GridMask:一种数据增强方法
GridMask Data Augmentation, ARXIV 2020
代码地址:https://github.com/akuxcw/GridMask
这篇论文提出了一种简单的数据增强方法,在图像分类、检测、分割三个任务进行实验,效果提升明显。
1. Introduction
作者首先回顾了数据增强(Data augmentation)方法,指出当前方法有三类:spatial transformation, color distortion, 以及 information dropping。本文提出的方法属于 information dropping,作者指出,对于此类方法,避免过度删除或保持连续区域是核心问题:一方面,过度删除区域将造成完整目标被删除或者上下文信息缺失,因此,剩下的区域不足以表达目标信息,会成为noisy data。另一方面,保留过多区域,将会使得目标不受影响(untouched),会影响网络的鲁棒性。
作者重点介绍了 Cutout 和 HaS 方法。Cutout方法只删除图像中的一块连续区域,因此,容易出现删除掉整个目标,或者一点目标也没有删除的情况;HaS方法把图像划分为若干小块的区域,然后随机删除,但仍然会出现和 Cutout 相同的问题。下图展示了 GridMask 方法与当前方法的对比。

2. Methodology
GridMask 通过生成一个和原图相同分辨率的mask,然后将该mask与原图相乘得到一个图像。下图中灰色区域的值为1,黑色区域的值为0。这样,就实现了特定区域的 information dropping,本质上可以理解为一种正则化方法。

GridMask对应4个参数,为 \((x,y,r,d)\) ,四个参数的设置如下图所示:
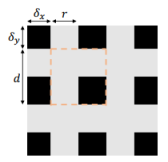
从图中可以看出,\(r\) 代表了保留原图像信息的比例,有一个计算方法,具体可以阅读论文。\(d\) 决定了一个dropped square的大小, 参数 \(x\)和\(y\)的取值有一定随机性,细节可以阅读论文。
3. 实验分析
在ImageNet-1K图像分类任务上,Cutout对ResNet50的提升为0.6%,HaS的提升为0.7%,AutoAugement提升为1.1%,相比而言,GridMask的提升为1.4%。作者还在CIFAR10数据集上进行了实验,这里不再详述。
在Ablation Study中,作者首先分析了参数\(r\)。如下图所示,在ImageNet-1K数据集上,设置为0.6比较好;在CIFAR10数据集上,设置为0.4比较好。作者解释为,在复杂的数据集上应该保持更多的信息来避免under-fitting,在简单数据集上应该丢弃更多的信息来减少over-fitting。这和 common sense 是一致的。

作者还在目标检测、语义分割任务上进行了实验,具体可阅读论文,不再详述。此外,作者还把方法和 Mixup方法进行了结合,结果表明性能同样可以得到提升。
4. 总结与讨论
GridMask是简单、通用性强并且有效的数据增强工具,同时,作者相信未来可以构造more excellent structures 来进一步改进性能。
GridMask:一种数据增强方法的更多相关文章
- iOS中常用的四种数据持久化方法简介
iOS中常用的四种数据持久化方法简介 iOS中的数据持久化方式,基本上有以下四种:属性列表.对象归档.SQLite3和Core Data 1.属性列表涉及到的主要类:NSUserDefaults,一般 ...
- iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比
iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比 iphoneiPhoneIPhoneIPHONEIphone数据持久化 对比总结 本篇对IOS中常用的5种数据持久化方法进行简单 ...
- JSON三种数据解析方法(转)
原 JSON三种数据解析方法 2018年01月15日 13:05:01 zhoujiang2012 阅读数:7896 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
- YoloV4当中的Mosaic数据增强方法(附代码详细讲解)码农的后花园
上一期中讲解了图像分类和目标检测中的数据增强的区别和联系,这期讲解数据增强的进阶版- yolov4中的Mosaic数据增强方法以及CutMix. 前言 Yolov4的mosaic数据增强参考了CutM ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning 小样本学习最新综述 | 三大数据增强方法
目录 原文链接:小样本学习与智能前沿 01 Transforming Samples from Dtrain 02 Transforming Samples from a Weakly Labeled ...
- python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释 本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(St ...
- AI佳作解读系列(四)——数据增强篇
前言 在深度学习的应用过程中,数据的重要性不言而喻.继上篇介绍了数据合成(个人认为其在某种程度上可被看成一种数据增强方法)这个主题后,本篇聚焦于数据增强来介绍几篇杰作! (1)NanoNets : H ...
- TensorFlow之DNN(三):神经网络的正则化方法(Dropout、L2正则化、早停和数据增强)
这一篇博客整理用TensorFlow实现神经网络正则化的内容. 深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合.缓解神经网络的过拟 ...
- 数据增强利器--Augmentor
最近遇到数据样本数目不足的问题,自己写的增强工具生成数目还是不够,终于在网上找到一个数据增强工具包,足够高级,足够傻瓜.想要多少就有多少!再也不怕数据不够了! 简介 Augmentor是一个Pytho ...
随机推荐
- [CF1216E] Numerical Sequence hard version
题目 The only difference between the easy and the hard versions is the maximum value of k. You are giv ...
- 【反转开灯问题】Face The Right Way
题目 Farmer John has arranged his N (1 ≤ N ≤ 5,000) cows in a row and many of them are facing forward, ...
- C# 从1到Core--委托与事件
委托与事件在C#1.0的时候就有了,随着C#版本的不断更新,有些写法和功能也在不断改变.本文温故一下这些改变,以及在NET Core中关于事件的一点改变. 一.C#1.0 从委托开始 1. 基本方式 ...
- Python-使用tkinter实现的Django服务进程管理工具
import tkinter import subprocess import os import time import re import sys from tkinter import Labe ...
- 在linux上安装jdk(转载)
软件环境: 虚拟机:VMware Workstation 10 操作系统:Ubuntu-12.04-desktop-amd64 JAVA版本:jdk-7u55-linux-x64 软件下载地址: JD ...
- java语言基础(三)_数组
数组 是引用类型 1. 容器:是将多个数据存储到一起,每个数据称为该容器的元素. 2. 数组概念:数组就是存储数据长度固定的容器,保证多个数据的数据类型要一致. 特点: 数组是一种引用数据类型 数组当 ...
- BUUCTF-Misc-No.2
比赛信息 比赛地址:Buuctf靶场 [GUET-CTF2019]虚假的压缩包 | SOLVED 解压文件夹,发现2个zip,第一个伪加密,破解后 n=33 e=3 m=0 while m<10 ...
- day72 bbs项目☞登录注册
目录 一.表创建及同步 二.注册功能 二.登录页面搭建 一.表创建及同步 from django.db import models from django.contrib.auth.models im ...
- JavaScript学习 Ⅰ
一. JavaScript的使用 <script>标签 在HTML中,JavaScript代码必须位于<script>与</script>标签之间. 实例: < ...
- java 面向对象(三十):异常(三) 手动抛出异常对象
1.使用说明在程序执行中,除了自动抛出异常对象的情况之外,我们还可以手动的throw一个异常类的对象. 2.[面试题] throw 和 throws区别:throw 表示抛出一个异常类的对象,生成异常 ...