给自己挖坑——DateWay
填坑
简介
依托 DataQL 服务聚合能力,为应用提供一个 UI 界面。并以 jar 包的方式集成到应用中。 通过 Dataway 可以直接在界面上配置和发布接口。而不需要写代码。
使用
1. 引入相关依赖
<dependency>
<groupId>net.hasor</groupId>
<artifactId>hasor-spring</artifactId>
<version>4.1.4</version>
</dependency>
<dependency>
<groupId>net.hasor</groupId>
<artifactId>hasor-dataway</artifactId>
<version>4.1.4</version><!-- 4.1.4 包存在UI资源缺失问题 -->
</dependency>
hasor-spring 负责 Spring 和 Hasor 框架之间的整合。hasor-dataway 是工作在 Hasor 之上,利用 hasor-spring 我们就可以使用 dataway了。
2. 配置 Dataway,并初始化数据表
- Spring配置文件
dataway 会提供一个界面让我们配置接口,这一点类似 Swagger 只要jar包集成就可以实现接口配置。找到我们 springboot 项目的配置文件 application.properties
# 是否启用 Dataway 功能(必选:默认false)
HASOR_DATAQL_DATAWAY=true
# 是否开启 Dataway 后台管理界面(必选:默认false)
HASOR_DATAQL_DATAWAY_ADMIN=true
# dataway API工作路径(可选,默认:/api/)
HASOR_DATAQL_DATAWAY_API_URL=/api/
# dataway-ui 的工作路径(可选,默认:/interface-ui/)
HASOR_DATAQL_DATAWAY_UI_URL=/interface-ui/
# SQL执行器方言设置(可选,建议设置)
HASOR_DATAQL_FX_PAGE_DIALECT=mysql
- 在数据库创建数据表
Dataway 需要两个数据表才能工作,下面是这两个数据表的简表语句。下面这个 SQL 可以在 dataway的依赖 jar 包中 “META-INF/hasor-framework/mysql” 目录下面找到,建表语句是用 mysql 语法写的。
CREATE TABLE `interface_info` (
`api_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`api_method` varchar(12) NOT NULL COMMENT 'HttpMethod:GET、PUT、POST',
`api_path` varchar(512) NOT NULL COMMENT '拦截路径',
`api_status` int(2) NOT NULL COMMENT '状态:0草稿,1发布,2有变更,3禁用',
`api_comment` varchar(255) NULL COMMENT '注释',
`api_type` varchar(24) NOT NULL COMMENT '脚本类型:SQL、DataQL',
`api_script` mediumtext NOT NULL COMMENT '查询脚本:xxxxxxx',
`api_schema` mediumtext NULL COMMENT '接口的请求/响应数据结构',
`api_sample` mediumtext NULL COMMENT '请求/响应/请求头样本数据',
`api_create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`api_gmt_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`api_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COMMENT='Dataway 中的API';
CREATE TABLE `interface_release` (
`pub_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Publish ID',
`pub_api_id` int(11) NOT NULL COMMENT '所属API ID',
`pub_method` varchar(12) NOT NULL COMMENT 'HttpMethod:GET、PUT、POST',
`pub_path` varchar(512) NOT NULL COMMENT '拦截路径',
`pub_status` int(2) NOT NULL COMMENT '状态:0有效,1无效(可能被下线)',
`pub_type` varchar(24) NOT NULL COMMENT '脚本类型:SQL、DataQL',
`pub_script` mediumtext NOT NULL COMMENT '查询脚本:xxxxxxx',
`pub_script_ori` mediumtext NOT NULL COMMENT '原始查询脚本,仅当类型为SQL时不同',
`pub_schema` mediumtext NULL COMMENT '接口的请求/响应数据结构',
`pub_sample` mediumtext NULL COMMENT '请求/响应/请求头样本数据',
`pub_release_time`datetime DEFAULT CURRENT_TIMESTAMP COMMENT '发布时间(下线不更新)',
PRIMARY KEY (`pub_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COMMENT='Dataway API 发布历史。';
create index idx_interface_release on interface_release (pub_api_id);
3. 配置数据源
作为 Spring Boot 项目有着自己完善的数据库方面工具支持。我们这次采用 druid + mysql + spring-boot-starter-jdbc 的方式
首先引入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.30</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
然后增加数据源的配置
# db
spring.datasource.url=jdbc:mysql://xxxxxxx:3306/example
spring.datasource.username=xxxxx
spring.datasource.password=xxxxx
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.type:com.alibaba.druid.pool.DruidDataSource
# druid
spring.datasource.druid.initial-size=3
spring.datasource.druid.min-idle=3
spring.datasource.druid.max-active=10
spring.datasource.druid.max-wait=60000
spring.datasource.druid.stat-view-servlet.login-username=admin
spring.datasource.druid.stat-view-servlet.login-password=admin
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=1
如果项目已经集成了自己的数据源,那么可以忽略第三步。
4. 把数据源设置到 Hasor 容器中
Spring Boot 和 Hasor 本是两个独立的容器框架,我们做整合之后为了使用 Dataway 的能力需要把 Spring 中的数据源设置到 Hasor 中。
首先新建一个 Hasor 的 模块,并且将其交给 Spring 管理。然后把数据源通过 Spring 注入进来。
@DimModule
@Component
public class ExampleModule implements SpringModule {
@Autowired
private DataSource dataSource = null;
@Override
public void loadModule(ApiBinder apiBinder) throws Throwable {
// .DataSource form Spring boot into Hasor
apiBinder.installModule(new JdbcModule(Level.Full, this.dataSource));
}
}
5. 在SprintBoot 中启用 Hasor
@EnableHasor()
@EnableHasorWeb()
@SpringBootApplication()
public class ExampleApplication {
public static void main(String[] args) {
SpringApplication.run(ExampleApplication.class, args);
}
}
这一步非常简单,只需要在 Spring 启动类上增加两个注解即可。
6. 启动应用
- 在启动的时候会看到两个图标
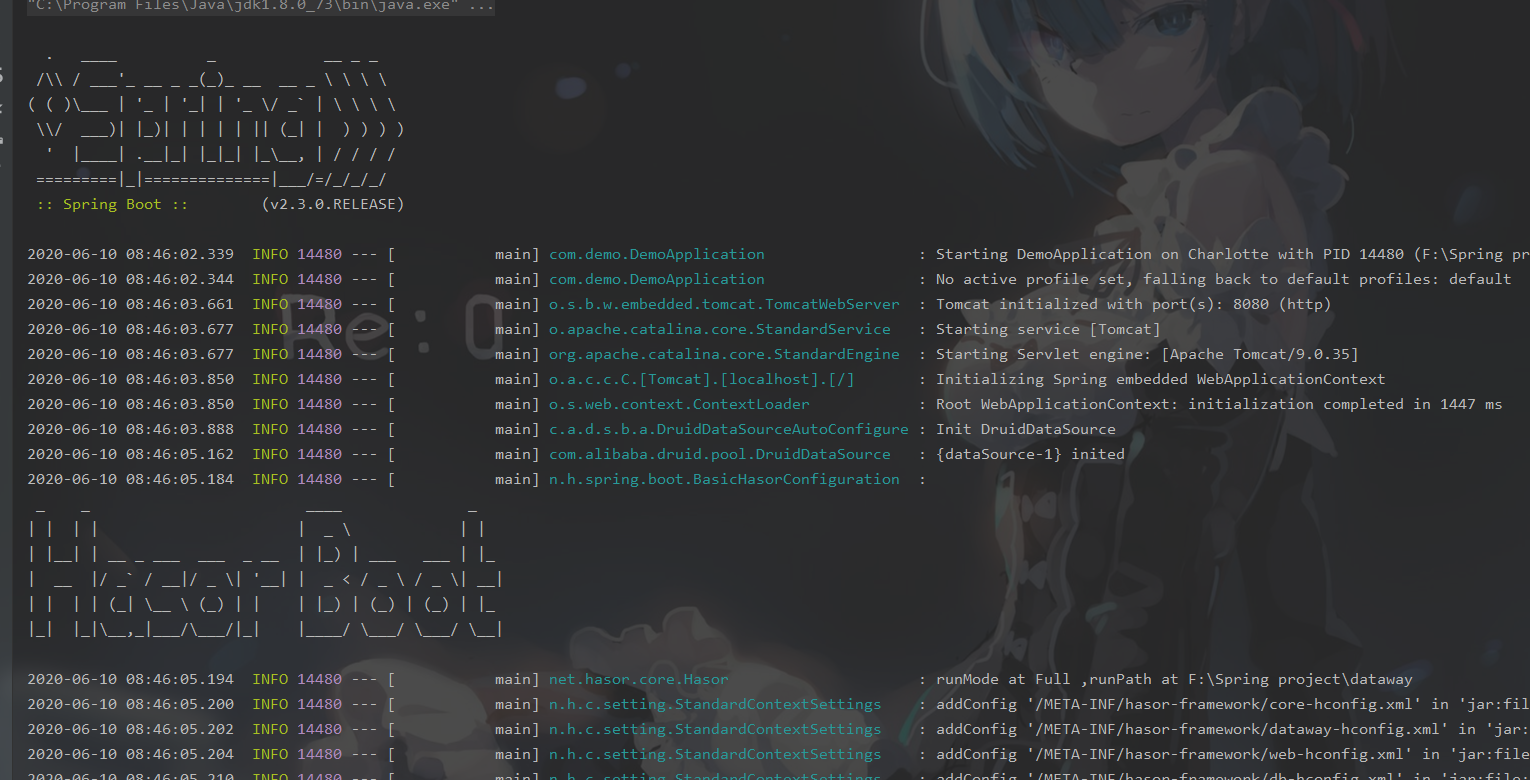
当看到2020-06-10 08:46:05.374 INFO 14480 --- [main] net.hasor.dataway.config.DatawayModule:dataway api workAt /api/时,可以认为启动成功。
7. 访问接口管理页
浏览器输入http://127.0.0.1:8080/interface-ui/#/进入界面。

8. 新建一个接口
点击New
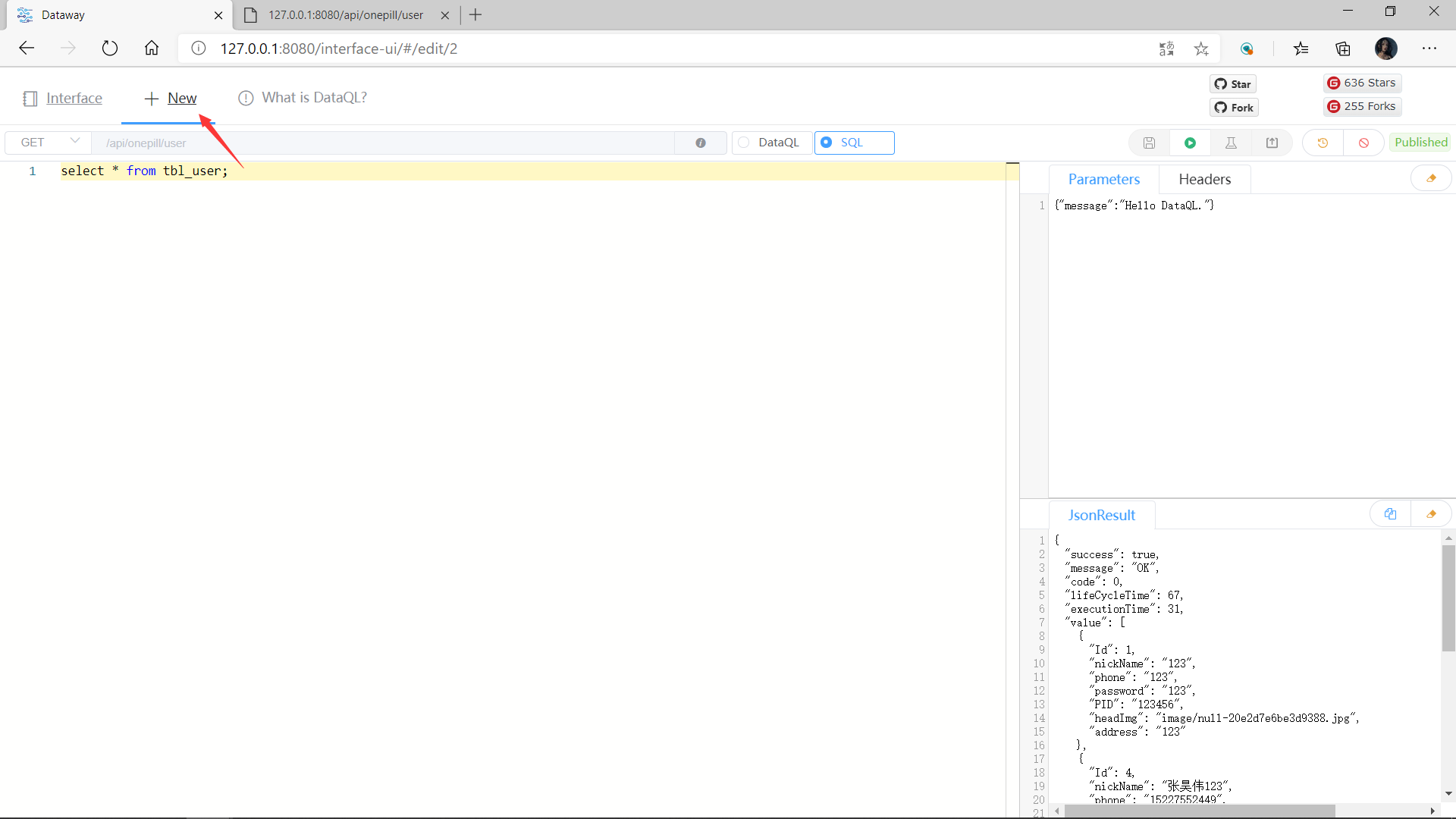
在下方窗口中输入sql语句
后续操作
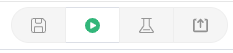
右边的四个按钮分别是保存,运行,冒烟测试,发布。
首先点击运行,然后下方会有返回的数据:
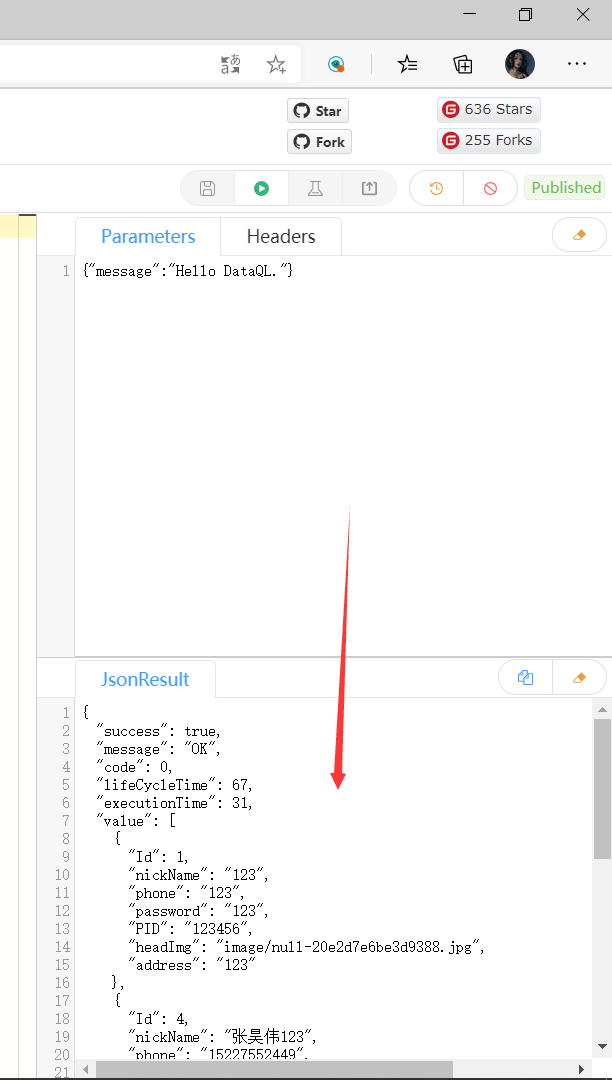
修改发布的url地址

如果测试无误,可以点击保存,然后进行冒烟测试,测试成功则可以点击发布,将接口发布出去。
9. 测试接口
在浏览器地址栏输入上一步设置的路径
会出现返回结果。

10. 创建一个测试接口
- 点击New
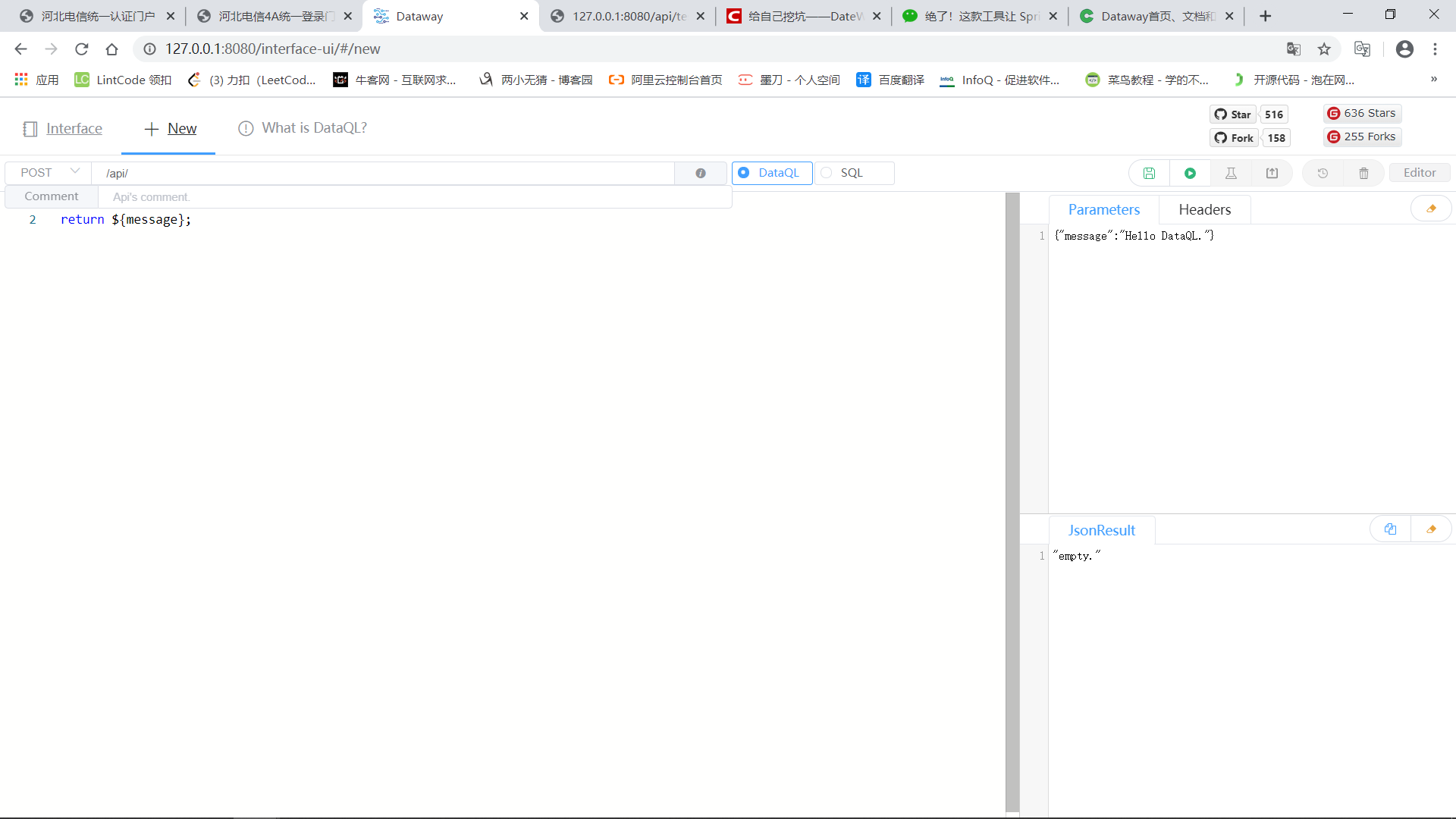
- 修改url地址,并将请求类型设置为get

- 编辑mysql语句

在sql语句中使用url中的参数需要改成#{参数名称}。
- 添加测试参数

在Parameters中添加的测试数据就是访问url时,后面添加的参数,可以在3中直接使用。
- 点击运行
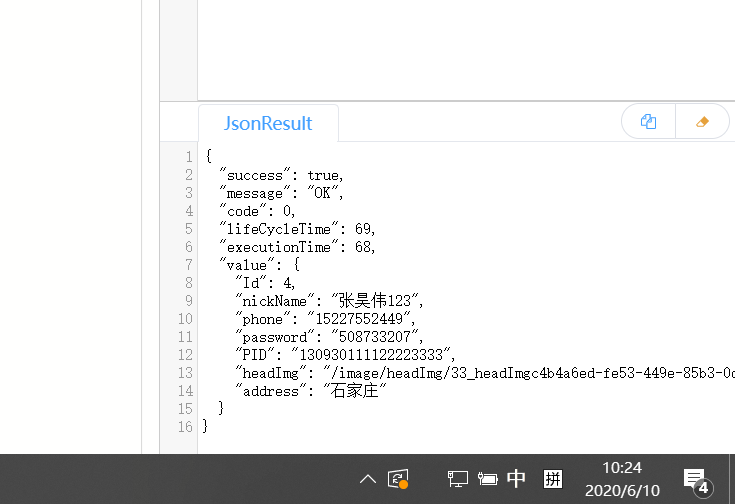
- 保存,冒烟测试,发布
此时状态已经更新

- 浏览器访问
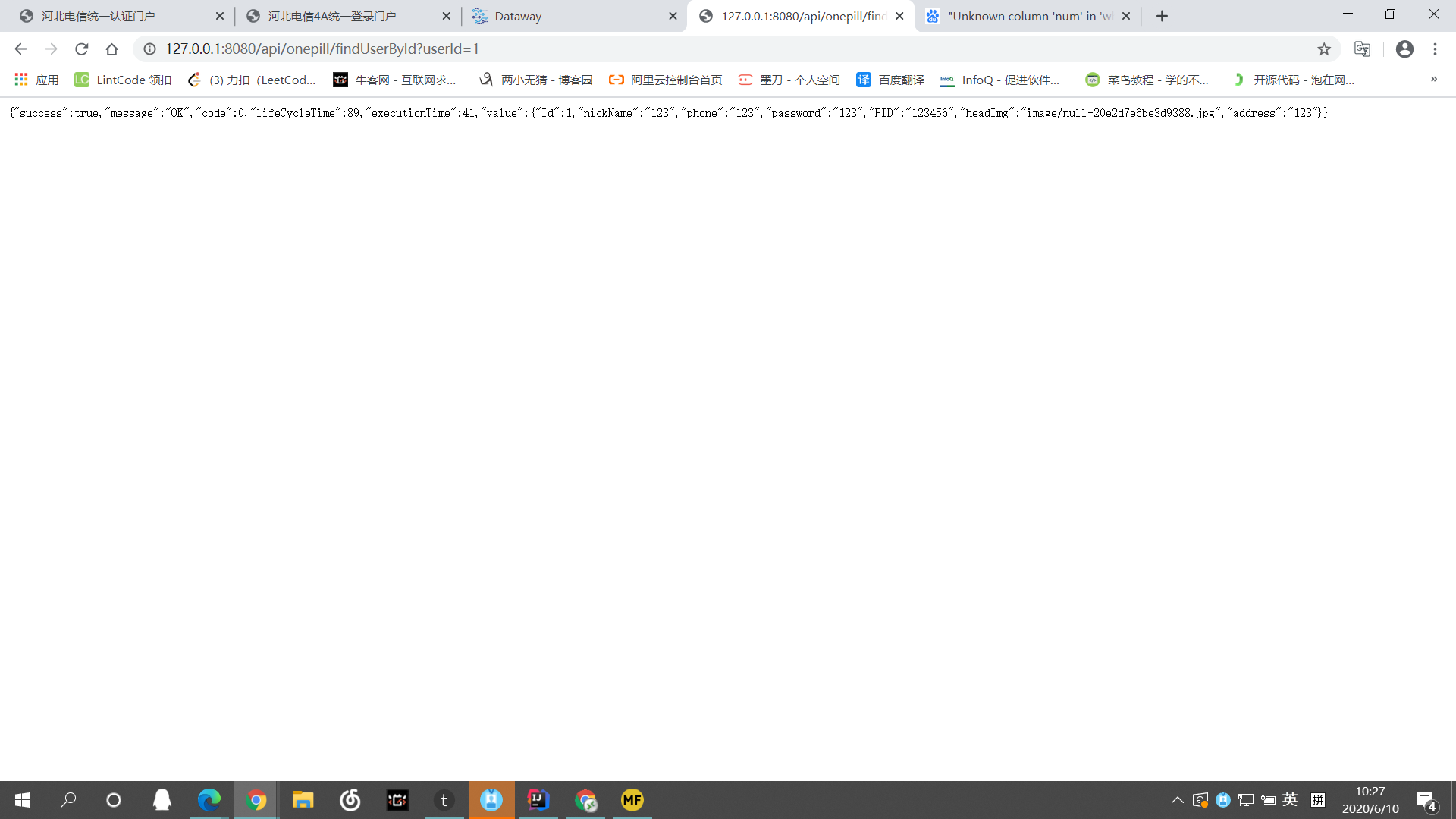
数据返回正常。
POST类型没有测试
3. 拓展
1. DateQL引擎
- 语法
- 注释:单行注释为
//``,多行注释为/* ... */`
和java一样的。 - DataQL 会把这些字符识别为空白字符:(空格)、\t、\n、\r、\f
- 关键字
- 注释:单行注释为
| 关键字 | 含义 |
|---|---|
| if | 条件语句 |
| else | 用在条件语句之后 |
| return | 三大退出指令之一,终止当前过程的执行并正常退出到上一个执行过程中 |
| exit | 三大退出指令之一,终止所有后续指令的执行并正常退出 |
| throw | 三大退出指令之一,终止所有后续指令的执行并抛出异常 |
| var | 执行一个查询动作,并把查询结果保存到临时变量中 |
| run | 仅仅执行查询动作,不保留查询的结果 |
| hint | 写在 DataQL 查询语句的最前面,用于设置一些执行选项参数 |
| import | 将另外一个 DataQL 查询导入并作为一个 Udf 形式存在、或直接导入一个 Udf 到当前查询中 |
| as | 与 import 关键字配合使用,用作将导入的 Udf 命名为一个本地变量名 |
| true | 真 |
| false | 假 |
| null | 空值 |
4. 分隔符
| 分隔符 | 含义 |
|---|---|
| () | 函数入参的圈定,表达式中的计算项提取权 |
| {} | 用来定义复合语句 |
| [] | 对数据通过下标方式取值 |
| , | 不同参数的分割 |
| : | 对象键值对 |
| ; | 语句的结束,DataQL 会自动推断语句结束,因此语句结束分割符并不是必须的 |
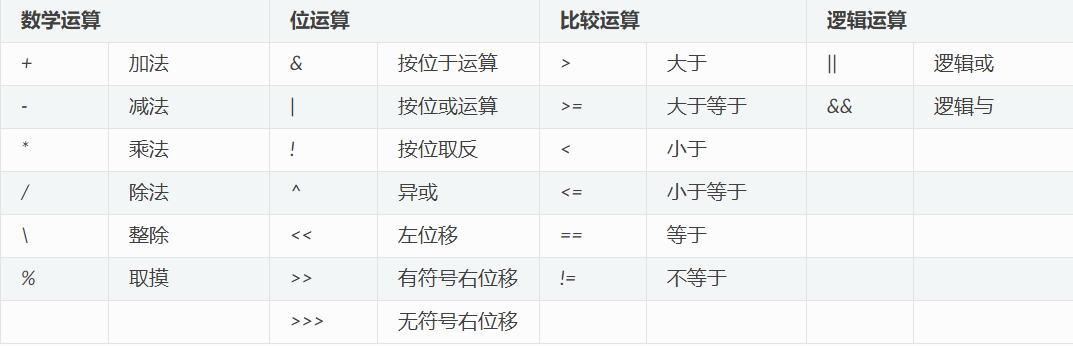
5. 运算符
- 类型系统
DataQL 是弱类型定义的查询语言,在DataQL 中所有数据都会被归结到有限的几种类型上。无需定义数据类型结构,在弱类型系统中编写查询会非常方便,它去掉了繁杂的类型定义。
1. 布尔类型
var bool = true;
2. 集合
格式:[…]
空集合:[]
多维集合:[[…],[…]]
3. 对象
格式:{“k1”: … ,”k2”: …}
空对象:{}
多层结构:{“k1”: { … }, “k2”: { … } }
4. UDF
外部Udf:外部的 Udf 被引入之后,通常以标识符形式表示它。
DataQL 中书写的 lambda 表达方式为:var foo = () -> { /* 代码块 / }
外部代码片段:var a = @@xxx() <% / 外部代码块 */ %>
5. JSON
DataQL 可以直接表达 Json 数据(Json 的 Key 必须通过双引号或单引号形式包裹起来)
- 取值和赋值



官方文档什么的没提过返回一个网页的操作,所以应该只能作为后台使用。填坑成功。
给自己挖坑——DateWay的更多相关文章
- windows的ReactNative挖坑一分钟爬坑一小时
其实开发并不需要Android Studio来开发,因为命令行都是要自己手打的,所以就开始了我的挖坑爬坑之旅 首先安装React Native要用到的git.nodejs等等这里不讲了,主要讲在手机上 ...
- Saku实力挖坑记!!(十八)
Saiku实力挖坑记!!!!!!! 我可真真真的是个挖坑小能手呀!不知道你们有没有遇到过这个异常: Enclosure class mondrian.olap.MondrianDef not foun ...
- 使用java实现快速排序(挖坑填数法和指针交换法)
快速排序:通过一趟排序,将数据分为两部分,其中一部分中的所有数据比另外一部分的所有数据要小,然后按照此方法,分别对这两部分进行排序,达到最终的排序结果. 每趟排序选取基准元素,比该基准元素大的数据放在 ...
- 【Python】远离 Python 最差实践,避免挖坑
原文链接:http://blog.guoyb.com/2016/12/03/bad-py-style/ 最近在看一些陈年老系统,其中有一些不好的代码习惯遗留下来的坑:加上最近自己也写了一段烂代码导致服 ...
- Executors 挖坑
Executors 挖坑 线程频繁的创建销毁是有代价的,所以Java为我们提供了线程池 线程池构造方法很多 我们一般使用Executors的工厂方法: public static ExecutorSe ...
- 【挖坑】2019年JAVA安全总结:SQL注入——新项目的开发与老项目的修复
如何在项目中有效的防止SQL注入 写给需要的人,所有的问题源自我们的不重视. 本章略过"什么是SQL注入","如何去利用SQL注入"的讲解,仅讲如何去防御 PS ...
- 布隆过滤器(Bloom Filter)-学习笔记-Java版代码(挖坑ing)
布隆过滤器解决"面试题: 如何建立一个十亿级别的哈希表,限制内存空间" "如何快速查询一个10亿大小的集合中的元素是否存在" 如题 布隆过滤器确实很神奇, 简单 ...
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用 周翼南 北京大学 工学硕士 373 人赞同了该文章 基于深 ...
- Angular 从入坑到挖坑 - 组件食用指南
一.Overview angular 入坑记录的笔记第二篇,介绍组件中的相关概念,以及如何在 angular 中通过使用组件来完成系统功能的实现 对应官方文档地址: 显示数据 模板语法 用户输入 组件 ...
随机推荐
- vueX基础知识笔记
接着昨天的知识点 mutations提交时,有时候达不到想要的响应式,我们必须要将数据提前放到state中,否则不会达到响应式的效果.比如 state.info['address'] = value ...
- MongoDB快速入门教程 (2)
2.MongoDB的基本的CRUD操作 2.1.创建文档 在具体操作之前,想要知道有多少数据库,可以执行下面命令 show dbs 在mongodb中,数据库中包含的叫做集合(表),集合中存储的内容叫 ...
- GDI+ 双缓冲实现
早前曾为此问题在CSDN发帖求助(GDI+ 如何使用双缓冲绘制图像),得到了一个GDI+下较可行的方法,虽然绘制效果比直接绘制要好一些,不过还不能跟GDI的双缓冲方式比肩. 现在,我终于找到了一个 ...
- Red Hat Enterprise Linux 6上安装Oracle 11G(11.2.0.4.0)缺少pdksh包的问题
RHEL 6上安装Oracle 11G警告缺少pdksh包 前言 相信很多刚刚接触学习Oracle的人,在RHEL6上安装11.2.0.3 or 11.2.0.4这两个版本的时候, 都遇到过先决条件检 ...
- Raft论文《 In Search of an Understandable Consensus Algorithm (Extended Version) 》研读
Raft 论文研读 说明:本文为论文 < In Search of an Understandable Consensus Algorithm (Extended Version) > 的 ...
- RESTful API 规范(一)
一,简介 DRF 即Django rest framework 二,rest 规范 1 协议 API 与用户通信,总是使用https协议 2 域名 1) 应尽量将API 部署在域名下(这种情况会存在跨 ...
- uni-app网络请求
对于 GET 方法,会将数据转换为 query string.例如 { name: 'name', age: 18 } 转换后的结果是 name=name&age=18. 对于 POST 方法 ...
- python 检索文件内容工具
公司内部需求一个工具检索目录下的文件在另外的目录中使用次数, 用来优化包体的大小. 此代码效率并不高效, 另添加对应的 后缀检索. 用python 实现比较快速, 另还有缺点是只支持 utf-8 格式 ...
- 题解:2018级算法第六次上机 C6-危机合约
题目描述 样例: 实现解释: 没想到你也是个刀客塔之二维DP 知识点: 动态规划,多条流水线调度?可以看做一种流水线调度 坑点: 输入内容的调整(*的特殊判定),开头结尾的调整策略 从题意可知,要做的 ...
- java 面向对象(二十):类的结构:代码块
类的成员之四:代码块(初始化块)(重要性较属性.方法.构造器差一些)1.代码块的作用:用来初始化类.对象的信息2.分类:代码块要是使用修饰符,只能使用static分类:静态代码块 vs 非静态代码块3 ...