python爬取网易翻译 和MD5加密
一、程序需要知识
1、python中随机数的生成
# 生成 0 ~ 9 之间的随机数 # 导入 random(随机数) 模块
import random print(random.randint(0,9))
2、python获取当前时间和时间戳
import time,datetime
#时间戳
print(time.time())
#今天的日期
print(datetime.date.today())
3、JavaScript parseInt(string,radix) 函数
| string | 必需。要被解析的字符串。 |
| radix |
可选。表示要解析的数字的基数。该值介于 2 ~ 36 之间。 如果省略该参数或其值为 0,则数字将以 10 为基础来解析。如果它以 “0x” 或 “0X” 开头,将以 16 为基数。 如果该参数小于 2 或者大于 36,则 parseInt() 将返回 NaN。 |
当参数 radix 的值为 0,或没有设置该参数时,parseInt() 会根据 string 来判断数字的基数。
举例,如果 string 以 "0x" 开头,parseInt() 会把 string 的其余部分解析为十六进制的整数。如果 string 以 0 开头,那么 ECMAScript v3 允许 parseInt() 的一个实现把其后的字符解析为八进制或十六进制的数字。如果 string 以 1 ~ 9 的数字开头,parseInt() 将把它解析为十进制的整数。
parseInt("10"); //返回 10
parseInt("19",10); //返回 19 (10+9)
parseInt("11",2); //返回 3 (2+1)
parseInt("17",8); //返回 15 (8+7)
parseInt("1f",16); //返回 31 (16+15)
parseInt("010"); //未定:返回 10 或 8
其实就是说string是radix进制,你把它转为十进制的数然后返回
4、python中的md5加密
def get_md5(t): #传入一个待加密的字符串t
t = t.encode('utf-8')
md5 = hashlib.md5(t).hexdigest()
return md5 #md5就是加密后的字符串
二、js加密破解

你多翻译几次,得到多次请求和回应信息,比较一下就会发现红线处三个值一直在改变
其中 i 值比较明显就能看出来,这个就是你要翻译的字符,剩下三个想来也就只有搜索一下在哪个文件出现过

点击红线处,就会打开一个js文件
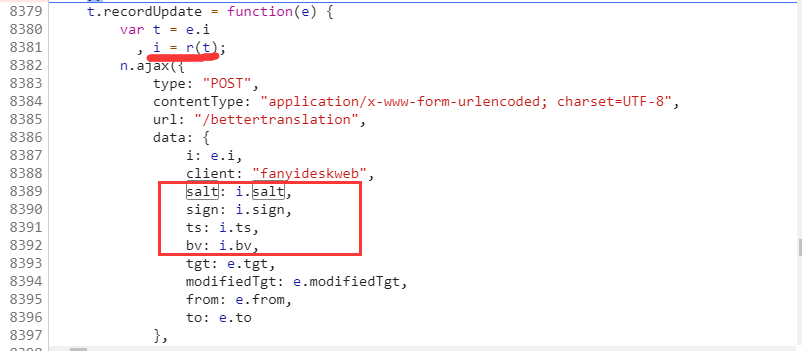
我们发现i这个对象是来自己r函数,逻辑就是r函数创建了一个对象,那就找一下r函数所在位置
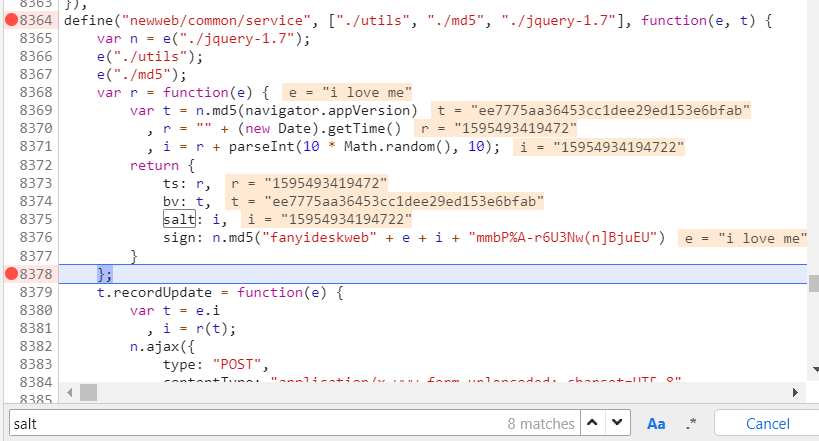
在文件中搜索这个词所在的位置,然后打断点看一下各变量的值
你发现t变量的值就是对一个字符串就行md5加密,如图

r变量的就是获取当前时间戳,然后乘于1000,因为不乘于1000得到的值的整数部分位数不够
i变量就是在r变量的基础上随机在后面加上一个[0,9]的数字
这个代码有些英文字母可以翻译,有些不可能。我也有点迷。在网上找了几个也是破js加密的代码发现也是和我一样的问题,,不太清楚哪里的错(如果某个大神找到了,带带我^_^)


import time
import random
import requests
import json
import hashlib headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '242',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'OUTFOX_SEARCH_USER_ID=-636625617@10.168.1.8; OUTFOX_SEARCH_USER_ID_NCOO=1075352995.079191; Hm_lvt_eaa57ca47dacb4ad4f5a257001a3457c=1568894226; JSESSIONID=aaaXQbfNVU1rgbPOx94nx; ___rl__test__cookies=1595473000749',
'Host': 'fanyi.youdao.com',
'Origin': 'http://fanyi.youdao.com',
'Referer': 'http://fanyi.youdao.com/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36' } def get_md5(t):
t = t.encode('utf-8')
md5 = hashlib.md5(t).hexdigest()
return md5 url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
r = time.time()*1000
r = str(int(r))
i = r + str(random.randint(0,9)) e = input('请输入待翻译内容:')
sign = get_md5("fanyideskweb" + e + i + "mmbP%A-r6U3Nw(n]BjuEU")
bv = get_md5("5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36") data = {
'i': e,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
#'salt' : '15810537039389',
#'sign' : '157b38258a2253c7899895880487edfd',
#'ts' : '1581053703938',
#'bv' : '901200199a98c590144a961dac532964', 'salt': i,
'sign': sign,
'ts': r,
'bv': bv,
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
#data = urllib.parse.urlencode(data).encode('utf-8')
text = requests.post(url,headers=headers,data=data)
dic = text.json()
#print(dic)
lis = dic['translateResult']
#print(lis)
print(lis[0][0].get('tgt'))
我又在网上找到了另一种方式的代码,这个代码中文英文什么都能翻译,,,emmmm有点强
import urllib.request
import urllib.parse
import json
import time
while True:
target = input("请输入需要翻译的内容:")
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = {
'i' : target,
'from' : 'AUTO',
'to' : 'AUTO',
'smartresult' : 'dict',
'client' : 'fanyideskweb',
'salt' : '15810537039389',
'sign' : '157b38258a2253c7899895880487edfd',
'ts' : '1581053703938',
'bv' : '901200199a98c590144a961dac532964',
'doctype' : 'json',
'version' : '2.1',
'keyfrom' : 'fanyi.web',
'action' : 'FY_BY_CLICKBUTTION'
} head = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'} data = urllib.parse.urlencode(data).encode('utf-8') rep = urllib.request.Request(url, data, head)
response = urllib.request.urlopen(rep) html = response.read().decode('utf-8')
result = json.loads(html)
result = result['translateResult'][0][0]['tgt'] print("翻译结果为:",result)
python爬取网易翻译 和MD5加密的更多相关文章
- 如何利用python爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: LSGOGroup PS:如有需要Python学习资料的小伙伴可以 ...
- python爬取百度翻译返回:{'error': 997, 'from': 'zh', 'to': 'en', 'query 问题
解决办法: 修改url为手机版的地址:http://fanyi.baidu.com/basetrans User-Agent也用手机版的 测试代码: # -*- coding: utf-8 -*- & ...
- 用 Python 爬取网易严选妹子内衣信息,探究妹纸们的偏好
网易商品评论爬取 分析网页 评论分析 进入到网易精选官网,搜索“文胸”后,先随便点进一个商品. 在商品页面,打开 Chrome 的控制台,切换至 Network 页,再把商品页Python入门到精通学 ...
- python爬取网易评论
学习python不久,最近爬的网页都是直接源代码中直接就有的,看到网易新闻的评论时,发现评论时以json格式加载的..... 爬的网页是习大大2015访英的评论页http://comment.news ...
- python 爬取百度翻译进行中英互译
感谢RoyFans 他的博客地址http://www.cnblogs.com/royfans/p/7417914.html import requests def py(): url = 'http: ...
- python爬取股票最新数据并用excel绘制树状图
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Python爬虫实战教程:爬取网易新闻;爬虫精选 高手技巧
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. stars声明很多小伙伴学习Python过程中会遇到各种烦恼问题解决不了.为 ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
随机推荐
- java8 stream api流式编程
java8自带常用的函数式接口 Predicate boolean test(T t) 传入一个参数返回boolean值 Consumer void accept(T t) 传入一个参数,无返回值 F ...
- 在JavaScript种遇到这样的错误如何解决XML 解析错误:格式不佳 位置:http:/... 行 27,列 32:
相信很多人在开发的过程中都会遇到在js中解析xml文档的问题.有时候文档解析失败,但就是不知道怎么失败的,哪里格式不对.这里教大家一个方法来排查JavaScript解析xml文档格式出错的办法. 1. ...
- linux网络工具nc命令
nc是netcat的简写,有着网络界的瑞士军刀美誉.因为它短小精悍.功能实用,被设计为一个简单.可靠的网络工具. nc命令的作用 (1)实现任意TCP/UDP端口的侦听,nc可以作为server以TC ...
- nginx日志按天切割
要求:以天为单位进行日志文件的切割,如host.access_20150915.log, 日志保留最近10天的, 超过10天的日志文件则进行删除. nginxcutlogs.sh脚本内容: #!/bi ...
- 【Git】Git初始化一个仓库
文章目录 初始化仓库 检查当前文件状态 跟踪新文件 提交更新 跳过使用暂存区域 移除文件 添加远程仓库 推送到远程仓库 简单记录-慕课网 从0开始 独立完成企业级Java电商网站开发 Git初始化一个 ...
- 【ORA】ORA-32004: 问题分析和解决
今天做一个特殊的实验,需要重启数据库 数据库关闭没有问题 SQL> shutdown immediate; Database closed. Database dismounted. ORACL ...
- 【.NET 与树莓派】矩阵按键
欢迎收看火星卫视,本期节目咱们严重探讨一下矩阵按键. 所谓矩阵按键,就是一个小键盘(其实一块PCB板),上面有几个 Key(开关),你不按下去的时候,电路是断开的,你按下去电路就会接通.至于说有多少个 ...
- Ubuntu源、Python虚拟环境及pip源配置
Ubuntu 命令行更改源 在修改source.list前,最好先备份一份 软件源的地址配置文件在 /etc/apt/sources.list 执行备份命令 sudo cp /etc/apt/sour ...
- ././include/linux/kconfig.h:4:32: fatal error: generated/autoconf.h: No such file or directory 解决办法
我在编写内核驱动模块的时候报了一个非常奇怪的错误,如下图: 在目录下看了一下确实没有发现这个文件,感觉很奇怪,因为我记得之前编译模块是没有错误的,所以不可能是我代码写的有问题. 查阅了资料很多说要清除 ...
- jquery 数据查询
jquery 数据查询 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> & ...