干货!Apache Hudi如何智能处理小文件问题
1. 引入
Apache Hudi是一个流行的开源的数据湖框架,Hudi提供的一个非常重要的特性是自动管理文件大小,而不用用户干预。大量的小文件将会导致很差的查询分析性能,因为查询引擎执行查询时需要进行太多次文件的打开/读取/关闭。在流式场景中不断摄取数据,如果不进行处理,会产生很多小文件。
2. 写入时 vs 写入后
一种常见的处理方法先写入很多小文件,然后再合并成大文件以解决由小文件引起的系统扩展性问题,但由于暴露太多小文件可能导致不能保证查询的SLA。实际上对于Hudi表,通过Hudi提供的Clustering功能可以非常轻松的做到这一点,更多细节可参考之前一篇文章查询时间降低60%!Apache Hudi数据布局黑科技了解下。
本篇文章将介绍Hudi的文件大小优化策略,即在写入时处理。Hudi会自管理文件大小,避免向查询引擎暴露小文件,其中自动处理文件大小起很大作用。
在进行insert/upsert操作时,Hudi可以将文件大小维护在一个指定文件大小(注意:bulk_insert操作暂无此特性,其主要用于替换spark.write.parquet方式将数据快速写入Hudi)。
3. 配置
我们使用COPY_ON_WRITE表来演示Hudi如何自动处理文件大小特性。
关键配置项如下:
hoodie.parquet.max.file.size:数据文件最大大小,Hudi将试着维护文件大小到该指定值;
hoodie.parquet.small.file.limit:小于该大小的文件均被视为小文件;
hoodie.copyonwrite.insert.split.size:单文件中插入记录条数,此值应与单个文件中的记录数匹配(可以根据最大文件大小和每个记录大小来确定)
例如如果你第一个配置值设置为120MB,第二个配置值设置为100MB,则任何大小小于100MB的文件都将被视为一个小文件,如果要关闭此功能,可将hoodie.parquet.small.file.limit配置值设置为0。
4. 示例
假设一个指定分区下数据文件布局如下
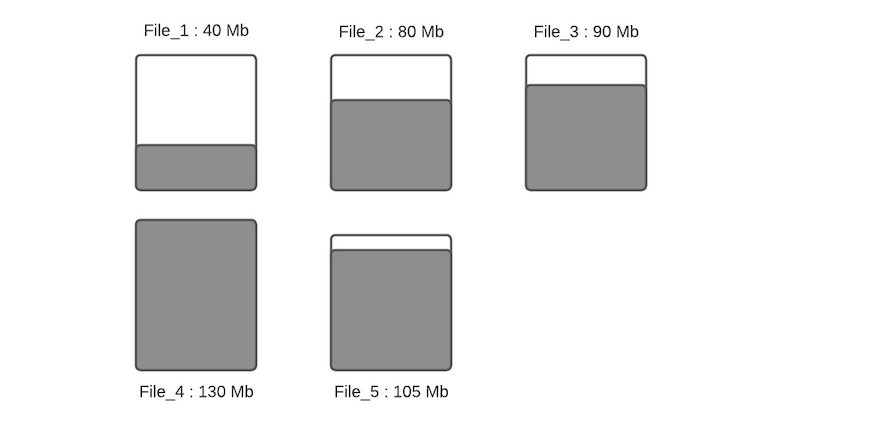
假设配置的hoodie.parquet.max.file.size为120MB,hoodie.parquet.small.file.limit为100MB。File_1大小为40MB,File_2大小为80MB,File_3是90MB,File_4是130MB,File_5是105MB,当有新写入时其流程如下:
步骤一:将更新分配到指定文件,这一步将查找索引来找到相应的文件,假设更新会增加文件的大小,会导致文件变大。当更新减小文件大小时(例如使许多字段无效),则随后的写入将文件将越来越小。
步骤二:根据hoodie.parquet.small.file.limit决定每个分区下的小文件,我们的示例中该配置为100MB,所以小文件为File_1、File_2和File_3;
步骤三:确定小文件后,新插入的记录将分配给小文件以便使其达到120MB,File_1将会插入80MB大小的记录数,File_2将会插入40MB大小的记录数,File_3将插入30MB大小的记录数。
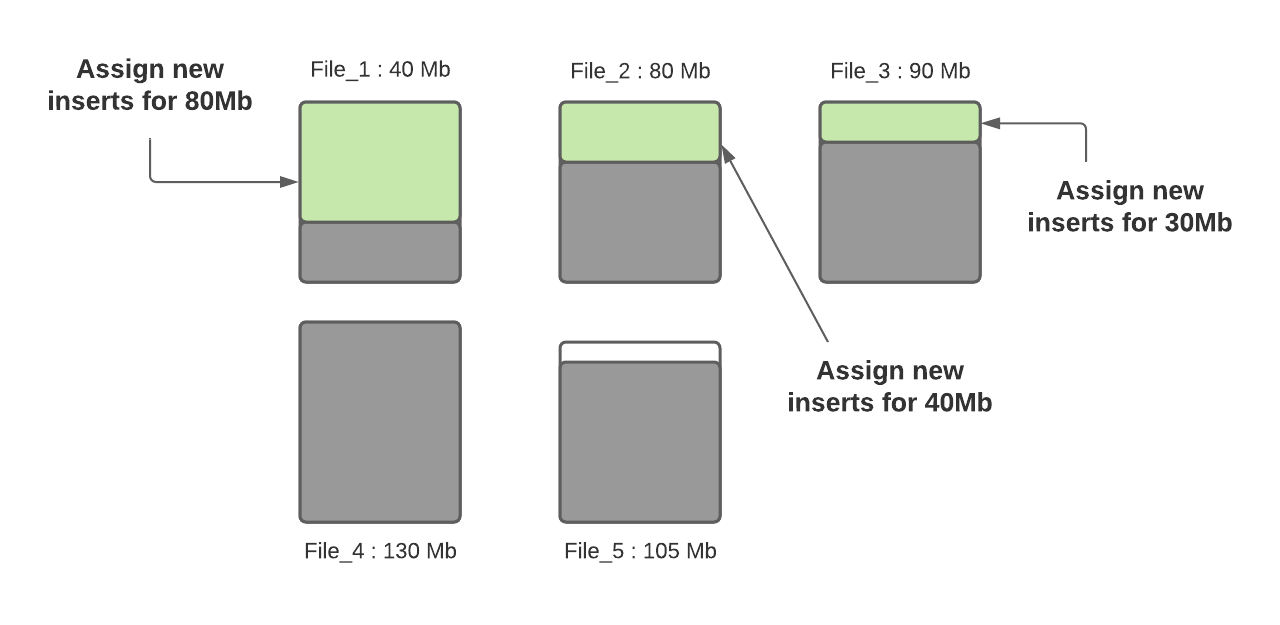
步骤四:当所有小文件都分配完了对应插入记录数后,如果还有剩余未分配的插入记录,这些记录将分配给新创建的FileGroup/数据文件。数据文件中的记录数由hoodie.copyonwrite.insert.split.size(或者由之前的写入自动推算每条记录大小,然后根据配置的最大文件大小计算出来可以插入的记录数)决定,假设最后得到的该值为120K(每条记录大小1K),如果还剩余300K的记录数,将会创建3个新文件(File_6,File_7,File_8),File_6和File_7都会分配120K的记录数,File_8会分配60K的记录数,共计60MB,后面再写入时,File_8会被认为小文件,可以插入更多数据。
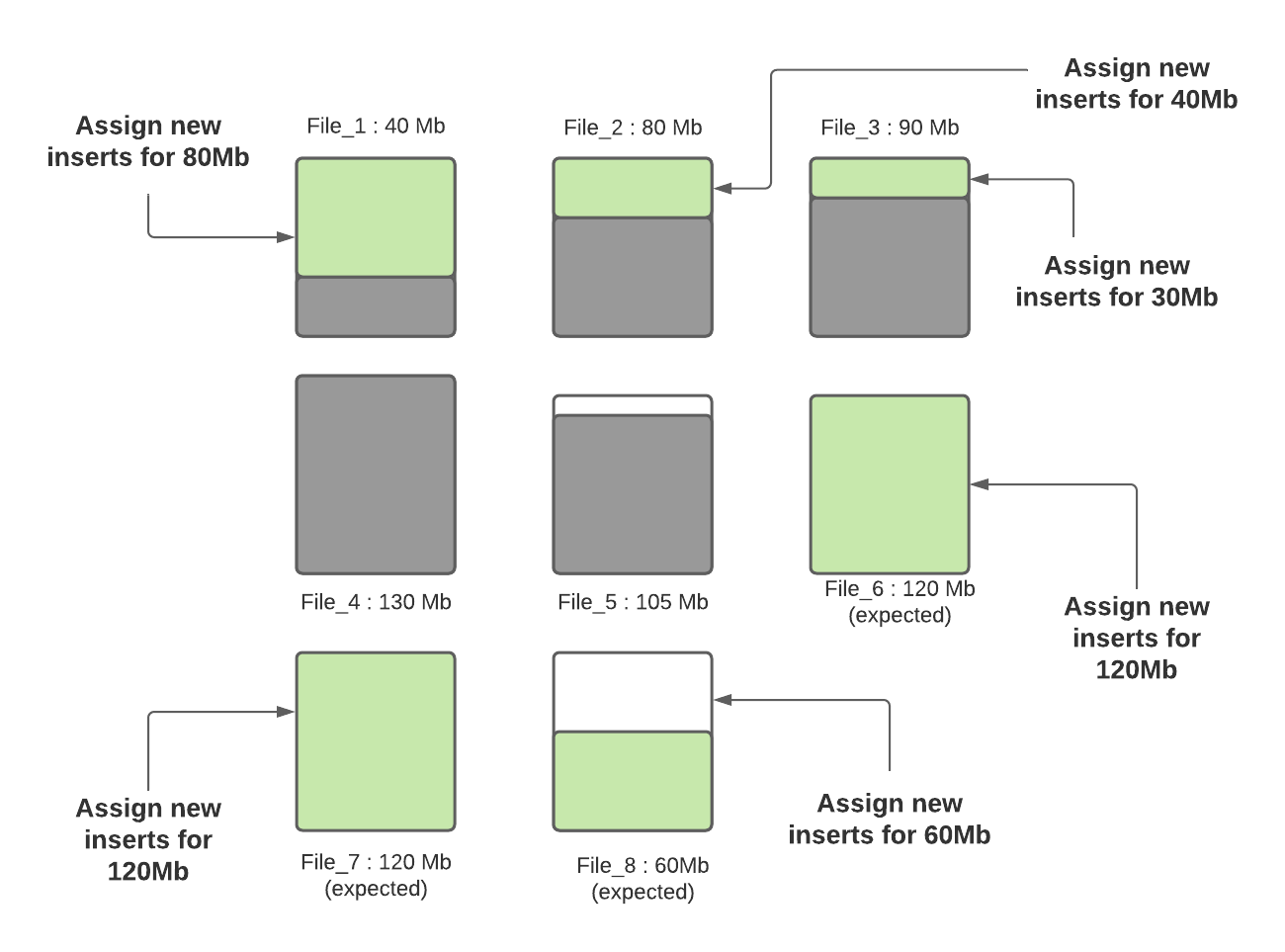
Hudi利用诸如自定义分区之类的机制来优化记录分配到不同文件的能力,从而执行上述算法。在这轮写入完成之后,除File_8以外的所有文件均已调整为最佳大小,每次写入都会遵循此过程,以确保Hudi表中没有小文件。
5. 总结
本文介绍了Apache Hudi如何智能地管理小文件问题,即在写入时找出小文件并分配指定大小的记录数来规避小文件问题,基于该设计,用户再也不用担心Apache Hudi数据湖中的小文件问题了。
干货!Apache Hudi如何智能处理小文件问题的更多相关文章
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- 重磅!Vertica集成Apache Hudi指南
1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访 ...
- Apache Hudi内核之文件标记机制深入解析
1. 摘要 Hudi 支持在写入时自动清理未成功提交的数据.Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件. 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其 ...
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- Apache Hudi在华米科技的应用-湖仓一体化改造
徐昱 Apache Hudi Contributor:华米高级大数据开发工程师 巨东东 华米大数据开发工程师 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技 ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
随机推荐
- SameSite cookies explained
SameSite cookies explained
- CURTIS SAVANAH:数字经济=智能基础设施+海量数据+新生业态
前不久,Datahero Inc公司(公司编号:20141166945)创始人CURTIS SAVANAH在会议上表示,要构建数字经济的愿景,需要智能基础设施.海量数据和全新新生业态. 他在演讲中说到 ...
- 去中心化预言机如何助力NGK DeFi 项目发展?
早在 2014 年前后,协议智能合约就已经出现了,最初协议很笨重,包含了许多不同的部分,每个部分都是一个单独的智能合约,你需要在区块链本身的协议中添加不同的智能合约,这需要几个月甚至几年的时间,而之后 ...
- K8S部署Redis Cluster集群
kubernetes部署单节点redis: https://www.cnblogs.com/zisefeizhu/p/14282299.html Redis 介绍 • Redis代表REmote DI ...
- K8S部署Redis Cluster集群(三主三从模式) - 部署笔记
一.Redis 介绍 Redis代表REmote DIctionary Server是一种开源的内存中数据存储,通常用作数据库,缓存或消息代理.它可以存储和操作高级数据类型,例如列表,地图,集合和排序 ...
- java放射机制的学习心得
概述 之前在了解Spring的类加载机制的时候,了解了java的反射机制.但是,我对反射理解一直不深.也一直有点疑惑:Spring为什么利用反射创建对象?直接new对象和依靠反射创建对象有什么区别?什 ...
- 20_MySQL表的内连接实操
-- 查询底薪超过公司平均底薪的员工信息 -- 方法1 SELECT empno,ename FROM t_emp HAVING sal>AVG(sal); 因为在having中不能拿一个字段与 ...
- Django模型层2
目录 一.聚合查询 聚合函数 二.分组查询 利用group by进行分组查询 三.F与Q查询 1. F类 2. Q类 四.orm字段及参数 五.自定义char字段 六.orm中的事务操作 1. 什么是 ...
- 优化程序性能(CSAPP)
[前言]虽然现在没有接触过大型项目,但是工作了会注重性能.学习一下,应该能更好更快的理解别人写的经典优化的代码.结合CSAPP和自己的理解,总结一下. 一.程序优化综述 1.高效程序的特点 (1)适当 ...
- nacos服务注册之服务器端Distro
一致性协议算法Distro阿里自己的创的算法吧,网上能找到的资料很少.Distro用于处理ephemeral类型数据 Distro协议算法看代码大体流程是: nacos启动首先从其他远程节点同步全部数 ...