Mysql探索之Explain执行计划详解
前言
- 如何写出效率高的SQL语句,提到这必然离不开
Explain执行计划的分析,至于什么是执行计划,如何写出高效率的SQL,本篇文章将会一一介绍。
执行计划
执行计划是数据库根据 SQL 语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的。
使用
explain关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的,分析你的 select 语句或是表结构的性能瓶颈,让我们知道 select 效率低下的原因,从而改进我们的查询。explain 的结果如下:
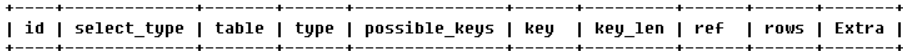
- 下面是有关各列的详细介绍,重要的有
id、type、key、rows、extra。
id
- id 列的编号就是 select 的序列号,也可以理解为 SQL 执行顺序的标识,有几个 select 就有几个 id。
- id 值不同:如果是只查询,id 的序号会递增,id 值越大优先级越高,越先被执行;
- id 值相同:从上往下依次执行;
- id 列为 null:表示这是一个结果集,不需要使用它来进行查询。
select_type
查询的类型,主要用于区分普通查询、联合查询、子查询等复杂的查询;
- simple:表示查询中不包括 union 操作或者子查询,位于最外层的查询的 select_type 即为 simple,且只有一个;
explain select * from t3 where id=3952602;
复制代码- primary:需要 union 操作或者含有子查询的 select,位于最外层的查询的 select_type 即为 primary,且只有一个;
explain select * from (select * from t3 where id=3952602) a ;
复制代码- derived:from 列表中出现的子查询,也叫做衍生表;mysql 或者递归执行这些子查询,把结果放在临时表里。
explain select * from (select * from t3 where id=3952602) a ;
复制代码- subquery:除了 from 子句中包含的子查询外,其他地方出现的子查询都可能是 subquery。
explain select * from t3 where id = (select id from t3 whereid=3952602 ) ;
复制代码
- union:若第二个 select 出现在 union 之后,则被标记为 union;若 union 包含在 from 子句的子查询中,外层 select 将被标记为 derived。
explain select * from t3 where id=3952602 union all select * from t3;
复制代码- union result:从 union 表获取结果的 select ,因为它不需要参与查询,所以 id 字段为 null。
explain select * from t3 where id=3952602 union all select * from t3;
复制代码
- dependent union:与 union 一样,出现在 union 或 union all 语句中,但是这个查询要受到外部查询的影响;
- dependent subquery:与 dependent union 类似,子查询中的第一个 SELECT,这个 subquery 的查询要受到外部表查询的影响。
table
- 表示 explain 的一行正在访问哪个表。
- 如果查询使用了别名,那么这里显示的是别名;
- 如果不涉及对数据表的操作,那么这显示为 null;
- 如果显示为尖括号括起来的就表示这个是临时表,后边的 N 就是执行计划中的 id,表示结果来自于这个查询产生;
- 如果是尖括号括起来的<union M,N>,与类似,也是一个临时表,表示这个结果来自于 union 查询的 id 为 M,N 的结果集。
type
访问类型,即 MySQL 决定如何查找表中的行。
依次从好到差:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,除了 all 之外,其他的 type 都可以使用到索引,除了 index_merge 之外,其他的 type 只可以用到一个索引。一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
system:表中只有一行数据(等于系统表),这是 const 类型的特例,平时不会出现,可以忽略不计。
const:使用唯一索引或者主键,表示通过索引一次就找到了,const 用于比较 primary key 或者 unique 索引。因为只需匹配一行数据,所有很快。如果将主键置于 where 列表中,mysql 就能将该查询转换为一个 const。
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一行数据与之匹配。常见于主键或唯一索引扫描。
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质也是一种索引。
fulltext:全文索引检索,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql 不管代价,优先选择使用全文索引。
ref_or_null:与 ref 方法类似,只是增加了 null 值的比较。
index_merge:表示查询使用了两个以上的索引,索引合并的优化方法,最后取交集或者并集,常见 and ,or 的条件使用了不同的索引。
unique_subquery:用于 where 中的 in 形式子查询,子查询返回不重复值唯一值;
index_subquery:用于 in 形式子查询使用到了辅助索引或者 in 常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
range:索引范围扫描,常见于使用
>,<,between,in,like等运算符的查询中。index:索引全表扫描,把索引树从头到尾扫一遍;
all:遍历全表以找到匹配的行(Index 与 ALL 虽然都是读全表,但 index 是从索引中读取,而 ALL 是从硬盘读取)
NULL: MySQL 在优化过程中分解语句,执行时甚至不用访问表或索引。
possible_keys
- 显示查询可能使用到的索引。
key
显示查询实际使用哪个索引来优化对该表的访问;
select_type 为 index_merge 时,这里可能出现两个以上的索引,其他的 select_type 这里只会出现一个。
key_len
- 用于处理查询的索引长度,表示索引中使用的字节数。通过这个值,可以得出一个多列索引里实际使用了哪一部分。
- 注:key_len 显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的。另外,key_len 只计算 where 条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到 key_len 中。
ref
显示哪个字段或者常数与 key 一起被使用。
如果是使用的常数等值查询,这里会显示 const。
如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段。
如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为 func。
rows
- 表示 MySQL 根据表统计信息及索引选用情况,大致估算的找到所需的目标记录所需要读取的行数,不是精确值。
extra
不适合在其他列中显示但十分重要的额外信息。
这个列可以显示的信息非常多,有几十种,常用的有:
| 类型 | 说明 |
|---|---|
| Using filesort | MySQL 有两种方式可以生成有序的结果,通过排序操作或者使用索引,当 Extra 中出现了 Using filesort 说明 MySQL 使用了后者,但注意虽然叫 filesort 但并不是说明就是用了文件来进行排序,只要可能排序都是在内存里完成的。大部分情况下利用索引排序更快,所以一般这时也要考虑优化查询了。使用文件完成排序操作,这是可能是 ordery by,group by 语句的结果,这可能是一个 CPU 密集型的过程,可以通过选择合适的索引来改进性能,用索引来为查询结果排序。 |
| Using temporary | 用临时表保存中间结果,常用于 GROUP BY 和 ORDER BY 操作中,一般看到它说明查询需要优化了,就算避免不了临时表的使用也要尽量避免硬盘临时表的使用。 |
| Not exists | MYSQL 优化了 LEFT JOIN,一旦它找到了匹配 LEFT JOIN 标准的行, 就不再搜索了。 |
| Using index | 说明查询是覆盖了索引的,不需要读取数据文件,从索引树(索引文件)中即可获得信息。如果同时出现 using where,表明索引被用来执行索引键值的查找,没有 using where,表明索引用来读取数据而非执行查找动作。这是 MySQL 服务层完成的,但无需再回表查询记录。 |
| Using index condition | 这是 MySQL 5.6 出来的新特性,叫做“索引条件推送”。简单说一点就是 MySQL 原来在索引上是不能执行如 like 这样的操作的,但是现在可以了,这样减少了不必要的 IO 操作,但是只能用在二级索引上。 |
| Using where | 使用了 WHERE 从句来限制哪些行将与下一张表匹配或者是返回给用户。注意:Extra 列出现 Using where 表示 MySQL 服务器将存储引擎返回服务层以后再应用 WHERE 条件过滤。 |
| Using join buffer | 使用了连接缓存:Block Nested Loop,连接算法是块嵌套循环连接;Batched Key Access,连接算法是批量索引连接 |
| impossible where | where 子句的值总是 false,不能用来获取任何元组 |
| select tables optimized away | 在没有 GROUP BY 子句的情况下,基于索引优化 MIN/MAX 操作,或者对于 MyISAM 存储引擎优化 COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 |
| distinct | 优化 distinct 操作,在找到第一匹配的元组后即停止找同样值的动作 |
filtered
- 使用 explain extended 时会出现这个列,5.7 之后的版本默认就有这个字段,不需要使用 explain extended 了。
- 这个字段表示存储引擎返回的数据在 server 层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
关于 MySQL 执行计划的局限性
- EXPLAIN 不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况;
- EXPLAIN 不考虑各种 Cache;
- EXPLAIN 不能显示 MySQL 在执行查询时所作的优化工作;
- 部分统计信息是估算的,并非精确值;
- EXPALIN 只能解释 SELECT 操作,其他操作要重写为 SELECT 后查看。
查询计划案例分析

执行顺序
(id = 4):【select id, name from t2】:select_type 为 union,说明 id=4 的 select 是 union 里面的第二个 select。
(id = 3):【select id, name from t1 where address = ‘11’】:因为是在 from 语句中包含的子查询所以被标记为 DERIVED(衍生),where address = ‘11’ 通过复合索引 idx_name_email_address 就能检索到,所以 type 为 index。
(id = 2):【select id from t3】:因为是在 select 中包含的子查询所以被标记为 SUBQUERY。
(id = 1):【select d1.name, … d2 from … d1】:select_type 为 PRIMARY 表示该查询为最外层查询,table 列被标记为 “derived3”表示查询结果来自于一个衍生表(id = 3 的 select 结果)。
(id = NULL):【 … union … 】:代表从 union 的临时表中读取行的阶段,table 列的 “union 1, 4”表示用 id=1 和 id=4 的 select 结果进行 union 操作。
Mysql探索之Explain执行计划详解的更多相关文章
- ( 转 ) MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解(转)
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL — 优化之explain执行计划详解(转)
EXPLAIN简介 EXPLAIN 命令是查看查询优化器如何决定执行查询的主要方法,使用EXPLAIN,只需要在查询中的SELECT关键字之前增加EXPLAIN这个词即可,MYSQL会在查询上设置一个 ...
- 高性能mysql 附录D explain执行计划详解
EXPLAIN: extended关键字:在explain后使用extended关键字,可以显示filtered列和warning信息.在较旧的MySQL版本中,扩展信息是使用EXPLAIN EXTE ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- 【夯实Mysql基础】mysql explain执行计划详解
原文地址 1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A ...
- mysql explain执行计划详解
1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A:simp ...
随机推荐
- HM16.0之帧间预测——xCheckRDCostInter()函数
参考:https://blog.csdn.net/nb_vol_1/article/category/6179825/1? 1.源代码: #if AMP_MRG Void TEncCu::xCheck ...
- All in One 你想知道的 hacker 技术都在这里
作者:HelloGitHub-小鱼干 hacker 这个词,大多数理解为黑客,而维基百科对其的定义为--黑客(Hacker)是指对设计.編程和计算机科学方面具高度理解的人,在本文中 hacker 主要 ...
- ASP.NET Core 3.1 WebAPI的跨域问题
1.nuget要加上 Microsoft.AspNetCore.Cors 中间件. 2.在Startup类里先定义一个全局变量. private readonly string AllowSpecif ...
- 漏洞重温之sql注入(五)
漏洞重温之sql注入(五) sqli-labs通关之旅 填坑来了! Less-17 首先,17关,我们先查看一下页面,发现网页正中间是一个登录框. 显然,该关卡的注入应该为post型. 直接查看源码. ...
- 【小白学PyTorch】4 构建模型三要素与权重初始化
文章目录: 目录 1 模型三要素 2 参数初始化 3 完整运行代码 4 尺寸计算与参数计算 1 模型三要素 三要素其实很简单 必须要继承nn.Module这个类,要让PyTorch知道这个类是一个Mo ...
- android开发之动画的详解 整理资料 Android开发程序小冰整理
/** * 作者:David Zheng on 2015/11/7 15:38 * * 网站:http://www.93sec.cc * * 微博:http://weibo.com/mcxiaob ...
- Lct 动态链接树
通过树链剖分能了解轻重边 Acdreamer 的博客 http://blog.csdn.net/acdreamers/article/details/10591443 然后看杨哲大大的论文,能了解轻重 ...
- Web最最基础
web 网站网页一个网站是由多个网页组成的一个网页=网页元素(文字.图片.超链接.文本框.按钮.下拉框ext.) +样式+用户交互 一个网页=(网页元素)html+(样式)CSS+(用户交互)Java ...
- HDU多校1003-Divide the Stones(构造)
Problem Description There are n stones numbered from 1 to n.The weight of the i-th stone is i kilogr ...
- cometoj(A-D+F+H)代码
A #include<cstdio> #include<cstring> #include<algorithm> #include<iostream> ...