
一个简单的GAT层可以表示为
\]
\(e_{ij}\) 表示 G 中的边 (\(e_i,e_j\)) 的注意力系数,\(W\)是一个参数化的线性变换矩阵,其作用为将输入特征映射到更高维度的输出特征空间,\(a\)是任意选择的一个计算注意力系数的函数,可以为余弦距离等。
得到一个节点连接的所有边的注意力系数后,就可以用加权平均的方法计算新嵌入,这里需要注意的是下面式子中的 \(a_{ij}\) 是将 \(e_{ij}\) 进行softmax运算得出
\]
GAT中运用多头注意力来稳定学习过程。连接k头的多头注意力计算过程如下式
\]
其中||表示concat,\(\sigma\) 表示任意一个非线性函数,\(a_{ij}^k\) 表示由第k个注意力机制计算的边\((e_i, e_j)\)的归一化后的注意力系数,\(W^k\) 表示第k个注意力机制中对应的线性转化矩阵。
使用multi-head,即做多次运算并将结果拼接,好处是可以允许模型在不同的表示子空间里学习到相关的信息,也就是增加了模型的稳定性。在最终层输出的嵌入向量使用多头运算结果的平均值而不是和之前一样把结果拼接。公式如下
\]
这样做主要是为了得到较小维度的向量,以便进行后续操作如分类等。
Relations are Important
作者认为GATs方法不适合用于知识图谱,因为知识图谱中实体在不同的关系下扮演着不同的角色,而GAT忽略了知识图谱中关系的作用。为此,作者提出了一种新颖的嵌入方法,以将关系和相邻节点的特征纳入注意力机制。
与GAT不同,模型的每一层的输入为两个嵌入矩阵--实体嵌入矩阵和关系嵌入矩阵。其中实体嵌入矩阵用 \(H \in R^{N_e \times T}\) 表示,其中第i行是实体 \(e_i\) 的嵌入,\(N_e\)是实体的总数,T是每个实体嵌入的特征维。 关系嵌入矩阵用 \(G \in R^{N_r \times P}\) 表示,其中 \(N_r\) 是关系的数量, P为关系嵌入的特征维数。最终该层输出两个更新后的嵌入矩阵 \(H^{'} \in R^{N_e \times T^{'}}\) 和 \(G^{'} \in R^{N_r \times P^{'}}\)。
获得实体的新嵌入
首先获得实体 \(e_i\) 的新嵌入,需要学习与 \(e_i\) 关联的每个三元组的表示。 我们通过对对应于特定三元组 \(t_{ij}^k = (e_i, r_k, e_j)\)的实体和关系特征向量的级联执行线性变换来学习这些嵌入,如下式
\]
其中 \(\vec{c_{ijk}}\) 是三元组 \(t_{ij}^k\) 的一个向量表示。\(\vec{h_i},\vec{h_j},\vec{g_k}\) 分别为实体 \(e_i, e_j\), 关系 \(r_k\) 的嵌入表示, \(W_1\) 为线性转化矩阵。
同GAT的思路,我们需要获取每一个三元组的重要程度,即注意力系数 \(b_{ijk}\)。 我们先使用进行一个线性变换,再应用一个非线性的激活函数得到 \(b_{ijk}\),如下式
\]
同理,接下来要做的是把注意力系数进行归一化
\]
其中 \(N_i\) 表示所有与 \(e_i\) 相邻的实体集合,\(R_{in}\) 表示连接实体 \(e_i, e_n\) 关系的集合。
得到归一化后的注意力系数,就可以计算新的嵌入向量了,加权计算公式如下
\]
同GAT,为了稳定学习过程,且获得更多的有关邻居节点的信息,采用多头注意力机制。多头注意力机制中的每一个独立注意力机制之间,上文中的参数 \(W_1, W_2\) 不同。
\]
同理,在最后一层的时候采用平均值而不是concat
\]
获得关系新嵌入
作者使用一个权重矩阵 \(W^R \in \mathbb{R}^{T \times T^{'}}\) 对关系嵌入矩阵 \(G\) 做线性变换得到新嵌入,其中 $ T^{'}$ 是该层输出的关系嵌入向量的维度
\]
模型优化
作者认为在学习新的嵌入向量时,实体丢失了它们初始的嵌入信息。因此作者使用一个权重矩阵 \(W^E \in R^{T^i \times T^j}\) 对初始的实体嵌入向量 \(H^i\) 做线性变换得到转化后的实体嵌入向量 \(H^t\), 而 \(T_i, T_j\) 分别代表初始和最终的实体嵌入向量的维数。作者将初始的实体嵌入向量与最后一个注意力层获得的实体嵌入向量相加
\]
其中\(H^f \in \mathbb{R}^{N_e \times T^f}\)
图四展示了整个模型的架构,这个图可以说是相当形象了。
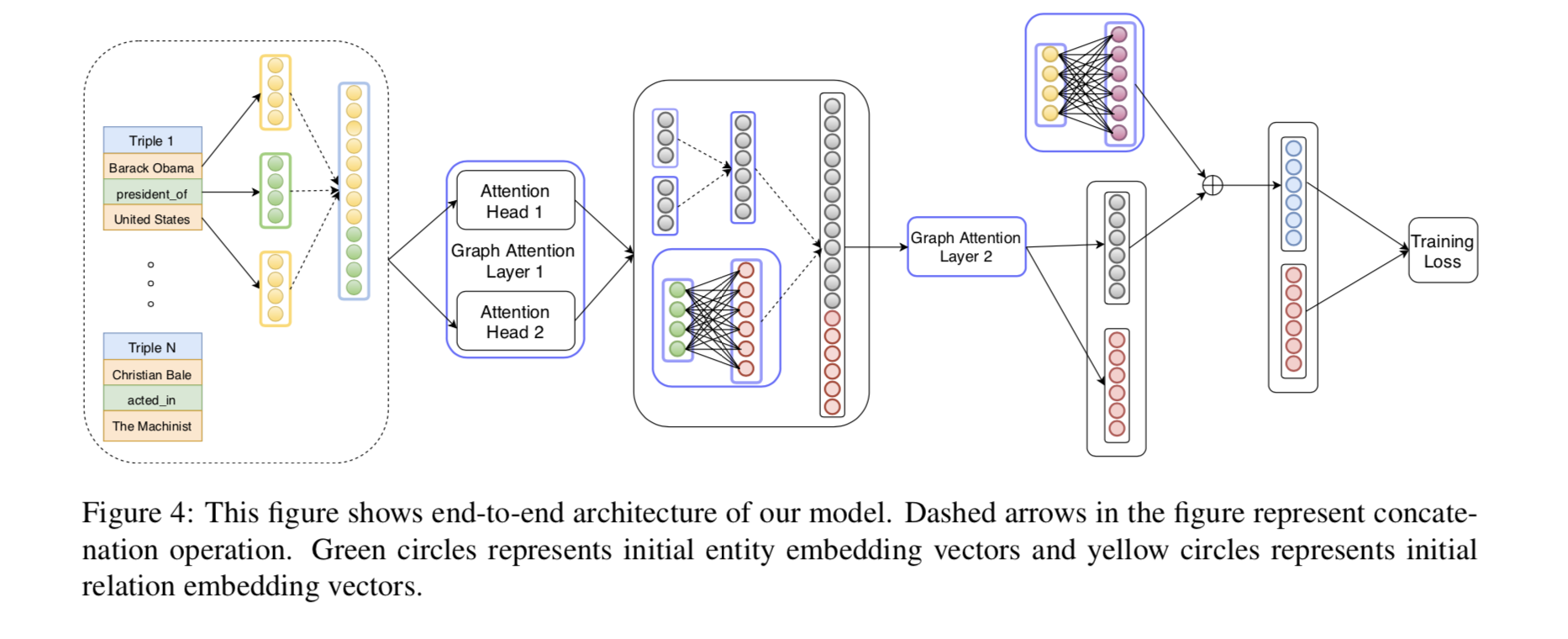
模型中,作者通过定义辅助关系,将边的定义拓展为有向路径,辅助关系的嵌入为有向路径中所有关系的嵌入之和,这样对于一个n层的模型,在第m层就可以通过聚合相邻m跳的邻居计算出新嵌入
Training Objective
作者提出的模型借鉴了(Bordes et al,2013)的翻译评分函数的思想,该函数学习嵌入使得对于给定的有效三元组 \(t_{ij}^k = (e_i, r_k, e_j)\), 有 \(\vec{h_i} + \vec{g_k} \thickapprox \vec{h_j}\) 。作者则提出了一个L1-范数不相似测度 \(d_{t_{ij}} = || \vec{h_i} + \vec{g_k} - \vec{h_j} ||\) ,并使用hinge loss来训练模型
\]
其中 \(\gamma\) 是一个非常小的超参数,\(S\) 是正确的三元组集合,\(S^{'}\) 是无效三元组集合。获得 \(S^{'}\) 的方法为
\]
Decoder
模型采用 ConvKB 作为解码器,卷积层的目的是分析三元组各个维度上面的全局嵌入特性,并归纳出模型的转化特性,根据多个特征映射得到的打分函数如下
\]
其中 \(\omega^m\) 表示第m个 filter,\(\Omega\) 表示 filter 数量,*是卷积运算符,\(W \in \mathbb{R}^{\Omega k \times 1}\) 是一个用于计算三元组最终得分的线性转化矩阵。使用 soft-margin loss
\]
其中当 \(t_{ij}^k \in S\) 时,\(l_{t_{ij}^k} = 1\); 当 \(t_{ij}^k \in S^{'}\) 时, \(l_{t_{ij}^k} = -1\)。
Experiments and Results
Dataset
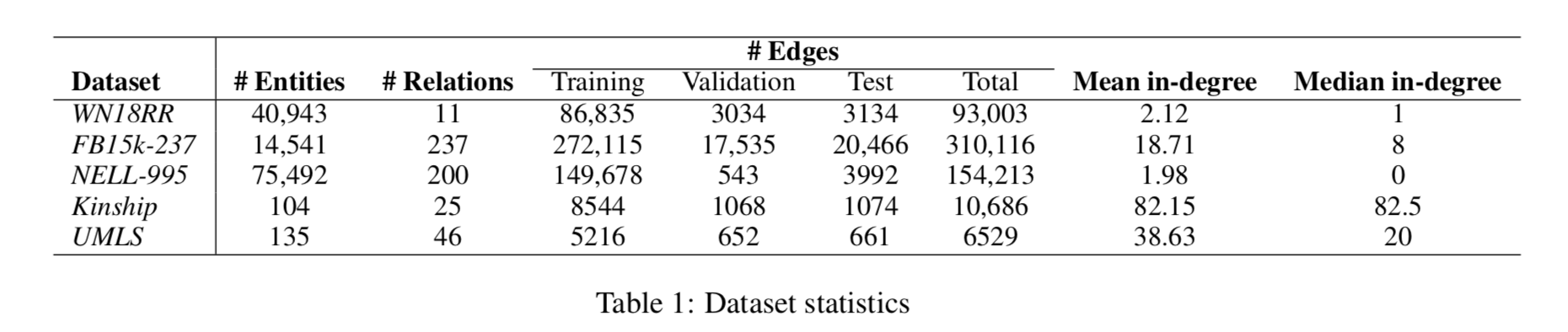
Training Protocol
通过将三元组的头部或尾部实体替换为无效实体,得到两个无效的三元组集合,从两个集合中随机抽取了相等数量的无效三元组,以确保在检测头部和尾部实体时的鲁棒性。TransE 生成的实体和关系嵌入(Bordes等,2013; Nguyen等,2018)用于初始化嵌入。
作者采用两步训练过程。首先训练编码器,即训练广义GAT来编码图中实体和关系的信息,编码器的目的是得到更好、表达程度更高的嵌入。然后训练解码器,如ConvKB模型来进行关系预测任务。传统的 GAT 模型仅根据1-hop邻居的信息对节点特征进行更新,而本文的泛化GAT 则运用多跳邻居对节点特征进行更新。并通过进入辅助关系来聚集稀疏图中邻居的更多信息。作者采用Adam优化器,学习率设置为0.001。最后一层得到的实体和关系的嵌入向量维数设置为200。
Evaluation Protocol
给定一个有效三元组,用其他所有实体对有效三元组中的头实体或尾实体进行替换,产生一个(N-1)三元组集合,其中 1 为被替换之前的有效三元组,N 表示经过替换后产生的三元组数量。移除所有经过替换产生的有效三元组,仅保留替换产生的无效三元组,与最初的有效三元组组成一个三元组集合。对该集合中的所有三元组进行打分,并根据分数进行排序。用平均倒数排名(MRR),平均排名(MR)以及 Hits@N(N = 1, 3, 10) 指标来对模型进行评估。
Results and Analysis
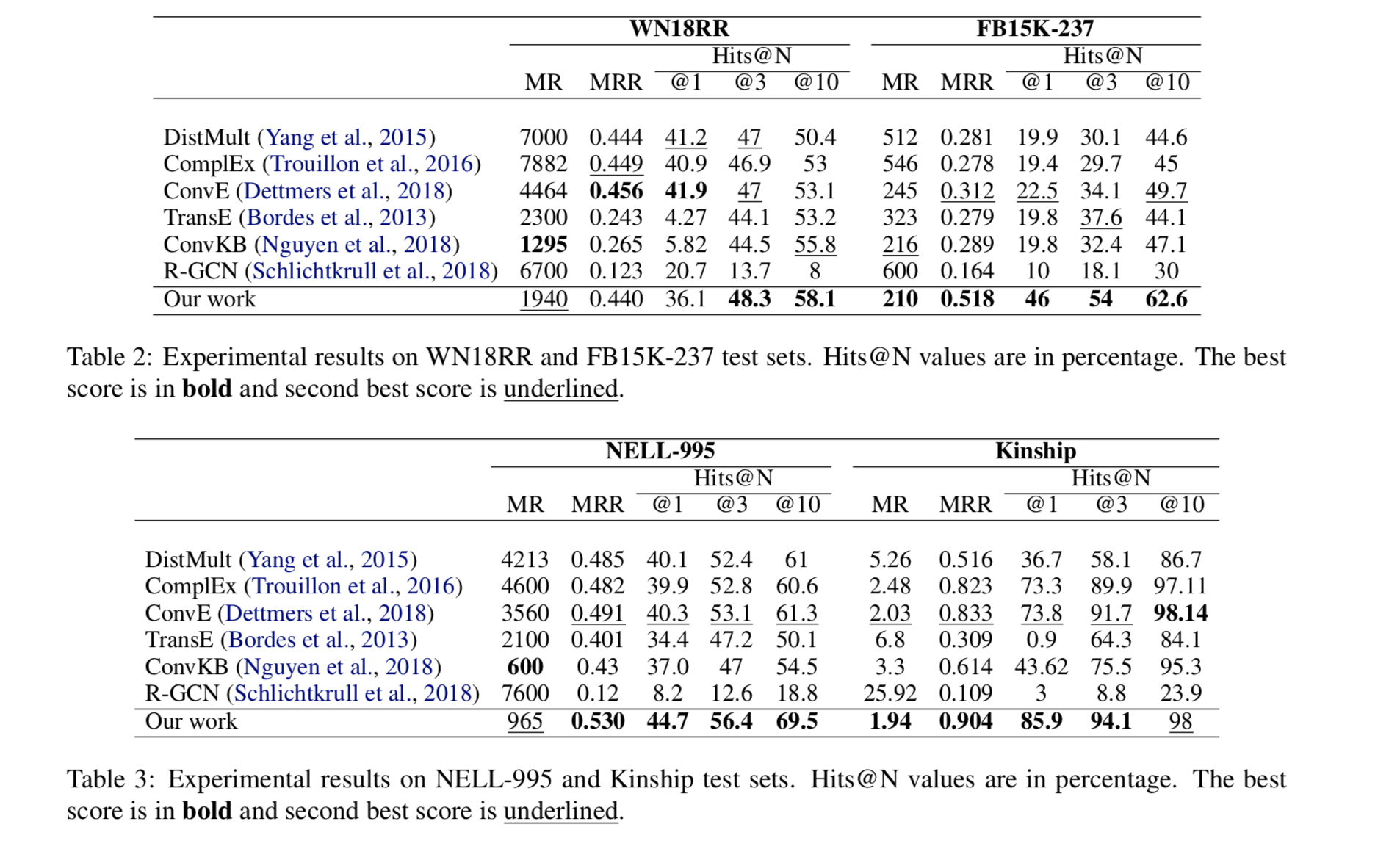
表2和表3展示了在所有数据集上的结果,表明了模型的优越性
Ablation Study
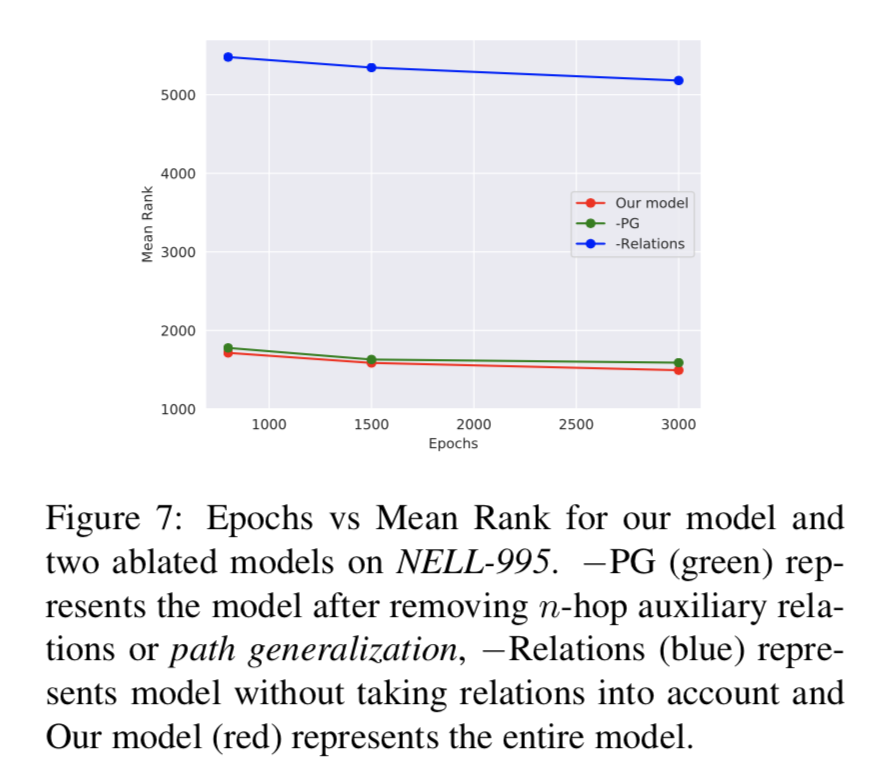
分析了当模型移除了路径的信息(-PG)和移除关系的信息(-Relation)时 MR值的变化。可看出关系信息至关重要。
Conclusion and Future Work
本文贡献:
- 提出一个新型的关系预测方法
- 推广和拓展了图注意力机制
未来工作方向
- 扩展现有方法,使其可以更好地处理层次图。
- 拓展现有方法,在图注意力模型中捕获实体(如主题)之间的高阶关系。
论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)的更多相关文章
- Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs
这篇论文试图将GAT应用于KG任务中,但是问题是知识图谱中实体与实体之间关系并不相同,因此结构信息不再是简单的节点与节点之间的相邻关系.这里进行了一些小的trick进行改进,即在将实体特征拼接在一起的 ...
- 【论文阅读】PBA-Population Based Augmentation:Efficient Learning of Augmentation Policy Schedules
参考 1. PBA_paper; 2. github; 3. Berkeley_blog; 4. pabbeel_berkeley_EECS_homepage; 完
- 论文阅读 Continuous-Time Dynamic Network Embeddings
1 Continuous-Time Dynamic Network Embeddings Abstract 描述一种将时间信息纳入网络嵌入的通用框架,该框架提出了从CTDG中学习时间相关嵌入 Co ...
- [论文阅读] Residual Attention(Multi-Label Recognition)
Residual Attention 文章: Residual Attention: A Simple but Effective Method for Multi-Label Recognition ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 《Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks》论文阅读
<Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shi ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- 搭建ipse隧道
我没有太多的物理服务器,实验环境只能用四台装了linux的虚拟机来模拟,用户层工具是openswan.大致拓扑如下(我有点懒,公网地址我用的194.168.10.0/24,别和192.168.xx.x ...
- day42 Pyhton 并发编程05
一.内容回顾 # 线程 # 正常的编程界: # 进程 # 计算机中最小的资源分配单位 # 数据隔离 # 进程可以独立存在 # 创建与销毁 还有切换 都慢 给操作系统压力大 # 线程 # 计算机中能被C ...
- 基于python实现顺序存储的栈
""" 栈 sstack.py 栈模型的顺序存储 重点代码 思路总结: 1.列表是顺序存储,但功能多,不符合栈的模型特征 2.利用列表,将其封装,提供接口方法 " ...
- 学习使用C语言/C++编程的7个步骤!超赞~
C是一种编译性语言.如果你以前从来没有接触过任何的编程语言,那么你则需要学习一下一个拆分的逻辑思维.当我们想要写一个项目或者软件的时候,我们需要把这个整体拆分为7个步骤,这样也会让你的思路看起来更有条 ...
- go读取键盘输入两种方式
一种scanf var x intfmt.Println("input a int number")fmt.Scan(&x)fmt.Printf("读取到内容:% ...
- Ubuntu服务安装
一.ifconfig命令安装 sudo apt install net-tools 二.ssh服务安装 sudo apt-get install openssh-server netstat -ltn ...
- Iobuffer的使用
写模式: 创建Iobuffer实例,使用Iobuffer的static方法-allocate,有一个参数的方法或者两个参数,第一个参数capacity是指定创建的Iobuffer的容量的最大值,需要注 ...
- JDK新特性——Stream代码简洁之道的详细用法
一.概述 Stream 是一组用来处理数组.集合的API,Stream API 提供了一种高效且易于使用的处理数据的方式. Java 8 中之所以费这么大的功夫引入 函数式编程 ,原因有两个: 代码简 ...
- 基于Spring读写分离
为什么是基于Spring的呢,因为实现方案基于Spring的事务以及AbstractRoutingDataSource(spring中的一个基础类,可以在其中放多个数据源,然后根据一些规则来确定当前需 ...
- Python作业1
name = " aleX" # 1 移除 name 变量对应的值两边的空格,并输出处理结果 print(name.strip()) # 2 判断 name 变量对应的值是否以 & ...